- JAVA 基础
- 位运算
- 基础数据类型
- switch
- IO
- IO 密集型&CPU 密集型
- 反射
- 代理
- 序列化与反序列化
- 范型
- finally 和 return 的执行顺序
- CET、UTC、GMT、CST(时间)
- 设计模式
- JAVA 动态字节码技术
- java 常见的字节码操作类库
- Enumeration 和 Iterator 区别
- fail-fast 和 fail-safe
- Copy-On-Write
- Queue&Deque
- Collection
- ArrayList、LinkedList、Vector、SynchronizedList、CopyOnWriteArrayList
- Set
- HashSet、LinkedHashSet、TreeSet
- Set 和 List 区别
- HashMap、HashTable、LinkedHashMap、TreeMap、ConcurrentHashMap、ConcurrentSkipListMap
- HashMap
- Stream
- JVM
- 锁
- 线程
- JUC&Unsafe
- LockSupport
- AQS(AbstractQueuedSynchonizer)(见上文)
- ReentrantLock(见上文)
- ReentrantReadWriteLock
- StampedLock
- CountDownLatch(倒数计数器)
- CyclicBarrier(循环屏障)
- Phaser(阶段)
- Semaphore(信号量)
- Exchanger(线程数据交换器)
- BlockingQueue
- BlockingDeque
- ArrayBlockingQueue(数组阻塞队列)
- LinkedBlockingQueue(链式阻塞队列)
- LinkedBlockingDeque(链式阻塞双端队列)
- ConcurrentLinkedQueue
- ConcurrentLinkedDeque
- DelayQueue(延迟队列)
- PriorityBlockingQueue(具有优先级的阻塞队列)
- SynchronousQueue(同步队列)
- LinkedTransferQueue
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- ConcurrentSkipListSet
- ConcurrentHashMap
- ConcurrentSkipListMap
- Atomic 原子类
- ForkJoinPool
- Executors
- FutureTask
- Future
- CompletableFuture
- ThreadPoolExecutor
- ScheduledThreadExecutor
- 计算机中数据都以二进制存储,其中整数占 4byte,即 32bit
- 5 的补码:0000 0000 0000 0000 0000 0000 0000 0101(最高位表示正负)
- 3 的补码:0000 0000 0000 0000 0000 0000 0000 0011
- 规则:如果相对应位都是 1,则结果为 1,否则为 0
- 位与运算的结果:0000 0000 0000 0000 0000 0000 0000 0001,即 1,换成十进制为 1
- 规则:如果相对应位都是 0,则结果为 0,否则为 1
- 位或运算的结果:0000 0000 0000 0000 0000 0000 0000 0111,即 111,换成十进制为 7
- 规则:如果相对应位值相同,则结果为 0,否则为 1
- 位异或运算的结果:0000 0000 0000 0000 0000 0000 0000 0110
- 规则:按位取反运算符翻转操作数的每一位,即 0 变成 1,1 变成 0
- 位非运算的结果:1111 1111 1111 1111 1111 1111 1111 1010,换成十进制为-6
- 往左位移 2 位,得到 0000 0000 0000 0000 0000 0000 0001 0100,即 10100,换成十进制为 20
- 公式:a << b = a * (2 ^ b)
- int 为 32bit,如果 int 左移超过 32 位,即等价于左移位数对 32 取模,long 类型也是如此,例如:1<<50=1<<18,1L<<65=1L<<1
- 往左位移 2 位,得到 0000 0000 0000 0000 0000 0000 0001 0100,即 10100,换成十进制为 20
- 与左移的区别:会连同符号位一起位移,而正常位移不会移动符号位
- 往右位移 2 位,得到 0000 0000 0000 0000 0000 0000 0000 0001,即 10100,换成十进制为 1
- 公式:a >> b = a / ( 2 ^ b )
- int 为 32bit,如果 int 右移超过 32 位,即等价于右移位数对 32 取模,long 类型也是如此,例如:1>>50=1>>18,1L>>65=1L>>1
- 往右位移 2 位,得到 0000 0000 0000 0000 0000 0000 0000 0001,即 10100,换成十进制为 1
- 与右移的区别:会连同符号位一起位移,而正常位移不会移动符号位
- byte/boolean 用 1 个字节来存储,char/short 用 2 个字节存储,float/int 用 4 个字节存储,double/long 用 8 个字节存储
- JVM 会缓存部分基础封装类型的值,Byte, Short, Long 有固定范围: -128 到 127。对于 Character, 范围是 0 到 127。除了 Integer 以外,这个范围都不能改变
- Integer 在 JVM 中只会缓存-128-127,其余的都不会缓存,不能用==判断相等
- 由于计算机中保存的小数其实是十进制的小数的近似值,并不是准确值,所以 float 和 double 会丢失精度
