From f2af8e8eddb5945a70c1fde5fcf3c481154ec919 Mon Sep 17 00:00:00 2001
From: Sal2912 <58745060+Sal2912@users.noreply.github.com>
Date: Tue, 3 Mar 2020 00:02:03 -0500
Subject: [PATCH 1/6] Delete first_last_name_reverse.py
---
first_last_name_reverse.py | 4 ----
1 file changed, 4 deletions(-)
delete mode 100644 first_last_name_reverse.py
diff --git a/first_last_name_reverse.py b/first_last_name_reverse.py
deleted file mode 100644
index 50bfa31..0000000
--- a/first_last_name_reverse.py
+++ /dev/null
@@ -1,4 +0,0 @@
-first_name = input("Enter your First Name: ")
-last_name = input("Enter your Last Name: ")
-full_name = first_name + last_name
-print(f'Reversed name is: {full_name[: :-1]}')
From 567386b1d0d1475a4f7916712f7dac4179661d10 Mon Sep 17 00:00:00 2001
From: Sal2912 <58745060+Sal2912@users.noreply.github.com>
Date: Tue, 3 Mar 2020 00:02:30 -0500
Subject: [PATCH 2/6] Add files via upload
Python file
---
US Economic data .py | 329 +++++++++++++++++++++++++++++++++++++++++++
1 file changed, 329 insertions(+)
create mode 100644 US Economic data .py
diff --git a/US Economic data .py b/US Economic data .py
new file mode 100644
index 0000000..dd748a3
--- /dev/null
+++ b/US Economic data .py
@@ -0,0 +1,329 @@
+#!/usr/bin/env python
+# coding: utf-8
+
+#  +
+#
+
+# Analyzing US Economic Data and Building a Dashboard
+# Description
+#
+
+# Extracting essential data from a dataset and displaying it is a necessary part of data science; therefore individuals can make correct decisions based on the data. In this assignment, you will extract some essential economic indicators from some data, you will then display these economic indicators in a Dashboard. You can then share the dashboard via an URL.
+#
+# Gross domestic product (GDP) is a measure of the market value of all the final goods and services produced in a period. GDP is an indicator of how well the economy is doing. A drop in GDP indicates the economy is producing less; similarly an increase in GDP suggests the economy is performing better. In this lab, you will examine how changes in GDP impact the unemployment rate. You will take screen shots of every step, you will share the notebook and the URL pointing to the dashboard.
+
+# Table of Contents
+#
+#
+#
+# Estimated Time Needed: 180 min
+#
+
+# Define Function that Makes a Dashboard
+
+# We will import the following libraries.
+
+# In[1]:
+
+
+import pandas as pd
+from bokeh.plotting import figure, output_file, show,output_notebook
+output_notebook()
+
+
+# In this section, we define the function make_dashboard.
+# You don't have to know how the function works, you should only care about the inputs. The function will produce a dashboard as well as an html file. You can then use this html file to share your dashboard. If you do not know what an html file is don't worry everything you need to know will be provided in the lab.
+
+# In[2]:
+
+
+def make_dashboard(x, gdp_change, unemployment, title, file_name):
+ output_file(file_name)
+ p = figure(title=title, x_axis_label='year', y_axis_label='%')
+ p.line(x.squeeze(), gdp_change.squeeze(), color="firebrick", line_width=4, legend="% GDP change")
+ p.line(x.squeeze(), unemployment.squeeze(), line_width=4, legend="% unemployed")
+ show(p)
+
+
+# The dictionary links contain the CSV files with all the data. The value for the key GDP is the file that contains the GDP data. The value for the key unemployment contains the unemployment data.
+
+# In[3]:
+
+
+links={'GDP':'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/projects/coursera_project/clean_gdp.csv', 'unemployment':'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/projects/coursera_project/clean_unemployment.csv'}
+
+
+# Question 1: Create a dataframe that contains the GDP data and display the first five rows of the dataframe.
+
+# Use the dictionary links and the function pd.read_csv to create a Pandas dataframes that contains the GDP data.
+
+# Hint: links["GDP"] contains the path or name of the file.
+
+# In[6]:
+
+
+# Type your code here
+df_GDP = pd.read_csv(links['GDP'])
+df_GDP
+
+
+# Use the method head() to display the first five rows of the GDP data, then take a screen-shot.
+
+# In[7]:
+
+
+# Type your code here
+df_GDP.head()
+
+
+# Question 2: Create a dataframe that contains the unemployment data. Display the first five rows of the dataframe.
+
+# Use the dictionary links and the function pd.read_csv to create a Pandas dataframes that contains the unemployment data.
+
+# In[8]:
+
+
+# Type your code here
+df_Unemployment = pd.read_csv(links['unemployment'])
+
+
+# Use the method head() to display the first five rows of the GDP data, then take a screen-shot.
+
+# In[9]:
+
+
+# Type your code here
+df_Unemployment.head()
+
+
+# Question 3: Display a dataframe where unemployment was greater than 8.5%. Take a screen-shot.
+
+# In[15]:
+
+
+# Type your code here
+df_Unemployment[df_Unemployment['unemployment']>8.5]
+
+
+# Question 4: Use the function make_dashboard to make a dashboard
+
+# In this section, you will call the function make_dashboard , to produce a dashboard. We will use the convention of giving each variable the same name as the function parameter.
+
+# Create a new dataframe with the column 'date' called x from the dataframe that contains the GDP data.
+
+# In[17]:
+
+
+x = df_GDP['date']
+x
+
+
+# Create a new dataframe with the column 'change-current' called gdp_change from the dataframe that contains the GDP data.
+
+# In[18]:
+
+
+gdp_change = df_GDP['change-current']
+gdp_change
+
+
+# Create a new dataframe with the column 'unemployment' called unemployment from the dataframe that contains the unemployment data.
+
+# In[19]:
+
+
+unemployment = df_Unemployment['unemployment']
+unemployment
+
+
+# Give your dashboard a string title, and assign it to the variable title
+
+# In[21]:
+
+
+title = 'US Economic Data Analysis'
+title
+
+
+# Finally, the function make_dashboard will output an .html in your direictory, just like a csv file. The name of the file is "index.html" and it will be stored in the varable file_name.
+
+# In[22]:
+
+
+file_name = "index.html"
+
+
+# Call the function make_dashboard , to produce a dashboard. Assign the parameter values accordingly take a the , take a screen shot of the dashboard and submit it.
+
+# In[23]:
+
+
+# Fill up the parameters in the following function:
+make_dashboard(x=x, gdp_change=gdp_change, unemployment=unemployment, title=title, file_name=file_name)
+
+
+# (Optional not marked)Save the dashboard on IBM cloud and display it
+
+# From the tutorial PROVISIONING AN OBJECT STORAGE INSTANCE ON IBM CLOUD copy the JSON object containing the credentials you created. You’ll want to store everything you see in a credentials variable like the one below (obviously, replace the placeholder values with your own). Take special note of your access_key_id and secret_access_key. Do not delete # @hidden_cell as this will not allow people to see your credentials when you share your notebook.
+
+#
+# credentials = {
+# "apikey": "your-api-key",
+# "cos_hmac_keys": {
+# "access_key_id": "your-access-key-here",
+# "secret_access_key": "your-secret-access-key-here"
+# },
+#
+#
+# "endpoints": "your-endpoints",
+# "iam_apikey_description": "your-iam_apikey_description",
+# "iam_apikey_name": "your-iam_apikey_name",
+# "iam_role_crn": "your-iam_apikey_name",
+# "iam_serviceid_crn": "your-iam_serviceid_crn",
+# "resource_instance_id": "your-resource_instance_id"
+# }
+#
+
+# In[ ]:
+
+
+# @hidden_cell
+#
+
+
+# You will need the endpoint make sure the setting are the same as PROVISIONING AN OBJECT STORAGE INSTANCE ON IBM CLOUD assign the name of your bucket to the variable bucket_name
+
+# In[ ]:
+
+
+endpoint = 'https://s3-api.us-geo.objectstorage.softlayer.net'
+
+
+# From the tutorial PROVISIONING AN OBJECT STORAGE INSTANCE ON IBM CLOUD assign the name of your bucket to the variable bucket_name
+
+# In[ ]:
+
+
+bucket_name = # Type your bucket name on IBM Cloud
+
+
+# We can access IBM Cloud Object Storage with Python useing the boto3 library, which we’ll import below:
+
+# In[ ]:
+
+
+import boto3
+
+
+# We can interact with IBM Cloud Object Storage through a boto3 resource object.
+
+# In[ ]:
+
+
+resource = boto3.resource(
+ 's3',
+ aws_access_key_id = credentials["cos_hmac_keys"]['access_key_id'],
+ aws_secret_access_key = credentials["cos_hmac_keys"]["secret_access_key"],
+ endpoint_url = endpoint,
+)
+
+
+# We are going to use open to create a file object. To get the path of the file, you are going to concatenate the name of the file stored in the variable file_name. The directory stored in the variable directory using the + operator and assign it to the variable
+# html_path. We will use the function getcwd() to find current the working directory.
+
+# In[ ]:
+
+
+import os
+
+directory = os.getcwd()
+html_path = directory + "/" + file_name
+
+
+# Now you must read the html file, use the function f = open(html_path, mode) to create a file object and assign it to the variable f. The parameter file should be the variable html_path, the mode should be "r" for read.
+
+# In[ ]:
+
+
+# Type your code here
+
+
+# To load your dataset into the bucket we will use the method put_object, you must set the parameter name to the name of the bucket, the parameter Key should be the name of the HTML file and the value for the parameter Body should be set to f.read().
+
+# In[ ]:
+
+
+# Fill up the parameters in the following function:
+# resource.Bucket(name=).put_object(Key=, Body=)
+
+
+# In the dictionary Params provide the bucket name as the value for the key 'Bucket'. Also for the value of the key 'Key' add the name of the html file, both values should be strings.
+
+# In[ ]:
+
+
+# Fill in the value for each key
+# Params = {'Bucket': ,'Key': }
+
+
+# The following lines of code will generate a URL to share your dashboard. The URL only last seven days, but don't worry you will get full marks if the URL is visible in your notebook.
+
+# In[ ]:
+
+
+import sys
+time = 7*24*60**2
+client = boto3.client(
+ 's3',
+ aws_access_key_id = credentials["cos_hmac_keys"]['access_key_id'],
+ aws_secret_access_key = credentials["cos_hmac_keys"]["secret_access_key"],
+ endpoint_url=endpoint,
+
+)
+url = client.generate_presigned_url('get_object',Params=Params,ExpiresIn=time)
+print(url)
+
+
+# How to submit
+
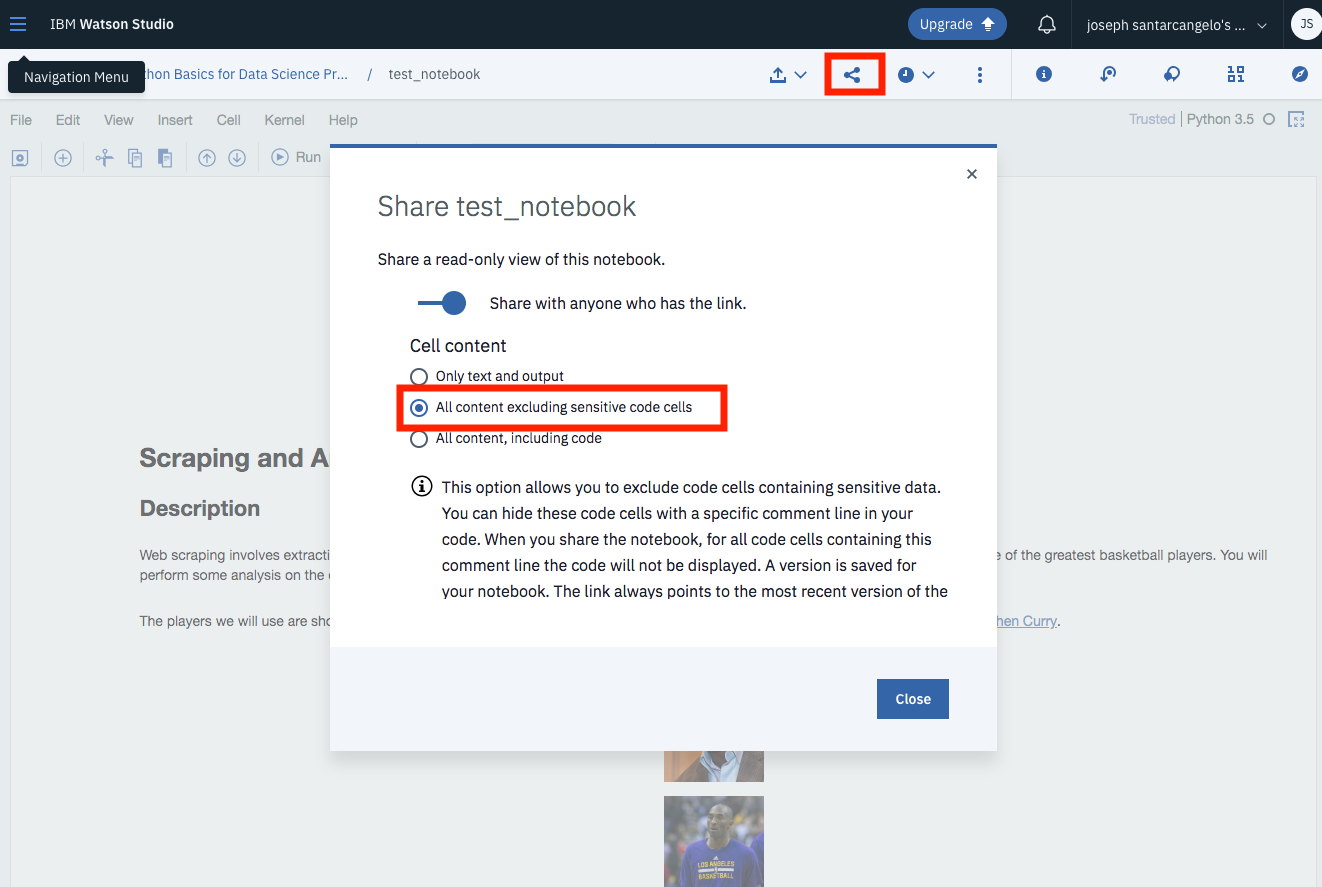
+# Once you complete your notebook you will have to share it to be marked. Select the icon on the top right a marked in red in the image below, a dialogue box should open, select the option all content excluding sensitive code cells.
