- 中序遍历:左子树——》根节点——》右子树
- 前序遍历:根节点——》左子树——》右子树
- 后序遍历:左子树——》右子树——》根节点
若设二叉树的深度为 h,除第 h 层外,其它各层 (1 ~ h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树
- 二叉查找树(Binary Search Tree,简称 BST)是一棵二叉树,它的左子节点的值比父节点的值要小,右节点的值要比父节点的值大。它的高度决定了它的查找效率
- 在理想的情况下,二叉查找树增删查改的时间复杂度为 O(logN)(其中 N 为节点数),最坏的情况下为 O(N)。当它的高度为 logN+1 时,我们就说二叉查找树是平衡的
- 缺点:数在插入的时候会导致树倾斜,不同的插入顺序会导致树的高度不一样,而树的高度直接的影响了树的查找效率。理想的高度是 logN,最坏的情况是所有的节点都在一条斜线上,这样的树的高度为 N
平衡二叉查找树,简称平衡二叉树。由前苏联的数学家 Adelse-Velskil 和 Landis 在 1962 年提出的高度平衡的二叉树,根据科学家的英文名也称为 AVL 树。平衡二叉树在添加和删除时需要进行旋转保持整个树的平衡
提出的原因:
- 二叉查找树的查找效率取决于树的高度,因此保持树的高度最小,即可保证树的查找效率
- 二叉查找树存在插入数据会导致树倾斜的问题,在极端情况下(插入的元素是有序的),生成的二叉排序树就是一个链表,这种情况下,需要遍历全部元素才行
它具有如下几个性质:
- 可以是空树。
- 假如不是空树,任何一个结点的左子树与右子树都是平衡二叉树,并且高度之差的绝对值不超过 1
红黑树(Red-Black Tree)是平衡二叉查找树的一种 ,实际应用非常广泛,比如 Linux 内核中的完全公平调度器、高精度计时器、ext3 文件系统等等,各种语言的函数库如 Java 的 TreeMap 和 TreeSet,C++ STL 的 map、multimap、multiset 等,Java 8 中 HashMap 的实现也因为用 RBTree 取代链表,性能有所提升,插入数据时通过旋转和转换颜色来保持平衡
红黑树的定义:
- 任何一个节点都有颜色,黑色或者红色
- 根节点是黑色的
- 父子节点之间不能出现两个连续的红节点
- 任意一结点到每个叶子结点的路径都包含数量相同的黑结点(确保没有一条路径会比其它路径长出两倍)
- 空节点被认为是黑色的
- AVL 树(弱平衡二叉树)
- AVL 树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过 1,和红黑树相比,AVL 树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1)
- 不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转非常耗时,由此我们可以知道 AVL 树适合用于插入与删除次数比较少,但查找多的情况
- 红黑树(强平衡二叉树)
- 红黑树是一种弱平衡二叉树(由于是弱平衡,在相同的节点情况下,AVL 树的高度低于红黑树
- 相对于要求严格的 AVL 树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树
数组+链表实现,Hash 散列值取模得到数组下标,值放在对应下标中的链表内
链表就是链式存储的线性表。根据指针域的不同,链表分为单向链表、双向链表、循环链表等
每个节点包含两个域,值域和指针域,每个节点的指针域内有一个指针,指向下一个节点的指针,而最后一个节点则指向一个空值
每个节点包含三个域,一个值域和两个指针域,一个指针域内的指针指向前一个节点的指针,另一个指针域内的指针指向后一个节点的指针
双链表的最后一个结点的 next 指针域指向头结点,而头结点的 prev 指针指向头最后一个结点,则构成了循环链表(Circular Doubly LinkedList)
- 队列同样是一种特殊的线性表,其插入和删除的操作分别在表的两端进行,我们把向队列中插入元素的过程称为入队(Enqueue),删除元素的过程称为出队(Dequeue),并把允许入队的一端称为队尾,允许出的的一端称为队头,没有任何元素的队列则称为空队
- 队列是先进先出
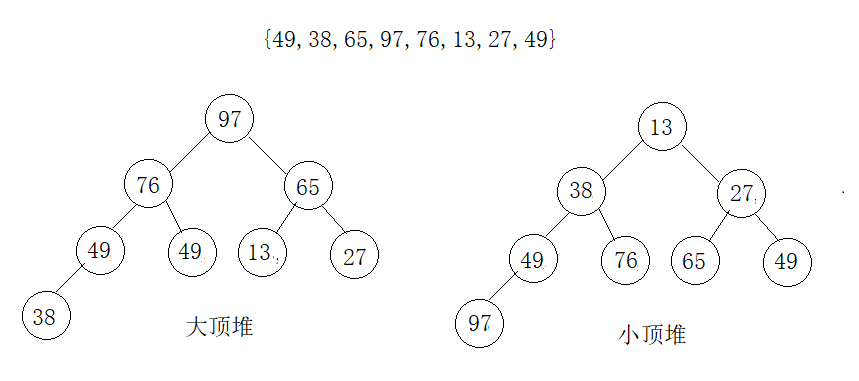
- 堆是一种完全二叉树
- 堆分为大顶堆(根节点最大)和小顶堆(根节点最小)
- 堆要求子节点要小于等于(大顶堆)或者大于等于(小顶堆)父亲节点
- 栈是一种类似链表的数据解耦股,栈与链表的最大区别是数据的存取的操作,其插入和删除操作只允许在一端(栈顶)进行,一般而言,把允许操作的一端称为栈顶(Top),不可操作的一端称为栈底(Bottom),同时把插入元素的操作称为入栈(Push),删除元素的操作称为出栈(Pop),若栈中没有任何元素,则称为空栈
- 栈是先进后出
{kind=link}
- 跳跃表是一种使用”空间换时间”的概念用来提高查询效率的链表
- 跳跃表在原始链表基础上增加多层多段链表,用于提升遍历速度
- 跳跃表的插入和查询时间复杂度为 O(logn),极端情况下,跳表退化为单链表,会使得插入和查找的效率从 O(logn) 退化为 O(n),空间复杂度是 O(n)
- 介绍地址
- 概念
- 快慢指针
- 快指针在每一步走的步长要比慢指针一步走的步长要多,快指针通常的步速是慢指针的 2 倍
- 在循环中的指针移动通常为:faster = faster.next.next; slower = slower.next;