- String 对象无法被修改,String 类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象(会有大量时间浪费在垃圾回收上,因为每次试图修改都有新的 string 对象被创建出来)
- 如果需要修改字符串,应该使用 StringBuffer 或者 StringBuilder
- StringBuilder 内部使用可变字符数组(char[] ),初始字符数组容量为 16,存在扩容,其 append 拼接字符串方法内部调用 System 的 native 方法,进行数组的拷贝,不会重新生成新的 StringBuilder 对象
- StringBuilder 扩容的大小是新字符串的长度的 2 倍+2(+2 是考虑到 append()之后可能会加分隔符,而 char 在 java 中占 2 个字节)
- StringBuilder 每次调用 toString 方法而重新生成的 String 对象,不会共享 StringBuilder 对象内部的 char[],会进行一次 char[]的 copy 操作(非线程安全)
- jdk6 中 subString 时,不会创建新的字符串,而是引用旧的字符串的字符数组,只是改变了 offset 和 count,如果字符串比较大,导致字符数组一直无法释放,造成内存浪费,如果一直执行 subString,会造成内存泄露,jdk7 中会先将字符数组 copy 一份,然后再截取
- 拼接字符串方法:+、string.concat、StringBuffer、StringBuilder、StringUtils.join、String.join(jdk8),其中+会被编译成 new StringBuilder,concat 每次都会创建新的 String,不推荐使用,join 方法都是通过 StringBuilder 来实现的,速度比较:StringBuilder<StringBuffer<concat<+<StringUtils.join
- StringBuilder 和 StringBuffer 的区别:都是使用字符数组和 count,动态扩展字符数组,但是 StringBuffer 是线程安全的,因为 append/toString 等方法声明了 synchronized
- switch 支持的数据类型:byte short int char String
- jdk7 中 switch 对 char 的支持
- 实际上比较的是 ascii 码,编译器会把 char 型变量转换成对应的 int 型变量
- jdk7 中 switch 对 String 的支持
- 通过 equals()和 hashCode()方法来实现,switch 中比较的是 hashcode,但是因为 hashcode 可能会变,所以在每个 case 中会再用 equals 比较一次字符串的值
- switch 对枚举的支持
- 实际上比较的是枚举的 ordinal(序号,整数类型)
- char+int 或者 char+char 会的到一个整数,而不是 String,因为 char 相加,实际上加的是 char 的 ascii 值
- == 和 equals 的区别:
- == 的作用:
- 基本类型:比较的是值是否相同
- 引用类型:比较的是引用是否相同
- equals 方法取决于具体实现
- 示例:
String x = "string"; String y = "string"; String z = new String("string"); System.out.println(x==y); // true System.out.println(x==z); // false System.out.println(x.equals(y)); // true
- == 的作用:
- JDK12 开始有 switch 表达式
- hashCode()和 equals():两个方法没有必然的联系,都取决于具体实现
- 布隆过滤器(Bloom Filter)本质上是由长度为 m 的位向量(位数组)或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,然后提供 K 个不同的哈希函数,存储数据时,将数据按照 K 个哈希函数得到不同 Hash 值,作为向量位,并将对应位的值置为 1
- 优点:海量数据的情况下,空间效率高,查询效率也高
- 缺点:有一定的误识别率,删除困难
- 位图,基本原理就是用一个 bit 位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的
- 多张 BitMap 进行聚合运算,实际上相当于矩阵运算
- Redis 的实现:bits
- 使用 Long 数组来存储位图,每一个 Long 表示 64(2 的 6 次方)bit 的 X 轴,数组下标表示 Y 轴
- 设置值时,bitIndex>>6 即 bitIndex/64 表示数组的下标,1L << bitIndex 表示对应 bit 位的值(long 类型左移超过 64 位,等价于左移位数对 64 取模)
- 然后用 words[wordIndex] |= 1L << bitIndex 得出具体下标的 long 值,最后根据下标设置值
- 明文加密算法
- Base32、Base64、BinaryCodec、Hex
- 摘要/杂凑算法
- Hmac、MD5、SHA、SM3
- 对称加密算法
- AES、Blowfish、DES、DESede、RC4、SM4
- AES 原理:https://www.jianshu.com/p/9e207b910abb?from=groupmessage
- 非对称加密算法
- RSA、SM2
- RSA 原理:利用大整数分解质因数极度困难来实现算法安全性,https://www.jianshu.com/p/685cfeffe703