+#
+# 
+#
+#
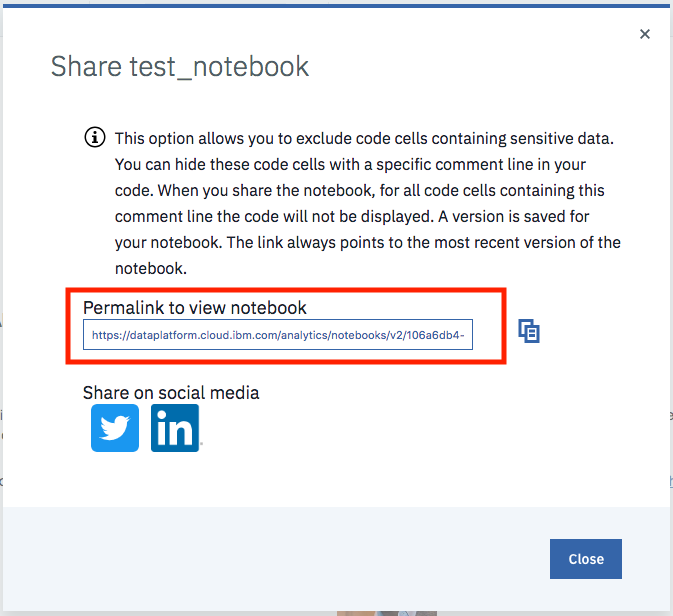
+# You can then share the notebook via a URL by scrolling down as shown in the following image:
+# 
+
+#
+# Copyright © 2019 IBM Developer Skills Network. This notebook and its source code are released under the terms of the MIT License.
+
+# About the Authors:
+#
+# Joseph Santarcangelo has a PhD in Electrical Engineering, his research focused on using machine learning, signal processing, and computer vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.
+#
+# Other contributors: Yi leng Yao, Mavis Zhou
+#
+
+# References :
+
+#
+#
From 397c2f51fb28bd35d3aca945e49e3e086a37314c Mon Sep 17 00:00:00 2001
From: Sal2912 <58745060+Sal2912@users.noreply.github.com>
Date: Tue, 3 Mar 2020 00:03:17 -0500
Subject: [PATCH 3/6] Add files via upload
Screenshot of first five rows of GDP data
---
Screen Shot 2020-03-02 at 11.42.11 PM.png | Bin 0 -> 111454 bytes
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 Screen Shot 2020-03-02 at 11.42.11 PM.png
diff --git a/Screen Shot 2020-03-02 at 11.42.11 PM.png b/Screen Shot 2020-03-02 at 11.42.11 PM.png
new file mode 100644
index 0000000000000000000000000000000000000000..78142641ba4ef0c12e3d210eb56b67337c61fd2b
GIT binary patch
literal 111454
zcmeFZXIN9++BHfMQHo#zRHQ4tDNRZMrHS+|El95c=_GWOA_#~y>AjbTGzlcAh#*KW
zp@UKa2_Z;_P`-ukckg|D=lpoipY!X@btPG3^*Qf(&vB127O!-*)o7`1Qjw65(5gRD
z)+Zsks7yja_VmJe;Fm{7M0pYt8ZBofC0%tTC3ame4+m#Adtk+@lr+jG2HzROFsX)D
z%-G5FA9@sAAR{e$Ily`05rgub+u<*-*gn*)<%*@Mu~hyX$>2FS%J8PaMkLmT5KEDg
z;_J!4%rWSR?2}FpB+!t+MuXA?=|(Bpt<2aH5-wQBX=&LevXY-$
zA+?>qxDpip@Y}1{*z>xFgwtdxbiPEgfIGj{+}^3lUHX`7WF&9yccnj!U}xJDA(`(W
zOK&A1;bg`_O0RVpW?hpn+#&q=sQu`On7SZ{dcDgI!382?i4wnFIJn0%IJ-ACOzy9z-Lm-ZL8>L{Ni#hP{H
zUx^S*P{5xGcAlml$=RRYy7YeV>t1E%_A0pf3mMG4tyuhZ>|2C@A6>onKa}rdmU;C1&aH*Tj)266I
zeq5W>ily!1;`zknq!EHz(RJpT+*sXfH%q>=xH70G)gRdG*;8=*o~)hu(0acbq|Lab
zQnoGmruSOJ#mUL<7F^LIxcp)xH=YOfJ|3Ro1Sv_htr@cn#baQX+Pk5
z!Tb4IsfQXCu>zwF&@?>wWO4#$;}
z%TdnE)2^t{zkE4x`Mgcc6OP?zfnVY86BTdMyi)y@Xn33ayJ}JNmGtl*O5KS|U1oMy
z^<$4--%^a{a7>h3WZWcKRX$Ob&%6FuDNdJqgp?)ngWjc^5!?j}gKj?e%wDGE#ST8M
zKR**8nb$e6wIWf^5*)w#lw|nxyLS@Hk+pY)8DopBP2b(hj7YI&ctUHOAkiLrNHrGk
zYfbRv?E7T;k=dd>G2n{uC!U464V8VfAj;XW+)wa%x()Xuv2blso{v|KF35d(@=(&6
zDnD8G!MN(U&i#wIC6~T1b0&7(mbnrjhERj2R^#}mhXGY
zHN}`aztt&<^oMQ^2@hQ!ve&0vWigF%Q`u#YN*eCc_qyBsyfrE4T~PW_^0dZa>A1lW
zZ|yY>`
zc&pH>F!!}t93qZ3PVG7mvyMc~J$bw7zOU~tX|jqXG{0<4gJvICzv*D_V;{_mc!8y~
zWZfRKd$0cfRaemuyQc3FNpvNG!=l3$!}cX{C3`=fi80mPbujobmYFS%yXhuA9{T?2
zvx#}+3y;jgW#Q%D%fr1=nO35N+V}O*@86hK)!ug>wEtdD)A*y-!WlaLVK~N`!Rbz|
znX~U#EM4l|*!FH)qYv8e5!JobT-7OKnN{Z1fsk8}w{9^Izp3fE;>iz?IyaNa#&N$X
z(}}poOluQI|EV0C{zj%Lc%uU3bnNpWM~5{^sjyv4?W$UiZK7@Vf+Y{a;LWgI>CMv0
zK4r&7@0u+cjD~PoY+CGiaraVz02Yhq_q4=JO1>2R>L2a%sP_%CySP-mdA@n})QkKd
z`GZQaQIeN}@BVOqGWp)VU7L=$w!V~uL3JGWJ!}727|BHE!FtjZ6&v-buzR6`XGUz=
zyU{TT({s6oOPOmd;p1w@#!bA$TxAC?sVSjpx@ERyxU-L^y>t?Dekz)!6Z}J#pZrQf56cAdOwvQSvpTp!dG6z8lLte5y9D#+&s89#oO
zxv{o^*jT>+k6yj3#&t1KFR_QyV?!{23@ii>OztmBFVt2ZEVxoIrV4uP_bOFQDnV5(
z;U>~%d*(Xvy0fOOVDwT)O*E1Tb6rY$9ewxfT~FJJZ*s5LSQWTVe8{-0ZNBuqlzPSS
zO5+OQw)7poB(t|WZ-kRZ{9?$IdsKAl$UdYxf_g4>ffHx=E?qH+ZnB?cN1oJsdy3J
z$AfWPWP5Y-v3D^Kx2bl9Ou5!Fzd%ZZ&TeL_i&vA}W0Y1n?>B)As@L<8$Ipk<4_<6O
zuzqT7^s|NUyTPuO#5?|Mm~}=^eZ+7MV+0cDN1wlXvXA1^1%9di7NLg>%vLs#PtPPU{3KQTRG
ztQX$4_~`HxbI*FB*=uhzW-}r7Tx{R*{iDuqHX@^=kh|qCq}{RpFa6aaT+j1V{1f;0
ztxgAp4234*Rd&^a<_ECRuSSjns)lY)v@EMFX23TrC+fes_YO(0p<~eCN~-cnO9&YG
z{tz$o6VZcvfku10AJ;|wY*+pMEi;o-Qex!(h@l&|yYTdpoyKPBu=#|!Yg0NzU~bpB
z#V3#$zt6(s671sYpFyzDj~e5{$@mu&5ZeYTI$AsKJDGlB{%Hi#z~sP_edz@ZF0gR7
zam|)cdD?N3hCP0LY)|{By*_eX)zdc6z{OxHT#wQ$<2ZBgRAw8Er>v$kX1OO{zbLx%
z?E6m?mx>xJzB}HJrAL0Z%-*Iad%-rr3Uqf_8TY*`$x%BZS0*IG`>-oLOpLPsFdOtN
zKDg$0>)t^mHJEAlba`j$#F#J^87t3}DSQBSac7?J+xHq+vNd@K&q8#!z)sA5G&JJW
z(H^sp+6F@m0=6cqTg^p0m}b|JVi@6{?h~NnK!&|u0{UqEh`8=Y*j1u?$Yv4nZeyd5
z>vJI{fgwS`FIg^Mp*+B4r+zoRv+hOq&+N35>w9XQ-VF=sL2!9S6ph&#~h-^=G-<)DA4iHy)$r^ILxLmFNe?GOx&*BOxh}4
z?$^sD>@Mx?eBbv%!34rSM>^P(ZtVGytUM!p`gm@SZb2L)*T9}pSDx`H)TY-|S7?@G
zq&?H6r4K~)iFN$ea#_M{#RelCn)79)7{%cj&YoeVh1l~taxeXZgW-ZC>=NV~>a%Ec
zOAVYb%y@lGh$LQnEK9`b;Y-ICaishR2hJ>VRAMNpcwh)#vdi)is4rsdpQt-%X_4>)
z%NIz_k=`Vs0G3FBw>&BHzn4`>c}d9s{7yzf66H*C?qAzz1K($_H^BRBpTFPaZzD-4
zfxoT*?|?kA|JnMYavu5rER#J2){#6gP*PV1z71@>?CssXojiPE%Gj-eA1*$7Wa>>q
z!g%NGO{%VcdjmK=+S%}l&l4?88CwsCu(h3sjlFOH(Ldvbqv_$fA9F`oTmRdr=;lp|32k^t@+oUaw2E9{$EY;x1Im|3N*Alm7K`GJ58SINjq2z
z=*L^m$~uO?HxOlKFH%w9gZJP35g}+U%H-6T`k%wR9`x|;i64G=3>?8aV{k!O}vP(`X6=5V~7uf&V
zM=c4dp4)|gy7dM2fxBeqlzlY~^e_Lz%K|Q+ojnHfk8gwYoQ!H%SXsRDWB%v={5H-h
z*V6vOI|lAmvGW2w{pejSb(MeCv}auq7RKB7PrCxxZsj^DS%FLmU-^Z9+!eqzbx8iR
zUi;HuEL@6;hMnSf7#{rd#w9BlKmX6~InVaog=p-%k|NH39w3T}*QWk?zg_To4Fn*|
zaI)dKf8MwkqHUP}Ka7j`%k1nGwi$0@{&|3$4GQvqe$W3qDE?XJ{qLaoXCvc(2gN_j
zX#YD?{Iluee`kt+G+l)M|2k7l8q805v`P5S1vlN0@hLmlUr6ZX$ql-~wYWEu+1;rm%d300N>NH^v|r)WO@4p=Ma59R1lq!(;1zd8hJ3!}br8(QVsy16
zv!1le5ZX>gE*
zzsW?Q8l4y>%Nvoz{n0afPyY1Cd$`g>WVlp^O>DI&N&DG(!~IhV6mh*}(?9n#*X1>e
zQcM0|asBqU%kSnX?$7CLWCB$i`@jRTAj=g3EH8Jl`q?GS6Jx~*`nWbt2g(F-#wsBTcNAP
zX+OFWxfUw46^^$ZK2tD>yTXx;(kpo{UduP}LlCPa3{uYu&V0kG=T=n{vk-=(nuUlY>{~I||tRgd`pL2~DwH@!52sjlkaP
z&6sa=YFPOnU$5%inj3x+a9G!|K^BXhwK-R}<>Ta=kb#XYXjn^{xj%g)4cyZoHb2w^%?lEGp
z0h1GG+&lN`Y7KJNtnT!L*a>PFsmOJ&z_$=k%j32Q5Op14X1Dj@KywDVFqE&)`As_W
zcz?U$I6||CErR4FVfC9lTLx+J!^%QWiF2yqp(>@S@vl@;m%6wTUWd{=dyzN210t@~
zIi%aCdh*()izYhT&TpAg7D4z|!