- 应用
- 用来判断链表是否有环以及寻找环入口
- 数组寻找范围
- 链表或者数组中移除重复的元素
- 用来找中点或中位数
- 倒数第 n 个:倒数第 n 个,那么设置快指针步长为 n,然后快慢指针同时以同一速度走,用慢指针寻找倒数第 n 个
- 拆分链表
- 二分搜索(binary search),也称折半搜索(half-interval search)、对数搜索(logarithmic search),是一种在有序数组中查找某一特定元素的搜索算法
- 搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到
- 并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。有一个联合-查找算法(Union-find Algorithm)定义了两个用于此数据结构的操作: - Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。 - Union:将两个子集合并成同一个集合。 由于支持这两种操作,一个不相交集也常被称为联合-查找数据结构(Union-find Data Structure)或合并-查找集合(Merge-find Set)
- 把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并
- 贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解
- 回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就 “回溯” 返回,尝试别的路径
- 广度优先搜索(BFS)类似树的按层遍历
- 其过程为:首先访问初始点,并将其标记为已访问过,接着访问所有未被访问过可到达的邻接点,以此类推,直到所有和初始点有路径相通的顶点都被访问过为止
- 深度优先搜索(DFS)所遵循的搜索策略是尽可能“深”地搜索树
- 基本思想是:为了求得问题的解,先选择某一种可能情况向前(子结点)探索,在探索过程中,一旦发现原来的选择不符合要求,就回溯至父亲结点重新选择另一结点,继续向前探索,如此反复进行,直至求得最优解
- 深度优先搜索的实现方式可以采用递归或者栈来实现
时间复杂度:O(n^2)
- 比较前后相邻的二个数据,如果前面数据大于后面的数据,就将这二个数据交换
- 这样对数组的第 0 个数据到 N-1 个数据进行一次遍历后,最大的一个数据就“沉”到数组第 N-1 个位置
- N=N-1,如果 N 不为 0 就重复前面二步,否则排序完成
public static void bubbleSort1(int [] a){
int i, j;
for(i=0; i<arr.length-1; i++){//表示n次排序过程。
for(j=1; j<arr.length-i; j++){
if(a[j-1] > a[j]){//前面的数字大于后面的数字就交换
//交换a[j-1]和a[j]
int temp;
temp = a[j-1];
a[j-1] = a[j];
a[j]=temp;
}
}
}
}时间复杂度:O(n^2)
- 将一个记录插入到已经排好的有序表中,从而得到一个新的、记录数增 1 的有序表
- 接着从第二个记录开始,按照记录的大小依次将当前处理的记录插入到其之前的有序序列中,直到最后一个记录插到有序序列中为止
public static void insertSort(int[] a) {
int i, j, insertNote;// 要插入的数据
for (i = 1; i < a.length; i++) {// 从数组的第二个元素开始循环将数组中的元素插入
insertNote = a[i];// 设置数组中的第2个元素为第一次循环要插入的数据
j = i - 1;
while (j >= 0 && insertNote < a[j]) {
a[j + 1] = a[j];// 如果要插入的元素小于第j个元素,就将第j个元素向后移动
j--;
}
a[j + 1] = insertNote;// 直到要插入的元素不小于第j个元素,将insertNote插入到数组中
}
}时间复杂度:O(logn)
- 先从序列中取出一个数作为基准数;
- 分区过程:将把这个数大的数全部放到它的右边,小于或者等于它的数全放到它的左边;
- 递归地对左右子序列进行步骤 2,直到各区间只有一个数
public static void main(String[] args) {
int[] a = new int[]{2,7,4,5,10,1,9,3,8,6};
int[] b = new int[]{1,2,3,4,5,6,7,8,9,10};
int[] c = new int[]{10,9,8,7,6,5,4,3,2,1};
int[] d = new int[]{1,10,2,9,3,2,4,7,5,6};
sort(a, 0, a.length-1);
System.out.println("排序后的结果:");
for(int x : a){
System.out.print(x+" ");
}
}
/**
* 排序
* @param a
* @param start
* @param end
*/
public static void sort(int[] a, int start, int end){
if(start > end){