- SM2 原理:利用离散对数问题来实现算法安全性,https://blog.csdn.net/boliwu/article/details/81510305
- 同态加密
- 同态加密(Homomorphic Encryption, HE)是指满足密文同态运算性质的加密算法,即数据经过同态加密之后,对密文进行特定的计算,得到的密文计算结果在进行对应的同态解密后的明文等同于对明文数据直接进行相同的计算,实现数据的“可算不可见”
- 如果一种同态加密算法支持对密文进行任意形式的计算,则称其为全同态加密(Fully Homomorphic Encryption, FHE)
- 如果支持对密文进行部分形式的计算,例如仅支持加法、仅支持乘法或支持有限次加法和乘法,则称其为半同态加密或部分同态加密,英文简称为 SWHE(Somewhat Homomorphic Encryption)或 PHE(Partially Homomorphic Encryption)
- 拜占庭问题(Byzantine Problem)又叫拜占庭将军(Byzantine Generals Problem)问题,讨论的是允许存在少数节点作恶(消息可能被伪造)场景下的如何达成共识问题,用于解决去中心化的共识机制问题
- 简单介绍地址:https://blog.csdn.net/Deacoo/article/details/84779159
- 共识算法,通过算法手段,让各个参与方对某一提案达成一致/共识
- 主要用于解决去中心化的共识机制问题,常用于区块链技术中
- PBFT(Practical Byzantine Fault Tolerance,实用拜占庭容错算法)
- PoW(Proof of Work,工作量证明)(比特币使用的算法)
- PoS(Proof of Stake,权益证明)
- DPoS(Delegate Proof of Stake,委托权益证明)
- Ripple(瑞波)
- 分布式一致性算法(Pasox、Raft)
- BIO:BIO 即 Block I/O , 同步阻塞 I/O 模式
- NIO:NIO 即 New I/O,同时支持阻塞与非阻塞模式
- AIO:AIO 即 Async 非阻塞,是异步非阻塞的 IO
- BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,但程序直观简单易理解
- NIO 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4 开始支持
- AIO 方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK7 开始支持
- CPU 密集型: 也叫计算密集型,指的是程序主要消耗的是 CPU 资源,I/O 在很短的时间就可以完成,所以为了降低 Linux 内核态和用户态之前频繁切换的代价(多线程同时执行时,CPU 会一直切换内核态和用户态,耗费性能),需要配置尽可能少的线程,普通情况下建议线程数=Ncpu+1
- IO 密集型: 指的是 CPU 多数时候都在等 I/O (硬盘/内存/网络) 的读/写操作,CPU 占用率低,所以为了尽可能提升 CPU 的利用率,需要配置尽可能多的线程, 普通情况下建议线程数=Ncpu*2
反射机制指的是程序在运行时能够获取自身的信息
- 原理:
- 反射类及反射方法的获取,都是通过从列表中搜寻查找匹配的方法,所以查找性能会随类的大小方法多少而变化
- 每个类都会有一个与之对应的 Class 实例,从而每个类都可以获取 method 反射方法,并作用到其他实例身上
- 反射也是考虑了线程安全的
- 反射使用软引用 RelectionData(存储 Field、Method、Constructor、Class 信息)缓存 class 信息,避免每次重新从 jvm 获取带来的开销
- 反射调用多次生成新代理 Accessor, 而通过字节码生存的则考虑了卸载功能,所以会使用独立的类加载器
- 当找到需要的 Method,都会通过 ReflectionFactory.copy 方法 copy 一份出来,而不是使用原来的实例,从而保证数据隔离
- 调度反射方法,最终是由 jvm 执行 invoke0()执行,invoke0 方法是一个 native 方法,它在 HotSpot JVM 里调用 JVM_InvokeMethod 函数
- 作用:
- 在运行时判断任意一个对象所属的类
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时任意调用一个对象的方法
- 在运行时构造任意一个类的对象
- 代理类是由程序员自己编写的,在编译期就确定好了的
- 在接口实现类的方法中,代理调用其他接口实现类的方法,即为静态代理
动态代理的实现方式:
-
JDK 动态代理:java.lang.reflect 包中的 Proxy 类和 InvocationHandler 接口提供了生成动态代理类的能力
//JDK动态代理实现InvocationHandler接口 public class JdkProxy implements InvocationHandler { private Object target ;//需要代理的目标对象 @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.out.println("JDK动态代理,监听开始!"); Object result = method.invoke(target, args); System.out.println("JDK动态代理,监听结束!"); return result; } //定义获取代理对象方法 private Object getJDKProxy(Object targetObject){ //为目标对象target赋值 this.target = targetObject; //JDK动态代理只能针对实现了接口的类进行代理,newProxyInstance 函数所需参数就可看出 return Proxy.newProxyInstance(targetObject.getClass().getClassLoader(), targetObject.getClass().getInterfaces(), this); } public static void main(String[] args) { JdkProxy jdkProxy = new JdkProxy();//实例化JDKProxy对象 UserManager user = (UserManager) jdkProxy.getJDKProxy(new UserManagerImpl());//获取代理对象 user.addUser("admin", "123123");//执行新增方法 } }