zB)|XEyMw{x9b3qL{_+=W%HCevDN=g<<3h%|=l091+M=N+Te+?^BHNv(M;L|KPgMpw
zpwX3^>L7)~w=m(hg?QOtBz$vo_5p*k-?HTDHoN>M$93`29|tHs1m;h#%lkmzX+*Jw1n?oG3v2G)
zJB|fkHkR2QP|_Hr&9mqpQBPOaIcJ=%8typDe>S>}wkos=!gvWs*^-{Q!Mnf5+Q$5v
zXZ)s8fH+9|!Z&6WdK}raEZ{$~16@VnYN%72k{ZLcD>UAJM*L)B4P3iRXuL(C+)yML
zck5~_zwY+eYV@ZW$3o^|mFk?JmT<*wr6_;qL7yvR7YwPMq2Sx^-pDt!O9wyPEUD?Z
zpvgPsISJcj;XU?aM8>pUqkspri6PJo-+z};t`3=41*e3l!1MLP?c1#H*lg{$EyY*~z
z=B*wTo48{?E^y;xJ8yZve)YWgN7G!0YpR(GpV+9OL35obFi?Fug*SQfmh&qh+@B6m
zy*G;@I##jXFzU+g3YjNQA5O#%k0lWlS0#6KvW4?^
zcWaHVWA+7~NJW1+rV>!UzbdsJ^%RCipYfkV%H_7a{#N)Y_3b8i9Mk;8xI^GTE}sDSaG
zarNWI7iz6-^7m3nT=Dlg*UP(zou^ty!?`DR1$lG?K}@!P&IAAfx?%KROAcUSWpC;h|^uemIS_(s(&!Sb$zE$Va
zjI{iq7HOq#nktADb}_c_?1;2X+PS~>zWqmeX^z=lQ;-Jzz4lp5_{V
zch~k8&(qP$)SNFVX}d~Rn-i<=@@>_4SMM(bA|#vf5vhAx9wnDhM>o@VfnnE)EdQ>6
zm|#}$tpcCa>+sp*IV#d+n(;#`cL%Ej#q4$If+kbv0v2cqN#m0yl$UN@hxf4(v3TZ;
zgKYoVS6aTU`uzqn@IzRtOUc^UC*S(vX}mbq6G^>KnNR>RN9G%uJ=@e%MJ(_u@ixJf5D4UqW(3$H7&+}(NlCJ4nhSFeuVcg*%R?pVvu`6Mws
z8%TioAb*yaZMAIO=`2K#r@+nE=1w-E6bxq!YC|iffFKp?{Y=Sbk)wrHc2CgNBS|#{
zFiB4++E?j=zlY@uAaagW(Oi!Q1@?Xb9bpPCnNjtzQU_Tdygez&L1Bv>8m%&$ES7NG
z06O&Fwj1*2W`PHnj~y2{#Ot7Zi?dUsbS8b9w-|i;MvskWsDlAu{tJgYSkCNU$%Uz8
z0u{wHr{U{TX=C3}X+w%$L~v2LNn+a!kn)nR0y`X+FV~h9_$VEi<<2HO
z^aW*}#{lkNe`Csyh!$3XQ*O#%ZrB+!FYWUOQ0?#K%M_Z)1(_a8K_BEyYk|yQvIKG(
z$n(niei`Ij$_j<;V2v6qe2Ros6kexn7nyH&w=EVJ%w6%|S(Y532##E4mQy`%r
zn=yK&Rh`P_c@8}rK$iN3Awd_8?E^K+Ex1g*$I8d+6!xhFPrLN5xtaVt2GaecO=r79
zkGmK(UMJ&ZvqvOt+sAXe&|SsUP%ZmvA=~|K;wq4Wbj@tzBr2BcSY;AaN#*?-K3nHt
zrsp3QC@3pb8KxLv#94CR@*P^2xPV6msOGi%ZidQlc5xxM6o5MGj@6Wah*knwf`;Ck
z2DJIsN>Dz&5Zv89V4@wkuH6z>kp)dI1_$r>TS2Q`oesq3D1#5oqFPbyi`FBfM9;4B
zQA}WiZ{3_#?0t;CFL8f2+@YyOH&bfs7&YOIfahe48Fdovpqnxt0&}gXN}ir~%XKv!
zg=oK&0+X1)e&0cI`8zv9%t-!9Y|HET9so!CLM0j+3+pi%4oyp5)+bU!Zn8@aEEqkw
zTu_qyu6HWzu-mqO6dFwF(s*pBU?sgJzh|yCH-L79ZNEwN7z>zG=gBr~5W&i8rxp=*
zU9RrUrI>)z?^Fh)x1H?38K8IIxrHQeV%l)>PwwH{PEVGgKEXwh;_M_C%dO6Fo;V4Rg4ET|%9DH4FGJ|jX~eRo7b6EHy`^Ij%1-vEFrnk|TunrNC;%Q|
zE$mHF7pC){3l)@Bznw@{z@<3q5u`rHT1tt?*0?+S-gPz@qkcO;cQ>EpZRj!1s<^B(
zYs7vu&cioqT_a!ev0tD&F6$P*$1!j2orB3kU|QUCC}zV4k&1P)g$6-SRxWPksi(3t
z*-vXKCa2Ch6~?vN5A|N9cs7yj$J}Kr+km5KKt2b(#jg>oK9N`{T1+C!Zb{7s*owaC
zY|_>;*obP>$@EzmYJ#jpvCk-O7bkM5!93XAPzTGX30Li&!b=h+x(f*voj_1qH6gFv
z^6uh@3czepC@&eEjSwU0gnP;$4k+%{WTOj(vhxiJkc!R=*p?4@!6t7DWOv}C$mEGK
zvJ~3$Ys@2x#gCUZ0nBtAG-&A$reKMDUa%>TnLLb$!fQ9ULy2Wt*s9w@m;w7O_paNk42i!+e#aRq7%
zy;~}QAPT+dyAyKD%Vp^RjL+)aLv!{WSkB0=%fCVUF}Z9x?8Z6tt-7-$Em-=t`u8Ma
zptAi0tox1O*J_}9U&CASy_02+{o9Dyds)UJ?2n;E(&)top_ZM#!t9Kh_^m1vCk3qq
z9Af`l-H4cBjvR`-{57;bck^OOUHU@irdHSK;b6ANEWcYipIMuBC*qaX<-t@~1
z*rM9zo8;je33h%s9<5(=F?t9jI+Odz-Q%zdH)gkCn$yW+-dEq=8a!0f6z#ok=|5vM
zB$3@eBPE2rQ&D99md~f^vG;3{0->#LF+;d9%ZsGG!z_#+eT5Ym^F^*E$`B)nfeNXe
zg)_ZkUdx%NXlWMX#W_$yhRT#e};jZ1QPM-$y$r)`?>3Yx+}08V9;|G;Br+_1ZHt#Lw$
zXpqs^uvK(%v35(iaolEB@e6>V8r>TrCz&AW)A>1Hv`PR>Fd^%)P4!CugTEqP3dP!B
zs8B2yADi!OlM|WmRWhM!)GyalaD*+^g-U>uhl1E>mT>N3JKxL)!Inri%+HY@2Vh7R
zX3xZmaLWZ#g*mEmXY*(4a-I88*qcOD9rH$*E6fF$un-`on{pnQW6PP;yS=(-jr=@3
ztn=CLnA92GH%l83)c`3ic{U}$7QQb;3R!{irAIM>
zr9vLn`K;%+4sw9{)Kg??{R8&0oO1~wpXzq^TZatil9(eOAt7^$&fDn1e(VGksQakT
ztMWy+TWTY{5vz+yIyL)5V{^#TN%J<&>J)M0PZ6;Er9a61>4C9@d+N2mR
zM_#MCio7!FV8pr%4dQpquqnEbd#y5#oOJ7B0Q@_2dbNk5#+NL{C^;Vvw
zEMK=$HeXJ0ECb7@4b%@be}Tl-FF-^0_&!`uR!ri2%sT;E6m|4N5~_N
zTOwg`Df%l>@9Y$l5$(puRlZ(j%+}vC?bhXBGrAu%@Vd;+J)_Jfd8YT~KH6v<@pxMb
zt^+{m&hZ6|Ks&&GKdFuMqlwlhRf3e@$4mYd&yE?5CjAdNLZ`UDqi>Y}A^m>wtp;q$
zcTj~%h$Ub?{EqMGX)IFzK4~`;gWaWy)(J7ZTkYWEc~I16D+brP3
z>-jLAz{u90k<6`A;dqt18dE&M!I-bDv~|hD?uF2_I}@y^{`^gsvjlOLjwiSqqsLvydWE|_-H4mE8HHo&7N2}sEV0=DtB
zb0mQ4Q}>Qa8b|hCQZPRG6bROGrv#$^ZO_MC-tb2mEf79sFHaB
zxI6p%J{eqqM?qHb?gVX`{I*@YnQOICpMVcX{%XDDZtdx7n)k>-4Cva6)
z=aMzRL44z1w6LC>(h0ECXCe*~ZHQY|-n|l)%cHJ?Z`I+$8q3W9XUpvvs}L0ut$tn^
zQrp331a)Bncmuxq2L>!vu
z@HwX)wSGR&oc!(e4TIWlKiX(Br~HUkNPZYw=8zjX)T6Xv5)994Io_S>(MiHC4*(^{
z&*~^LylMg~r1CBQCy%eumuFjpNHy7lxAoLnDXA@P9)gG{KPY1kb$!+4pW)VJ5~R2k(s
z#4|&itn`*Napec~BCCP^Tu2riad}XU&C(Z=;fF+s*fzxqDuKkyTqEr^Ef6tAjam-_(hq?RqsMlJ*Y?9Sb?!(GF)q9S*G!jY%1oy{DjvSGvkth2l6lw
z$Qyv-0o|(wgtF=aHQ}8rrIZyx#C)QtcC~GaWg`P-ptUK%Y{zBUBC(`5cxw^Ka?MC#
z&fgM3*=s>(notj900pHpCJ~^yUjSoZCO?Ijiwq(-0Jl;gsASGs&p07~0o)1|s{MLp
zsp=uql?>L$J0T>pJ0k{_W0mufx=jnA`|WHM%O?J_xuGY}<_pXot)8QD2vO)tepL6?
zcw(kIqP$23aq1(+n|`yI{o*nG!g=M@9hcpL36`1<-Tc23roQjsRQtOH;A@u4fF>r`
z&+5Wu`A&fTPWs!KlBo|X!M~y0nQ)J?-IiZ50u}Bnd>4dAARB2`A?f7-ICvWhy#Xi;
z8rfDEieG`0KRe}IhTo|l1DGa!wbcrDBFyUppO&R?^WqgaZXjO?BFUhH92096T3MBo
ziU41%DE&EIq*!kUKCD7lO1zCJQ<~htjTWI~R+h^}kbpw<8B97IR>p}--hKDP@Wv)p
z^w8COnc3rwb~>XGm1I!8!s_+oqpg0EzU$grS
zmpCgx7@6H{hBvliD=J&J#$l^+DrK)+^<`BS?D~CbtPP)$K(^|Wr$j8;x~N8qNq0&=Fp$IO+FV-Tz#v;oD-
zFC_ABn)jgujCKem0X@}olTX-3Qfi-P-qeB>Yj6J2$=$K7(#og4s6|%{QwW0~cgBox
zJ3IWgTPFRIDE1pW&+L;B5__X6OyyIMCd<`B99*Pa_P44&*B{_L9mY#Ra?rhUUhH;{
zKd=Eb%`=djsv(j1;$tRZ<7Yb(${MusdEHGbfr!n>Y6KXnG#{lNEkIGQTMegVE!*D%
z0$g%{$zV~$7tJl#kBC{hW!8Q3s?m59aUl2V-<*~3bJ@EI??_snl
zN;AKSW9b0m(YZV6m^AeY>^#p+p>P{B=z4flOJ#%ua$`h5@57~ghx0G!o|`)5Y6}c&~QNbAq69;oe~RxUBi&>5J*
zL)h}0of~ycZw@5_RJ);X&BzWMR(s*jPC%ku8@3MQ=+ZpkXNa>%+H0)xTAb1DHYiWT
ze~gCN|7Nk;{C1*a-meSI0J$&Dgs7y5RadMlysRMv6AisGz=PGZP0U*P=<3_#WxP=yaG~mf~eE$Y3a{~7O
z3Ona5tnI?_R*E-JaR@Ly&}lhXR@XLv8cy*TQJaTuAEkcdviSV=w$f{6dS4)I8>e_q
zI+s>s@044VJ1HY0oO0|ymt@!8Z@T46QXy6Kpoh=3&x{LRIndWDYVM|R)FJk>$%}Gu
zKC9;@?+akQW_JPLO{EKYiY2`217EM?n?1jqE`e6_FNI1Y<*!Q7-_x?3K3e+-n?5sB
zJf>=t1AGg=8moN^MQ_j-2L&NLo!QI|+u%x%P
zW~!dO({7+fS=P>D^mv#
z__P!atG%^mr@YE8_0}i#*8K_V2moZD8rR}zhQ|Otq&1$|Jw4O8%{X;fsE&n>f}3w#
zEnJ^!U;1Q!!S%cr-+tL(Q4WGZbLqs}${W923NB+bbK)S#ukSLh3m1CM;Pm>xU>}?S
zq6>c;XMeWHgzf$rrE#)#R(@JKZW5c|r4?S>6ba%t>6Zkw#iroB@Uh_dqBL-WkpPgN