//如果只有一个元素,就不用再排下去了
return;
}
else{
//如果不止一个元素,继续划分两边递归排序下去
int partition = divide(a, start, end);
sort(a, start, partition-1);
sort(a, partition+1, end);
}
}
/**
* 将数组的某一段元素进行划分,小的在左边,大的在右边
* @param a
* @param start
* @param end
* @return
*/
public static int divide(int[] a, int start, int end){
//每次都以最右边的元素作为基准值
int base = a[end];
//start一旦等于end,就说明左右两个指针合并到了同一位置,可以结束此轮循环。
while(start < end){
while(start < end && a[start] <= base)
//从左边开始遍历,如果比基准值小,就继续向右走
start++;
//上面的while循环结束时,就说明当前的a[start]的值比基准值大,应与基准值进行交换
if(start < end){
//交换
int temp = a[start];
a[start] = a[end];
a[end] = temp;
//交换后,此时的那个被调换的值也同时调到了正确的位置(基准值右边),因此右边也要同时向前移动一位
end--;
}
while(start < end && a[end] >= base)
//从右边开始遍历,如果比基准值大,就继续向左走
end--;
//上面的while循环结束时,就说明当前的a[end]的值比基准值小,应与基准值进行交换
if(start < end){
//交换
int temp = a[start];
a[start] = a[end];
a[end] = temp;
//交换后,此时的那个被调换的值也同时调到了正确的位置(基准值左边),因此左边也要同时向后移动一位
start++;
}
}
//这里返回start或者end皆可,此时的start和end都为基准值所在的位置
return end;
}时间复杂度:O(nlogn)
- 构建初始堆,将待排序列构成一个大顶堆(或者小顶堆),升序大顶堆,降序小顶堆;
- 将堆顶元素与堆尾元素交换,并断开(从待排序列中移除)堆尾元素。
- 重新构建堆。
- 重复 2~3,直到待排序列中只剩下一个元素(堆顶元素)
图解地址:https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190329000537287-1110479343.png
{kind=link}
- 大顶堆原理:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大顶堆。大顶堆要求根节点的关键字既大于或等于左子树的关键字值,又大于或等于右子树的关键字值。
- 小顶堆原理:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者,称为小顶堆。小堆堆要求根节点的关键字既小于或等于左子树的关键字值,又小于或等于右子树的关键字值
- 介绍的图片地址:https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190329000535006-1523603451.png
{kind=link}
public static void main(String[] args) {
int[] arr = {16, 7, 3, 20, 17, 8};
heapSort(arr);
for (int i : arr) {
System.out.print(i + " ");
}
}
/**
* 创建堆,
* @param arr 待排序列
*/
private static void heapSort(int[] arr) {
//创建堆
for (int i = (arr.length - 1) / 2; i >= 0; i--) {
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr, i, arr.length);
}
//调整堆结构+交换堆顶元素与末尾元素
for (int i = arr.length - 1; i > 0; i--) {
//将堆顶元素与末尾元素进行交换
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
//重新对堆进行调整
adjustHeap(arr, 0, i);
}
}
/**
* 调整堆
* @param arr 待排序列
* @param parent 父节点
* @param length 待排序列尾元素索引
*/
private static void adjustHeap(int[] arr, int parent, int length) {
//将temp作为父节点
int temp = arr[parent];
//左孩子
int lChild = 2 * parent + 1;
while (lChild < length) {
//右孩子
int rChild = lChild + 1;
// 如果有右孩子结点,并且右孩子结点的值大于左孩子结点,则选取右孩子结点
if (rChild < length && arr[lChild] < arr[rChild]) {