-
Cglib 动态代理:Cglib (Code Generation Library )是一个第三方代码生成类库,运行时在内存中动态生成一个子类(利用 ASM 技术,将代理对象类生成的 class 文件加载进来,通过修改其字节码生成子类)对象从而实现对目标对象功能的扩展
//Cglib动态代理,实现MethodInterceptor接口 public class CglibProxy implements MethodInterceptor { private Object target;//需要代理的目标对象 //重写拦截方法 @Override public Object intercept(Object obj, Method method, Object[] arr, MethodProxy proxy) throws Throwable { System.out.println("Cglib动态代理,监听开始!"); Object invoke = method.invoke(target, arr);//方法执行,参数:target 目标对象 arr参数数组 System.out.println("Cglib动态代理,监听结束!"); return invoke; } //定义获取代理对象方法 public Object getCglibProxy(Object objectTarget){ //为目标对象target赋值 this.target = objectTarget; Enhancer enhancer = new Enhancer(); //设置父类,因为Cglib是针对指定的类生成一个子类,所以需要指定父类 enhancer.setSuperclass(objectTarget.getClass()); enhancer.setCallback(this);// 设置回调 Object result = enhancer.create();//创建并返回代理对象 return result; } public static void main(String[] args) { CglibProxy cglib = new CglibProxy();//实例化CglibProxy对象 UserManager user = (UserManager) cglib.getCglibProxy(new UserManagerImpl());//获取代理对象 user.delUser("admin");//执行删除方法 } }
JDK 动态代理和 Cglib 动态代理的区别:
- JDK 的动态代理有一个限制:使用动态代理的对象必须实现一个或多个接口
- 使用 cglib 代理的对象则无需实现接口,达到代理类无侵入
- cglib 是通过继承的方式做的动态代理,因此如果某个类被标记为 final,那么它是无法使用 CGLIB 做动态代理的
- cglib 底层是 ASM 字节码生成框架,但是字节码技术生成代理类,在 JDL1.6 之前比使用 java 反射的效率要高
- 在 jdk6 之后逐步对 JDK 动态代理进行了优化,在调用次数比较少时效率高于 cglib 代理效率
- 只有在大量调用的时候 cglib 的效率高,但是在 1.8 的时候 JDK 的效率已高于 cglib
- Cglib 不能对声明 final 的方法进行代理,因为 cglib 是动态生成代理对象,final 关键字修饰的类不可变只能被引用不能被修改
- 当 bean 实现接口时,会用 JDK 代理模式
- 当 bean 没有实现接口,用 cglib 实现
- 可以强制使用 cglib(在 spring 配置中加入<aop:aspectj-autoproxy proxyt-target-class=”true”/>)
序列化是将对象的状态信息转换为可存储或传输的形式的过程。一般是以字节码或 XML 格式传输。而字节码或 XML 编码格式可以还原为完全相等的对象。这个相反的过程称为反序列化
JDK 默认提供的序列化和反序列化(对象必须实现 Serializable 接口):
public class ExternalizableDemo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//Write Obj to file
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
User1 user = new User1();
user.setName("hollis");
user.setAge(23);
oos.writeObject(user);
//Read Obj from file
File file = new File("tempFile");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
User1 newInstance = (User1) ois.readObject();
//output
System.out.println(newInstance);
}
}- Serializable 接口没有方法或字段,仅用于标识可序列化的语义