zD;iL+(4O|vS()v#*oO7OhJpb(bbI$(Zi!n4k55&F?;kRx4AsaqXKwK*0>TAOY4&}n!A%N>b%ECoxp+)qd
z*CWIL0O9#X00_qcAiQ;hVqw2q&m)6q*y?_?pOaCZ5(TpzyejH}Iw)!4kF$95G9=oQ
zyg(ALFad-|6Ckc2UEGGXq=ZBmUAT5)7#;)5mPV$Vm!iGU)xxX6aCt-GN~ar$!qjk+
z;?xQ0Y?WR*f6AOU_RDQ)Hd~-BQ(Wc76{4?CCYK2Nfk7%T
zz$4VDQ(GZ$Vuxyw2Xetfo!uEICi^%4PDQm{&SV-;GAfxDMMgo<`C!tK*i@0SO7OEh
z*u_U=EKg8D$Lgc8l|Nw
z09qI^qDB4%EvgAG{L*z%_%X0$Gg}Y;;z-O^u-=@N5xn&ek*Bf-gl|8>qiaelE@ybg
zUTL9Pezs+)3)h;x=kMF}y5XCz);qbja>_EZ)o;umRc5MCfHtGbc8wWNosn4_)t2n9
zpYqh(p~9DPSedV@Mmghd@aup(<60--D_&!p!GLg!1Tj^18qG-?fmm=Up5KoRJ{vTU
zCAp+<;O8C^1FCnc(wbPQd~k(gAS?#tBpnZ{5cPfqK6fV2WGirf#}c{p`g7^SMy})j#w|hIQnPip_@4lKE`)
z!M+tzLN_#vN>{cG-ymdbnyQHYp!8oY2cumS>MK##rPy5}7>vvK(@I7)T&o+5N4?e~
zg3IF8k$baG$DBioXoQd26nMMT;bK0gajYQ3vJK!13^uYHVNA2|Qtw^LIIyiF)$?fm
z9oh85og}e4&4GC!2xa8{98D6&qU8jpgk*iFaPtn@7qHBI
zh1dC(3Md-G*-d>%jRcm_u1Y?Ao}r&=dz#_>MyCH)%%;L1PkM}YE)<*1QR44$M4ctw
z=>*q_$4j~LRoH&TRhW#yLN+1`Wu0j4-%OgSaPOr9`uXwou)
z^;^9?m&1eDGt))`OknzBzu)YKB`;XaM*HQp#*|qlqLui)C%0Oc?{NGL
zP|LHYFocCvq%S)egm%5!P9MpP4;j#0b|x>_ZdWUdDg!REWTZ<08Pl8gEuO_3akSZ^(RPgY&;b0V8b+pX
z?S~yHF5JoGb_JkAFWud`4XHvl`eI`#lg`-z;K2;(CFJ2#df>Aj2G%=E>;Q=N24uw>Pkr#{m
z4qh#y;?`WYRj6#@MKWrG`uIL65i5@~Sq_2XB!og?0=lNFgU9awr2d2eN`;0e?d4rE
zBLc6nwm63`3p&F{c!P8eSRD;OsFJ`U6rtf0xy439gfyz1al4G5ib
z9nxr_K&K$U#0H=A+Yx_HEPUPQOk9A6tavtgvgB^d(D`Sugq|Mn2^cfW2s?my811j~
zJ61#L%RU&AoR@#uow-BIv();F3#Jq78N6IN{(xOTC0aOR9}K>pq1`HCftaJ^P?b}ySlXRKp+In*QiEP~5!zr1I%Ay?RyNRF5)Co+<*mpb`gfqZ
zHaJ$d75{g+X4*4w0zq5)S5JCeTd{?|zz41CDvapJtQHyd;9Ix)*4>&DT&?`}AhIEV
zzGP>X2J7@9jNXBRlHee%UB)_~+%-w&IoQ*T=zg#Jmw#yN0`P75@p+o-PnksMVrAr0
zOmrQKcynbcs}H^FFcxz!ik#P*j2XVB)5{n~#Qz4c?B%~$wje!>w`X?EFE0p))Iqco
zP>PMc;y4r8Nyug%01s}h4?Ir394^T?&@#Pamx#Ra>k`9$;##8_JP|w9Y0TPS<>4>DBGm{~use_0nl$~U&nr7G0~2GDOHTVG*(%OlIR##JO`Q$5=B3m-
z6fY<4-H8Hhu8%rgf>mK1IU>ae9Nay!oxZl(4{W}FK!EclU3P88OmzGw8B8qnjA~#~
zR~cTXRmIAm=^1`?eZH;0#Zyoo!X)+5=>QjX3?Mh0=VyEr)b#%Xzge=$Xzr#b5z5Q{7|y-1gr{EA4@-8BaZpzo%LhY)bl$D1eKlJJ
zgzR0!MZK`n
z{OBK1ngK&BK($Tw3MHH+$^`7&|EalLYpf@|5iOb-zl~W5Mmd~)Q~5B5gBsRu0cp^-
zi)WKRX7S$l*=u-z43I7X8M?K}KBcA1&*d*)usdugTXK-q2r$701X36T(su^Q(*VOD(cB*
z$`*isbq)w-xn%a!$KYU(r!3n5o=JDc%+y^Y}#h6Jtk
zM!2W+gdtowL*zzRo}7=t0O(}=NPHVfb^989@h9y$tz5hG9aEhH2d%R(O%H;f7z9tF
z8E$zoOwR#-gdpxl;*}HeCwQ
zNs|E|g0s`JPDMfwG>k4k>{K}`m81es+nd
z{hb?fSk9lR`=&M38BkaNDKDbGF5BX@YU2VYHpO1SwD1sO@844y@>&OD{!sWZ!q-|FqwA;5*t!>D3n)EzA;$^UGD#Y1_v4iOh6tX_js%#
zz+ZoVPpzAM&zlRw^#V!-@y*yc3l^0lvO1kHz1%RJ;aX#w1L~=*h;IBL+b_8D*t>?e
z9q?1^`Q;fg>9rNWqlR)Y%z5_4{~~EEfV3&>K}Hp(xW_a=M~Rvz3mhzEE~UCPgu^9+
z1Mv+*7T&!}$ous@PGvmlK_JcMt#MBzl|XuZ6_5~LH4n5qL~k~Mc4!#Nv=b*FHA=z*(CD4tA1DXpe*uw^~+5Y{*8
zm>cZI$e;uY#s(TW0Ev~F$0~j4uw`LgKwiMu45K7~)vdg6=E3wo9sF%B74f!w?8KJ5
zAg0D3!`3Fz{=#wBWS78Jeg8{+J$rbQ!kwO^KT$hv2OSOp`wXfer&?!neOb|-LnT_0
z6Gh8MW_^1LMk^nmRN`?n^Fm)lHKgqglufIk)%o!Yjev(q45<83f|o4+sLWAWG4gYj
zaWRJ{6|E4L-Loma5VnZ)h@7+-Rw|!G{S;1H&RXxA>k0sDdC=UZ*!`NEF)cd5mtd6{
zz_qa1FnZ>8bWOB
z`zN_)2nFl=A3YcNKM2|o8w55el$+^b*nsMJo~9r_xdUCj%V*{Yvv$s4mui#H9%2?V
zqQ5e*qQdc>Gg}@0=Oq9FZ*Nwe>2YT~mqWP;(p%+5_27e%OG0
zQt6xc_mN|#vj@8!wx2MPp6e#l0qrF3oqrX`QMw*3HU9L)(E9&j?=7R^+OoCb69NYd
zk^mt%L~scn9D=(Rg_Gd!T7?9X;1*nq;10pHs1Sl%aQEO+!5zL$(zpBE?zeB}{`-F1
zj2am=Ms2pNHP>8oKJ$6zZbTaB00k>JG1ScmjaTsOd(6t^P7nmThsI%1PvJI^aR~6r
z6I_PHh|!zDMw6GbZ|H?^R<^3;c(F?xHVd7o6YQw(Q3_6wUFL{lomgtmUo5QwvY;U#
zg|jJAqrBdW^gYzcXENYr_|y?Uk87G?kPonoV9~JN>YnT?8ndF3n!;{%&n<>*pf<-8MqVJ?S##=_qKCmVWLFR1Vf|7AS{B{1YBW@e`d@_b&%iWFvi
zZ_tqerfA?b+8ULd&YyZ=nVXW|l@isUWe8-|K+UmY6OA!;4hWALI_h-pfHJ&x4mC$w
zN_%)?W9+2pZ~$lj$CPm>Ve3go=Z!ewHricJL%&$Q>S)uP5M?+JL^F;IBp?P>WMZv4+r(PV>&J45be5
zxZiiL=UOh|pCfjh>%VA(kg^Fx8cZ4wIA&xZ{oZ|V>btEOun-R_jTL{`d4Yr!+|xc*
z*FBaBu-r<@5j=_@ldLkle_MN7)^SQNPv@O+XpJuAwNb+#eskw;(}A_&2>kgoedLs2
zwD^fwf(l+IR;n6)0OcVNH|olD!4hW#i5?AF$Q|1_Exsp)RLUG@m%_GYxNaFSBL@JT
z)#WC2D#Iw_9u+BO5F@Z0Buk0$bIuN}ENcO>Ts9QINs?H!MB=^W%8*h!yuisYaS;^t-0FZBJVTFEOWBQQt;cOMj-04
z*;{(OE{gy(6tN@LeE?J1a4529bFmA&t8JcE{aD0X3*bpM9W?Y90%-1@lcjHvDjqgt
zOiG|YY07KJ=0MtNgthj{Vs0ku@r>)c_CP!;O0VQe7IzChW!^?*${MI>EQ*jFfS$8S
z{}(t`S{s%JDE1b3ay(;%1ONh&|LM%pgd>_{8f3E|=N8rGviL@A&->lY08MI4?&!D$
zsEU`4ExF!|h47CsO3?pkJ6{i8RH4pDlNKk#&v7Nv&V%e^RIK0D-a>GL7`xf}uD{#S
zW$e7c
zoGI_hQKzg=o?zq=<1|1Ar1BE-&fmqN9D)m{tO0UG&AnF{jj5Ctl?Rsjfs8w?N?qQ0
zKvEAX^OoOQDCO+&cydRzTLif?9?z#J8oPRg2JHl&P>%|HRFpNYWvQ5XQhoN<0`mPQ
zQeW|~>fCngdcE=1raVWmlT#|li>kct+X8@r_Ga9w-r^KD2kgX6MdK=@iBb*
z2`}@~#jA&br53+R0$m4UB?H<6CvJ_M7Z*i+YR?mD#sS;Jx%$4u^1K$xn#H`O5Jld5zPqUG*Q3bv2h46Yq?`GQHOK~8t5&l(HN
zQ|0NX?{34MKpX&6D)MMYX1izygFV99cPxk47NtmLqr?JyN<4C@uMx
z`JYIhjcD6mt^w6;Kn)x*K9w98fc0>MXFHdOa~v3p6NMq1Erb0&+Yh
zSJeW_M6UzdyP2_w20U;ievAT#Y+(~f7|ztdVs*cJ~=a>DeaRGp=m_SlB3S+zlCzyDaMrg@14GO0V{&S1B4}g3mNq
z=)qs50o*;%WVN;E$n^!%aHy!qDyM2%6n4uhh!i@WNLFs1Jk|mfpK?e*c?+r@8j;+g
z+>D-CwGV_tjuHylhm3Uy7`SV>ZB#;KMWDm24BkFoP@
z&m#~g9vgp301mFI<7;O3w-A72@Dl*2jd_fc8S8tSSoKTU6Lrr~?_-)wQGIb&rQHY~nX$P2%%zh(p-xWVQ}xA@Mk
zOUK`BjUF~zGaY>_hS40!r2|6Ix=r!|s@YlVc;@L3Eb0c+75hw?X|eY4J1+(x+{;D#
zd5S;xW6QsAVF)#{kX+%16C+vDkv&dO)NzD`h6pnHw
z3j-O$kcPS<$UwOQUE9zHkO@0^`WR|++4`Y9r1u7jEuc`|C6#K2y9A`ak}%0zb3L<$
z%Zh
zh2x@mK4n8a(k`pte#89&Ae(&&
zwYeKeKzZuCv6k*z6Y3cVd8}DBtPAKs{XH2(MvWVHYM5pLka5myTjB_#3Q)&E>}8m!
zfX5?y*&r6r>|25UG^H#6>)ixUx|XYkd{#;5KNk}t7R)#VIHZ~-;1z(C$+%>ssZ6+A
z-a*N2h?!63bSv()>`i2!%PjEro=${37z!_Aw!AtTKRJIo-R(10#0XRfGolS}vh!Bv
z0C~1Xk*x_?r?o(dYepFvKfn@;J{gT^;Hv^=EdgMyliAM>jY&@Dz?@2sAd$C;(_y~=
z@@tt?Rr~I9!YB*u8i1?=nI71Mx-}QKYK~+WOjgZOd4B)!3?4mLUB1jOl~3k~cJCZT
zW;P{X2mA|_&AbOdvZj2jQ*Paj+mH;kaZd)
z4<(jE6Ch%RA0Vs84O&J`EH9)6f;}Gr3!!YtGqx?kzQoeghpKn!8_`b`44jUf-JvN%
zmf6AF1h;-}?eX&zJdO4>M)NWN$gmaX)&v;7Zah#h=;kfEB}Qrop5uDA;_$`-l)&O>
zh1t3EKk+E_Tq8!_qS|#=P}KKWH%;13u7V{57?8!&j+95;t>fn-WVr?A@%!0Ad8?B?