lChild++;
}
// 如果父结点的值已经大于孩子结点的值,则直接结束
if (temp >= arr[lChild]) {
break;
}
// 把孩子结点的值赋给父结点
arr[parent] = arr[lChild];
//选取孩子结点的左孩子结点,继续向下筛选
parent = lChild;
lChild = 2 * lChild + 1;
}
arr[parent] = temp;
}时间复杂度:O(nlogn)
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个变量,初始值分别为两个已经排序序列的起始位置;
- 比较以两个变量为下标的元素,选择相对较小的元素放入到合并空间,并使其下标值为下一位置下标;
- 重复步骤三直到左下标超过右下标;
- 将另一序列剩下的所有元素直接复制到合并序列尾
- 介绍地址:https://blog.csdn.net/weixin_41362649/article/details/81973942
public static void main(String[] args) {
int[] arr = {4, 2, 6, 1, 3, 8, 5, 9};
/*
* 归并排序
* 对上下限值分别为0和arr.length-1的记录序列arr进行归并排序
*/
mergeSort(arr, 0, arr.length-1);
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
/**
* 归并排序
* @param arr
* @param left
* @param right
*/
public static void mergeSort(int[] arr, int left, int right) {
if(null == arr) {
return;
}
if(left < right) {
//找中间位置进行划分
int mid = (left+right)/2;
//对左子序列进行递归归并排序
mergeSort(arr, left, mid);
//对右子序列进行递归归并排序
mergeSort(arr, mid+1, right);
//“合”。 进行归并
merge(arr, left, mid, right);
}
}
/**
* 进行归并
* @param arr
* @param left
* @param mid
* @param right
*/
private static void merge(int[] arr, int left, int mid, int right) {
int[] tempArr = new int[arr.length];
int leftStart = left;
int rightStart = mid+1;
int tempIndex = left;
while(leftStart <= mid && rightStart <= right) {
if(arr[leftStart] < arr[rightStart]) {
tempArr[tempIndex++] = arr[leftStart++];
} else {
tempArr[tempIndex++] = arr[rightStart++];
}
}
while(leftStart <= mid) {
tempArr[tempIndex++] = arr[leftStart++];
}
while(rightStart <= right) {
tempArr[tempIndex++] = arr[rightStart++];
}
while(left <= right) {
arr[left] = tempArr[left++];
}
}- 重写 LinkedHashMap,重写 accessOrder 构造参数和 removeEldestEntry 方法,put 的时候,若该方法返回 true,便会移除该 map 中最老的键和值
- 使用双向链表实现,add 的时候,若元素存在,将元素移动到队尾;若元素不存在,判断链表是否满,如果满,则删除队首元素,放入队尾元素,如果不满,放入队尾元素
哈希算法又称为摘要算法,它可以将任意数据通过一个函数转换为较短且长度固定的二进制哈希值,函数与数据串之间形成一一映射的关系
- MD5:信息-摘要算法(Message-Digest Algorithm 5),从 MD3、MD4 发展而来,输入不定长度信息,输出固定长度 128-bits
- SHA1:安全散列算法 1(Secure Hash Algorithm 1),由美国国家安全局设计,消息长度必须小于 2^64 位,SHA1 会产生一个 160bit 的消息摘要
- SHA2:安全散列算法 2(Secure Hash Algorithm 2),包括 SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256 六个不同的算法标准,由美国国家安全局研发,属于 SHA 算法之一,是 SHA-1 的后继者,SHA-224 和 SHA-256 消息长度也必须小于 2^64 位,算法名的数字即为消息摘要的长度,例如 SHA-256 的消息摘要长度为 256bit
- MurmurHash:由 Austin Appleby 在 2008 年发明, 并出现了多个变种,与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好,Guava、Jedis、Cassandra 的工具类中都有实现