- Externalizable 继承了 Serializable,该接口中定义了两个抽象方法:writeExternal()与 readExternal(),开发人员重写 writeExternal()与 readExternal()方法才可以进行序列化操作
- 实现 Externalizable 接口的类必须要提供⼀个 public 的⽆参的构造器
- jvm 在停机的时候,可以将 Java 对象序列化成可存储或传输的形式,并保存到本地文件,当再次需要这个对象的时候, 从⽂件中读取出⼆进制流, 再从⼆进制流中反序列化出对象。
- 在进⾏反序列化时, JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进⾏⽐较, 如果相同就认为是⼀致的, 可以进⾏反序列化, 否则就会出现序列化版本不⼀致的异常, 即是 InvalidCastException
- serialVersionUID 是用来验证版本一致性的。所以在做兼容性升级的时候,serialVersionUID 的值不可随意更改
- 序列化速度快,使用 proto 编译器,自动进行序列化和反序列化,速度比 XML 和 JSON 快 5~100 倍
- 数据压缩效果好,序列化后的数据量体积小,只有 JSON 的十分之一,XML 的二十分之一
数据结构:
- Hessian 的对象序列化机制有 8 种原始类型:
原始二进制数据
boolean
64-bit date(64 位毫秒值的日期)
64-bit double
32-bit int
64-bit long
null
UTF-8 编码的 string
- 另外还包括 3 种递归类型:
list for lists and arrays
map for maps and dictionaries
object for objects
- 还有一种特殊的类型:
ref:用来表示对共享对象的引用
- JDK 5 中引⼊的⼀个新特性, 允许在定义类和接⼜的时候使⽤类型参数,最⼤的好处是可以提⾼代码的复⽤性
- 由于编译器在编译时会进行范型擦除,导致所有的泛型类实例都关联到同一份字节码上,进而导致泛型类的所有静态变量是共享的
public class StaticTest{
public static void main(String[] args){
GT<Integer> gti = new GT<Integer>();
gti.var=1;
GT<String> gts = new GT<String>();
gts.var=2;
System.out.println(gti.var);//会输出2,因为范型擦除导致
}
}
class GT<T>{
public static int var=0;
public void nothing(T x){}
}如果 try 中有 return 语句, 那么 finally 中的代码还是会执⾏。因为 return 表⽰的是要整个⽅法体返回, 所以,finally 中的语句会在 return 之前执⾏
- CET:欧洲中部时间(英語:Central European Time,CET)是比世界标准时间(UTC)早一个小时的时区名称之一
- UTC:协调世界时(Coordinated Universal Time),是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统
- GMT:格林尼治标准时间(Greenwich Mean Tim),是指位于英国伦敦郊区的皇家格林尼治天文台的标准时间,因为本初子午线被定义在通过那里的经线
- CST:北京时间(China Standard Time),又名中国标准时间,等于 GMT+8
- 关系:UTC=GMT,CET=UTC/GMT+1 小时 ,CST=UTC/GMT+8 小时,CST=CET+9
- 创建型模式
- 这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象
- 工厂模式
- 抽象工厂模式
- 单例模式
- 建造者模式
- 原型模式
- 结构型模式
- 这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式
- 适配器模式
- 桥接模式
- 过滤器模式
- 组合模式
- 装饰模式
- 外观模式
- 享元模式
- 代理模式
- 行为型模式
- 这些设计模式特别关注对象之间的通信
- 责任链模式
- 命令模式
- 解释器模式
- 迭代器模式
- 中介者模式
- 备忘录模式
- 观察者模式
- 状态模式
- 空对象模式
- 策略模式
- 模板模式
- 访问者模式
单例模式、工厂模式、抽象工厂模式、建造者模式、代理模式、装饰模式、观察者模式
public class Singleton {
//在类内部实例化一个实例
private static Singleton instance = new Singleton();
//私有的构造函数,外部无法访问
private Singleton() {
}
//对外提供获取实例的静态方法
public static Singleton getInstance() {
return instance;
}
}public class Singleton {
//定义实例
private static Singleton instance;
//私有构造方法
private Singleton(){}
//对外提供获取实例的静态方法
public static Singleton getInstance() {
//在对象被使用的时候才实例化
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}public class VolatileSingleton {
private static volatile VolatileSingleton singleton;
private VolatileSingleton() {
}