zlJS)=<9#HgPDMeqNA=&|3o416j@Q~y}|MoM_CnxZPxM^XDW#J5xrYs5bE}CZ5V~)cNrjiO<2QQZU0BTJi(22nqJB}OcdB~0AEX}Q8IGZ)E`ypKE
zn}q&Z@_KNI@gkdwxxf*23q^!$XRuMY>}=*jF5a
zmbK93kse_;qN!lNDz55kk*&aABM1nPR)Ja{C*UD@RDTo(8;m}J@$mwF
zZpYUAXHjC}a9~r-O6C;9mRl+q?qpP&qBsT_>wB?sPqNyudz6?*m++I(c5`XQuB7B0
zW;0;ti#%zepU91J-MWY!Bfi3?ycuQ}J@Lz=v{oQ|6XluKP#OktW~EZs)HWp|5PB8E
zFA^ty;_QM{9$#V{9+GF9wM8mVhPc=6)Q)!Kx&0WtjvDvYo8E1Z&ba_8)B7QVLQiMS
z2SsM7#;(RSvjKw*64ZVD!Hh!E2HkQj#S|u37Fcy%Dm-A${_1b;+Y2BToM|Km{DGp+
z_%WqSV5dsmtC9|~UsXWHrmu5fGvYHUZPY6I(5^(LXhVL{`spLWqZeio!six1zH*`g
zqJe~r>v^ukfrgWQ7TIov@h($FenIJ@`g`DY1u^+e=K
z2Fk?Y$Cv=S5Qr!bfC-ie1UvrPPX5|d?PCsbbJejaaWrp4b?zKdXHjNnf;n^a-<<&}
zkx(@L9rU4f*ECuPk%9gw08R+*CYA1n_5STP&@parL-7kA;x3OuVN{XmVTi{8ATQNe
zA%P3eN|bGJ$TOEq%*4Eh_>Z+JY;HUTYJ8y(FWO(V!e1x(TbC*QX8@xJ+*N7t>lXPH
zJ`Vd(k46dsEKAQmO&#B>qdq`GuJ25F9rQ~kNr(A!2wM3NF*Pci(Se_V^wRzq;QYVR
zg!CyFXoMI_@1|G++axc5e-t5=6~uqWd;je}9a`X`J^9-Af2F!Dm
zH~@Pw*R%Hu2#=Z!7S7*14n0
zoPcEeuOobW#dWz`;-6Z&>)+Zph@qq%-?c2Ek_PL$f}DXoKUtDkzv`_{RN=3_Zz_f#
zhx<?wrP_ECouI>#bWfh|9aE^=Eg8gh^eU=8!6;}rMLg?sJ{-8XbL7E
z=rY53>G&@r``;}7ufI|^0)*?y9jyodYOnw9X{Ho_QRcD64|)6h!#oKXVYgjJ^gjmv
zKYjaVcI%V0->Q)R{xEm40+Z<`5HIm>ANQYs@Z$ksgTg-2cT0aA$p87dMBRYNte7r;
z`ulTPl?05k?HDy7`tJ{O1vY@W%|<-?wQm32Wc+n5KlTC3$Exzrj2HiDaQ|UV|F>lR
zZ^``MlKKDjlJQ3YNSkj-1l)>AgdkOCK-tOvU=RH_y`rDjt>+z&nZbX4yP@SM8y!>uKTDZ6(dmEt{(4UM8=*8x_22LjZ%?---@$F8_h1#}G
z?w4QyVc4ax0y20`pxNJcYKSVq?>)~)vRlnE4r%aXH#R?F0}mQjp!Wsa3>-_z^7s5C
z&~zGb_;*P^Fjghp%I!ueWB>dupG?aPczxR9s{$FF<2W+ULO*DMeDm1_e(9o&=x_AC_VDOJe_lpOL
zU!!VvnmjbXL~zqoak&0geBtK?++Lx+Zh(`k?rq?2JFM#PTMxMY2XHw5$NOX@U-%Kt
zLtX;A9ffUnO)g}d9X8&DxwSp-283_MY?@nNsWZkghHyDX2KQ!(|Ct1|)=Zo+r2-;o
z4v1!$=rpF@<-*%l1QJe_U|n`J#*IC|qdOhv*m=N~2nE(3>-fW->+WLsgpn;+3hS5P
z`hN<1xNg_)6CDZ;q#T)n5x~b?E1bGK*uOU0t{1Zm
zA04^RCy}N5@RzQYttNFa^Ns86ovPb6n;KA@Wo+D+^sz;B7n(%}Lp@k36ueF<2YQiZ
z&HO!?dmNm{8^--qT=WO~%s{4rbtrN{&gs;fSO>Y8umxAHZ&%jpgCZY!!95SF$CsQa
z06$_jY#MLZ$e~94ABXtkePDP6bs|NsVD;ziH<0V4^uxd_O`e0}w6U8Go>Z&5ndb`J
zNqpyc*0J(+Lr%_#K>wQT%Sm1i$o31)Q^QsuxADDy<9TigO%gvbY~!`|oC<9f<{{R*
zwmEYy`5=VOYJJYaQ|TU0<$K;Hcs&ALL8Q4H8%x2Z7+lpvM_S98t*$+;a2(;s`o7+r
zuU6ug_Jr8#zutr1+~wSO8k5+FCo*%GYO>@3p}d);IKp+lMA-GGjv6`lzGj_qP3Y~Z
zq((`j|G3bOqb&Tabn2@RBoP`Z_;}8Dx}+4rx5a$0H?h}oD1S0B%lu-ict=yB`#%Tj
zTu*@tNZ?kxt|2>}bPJE=u%x-IS-f_|#pN5DyP0Nbo^s9?t_Vd?Uu4!?QYramX8lV4
zc;CtVjfR0)d{Qo#_@Cqb%gurF?12EePwPIl>uH|5_FTv&f#$V1
zC4hx<5FyYfa&wSg2TRy3mnKYo9!hf3is$&MZ2)m;G-5q6DS*^)>ok_wYP?*OF03F0
z(s!ca+}&A$-Hbvbqr=x(Ip<06aa}gPqyY?tZzuz}RCc&^OWhN%nv={qz}wZ}X-}`c
zofnl|1$pf&YGuwRl%Clee2zXX@wVXC|Jl$9-U0gp%#6|rnX+1Zkj{9s(vj}NW9WS)
zesJ$HI$Qm2rkfyAkn?g_)vVAUCWQuQ4}wm;;p!Qv=d9RUK0Rff
zlm<40KUB2y1=tNetLrItAqOeNYfo3_oG(qZdeoD!@yL6PA_`5#+E
z?CMRYLGJ4U$i%y4O^mGLmzBLXtU%v`8m1>`zxsXrdlz>HmGst?zMlxB^0wre_i+$h
z1G?ziz?zDn2-4yYZ}QQp$X?^}ZNe&|HxY*qDiib4ub#ukEJR021z3%bLkvO_q&L3;
z9RAL#Nz1$r!6KHXPkff2YxYj(k@e$xCtnHnPR|3v04;suN@#82lNgmmK}LQ
z`-L0NI_w&GQcTr*e9u=Ba!;~jk{IaHix<7*o*7F;kQhT0r-l`HS7LG4=2@}xDUA_V
zw79V;R{I9F1RryqyswYIs|gk+?FHwF!8+u;yysi?VGxxRpF##WJaNAr@4)
z=%WoQ%$ekN*I~aPVTs>ZcF%9sXr
zC~J<$E303BY!*$qY-m}%*07bVotxCq!FT(S)1lKuJsIi@vRT=f}c?^Gb&$4aSwXMV5FfcSK4
zB|g+}?PLjxjK|SfqtMhJ%~v=Y+8GeC-}UuO^gL?C3rA6k1r}{j@rxT2GXxILb0^lv
z`iGz2O2LuzJB`=pX2JDe#B6RNYVO3T%iiIpvl9@;XNCPh+!$Orn2-~moRSS%Gx=UJ
zV7*ADpTdPC^5vz^*&sF<&E7ssa4~0#WSWpJvsM2X?cdTr<49-!Dcav%nDRohX=d-L
zmYwrxL%qM1f^YwPYuQcZ^Dx7-t+{ZRe{U(|ko{mp*Piq!H;?Pq*N$fG_@?L2aULgi
z>kHQIQTbj^&Kw>NufBJm=Prx9?DRSw1v}0`W~aA@70t&CoiHoA)a1da^z}^R`vBuB
zmSq3S!76+}I8un{8`ln@dZJ;UfbxtPrvj*PJFEG!TkrUX_-ZrIH2DqVipX@;aB>{6
z9(CzOgs;ee*K>$V(-Z=a+~WKwt%v2MVCl!K9!j4HU?1>4u+zYe6Z6w{?t2a=scR=S
z+W~}(I+D)d((KTwXSyn)p9?1pxhp{xs6r3RDRS
z=S}g|wRCy2Rg%2t7rPBjo(qGEtAlj&oCD1-hQdM&#CdN7hm+#6z^yyY!yINy!O(1a
zNuNrtA@Px(vdEC`tJ1TbG5JJc^>Ad|T8X=q`^B65+Q3L2@a(A?+GfPnMbg83SBzR?8QY)r&npg*}vhUxCt^!b#&a
z*HnfZk@L3N`D6ln_^9CZIoXW}J3Egna&9#>&7I?*PtbXZtMSx_n}}ZI10n8=fvwdSo8=k8O%$LylVJKND#m6
z#XKpRjHRa`KTrkjg~&56UZ|@N3!i!ceYn$k+x%3jIdrUcn^$M%uS%^RqJ5`uyjpPj
zWH@?n5cTNg@rmEtOj~2x`SfrI(=>9wr!O$8!{es;%jH2z-aLfqI>mo{SNPIl7+TQ{
z3m<`wSk}%{qEmWu2GiPI7n$~Eq}V<@cOD)_zud8xg2`b$Z&*XH#ns;BJ?MfSbKP#S
zgf^PqVZGLd0w*wN?*bhx3@iWyGDg$VhR{A1DNnD6jl9qZvWqwo>!)Q-8YbQUF?m^!
z2a<;ziyG!TstBD6D#w2Bwbb@|r$OAh!v4xr$1)X5Y%UDKH3gJ-~Ne!)8my-le)}U^KOb`l;cu*Q`Aj
zQ1k^ywVSBE@>ew9{$%|8Rcn8YYd*}nM);t3e~B2`oTBYfGufT){X{p-(Ttov6T#r|
zg;*iez_ljS|9SI;qZd-83mkmq+8I?BNXmNyY*sVOBJ*C3QT1_
zM4>?ip4sQe^6-I|?zG><
z&F^gW@z|R^=@m}UHxo%_piN=M)l~mHu&r7qgjJ`;rd|WiW;&Vc=@p0(`Iw(7`}T=)
z)1DbQInQn&Rku8&jQQR=cQoTbkZM*~cft7DmD&51K0h*B4Vdy1EKz~)$=1D0R9=si
z!IPtRqy3jgo<#c(*kGY)SdwWzk1feN9&cMse1iKBasa$TK$ptbs4^&Uvu&#(Uw<|m
z{Av@F$kQiyG&0D;Z-2>OXPyOH9#KzL%mWD9j%Dh{&IaOeT8FnW$`N;GY+zGh4STre
ze*I!=7WmZL_=fOAq6R#|lm=*g$46o&D+l@GMp!pl
z_~rQWIIndnhx?iH;1hik{OZq5!$~COiC@AfIr|lOZP_^O=Pko?Z9ny2=9-&~$V{0n
zgs-N#cbxQd9A3}D0U6xNIO`o%yR#937>Je{{%1yPmPd#P1z*HM^F<#}341sInfvHx
z)>WU3H{~==MhYHamcG|4d|inmybH9b$q#Qw6tY$I-hYdpa91v3#tFM}PfZ@w2U%jN
zO%}L5(P^nSPo=?4RlDZd@!4xzc}1i+yw#yJH>c?uLGkwcqwbA}G%~b}Fkhgng8@9u|NTr2Xw2SsUzQNn
zt#OhOGQ0HW6{F#^e996^Pgk!p@hRBRlnC1NWcH5Kbfh8}Ss6L#wwVh=(HszprPI$8
zX!-h|dOljfNS3t;E%II!yhi$}7?{kq5%YFjnr-cyS2xzYo?cFXh)>y;RA;^FkX`a5
z?9F+_kJie-FtPcC-hvGod(S}~f23TM&sHVPpfX>S?}#I}O6QQYG3HN==6?18Z`&+&
zC5DsO+@qspm!Z?q_nS$q{Ne4gaH#&_!ri?h%vuAVvps^Wn*(NPK6R=81YCTa{<&*!
zBm*i>v(2tPJ~~^Ahq@kK$_(cp&gzCKd2X7w!aa71il2ioPY5NuOyf)M1z~|i{ZxIg
zTQ|+RB!>|V#lt9>gxMLdaB{rI4d>})UdrBK!zxwz^i_Y*x)!3OCqU0&Kp%L+>hnX)
z`K&eaD__A$D%0^)rCn))(B-H4?=68#XN1KL-`eBg2Tgl}9fMob*Y{5jGn1nIWFV#~
z2D4^{Ej0_pmB|Nx;&MS;VJQ*K8?;&D;S4xhmd`4Ye{Ln*6jPdw42MPggIK3*!C91$
z=#5J#l57*;yL0xthAO!
zbyFe@pf}nAyC(5T=DVkrSIVXu+BcE#$~Os9T3M%oTWzzm47*B>Y-%%UFa2I-bTYB9
zpy|xa0{JHF(pHu)N|bZ`UVFR-@wg6Bl`4XVs&
z;~@%TLtoMp8RY=_bfJ{PLe0Ku^(>JH@z2%fdd^UA3NlZ5e8@pxa|dlWXL!bYv#{d&
z^~02pxcaZ=0~-6I0&uodgCY#-AMfNTske%!a%MJ5?Ul(G*;dtE~Z^>FVOIKL|kfU+T6Waq<(1F
ztmlj?P#D1w#Zz(#Lcmt`(#-o~?-JjDZ08f0nC4dp><`}_jD&~>jxK;|4KA*!UVYD2!25)~k5NkKNA{
z3qrqt%DO1<-r>aE_F`jr$od+En@1SptFG8>+GDm2)pR%!6coVQ`dvFA{%I!$fSuH^
z+A|LdK7Nr_U{X!8|9!(c_z_LtrcLChO&eidkJl=T|Ai=H8pMF$GZvlYk!wCA>FvW!8(ik!H-y*%I#TG8@=UgVCT}H