- 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即 H(key)=key 或 H(key) = a?key + b,其中 a 和 b 为常数(这种散列函数叫做自身函数)
- 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址
- 平方取中法:取关键字平方后的中间几位作为散列地址
- 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址
- 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合
- 除留余数法:取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址。即 H(key) = key MOD p, p《=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对 p 的选择很重要,一般取素数或 m,若 p 选的不好,容易产生同义词
java.lang.String 的 hashCode 方法:
使用 String 的 char 数组的数字每次乘以 31 再叠加最后返回,因此,每个不同的字符串,返回的 hashCode 肯定不一样
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与 2 相乘等价于移位运算(低位补 0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5) - i, 现代的 VM 可以自动完成这种优化。也可以使用 63 或者 15,但 63 容易溢出,而 15 又太小
HashMap 的 Hash 算法实现:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}介绍地址:https://zhuanlan.zhihu.com/p/34985026
一致性哈希算法主要用来解决分布式环境下环境不稳定导致 Hash 值取模无法满足应用场景的问题
- 普通 Hash 算法,得到的结果一般需要进行取模,而一致性 Hash 算法是对 2^32 取模
- 一致性 Hash 算法将整个哈希值空间组织成一个哈希函数 H 的值空间为 0-2^32-1 的虚拟圆环(Hash 环),使得每次 Hash 的值都在同一个区域
- 容错性和可扩展性:一致性 Hash 算法对于节点的增减都只需重定位环空间中的一小部分数据(新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据),具有较好的容错性和可扩展性
- 数据倾斜问题:一致性 Hash 算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,为了解决这种数据倾斜问题,一致性 Hash 算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点
snowflake,Twitter 开源的分布式唯一 ID 生成算法
- 最高位是符号位,始终为 0,Linux 补码的符号位,0 表示正数
- 41 位的时间序列,精确到毫秒级,41 位的长度可以使用 69 年。时间位还有一个很重要的作用是可以根据时间进行排序
- 10 位的机器标识,10 位的长度最多支持部署 1024 个节点,10 位机器标识又分为 workerId(5 位)+datacenterId(5 位)
- 12 位的计数序列号,序列号即一系列的自增 id,可以支持同一节点同一毫秒生成多个 ID 序号,12 位的计数序列号支持每个节点每毫秒产生 2^12=4096 个 ID 序号
mport lombok.extern.slf4j.Slf4j;
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
/**
* Twitter_Snowflake
* SnowFlake的结构如下(每部分用-分开):
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,
* 由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。
* 41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
* 加起来刚好64位,为一个Long型。
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,
* 经测试,SnowFlake每秒能够产生26万ID左右。
* @author Twitter
*/
@Slf4j
final class SnowflakeIdWorker {
/**
* 开始时间截 (2015-01-01)
*/
private final long twepoch = 1488297600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = ~(-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = ~(-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = ~(-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