public static VolatileSingleton getSingleton() {
if (singleton == null) {
synchronized (VolatileSingleton.class) {
if (singleton == null) {
singleton = new VolatileSingleton();
}
}
}
return singleton;
}
}为什么使用 volatile(以下为隐患场景举例):
- 线程 A 发现变量没有被初始化, 然后它获取锁并开始变量的初始化
- 由于编译器生成的代码允许变量初始化完成之前更新变量并将其指向部分初始化的对象
- 线程 B 发现共享变量已经被初始化,并返回变量
- 由于线程 B 确信变量已被初始化,它没有获取锁
- 如果在 A 完成初始化之前共享变量对 B 可见(这是由于 A 没有完成初始化或者因为一些初始化的值还没有穿过 B 使用的内存(缓存一致性)),程序很可能会崩溃
public class StaticInnerClassSingleton {
//在静态内部类中初始化实例对象
private static class SingletonHolder {
private static final StaticInnerClassSingleton INSTANCE = new StaticInnerClassSingleton();
}
//私有的构造方法
private StaticInnerClassSingleton() {
}
//对外提供获取实例的静态方法
public static final StaticInnerClassSingleton getInstance() {
return SingletonHolder.INSTANCE;
}
}public enum Singleton {
INSTANCE;
Singleton() {
}
}Byte Code Engineering Library (BCEL) ,这是 Apache Software Foundation 的 Jakarta 项目的一部分。 BCEL 是 Java classworking 广泛 使用的一种 框架 , 它 可以让您深入 JVM 汇编语言进行类操作的细节。 BCEL 与 Javassist 有不同的处理字节码方法, BCEL 在实际的 JVM 指令层次上进行操作 (BCEL 拥有丰富的 JVM 指令级支持 ) 而 Javassist 所 强调 的是源代码 级别的 工作
ASM 是一个轻量级 java 字节码操作框架,直接涉及到 JVM 底层的操作和指令
- Javassist 是一个开源的分析、编辑和创建 Java 字节码 的类库 。性能较 ASM 差,跟 cglib 差不多,但是使用简单。很多开源框架都在使用它
- 简介地址:https://www.cnblogs.com/rickiyang/p/11336268.html
- Enumeration 只有 2 个函数接口,通过 Enumeration,我们只能读取集合的数据,而不能对数据进行修改
- Iterator 只有 3 个函数接口,Iterator 除了能读取集合的数据之外,也能数据进行删除操作
- Iterator 支持 fail-fast 机制,而 Enumeration 不支持
- fail-fast:遍历过程中如果元素被修改会导致遍历失败
- fail-safe:在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历
- 简称 COW,在往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器
- CopyOnWrite 容器的 add/remove 等写方法是需要加锁的,目的是为了避免 Copy 出 N 个副本出来,导致并发写,读方法不加锁(为了提高并发性能),读到的数据可能不是最新的,属于弱一致性
单向队列,先进先出,只能队尾部进,队头出
双端队列,允许两头都进,两头都出
- 提供了对集合对象进行基本操作的通用接口方法,是 list,set 等的父接口
- JAVA 提供了 Collections 工具类,包含了各种有关集合操作的静态多态方法
- ArrayList 是一个可改变大小的数组,当更多的元素加入到 ArrayList 中时,其大小将会动态地增长,内部的元素可以直接通过 get 与 set 方法进行访问,add 和 remove 的性能弱,get 和 set 性能强,默认情况下 ArrayList 的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销
- LinkedList 是一个双链表,add 和 remove 的性能强,get 和 set 性能弱,LinkedList 还实现了 Queue 接口,该接口比 List 提供了更多的方法,包括 offer()、peek()、poll()等.
- Vector 跟 ArrayList 的实现类似,但是所有读写方法都实现了 synchronized
- Vector 和 ArrayList 在更多元素添加进来时会请求更大的空间。Vector 每次请求其大小的双倍空间,而 ArrayList 每次对 size 增长 50%
- Vector 使用同步方法实现,synchronizedList 使用同步代码块实现
- SynchronizedList 有很好的扩展和兼容功能。他可以将所有的 List 的子类转成线程安全的类
- SynchronizedList 在 listIterator 的时候没有枷锁,所以进行遍历时要手动进行同步处理
- SynchronizedList 可以指定锁定的对象
- CopyOnWriteArrayList 的 add、remove 方法使用 synchronized 加了锁,当有新元素 add/remove 时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组