zvjpmHX4ox9a_E!HYggeq)at}j?RW1+{AJiJBG}1zyHjVO8lc>-!KVJJE~Z52H&=8uSNtU@A($+#%XVa{G+c-i{NPn_3vLttvB^%8Np+zpPULg
zP(z4r&W9bIAB5c*;(uJ7PHElXPLO>fPK`Dz!fTiBbh$p5qhn{?LdpL*ZDXSdTv+Cd
zk-6Z4cK@O=|6-MKku_FzAwV&~3g@1>KM0!TIo9N`ZwUwX#!*yJ2y8@nB8OG)i&e-J+DW
z<<_AylvgmKbq^zml-lm}$6gi}IcK{=BYS9K?{boQCO5sF)>Q2I)Qn9m4a6TGWw2UJ
zQe1<>@JBjp8FEq;Z{Qu6?rnH-D~#q@wvnua}8qeOYR1D*$hy-
z`;Pmh3P~TsYWaq^nG6(?iP%c}H)aDH*A{2bCX`T~ivGq2Ul2nDf90*KlO%qeo_t{K
z*BBR%YF*|BFNkQ4ORZTKTLbr6Z1j*1Mo?AjG9!e>yGp&mqixj|QR-7X2Q%D~boi-g
zs^)fcgxTr`)>SO}a+}1A-^W|wLjBtfDCJ)vEI4GS)WVp~g+ker;tlXN-y0V3@nTS5
zN7w_&`U{ER1?KgaSbW*h;+JaT&c$7u+gfjH_@7919|hJRBlt=TE-a_^5^OtKGZ+=t
zzpd}uUaDmHM-DlA3Pg#cAMm%1TD;DS=+@6KjmJXn4(AoRPpeJoJajXVucSBE$_j`U
z05Jv*+BT}!*d{Pc*A!4l=M@c-@h~RPa6xF#Ij{?hhaMIBRpV9G6*-(Aa(uL-fHR2J
z$WVD)`Pue;*u+I)n}2u4Ur8&^Xq>`bDM*fz5sf(EO#Rf`uYhkNmiS&K;kloJ^&utqD13MXvJkl|{mmm@`lRF6Yj{2>;tRRP?m!Au8
zG6g$4u6EO62lZNntx#A6(RmI}Wgow<6+#D=Hzzhj3z3)i17KMz_jd{Z)?A9Bh^7C5
zrYfxUBmq@b*0?izg9rSmLtPdBD5*1cQrhIuB&AZh>oLPhnW4O|-C?$bSZrlbJAp=X
zDXiHzFCJzS%HPjf4!qA>X{rH~YdfEj{K23|GWdZS^ecwv{!sjR5j3t_jW3S{Ey?p<
z;%Y3}b5VmP&#b}@9(!8t7+P+3Rny9>`;74}yTwCW8DU(eGT;Ew5WehW>|T$P>$kDH
zH-XeF6etlddvGbAt0A665UHD0Unn^TRuYSUf#;1-`Ozb(GILI&2jU)luB3PH0x~fWh=PysYb*Zk))~5w1{CTsRiY>g~%Q}Xah~|-BkkP
zOVTXlqWOVD-)kqnb$+aG5Uo}2<$7M8!qc^_-#E%HgA+*Ts9An>Xt}}d>u2R}VGpN8
z8M@nHOfCV0bUD5h)~box*~Ut)^&4Mh&rJ7>T)nQVEH$Qts|hfuWcY$dVuH#lP2vr$
z$6S)zx~#`@`o4D+3IlKO;iwgdWO^KHRp-vSy(R%*FQWVxq#fU({UJmN$ooAA3^cVjtj3kGICQq
zfK*B206@8^KXahJ(}}x2SBD{Lg1-r-;6;cv2xj+*-zzjUq+Z9&_qaZFh1l{Ym|+$%qah=5B+)SM_a^GZVKG;~6XOHN_zV9G-=qkEe!Kg4Vk1BHE==1m
zjW;FYx^rU;8;NU03ff>y{`qvuhCSu#JRd@YU21ywo_c28E>kmWtKB?twW5AlJe*QSxIsGu>$krWH3_LlW{Z%HH8VsgdSyD*nTV~yzkzJCG
zwAtQ|<*_YGp68R<
z$1`d8GPM|VjM@Ant(R$Bd0&R7%PBq?y)Wj!^n~{@oGAS*k(f1>3@@DN`x3CHts{NF
zH=}AN{MtVi?kSIBsw7}ZIqk)=BbN{ld5=Zfw|iNdM6pr0($AvL1mfyn)^ABW__3>J
zLwDx^^>2JIgi+~(_FHsR@lEl%X8rSd?dN)G`-r=aQj|x7eQXR>HZ=x}eAPmQfG|qn
z#2`)yJ~kQ7e;Mhd_QIE=ksq;rs)=8HG$OK(c#l0=z#q>>SG~WYZaVvc&gj&kqVz)f
zfy$TQyfOpX_kO;l3A;&JU)Eo#=AW(^23W}2vnKIX9+s@6#>?CDhAOJ80k6EQvZUZD
z57|{i&FH?2n4hj!#L;cke7JL?i$lUGN9fl>_>L~ZugWV$85Vmn0F$p=Y9mjXZLoKn
z97GS0vC&E4iDonqgm+u&TG!FaK}`s9M!VCM`Qw?)56|+0*Unk=X}2P&z^)nM@1wQn
zz0DIe@gC5TnU}U0C_e7s)frIXy8Q5mfU01qo9knXbSQub>x{loiE2
zc$%}9)wl)IQD1QGI4DyJyHBI1
z>|P{Wp2?V#J!dy(Bn%iaD6^T+aXB$Xk5$|uP$S}e3c4yfW^?Jm=e||LPxTf0U{18<
z@4W!_HWvGl$&(*&OLZOQ_buz3DTRgTEqzA4Ho^9_%rMGg>AHw
zhMVEE8jfyMLl=o@28aCFSiMOcIkb9^Ld-;^E`&R>kT&eZ9Nv&D`Xp`+WJ@z=!S3k4
z7=kLDZGW(qP=)y*|9A_Jirx=>=v?d-h}u?1Opfy=OntmeeoHoHM`=$HHZzoyInMeb
zi^nF)6M9VAA@(#{L{X=HZ#_e<7NeF%X!9X6{d^ol36fMddsh5h2o+V?&>RRxmcA18
zTDArg1ZZLHM4)huY`lI*K%|hMR6ah9Vr31x+aHXS4R1Qr*lZF|hIO_zx@&~UW{h}w8-un?+W>fxupqNcZ_UabARJBz^R4_rTm~r{%6~@qyD`L|+T;
zL1*HN`wa~&QD5#Ckl%Meeao3>+;s6ntlOgW)x_g57bNZAV@ZyN`h!NZhc}9LqjE!Z
zau%r_jkn0pZ2fPC;a)%(Zd$I19yu4AQ)Gie!6gFS({w{3tPYvML&6~SE!z60+7F-^
z(xuS^8aLm6MtAe19m&|Y!Fo_AK6IQr0T5Xwrd*ZieFQqDTpYiB8b$@u>^m~JS8;)~
zuJAcPGZv0aZ+bXF^Cb}bNlxf=sG85Vii}`p0C*>_e=bJKHlfg`4GX9o7Z}TDzN73O
zUE2(&tFXG_t9M&2*bI%Nb*+>Sj2D)7eyE13iX#;n-*d8yE%At{@tQuFR^d2RfNplR
z7o-Q|X*#5YtTxa0kzatU+oV@2rAM)8eNaP(Z5~EoIT011h!-TK6VF_L)UoSh7^
z!NxY5&1H1CFyjF_dcujn0EU(fFCk3szjU?+cLnuu)sKXYdl>Zs52tg)okrLI)L7-xt($+Ot?5bTDgae_
z#G?!rR*qhw4H66q3qy~lHt`$zvv;N^Dg#CTSnq#xpmDR(Ga4nykv%@-GUiB1`SQsN
z2^wk>z3lqed;tQ@)(d~^(V?(6cJpFWgZr|y!9
z|+=
z)XEP?_MzI(U=`LsOz56sWJXnB6%<8%DU?`M*w-!5*|aj>nR>R&W2?D>$)Y2Z`!rZ6
zW8r!;!+NZH31PdX|H2zWqB5?{yf~|Ej+|pL=CxCsjf%H12*hP6i_l?{s{rya=o8w${G*d#rAdbXnz;-O$it_~2Jj_jI3!(@7UC?1dKX
z_tY4qm4eB3oTs>)sodkrYw)2oid326lND->qCQkOc05J=*fQJg7ea7B+GB-DRL9djEb4Ewg848$1
z;)cIEM<(Fj>gpd%ttA#MbKV@T9d4di$7#c!-Ic59t+E@HeSCBTPvevODY7&+PP4CF-y|io6g-epJ^YwMZEq4Ps
zBvem*UNpFDTxCiGQKJpz#6>4@=u(!Q9BjFD*VuBHPP@6j_-cz^&-dpT*;d3K#CoBi
zx^sQbMo^9{zF|&u6@R3=YiWOLw+Q`9)A?FlRnAqan8jt=
z-RHtd-=@%xo*AUl7jC6B4iNQ-ci44p@giC9BFlpF_^bQrOy#m`Y)*=Yh{Q%H`xXmZ
zm92LID7ioRi^i^4kqbdIa6ZsPNjxd-pC4VOc~l?*iTzNx$@@g5m<09gDT1X;dGtd|X+1b;JF*WU{0qa^<`=ka2}_XszuiD7Sw0
zYm}C%?Ma?;yJPjh&|P$sADi4(kAf1-s%-O89lSVMQH>Ljvjjih#AszEvU97d3sT`Z
zUbTqVyWnm7DUNyi*xSG%q82&d(GP%L(MyCp?jyEmx1!E2{b_BRg1iKj5
z&ThpxBaHox2vM^O5HWZYrIxhw+Ar=*Da0`WXVBegTZ|=sn8|)^X+_4#Vpu%Xvn>=z3QAxJ4dNMn8EE
z0}%cOKNDq2heKGHaH-S^u5Wd}sSw&~n}QkVrWBc4K4;T`dgnsjGON)hg}ZCBT4Fg@
zhv6w44l7tIkKgfm#4czUXCji+EL)+ki&GhV8W6=BcnU`r2sSo!OeBbYBx7HLTL`jtqz_-5xbPI^vT*0uJ{0jT&k7t;f)JFb^UF^w(OpJY@2|sv1lo8O=%l8^2TrxPf
z(eLE9tiX4e6jP3!ugY)My5lOAzP)a&rv>no>q4+0;4p2$0~G&@S){&mLj#}=Hx4WL
zhR^-jWbs{(uJ4}Be?haV&XNkFCn2DVzqA~Z+0`iU@k#
z8^6`*xZPYA&wy`+U3)M7SA+4uAq}{PQqJ!fPhUv`i&KDnhUPaC
zzJFM#-ygtrHQp?(b~U2{5x+NPQLpvW|IHaN3ITh-Dr9Q)MAHRMfHs}8{8g6v8-}3g
zg^IAx`GU*!qx(xT^gF)y{`z1D0*|Z3oF>T47t1&FuZ5m^B?c)S760S5{^brZu5T}M
zZQaR)VRZY=2>Z)Mlqf#kkKJWm%jT>quc7O;N8U~maa@BO0-Db0x6|-cHu~xQ())v+
zD*#E5Ez~HG2||^jP9#{LsjpN>;py98gdA@(h+Lm$sS7bR(LTS_u;=rz4^+?NkhPL)
z<(d~5t@Qu*(@A|w@R6GFw2Y>VI_Uln02?XQZ#0=}^4yf$8ZTo*!y^1K2ukO3mU7#j
zVIXERh+P{1St6;HRiO+@kYDX%Z)ReCtc)P3YXd#GYT8pF!qv`5Y3Ny3V
z?8-TUJ(>sdu!z=v3v#$l1H8sO2I%V74Rq&Nwe^MHO()|IUZ`Jje&SJ@VrUkQJO-|s
zhTAqz1BiUx3*C$B${o{YrV(I}v}~%z5RdKR#QTeDg@u+6;!c(=dOej-8Fa-S5VBcL
zws$W`elDA@=CPgXJlq&gV}0nKe{+TORXV!X-@9Ih)?a-O5cD|{UGjJuH%jHxQWL
z=qrZhWJOLb`08Llqz8EE+xJ%VH7-5q$!^^CWF=G}z@8sytEa_dKUa*~f}P3;D%7GB
zcH7p{u6N3@vYx3c2S$Fnf{IDftT&OSM7Op^!jJg12TeO*GQIx!DpR3t5lJGU2^C*^
zpWMGpY)8xN=!m3}Z}Qmt-W|szj6xJO5Dql(k*_rC8)?dv3TMQA$owgFc{oow$8NS^
ze`A;qlZ>ahSgZUCa1C43)0tDJT~vMi_dBP1%i-8;pu$**5W=pBlVS&_AENb56UXpS
z7%QAGiKnBowD^P$Wn8l?$`}BF$%XVod7?{`PJEHtl)c^5KL?$FPN{RHCtRE?tQ1@V_6nBQu?j!#Ph|c(4nTG3K=?C3f{M>$laHDXW=VzmD6*$
z*nVT*rutDhu0Asj4D?)$*Er(N&$9^Fm8mKcN^HEVd-g9Y>F+xa;4ku{YIB=1MQQN~
zQC0D2L4_J!)c2V*nO87~_^Wmd9S4#)rH8U*jjI~7zU8Yv(XMmIAhlZf?6-e)GFCvR
zBI39tFMKcmb1h59l#WN?R3PH!lTTemRi(3SH
ze<))L^1Hq)EzvTo5C_s%~o=76ob8v?8%VkOo2NE-3-&1|_AtJA_S0cS<)%
zH%Ln>DGk!yUGLsCB
zzZDFh*%f%-0$j7JpqIT`5gq0Wgb*=_
zkdwY3ner_k24V;BUi5|9JF%bJ(CbB%@HSGI8;%W&$XP0Cr8Ev?i!RE%X=p$(6de6s
z%}wEw70-w%Eg0R0#QEp27(D9zxfX2jo5B~z`wJ8%8A1N(n=?6Z$~IT0I}cjLKsch8
z^R@Nv>D4M4nKT6N#}GO&1lyX6CZ@D!9!6`VV)Bp`QbpmxcyOKKDzs3aJlQmnLE{%?