/**
* 可以接受的时间回拨最大毫秒数
*/
private long maxBackwardMillis = 1000;
SnowflakeIdWorker() {
long datacenterId = getDatacenterId(maxDatacenterId);
long workerId = getWorkerId(datacenterId, this.maxWorkerId);
checkAndSetWorkerIdAndDatacenterId(workerId, datacenterId);
}
private void checkAndSetWorkerIdAndDatacenterId(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new SnowflakeException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new SnowflakeException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
log.info("snowflake workerId: {}", workerId);
log.info("snowflake datacenterId: {}", datacenterId);
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
synchronized long nextId() {
long timestamp = System.currentTimeMillis();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
//如果时钟回拨在可接受范围内, 直接等待
if (timestamp - lastTimestamp <= maxBackwardMillis) {
LockSupport.parkNanos(TimeUnit.MILLISECONDS.toNanos(maxBackwardMillis));
timestamp = System.currentTimeMillis();
}
if (timestamp < lastTimestamp) {
throw new SnowflakeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,直到获得新的时间戳
long millis;
while ((millis = System.currentTimeMillis()) <= lastTimestamp) {
timestamp = millis;
}
}
} else {
//时间戳改变,毫秒内序列重置
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
}
/**
* 获取 maxWorkerId
*/
protected static long getWorkerId(long dataCenterId, long maxWorkerId) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(dataCenterId);
//用当前JVM进程的PID作为workerId
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
//获取jvm pid
stringBuilder.append(name.split("@")[0]);
}
//MAC + PID 的 hashcode 获取16个低位
return (stringBuilder.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* 数据标识id部分
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1]) | (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
log.error(" getDatacenterId error", e);
}
return id;
}
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
}- 控制单位时间内的请求数量
- 初始化时间区间,用 AtomicInteger 计数
- 滑动窗口是对计数器方式的改进, 增加一个时间粒度的度量单位
- 可以用 ConcurrentHashMap+AtomicInteger 实现滑动窗口,异步线程清理 Map 中过期的数据
- 也可以用 ConcurrentLinkedQueue 实现,插入时遍历当前时间窗口的数量是否超过限制,异步线程清理 Queue 中过期的数据
- 规定固定容量的桶, 有水进入, 有水流出. 对于流进的水我们无法估计进来的数量、速度, 对于流出的水我们可以控制速度
- 可以用信号量 Semaphore 实现,也可以用普通数字累加实现
- 规定固定容量的桶,token 以固定速度往桶内填充,当桶满时 token 不会被继续放入,每过来一个请求把 token 从桶中移除, 如果桶中没有 token 不能请求
- 可以用信号量 Semaphore 实现,也可以用普通数字累减实现