- CopyOnWriteArrayList 的迭代器支持 hasNext(), next()等不可变操作,但不支持可变 remove()等操作
- Arrays.asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错,只能遍历,要转成其他 List 才能增删(例如 new ArrayList())
- 使用普通 for 循环删除(需要调整循环的下标)
- 直接使用 Iterator 的 remove 进行删除
- 使用 jdk8 中提供的 filter 过滤
- 使用 jdk8 中的 removeIf 方法
- 使用 fail-safe 的集合类(例如:ConcurrentLinkedDeque)
- 基于 HashMap 实现,利用 HashMap 同一个 Hash 值只能有一个 Value 的特性来实现 Set 的去重功能
- 基于 LinkedHashMap 实现,利用 LinkedHashMap 同一个 Hash 值只能有一个 Value 的特性来实现 Set 的去重功能
- 基于 TreeMap 实现,利用 TreeMap 同一个 Hash 值只能有一个 Value 的特性来实现 Set 的去重功能
- TreeSet 是红黑树实现的,Treeset 中的数据是自动排好序的,不允许放入 null 值
- HashSet 是哈希表实现的,HashSet 中的数据是无序的,可以放入 null,但只能放入一个 null
- HashSet 基于 HashMap 实现,而 TreeMap 是基于红黑树实现的
- TreeMap 会按 key 升序排序,元素在插入 TreeSet 时 compareTo()方法要被调用,所以 TreeSet 中的元素要实现 Comparable 接口
- 当向 HashSet 中添加元素的时候,首先计算元素的 hashcode 值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置位空,就将元素添加进去;如果不为空,则用 equals 方法比较元素是否相等,相等就不添加,否则找一个空位添加
- TreeSet 是用元素的 compareTo()方法来判断重复元素的
- 都继承自 Collection
- 都是用来存储一组相同类型的元素
- List 中元素有放入顺序,元素可重复
- Set 中元素无放入顺序,元素不可重复
- HashMap 实现了 Map 接口,即允许放入 key 为 null 的元素,也允许插入 value 为 null 的元素
- 采用数组+链表的方式存储数据
- 存储的对象必须实现 hashCode()和 equals()两个方法
- 写入数据时,先根据对象的 hashCode 获取数组的下标,再获取到数组中对应位置的链表(解决了 hashcode 冲突的问题,也成为拉链法),然后插入数据到链表中,equals 方法决定对象存入链表时是覆盖还是新增
- 读取数据时,先根据对象的 hashCode 获取数组的下标,再获取到数组中对应位置的链表,然后依次遍历链表,通过 equals 方法判断是否命中
- 采用数组+链表+红黑树的方式存储数据
- 为了防止链表过长,当数组的长度大于 64 且链表的长度大于 8 的时候会将链表转换成红黑树(使用头结点的值来判断是否是链表,大于 0 表示是链表,如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树)
- 读取数据时,会根据头结点判断对应数组下标处的是链表还是红黑树,如果是链表,则遍历得到结果,如果是红黑树,执行查找得到结果
- 扩容机制:与 JDK1.7 的区别是,JDK7 是先扩容后插入新值的,JDK8 先插入新值再扩容
[介绍地址](https://zhuanlan.zhihu.com/p/82183524)
- HashMap 中存储了数组容量(capacity)、增长因子(loadFactor)、阈值(threshold)、元素数量(size),数组容量初始值为 1<<4=16,增长因子默认为 0.75,阈值等于 capacity 数组长度 乘以 loadFactor 增长因子,当元素数量大于等于阈值并且出现 hash 冲突时,HashMap 会选择对数组扩容,数组每次都是双倍扩容,将原来的 Entry 数组的元素迁移到新的 Entry 数组中,每个链表根据 hash%length 排序后拆分为高位和低位 2 个链表,然后分配到新数组中(将原来 table[i] 中的链表的所有节点,分拆到新的数组的 newTable[i]和 newTable[i + oldLength] 位置上)
- JDK8 与 JDK7 的区别是,JDK7 是先扩容后插入新值的,JDK8 先插入新值再扩容
- 为什么 capacity 数组容量必须为 2^n:为了保证通过 hash 方式获取下标的时候分布均匀。数组长度为 2 的 n 次幂的时候,不同的 key 算得得 index 相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。capacity 的值太小可能导致频繁发生扩容,影响效率,太大了又浪费空间,所以默认为 16
- 为什么负载因子的值默认为 0.75:加载因子是表示 Hash 表中元素的填满的程度,加载因子越大,填满的元素越多,空间利用率越高,但冲突的机会加大,反之加载因子越小,填满的元素越少,冲突的机会减小,但空间浪费多。冲突的机会越大,则查找的成本越高,反之,查找的成本越小,因此,必须在 "hash 冲突率"与"空间利用率"之间寻找一种平衡与折中,所以默认采用 0.75
- 如果多个线程同时定位到一个链表中的同一个 index,则会导致只有一个数据插入链表成功
- put 和 get 并发时,如果正好需要扩容,因为扩容会将旧 hash 表中元素 rehash 到新的 hash 表中,所以可能导致 get 为 null