zfv7MM>2<;(LcQSLD3!2LC_}Ja?38mNCpw4SNNM@yIk{3AmFR~J9rq#yQWZLCm`w~c
z>`y^mZ>BilV|8|?j(Tqby>t-d;+S+|0WI1GN<|r{09dM+FE0^6E}A78j9+fMCbKbB
zRhW1H+B;+!^u;<>CUv24?ME|RHbpbUN=T3r83Bn7&O>o7#Tq!=-lA5Ztu>6rEa_t
zBrNj0rK8n>LML$MjTwi4f9$)xxl$s`EN!_}&lcncQBqRnK2G7Z%~6+vjoB=JC%ZUYi2}Y_BIF5ke}Id+
zgXpgZkE32l%hM00@)pjtmm3byf*z(ZcAKL;haR=gM>)s4vl;_bGRYisIeyPrO`?hT
z+*D62XX~r#`5X^k3m^2=|8`Q@W11nTCE+d6X(<`UxiTKkir{fRT$k>`-%27AeylfN
zuprsnn6HpqaD_JX87#GAs}BOg*^cA9d+zu#cs^_=-JH{yGbPqrp}
z*5<&GMQJ`&Ib3IJ^pr&(W;WlfMNG=?;dauPuT&VTSfV*;J(aq9by9b**pB%0m0`&C
zRF%{|T8I4$so1ysGt?T@MWdxU^M}bCtKfSI&|7qBsd$6IVoId(xhuXZDfPU&Eg*_c
zeRg>UzvYixsXEVUI-WOAi4^+Epf}6uczaTz%^!WsE@%jt}q*hUwIz|^^m$F&1=pjSkF;-u=9AtfrN-J>vN4@YAQdKEK_RS
z%f)u7%E}E&!`Pz8`VTnwj(e8OvU2{n=Nohd`#{OqNR8>5@3XuO6n3@y*rftwJ%_^V
z&US}>$!Tm7BqaQ_5x=Rzv+xSV6W>VhbX}aE788;FlI1g=pUCTpl-j)fyxdl_G3ADl
zw`8rw%wiNHlHJF_{Po%Q58ZfzxW9DN>Q&2}JXXrZsUtob57Uz5Z?T2L4t{edOIKDU
zQia`eW^YER6q1#dJKxrf6>`_C^w<6@ur~6w?#+{_DYvoWToIY%4r4x-PnHu({JW|xI?GE}
zm{awgacJgKg;ytoyD5hY-^rZa?^2zzBr}U`1tlhmV*F5W-thPTN+sdd+;W`%)lx`&
zwR`cZD(zi^j#XNG`*TrAiIHDw6#BcqHUc^QSLZVN7Eh(|vWq?2G|BVn{3EkIi3)M^
zrxN9ERO%Qg!Z}}@))nlj=afeG9e!3wtMinN>}l{XysSK6>HYN>HTkkuT@ctcyfe?A
zQpRp|AY8w+nMhUHm4&}1hqXx^0%xMUo21>gKGKdlRG?Hy`vJ091TP0X({RJp$Kaz2
zk$20Pt+!jt7=nr|9yiNp^PVctg^;}Bena*+9?L%%Oyk$-jiy=pm32CA!bIzNu|n{a
z%`D!njX$Oa2?@h+ATb+WaCNobeyg|KpifcBX{VF6Yq-6=UASomw4`p*&aSo^_l7Zq
zY^)G=U_g+_pf>Rw))|e?M{jnL_=mHlsHEZ;?XeXTuGS4&P@cVzO)Y|d57AUb@H1S0
zbl}ekE%*I_D1-zr!VVEuMd;vI*x#OfMcKh^yBb0vov1j|iL+*B0A?l@o)PR4h%u9Q
zozOy)eFb_7_k*D*^j128`bK!tNo-1IF)BWJ-#jd8r64Pt^_$n%E}kh|_L9giPOOP)
zvL$2WAChUoXVxrT_^;)V$fokhk-ys(&O;KU*8EQNDE}P@2aG8D?aV5s&iZU0>5BK8
zpY6^n3m4QAvYLGVRi=k9Bx)P-j9n(M?wv}uB%rp~YLfaO0)qN}ABVF72{Bi`9MAk{
zp>k5LF`piI^1O$&f;d7=ZJRih=%|>DB~G-C{OdKc=~2%=raDZtaC^xNTH-
z;l=XyRR9I8(zvk&
zWW{DE6E962JGeiiQX%PKcMBQ0s2RA~Yzre{?~*?4)1a=3wsWSfO+oX|`d>P>b4SdOQ0aBVE{}NVw=oOhg(T`gqbz
zbvCruoSGBz=lje0et-RrO(xi$hj*ic`TU~L>k2vC9HV1p1YNT`Yild#RJ&PdOCsr`$U`7z^sNV@}~(#V-PIoronwOxlg_q^*LcYAn;{1}soj
zity-^pV(7MM!y?;C!5Bn^tM#HsbEUi6ax{$l0cl;&-5FIQj#KuRw=U1c8xYYj1MXz
z)L9ibUtu)FHjd87Xcau%P7fR2+SeuO7JLFHH}hNxHGB86#DVk*K{y|6-;0KLB=Y5
zbOw)SC>ZTQ4Drk$O~pdQAbPiJ@A51;9_n_)=yo;Z1;ZU;;dzD?|42j&!jU?msZ(t>
zsXL3FDvI6*&XQ4HQ$x6;_PJ~ePQ!PtO6>@4ENo{9T@^o&
ztq?$)D9g7|>*R}GwNiHJmXHJaCq2ducY$v_v^rX&i7;>U58mONnDeQ
zu5{J29%|!AZedXxvv?zITuv!%YUZ(rr2~?pezSYahk9Gs43GA$YG4$1n22QfJDmEI
zXeuM~-z1f5Bpknbnzqs+gjWXI5kD$hJDxEL6UBY?TZQ29CC_D5%SGjmc34!mxNj2@
zIXu*W7^KQ*nokZZqEPk(2l|z<=e=@NSlMuW)7S4_-QxP&g(4googi3DWZDs#*n+2-
zw%BMqdScJ)j&wEm@FrWaOHyX3R{aCMNH#3$4M~#|l$5VIj)GZ1{P0&keEwxnZVkbS
ztK;BbbHwTvODU=n#?QkJhr5vKsDF`k2;V0i?V?N3zHD$eE7X2ee1TwYWqzgjI%))_
z2*1^~;6f*hcFFJTLK0;k>L%&=-zyhjl6B0FwQ+`NDZ!?Jmg-#xSR2pc6Q8Y4)Q|8T
z@Sji#*hIu3najNfwvXNsS7O4x9}^7!%n*$NkkK?JDer`KtWa$xssjk-p992f470}e
zh2Ui~3LY&ia{+EEf>H{9ver7&MxeD7l0cT7N)qZrjfA+cnyJ$VPL8ogXo29{1eQ*j
z+N?0Wxq4bNuP;b4N|!`XNTFIqPQ>Xz?*PJ)A04g;HiT86@e8SC>NAdwk{6I5L0q4g
zsLwPPH#X~a8NoGMW^|s2Vb-3#*TMp0aQ4}ayalO-u+~Np4dDY?i6|!0
zIn+U@_m!U!c>b1V^z}7=Pvng2@{*Dnoz=BR@*g&ZsE?XTQ3LjQeVovL3nQ6>3^Q-Z
z5nF^TdkrM}ikpf}QEFe1eiC?C5)lU;H(!p|453%Ruyy77;W89?_jxVGixO{Wy(FWl&
zm|W)wQ-7MLY4I=g$(wN8`@ZFRHoDPnvM~tFI-u>}mD#m|wbd=Wjy~xodB}|Mdonw?
zyiiS8__c!5AzEMrbA`zWKh$YzeuKLz*m-SxdVcU?{iZO^rgCq{|2?hfXG=;cf~4>L
z08U9I%fwA!k@~EMe?md6EpKyo0OqJp&F0j_V(iAhAPR)8)Og@?a-n2|Co&Cv`GC#c
zz1AWz7(z@#U?`)oBz&yoHb_n-Mn3lOa=!{H>6&9^sVJ7J)%fL&gl0~%{@zVt>rvAS
za{eF16_QT_Fq9eJy|;ItHL-VF4b`GB*l{T^yY+f+CaaOO-~HTxmWItW{im5>+*;`e
z?3Q;}(r*p-I+V;--44W4-t6wo(_L{-ry^Qm`Uc07loS>6`Kv(?m^J4FpDS+iRSH8L
z8a;LDs$H@-LvaJ05yO69R?Y01OsWP>|4_A9!f3r&joaUG9M~js!r#i5j0nPMK~zqk
z#kMgUrmAa{Snkv+B&n{qn##_iFAmInJ&_l0Ty)jsawhM>XiP_CL8MHq`zDkDucd&d
zEVCmfDXg?-6DPPb+NIhvFZ{V0-$li$2!nzS^;WB99xEWGpS^Gl5;_##;KLqzo^GVI
zy-5QrZ*To`z5=Q29-A(c>O)1Pf7pyA(z=5rLn!{rA4FpT%RN!u7Ml>b1W|sSASkWH
zOzp!~_!)_Q?`YAH9BBomUqZ`zp~;-Kv~fhE(kWa@o1^)97Rm-l0}FoeKc5WGEN0t9
z-)Y+<=yV7d`4KEYm^;Eqb&7GcwcBq%M~I3{sqRo>1CTv-)d7oaeAi;P5h*euKOWz{
zU9cRp6yp(M`3W85d#rvE5VrRip*+@~!M0ZkWvYEK(*l`}f5ddLIOii!AcU0L4;M#+
z^neWG0TV1I+yb)5m|9Xox2lUTa&dCo#^C}V3++udL^FO4a^4czo?qjIDnk%MHwmzD
zOA6`E;?y7p_^KGBd^6&v>{bf`7og?&*kybg`q^t{6hB#{qa*k$E4V9goXb_BRum4m
zeL{^1PSHXPAfD%A2fjuh7PX&pu^2!~^aj^>q9nzoIRlQ-50aYrNLPtNgAAG{QZL>8
zlD}`j?FSPz@BQ}ccGfL%@)t_>_fnVvAcf*&Mc5Y#*r8cy>R5vY1dq&+{=#L$B!*NMG(O@dZO0M};vQ%@g<0$5oeK3|VCK@V!wImue
zq*Wx}yD{SAbo_POctU>XjZ~C!&|rKnkbE8`#$SB#Rf8xQ4j2x6p!LU&DyGv?tP>Fw
zQMB+qW%qNic*Xv*OVy>eyyWr;h*Oq$ej?Jdc`69n2bki`v^SzSB4;#m1;|dj(ZX1|
zM*QR)!-6%ZjwMPgMusu?+0~O#%0^6wm}=j|;369}bbjVbTaGg0s1mwWpP$aNr5_!b
z79w1=e7@N3qQ|-7^ab;5z$ee@Lz^k1($AHHKE%U=5wQlW$Zi>irDycfUq7@>j%n-w
zjgaUk`#*;P4*?sCcQ_ucg8Lob?KzCgr7-?1+qEI4kp+JccG8aV3i`lHKG5eI*X*)(xqQX(jO;U!kS7+V
zH3Z)D7x{kMGp1&REb$LWCD7;~qRG=$q)-~r30c|w-~&FdKxKAtZ3u=s+){fCqDF0_
z0Ax{Vif10>+5X`z=uIk@>*w`hf1!1CD4iR=2qzJi6Wt
z(ctZ=fi-J8NgG62$0E8HW?-MJ+?F?dG^hFsQ1vfGn#Q)ZfVuG>El}#SHlbx87`7&B
zrT}E$IGCf?M-TH^(%GAzEKtW)Da$$%Dlf9qoI
zKeG-a;avv(-5s`dYbj)PMC9>Ym
zAi^Xw5#63`P$@SWvN-l`c-ryJD&N-$d(AsuJ`ALQFHtkBO5+uZHjhM6)N9=r&mLe{
zXd@uV;VjQAAE3zfs@qf8u92o#X=%UKk-@l77&E#q$;>L5|Gs{7dCNPg*!dzn2*MqT
z{opC+T5p?JF0_;@{+59uO$`!L;!Gzo(OAW`IaRP?vmMr4kbL9WA{luYqxjVJ69i38
zQi_UzIdliiw>bTR-bRRIM$}GEE;U{GDa&$lyexRO*%G9jxze!}I9++n@*jCBRQE-e
z=CzvR8eAO<+isf
z%h)SmjO4Q5qDe^4pn#>S*1c<*VEny)@`%M^TF2(16=4ZY8l^h!@rC)kY36VSpotN1
zmH$-6DS$))2wfyiMQ!;7?ETMw!D?v@o*IVW>WQ-&;yLw%MVr9Dwpvk3q|A~v`SHbD
z_h*x9Dbv4L$r-9U?ztbk??XJYG4W!Qw0>|EPgjn|F*deU4|e}Fg`Ch
z2TCzKQkaM!r;ThHzN_Ha)m{NHe%XX_#M6i)0`4YDB8oPSudwXkdX#vNCus}xZin|_
zfS>sSX3FTIv0BdY7*AE^PazWUHl@yyfm6m#5VwS2*Gt)3G0@3F_*c+c)^51bSe#GZ
zkPr3HaK-FQqa4QF9@Qr%^QhIxW+m=NE57Xk`j%J9T^{RqGe}CEYiZ8rXHjl$XKE)A
zRT{Dq+Qt4UP+Gl)y{c&Q&tvI^Wb!2*k0?I`$`{=JE;6=p=@(ae)630U{6!7267zNS
z^t9OKtC)(tTO>-1A{TenQcr+0$%cAmgx!F;%kYS@yW6)t8~aZKE7TgLe36wIO}?2P
z`w0h`D{Xeu^AVxsua4_DjB=7mSl`;q%2ibBU!*5_#FMge
z^{#*{)Jnx0CsYs08=v~P6ySXiYw&mh(nr5DT{Ge6-U$9EwXti1y9{=!^%5ZZf++tq
zmB(4WF8SMz2xiu>Zy)mTce0e^d%K?`egkxO_YepmBnxK&vWGmZZGz7}X{5P|ws(|(av%jc+
zhe0nGz5B+ObEeT*A@J}WTldx39>NAO+3nT;vHo8A?=1X<3k8oIS>fU1#RCEaXgQHk
zueQr>BtlHicX2_9>_0Nk|Ms
zLsr4aw+*L46r==lDw*E^0;_$~%G*l|P^>3UUr8iBifv@`snZ#FLs$k#57y
zr4g^;oO(J7qbnk3t$7=Iip`Tc@$Tuwf*~pu%<@_@;;J*n^wUplc{|Iu12Beob_*ybNYr$SgF55eDH`c1sHFxCuA
zP|ppV=J^@nEMOTe$P8m^j
zSES0k^3k_Ch1*ebwLd|LmX~8%Ao>yF6C{oPMU2#4Rh9l85NW$j5ZFE8eaxKX{?
zB#ZaQZ4k06Yw^0y0V{iaZ(n0nx;dtWD!pYMEqT7z!Vr7cH8##)v#TGU+|!oaP91B=
zmtT&z=Yz|eya(KewJ_ustM-HvKmo;&hvhuU2etx?zK!$S^74w1V0lFO=h
zknE@*k#9V(>oSd3pg#5W!nUlg2XzBwxa<|;n?dOm&dAbEL_f#tH;!qaejSfJ#eGPH
zlv4D&GigoU-VQF)SY%c$lI8=O9zPT%?KOL$O}lMxKp5%hhKtIzR8a2OHR+QtI0$lZ
zWh^|1f9luZ@5>AydZKgqLf(912dLtED2w3x28&rPDME4LfVflG{R=|%B1%c?Cje48
zI?6#o;$*e2r2)WK@KyUET^Hub2m$~m^~mTSz|f6m-$^Ebd$y^ylg0%X?E8L
zM5E_6iGet^S|cp3hi20f^FhrBUw@AceQf4=zK9q=Qms`Rbq~Gl+|y>r`9)mh#82fn
z$rg~5Ypp(HT4uiatbgsa_L^pQVI$POGg+&t<)uGoe;aO=iQkWQri0U^XZKP>uGhNp
z-&x9FC$<8l&&Z!3Nke|=5(C1n>2Relx4^dmpeN*vnzdH6Cs|AO@9#Fp3MG?$S!T+<
zT4Jb7+^2+qkVqH$Bp<3Km-&WOr+_wzc-GBk{$jQ6;PS-O`w6NK6>JEqj*9alWP~WZ
z0Bd6(V&&`;-b=gi5J8Ny=xG^la98z^=HWO#;(rllJ78}IS}OLc#j6&7WImY
z!dQK|36iU?x%(OU)I7JzdRp=~?0SzBSQiIGlJ>j64Gb~qM4F$Nt$mJVYr;+8>o&&F
zRyq%WN>;ko&Eybcv&rk{DkP;O02-evfqSY$Q-=7i&`TI6IT50KeY<67_CMg_)zfMB
zQsR+cpmH-5^IW>5L^Y?N{N!3KQn|ncpj)*9=J{%(+Oy5snqQi=>(x)~KRzES)yC4)
z>k*}+uxS&K>8=z03p*NhC=2vbaBT>5Uv&YOWDCXs;BH
z*`G>ey&=LtRtKqwZVdk-bZ^R8KKFVdmkTt<&tUqRO4B~O4ywo_8ikx_AZyFNcRYZu
zjmC!i5NY+o=W7?OWDG4OkiRKQJIPtfV67E=T?C;hwvN<>4?zb~?UNOtk%@7?Tnr^R
z-~dS5C)QiwTPn{2)34JLXjZTA-h1qtay1`=7(KP2P_Ygq#+9RM8L
zUU~mYVz*SR{{|+n7I*+aFa`vNh2=}#!30dBO|WQ#cqV!D&5inS6FSe^>(Bt$UsEw=
zkZ5%Wb6YKVMfiUO!W^I1VIIiy08mDemo-H)V$(V{2=__v7Hwy`J=kPu{bwiSH3Q<`_Q4glrLL=H`Q9s~187ws$|^lnf}>4+8t5
zRcMa*OiJ{(Bne`|ruKL<_OqU1KaVoBTx#DZ5R7)P$oe8o%hm0*gq<7*N#MStrZF9}
z2Jp+>d746bq3ClZ#2TtvK4(0YIHriDM_2ibsmL9C&8~Dw1<_G8Q}a=<>*w7P$(qiJ
zlLt#P(SbG=kvn@e=b}M9DJg7NZ)X}WDCWO1ht7i24_>aMq>zu<5ro>i2ysmC^7~|X
zI`2QpBFKpcu-Am-1eK%g4E=zgYI!EEKodzU>85D+td-Z
zN)O|9*|FTH|62Fc5(wcUX)U<)<~8$}tMhoAPrhqX&i37qWxwL|blm20u6Si}rBl8h
zzGL|n;C4L)r&kCXr9M8?rR!fm|M`)Raew3wsvk=FAl*lyFIVmr2Z^kvqubo}n-t>g
zMxg+Xni@k;62ujefpC+BOCq-s&K66wkZ4lPl<>Kozpwp7A$feU5>(jsI2kd2KKvnu
z93Y@q3j8jB%HpAFDUdQg8Q68g3Tp-U?soeag5DO~S~Qpa=957kamqYY)nmR;4OlET
zl}u5=bFol*pyh(R;xD`vcRjhjupQHI3dehrM
zcpBYKkb1T1!amvL^xTVZSTr;}TC-MDD1oR0$f)wFYSANn#}#Yr*Q0B$$1=|0qZp)Tj|4$
zZ1feW0>%%OdrpBDQk1%yLoG||E!i%V&Uc&HTrbYNS|h)Fv~Ez)Oy(7q2_q@lB&U)r
z>Uv$8RCl!1;HY20MzU%an(Th}WB4G3RpqIHBe0=(x~&4)E>L`q<9SP_63d|6ZghEz
zD52E7`Xeii30ec%Jdt;f6Lr6SM48nYocP12!sGbRdz4URW?d7iWPOp{`w|)FvchyB
z>8v#S==z1t?jX(B&~sfowPA}~zu{XWJP#}p>G@ac3-6R@^$Y^BTjy90qTC`+a%20#
z(cPCbW7#kxUa5K9Q$U3y(_^3*D8QHd&+%*Bdl{>4Tr2^;>b>k@s=_Gj8;x*SwfQt{
zI@*jM^u6~{B&SaS6vg&>HOVrh(i1|qC~7&F%!zB5-6vklX)u7$M4KQIAA5+;4
zP`&pYLj>OHyAV|CiM-f`E|trBs`sj8ShjMGffV8bj>K-ETX@y+=w<|1Ko
z`o7HoJ>!AQFRud(Vy@-r4D_v4H7-8)=1>gPdannjRX~4;R{XFnBUd&JMbm0^D6Lc_
zxNs}Td&b)HDb6s8I9)8Kt)abaI!UM+I^pYg*jur}7Ei{lYl{`^WCtLXNMZ2%yCl;3!>IJzA5qa|Q{Yu5JBL)waP>_N->Dgv5A
zt77p$m&G;&d-XIJ_0ONz(_Zd8n2b8j^jPE~-%1qLkI;d50{B+Lp;U92Rl6y9!VBp{
z>Vuc5^GI$w#l!Ep1czzC4nk1Lksj;qo4(r>tVPQ<9#s@FZm|rLO$o1v>UuUP9bXD4
zX1|>t^;~eHodP*CxKv^%hM!ve8AlXR0cI*7YnMHRK1AZsU1m?ORT1
z@oXCPN~By~MBHjQ#NiQ)T!-@)QH~QK-r37Ur|`;`Vs~MjMC64rX_|hfOoH
zrnZM2e8U|v+D(GfYegpy9`GYbhzKg$;-G|S<^EU;_7JDb?LPIdTAA!by$8x^SnR8{
zi;0@&Ohcpo26#L@xo2fz4G3}*6D5(EEhlpA0pqv+lInE@4!ln(HF1+(B0j89owVJ|
zJ)0;72z~l%b8GT}S{#}KY*UTxE4Ith8ws{FZF8bnE(@3Zb0z6OV#?GR4;SHBk^}~E
zm0YpE>98+LM#ha<0uL&yJa5q<-;Ll
z0C{WVQ~OjrP<$4G_UGN_p!!%qVy|CJRr&%6a&L_aU44eIPdq?qZC4Zb1+Xo@keG(Z
zJ|56Q9lrIsV`5@9SnL8qQ~*Z5A2~^nQpO!&Oa+CPvtH^_Dxu98ArwWLU%<}Dt$szw
zLjx^-0xvCIv;M>?xZdd?LyNTo2NM5H^n0OzIz3Fb(I#LxEWi{kIST^0eJ=w^Rr}Q7
zhyG+b#=i4lx4z|NED4=*(YuFlw0>kxY-wb{zd|KBaXA7@K#imTCG>q3t+c@XxD}b4
z8Z`s(I2(ZO3eJdQ*8dLiem}}QQ&r;8)B;jP1mIn|><*%qSdDt4C6r6G&0%E3)5Q0Y
z(>*uk@edkT)Gj_T&9ET56p|HGX{3f@k;Q
z62B$A{+C?ok=e5!K#8;jXrC!h9Qs`NiFAq;+TN-$I>iQH^)Jtt6sT7AnVO={du&*8
zB=7J=1gUXe2#E+^>vL7nx@5g&xDX48Kq_0}U{l*|sdW)Otu!UGyp=LA-G#5olkb~I
zEL@(g$W4UhXTE4FzhRtaO>|fwiYc5=b12cyG0b#w?PlXVS0K=v=Vp#;fS2P)*O^dC
zD*}dS)jKuTn9jrL`iB40ESurDnf%9V+y<_@se^nd%H{9iM1N%6yzhJsD?BNOeKkYb
z14WiAt9sM?Ec=z2^*sO52aa=B7;UW1j&wkxAW|=Cg%3e4R#jEv
zPYeIZLhr$33khdIZ)pL~o&+HN){#a4jpUG;e%y{Vk~ooJl;LW-fI2TVrA!@AMs&;=
zI}N1vJ)jne!eRTD&CR8KAK$GKaykZ)iQ!)^D)vqn1#KG~gZcy>d4<^6mnJUmuH_NmeCqa2{aQw)8#N^lA4L85_xpGJi=%Vqcx
zQ+@;^jpOdjy`H~Gy$+5{6nof3kmyUmBpJ#Q185t$I*??|Imo3+=Y09GDLT+l3KHA1%)h<+@?ho`@&TJa!Tv(CnUB*s~@X`3#f<571h_#Bn7rjt_AEBrFaCnMWKMW^b3L~vzed5HjFo)
z!qTBc-nBo7tb)`VoyxGac%1eH0>|9QG0^(gx_~%$)K*Zo-LN?oB=3LGzn{c!os@G=
zj4_=}Oja1hJR)Az!#5X1%gyy`Ke;ETq@BUE>EY~PX|o4$^&wAR6O`dS`
zo0rEDnuiqhjah!7pqJ|{A?B`eH1Q!~>iU6szP}lhJU$aqQmXzTD`aH)D|&97MJJP{
zVq|nN6r^nm(nF=1%DeKv?)B^vfW0YbsjzJzTEF$BT_ffZ`i)1O)f-1J7!@UaC%>Xw
zK@cR?t5|@xmU}OlwFwDHptM~pvB^_$bavmXQ00tv;P0SQRkb<3&}w@Vm~nY|{75(N
zm7W-NZa%?82_elkd8aH?hv{bfS7z9mgp`D{;kI~P<;Ug}DT1kX6H_01ae&=7HN;KJ
zPTe%;=##bL%K^1gE2|5Bfafk5JG*)Ke&VZ-0ICYH;7%GH8OBSEc><(KixRIwE>Bh@
zzjN=T%Bq$}FJHQUkt-ztYOTw%!r*1RuU<&SzqW@!5XoK5O*j#iyEbGJDlv6rw?#5=
zL7QARnU99SUSkp27mWXLP>%p%S9yv+`6M`oApn<%yJzFcUEY2^w0CyR<7PL8o`XZ_
z$};iG_LHB_JELD9v_zq(nYz&Uw^`d$#YVag?fybPXp!{IQstW7%hYQ3soF
zo8pv9xcW3)REmORbp9@0YNcCEa3ya2SPr*?2LToTc(k~0_Y1W4(Hc=!J(xpub!r}i0vST*NJFrL?*bx3
z*l>#;q~e47A}$hEgypAqCFSim_P;xjtJs|Ug{{`sch_b)t1ahCQoYv$)-Zs;>G?xF
zt(zk*dqLbmtWJtrI31qpn^$u@E_s2HgFPDN&tCPZU~^hy-|?hO=$W=0FuEpKP
zuqQ$pGFE$^NJy~~0R5-sYK%5be2ybwg1(P?K;;p^`!$RnDi+j?{)xaA;o)3a%M#tm
z0eBu9k-Cf5-Yhe%Bw8zgOWvIM8?Yy5w4hoARfEbKB9SKb^dW6E~L+971rsW?u
zLyV=Dl=lGfLhPS|0sja87qG$>S?mO@pQbg*$MY4aXq0+6S3XPm`g{2bXFySW(6b)T
zfILY(9TaQzfVwZjhstzTOp723%fvkW4p8Id7m=*W+JTT48TVZdpm;{0bX1GW9n|V7
z*0aVvM)pPwP!z-^It;(W^j6HbLJtA;f=HUJUM*RmTIq=~(tr_@Le5*S2Ij<}JIZL`
z0_bLJEFnhz9puAv(b&?s;#ez^pUr-h=#djhSeKy8EP2%*H`VH${(0!P6{EG~+pTFC
zM9QE@A#72ZRmCBc|68&C_dk0tfL0iJ3oZVQKF~K%4&)5N*B_w(L30RPSpS)styW>k
z_!$cu6N3f-fPI^@4K>i&1yISU*o$98Fzi6~8NY)egel-#!Yd=idNDwK8Pi2P4*eht
zr9jRI|82ZC*HrF$W$-UC{IFF5GL|lk=4$Ey;Bzr&wh!(G-5FZ?e5-yE=M>eW-GDjI;k>|6Sg?_h!#y(?N
z5;zI`p3So?ty&mD`7b}T{Tj0kfcJUs9Zmt`I+S9nEBlZ#%R)h~CTVlJ!;~%*P+ho&
z@uytCU%LXsQ{C&IbH{#b`XYEQP{2^|1$;Ls0GPrE0xbCoQh=EPxfqkGb`K!kvw=9v
zWVcMWGg9aiN`9rYTDd-Q>_odnl)yX6{okFaG;$e!ZkNXrfsov{3D}Ccn>&qwxp^+W
zhOdsJAn*W;Pwv>*+2!+V#Qi^nH?aJj&$$z=}-V67*@Ir-hvhhpM^Fi^Y8nsN+pKhu@
z@EuT*``Td93c>Uf?_njhiE{VTwIdTL1ZYDJPQRJWN&;Ot|
zvsW1S-W5H?ZSjYE&w&bQh@*_)-@L_txXL*q_~L6{+V1NNaH$hfCVr;W|7s1w@1OiT
z>bH>qo_iv^k#z;{PlZr_^lb2?_g0lw_4}*3NnZ935hb*G-|7Hce;N9MWHXo#!x?vKZRAK+->0y;I5cp+J}(mq#1{SC^_dR1
zceGT3Hnsn1jl%_A-b>(KYQC1?{D|WOgl3>MfO4G(!cKyX!+-Up6p;T0FZ2(;_?L@$vyp+hsnSFhaTI^>)&KN~A8hbo>g;FR)7Zbi
z$A9|8zg}$0?|yi_b-#AxKRwkSd_rIv0%pIm4Nhuc|Is@9<0n4iJbaij)xqp4@ed33
zkH7fWixp6bms`?KF(J;okcWJYc6RRv-M&Do%m^mE!p<{
z=L@qi`Fs&Abm*wLPb_
zJ*mkGmF;SNk{LErHOPQox4O7qdyZ`%y78ab;m1Z`S6v!aQwiCV6~Cj(m_)BaQ!=I{
zZ=O$8Syt__>;}F1y^|!?Uv)=`Xo+unyXm>QX(>UR)_5uu!sk-MRr7jzGay4REcL(q
zzWM~5y=Kngv@o5gIJSmwhtAS^d+kYUEskdm?$$Z=`-XN>3}tSit8edKPZ_kTro?Sb
zZ|@bO!8V&#LVvm*?Hn4}Ya78VR#s
z8eF=<=&^N)x-`I_s7&vPS>iI~QY?Ea$T)ujldt{|vF#CH;I+
zx5{IYVz&im=l3dlB(E<55%sP=$90Ge@yN3_2~TwXmYU#KA5(EX+P%A_(Qf$YWbT-9
zcH_apb7{t2IaoF|*nKw7V(4+MJ;wkoQ10ga_ulA>Gq}^lwebv~u
zZDJ|3DT*QNlb`FJo!eo#ZfxTvT16f+7e7ri&4cPt3lB!qr;Xs`^p3hQZ`;4qLrp#z
zx+{UXuYAropPWt_mzI{|((;e45{V!&2DO`&A~)GP%ADr}KV5?@M=!LhQXXcQh|b{r
zdyliKBOow({j9o(Dq8YjnQYpCa&fNzY|MOROgClzhFLzp(N5aa(JkcZX>mN~#?7@y
z&k6fyR#~Em8iG|F9YulBjtKV7!ZlKzM)d{^;!M-|n57YRoq?-FLP*s%#(ba>=7s1%
zPM5ZSGcL=i=*_GTz!FD^;Su6GeTD;?)xYoS*b%^GlW=tPNR|K6Pn
z(BT44je=R6&d_2rIJDH{YB`W=r%~pKR=*HhmlJ0=5F*x6Vcnm=$3UuKotCNli5HV*
zbs&M6LHm3F^SR+rs0?ph=$L~u%(BrQcnKV8yR{@WOEL_r%0
zI&NI#ecCZ47KLabxG+WM>@US|Vkw%FN=6O<(!{S59u{-{&*;7_W@>hPgdgfq4#Z
zKFZMMyvh~D|9UL16{|(_nCNDjYryV5I8>%0fnO2buIxs;a#(H^n{;KUS(+>BJqs&5
zLf7Fq2#-Jh_2}Z)u*S}lM;>k_%$DP$VZY0o*n9T48R`_xoL2I5i^>l=yr