- JDK1.7 的 HashMap,并发 PUT 可能会造成循环链表,导致 get 不存在的 key 时会出现死循环
- Hashtable 是 JDK1.0 新增的,是遗留类,项目中不应该去使用它,实现原理和 HashMap 类似,也是通过数组+链表的方式实现,但它是线程安全的,因为所有读写方法都实现了 synchronized 锁
- LinkedHashMap 是 HashMap 的直接子类,二者唯一的区别是 LinkedHashMap 在 HashMap 的基础上,在 Entry 数组之外,采用双向链表的形式将所有 entry 连接起来,这样是为保证元素的迭代顺序跟插入顺序相同,该双向链表的迭代顺序就是 entry 的插入顺序
- 写入数据时,会先执行一次查询,数据如果已存在则直接返回,数据不存在时,按照 HashMap 的方式将数据插入到对应链表中,并将数据插入到双向链表的尾部
- 迭代 LinkedHashMap 时,不需要像 HashMap 那样遍历整个 table,而只需要直接遍历 header 指向的双向链表即可,也就是说 LinkedHashMap 的迭代时间就只跟 entry 的个数相关,而跟 table 的大小无关,所以当 Map 的数据量不大,而容量很大时,LinkedHashMap 的遍历速度比 HashMap 快
- LinkedHashMap 提供了 removeEldestEntry 方法,该方法的作用是告诉 Map 是否要删除最早插入的 Entry,如果该方法返回 True,那么最早插入的元素会被删除,在每次插入新元素的之后 LinkedHashMap 会自动询问 removeEldestEntry()是否要删除最老的元素,因此可以通过重载该方法,来实现 LRU 算法(固定大小的 FIFO 策略的缓存)
- TreeMap 底层通过红黑树(Red-Black tree)实现,也就意味着 containsKey(), get(), put(), remove()都有着 O(logn)的时间复杂度
- TreeMap 不允许放入 null 值
- TreeMap 中的数据是自动排好序的,TreeMap 会按 key 升序排序,元素在插入 TreeMap 时 compareTo()方法要被调用,所以 TreeMap 中的元素要实现 Comparable 接口
-
JDK1.5~1.7 版本(分段锁):
- ConcurrentHashMap 维护了一个 Segment 数组,将整个 Hash 表划分为多个分段
- Segment 继承了 ReentrantLock,实现了独占模式的可重入锁,为每一个 segment 提供了线程安全的保障
- Segment 内部是由数组+链表组成,维护了哈希散列表的若干个桶,每个桶是由 HashEntry 构成的链表,Segment 内部的数组支持扩容
- 写入数据之前需要先获取该 Segment 的独占锁,再执行类似 HashMap 的写入逻辑
- 读取数据时,先根据 Key 计算 hash 值,找到对应的 sgment,再根据 hash 找到 sgment 内部的数组中的对应链表,最后使用 key.equals 方法遍历链表得到结果
- 缺点:最大并发度受 Segment 的个数限制
-
JDK1.8 及 1.8 之后的版本(数组+链表+红黑树)
- 采用类似 JDK1.8 的 HashMap 的数据+链表+红黑树方式存储数据
- put 时,先根据 hashcode 获取到数组下标对应的链表,如果数组对应下标的链表为空,使用 CAS 创建链表,如果链表已存在,使用 synchronized 对链表加锁,然后再插入数据
- 为了防止链表过长,当数组的长度大于 64 且链表的长度大于 8 的时候会将链表转换成红黑树(跟 JDK8 的 HashMap 一样,使用头结点的值来判断是否是链表,大于 0 表示是链表,如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树)
- 读取数据时,先根据 Key 计算 hash 值,找到数组中的对应链表,再根据头结点判断是链表或者红黑树或者正在扩容,如果是链表,则遍历得到结果,如果是红黑树,执行查找得到结果,如果正在扩容,会等待取到锁后再读取数据
- 扩容机制:数组每次都是双倍扩容,将原来的 tab 数组的元素迁移到新的 nextTab 数组中,使用多线程,每个线程可以分到 16 个链表,各自处理,不会互相影响,每个链表根据 hash%length 排序后拆分为高位和低位 2 个链表,然后分配到新数组中,如果有新的线程 put 数据,会先帮助完成扩容,再 put 数据
- ConcurrentSkipListMap 是一个内部使用跳跃表,并且支持排序和并发的一个 Map,是线程安全的
- 线程安全:Hashtable 是线程安全,HashMap 是非线程安全。HashMap 的性能会高于 Hashtable,Hashtable 的所有方法都实现了 synchronize 锁
- 是否可以使用 null 作为 key:HashMap 允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许
- 继承和实现:HashTable 继承自 Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现
- 计算 hash 的方法:Hashtable 计算 hash 是直接使用 key 的 hashcode 对 table 数组的长度直接进行取模,而 HashMap 计算 hash 是对 key 的 hashcode 进行了二次 hash,以获得更好的散列值,然后对 table 数组长度取模
- 初始容量及扩容机制:HashMap 的初始容量为 16,Hashtable 初始容量为 11。HashMap 扩容时是当前容量翻倍即:capacity 2,Hashtable 扩容时是容量翻倍+1 即:capacity (2+1)
- 遍历方式:都使用了 Iterator,但 Hashtable 还使用了 Enumeration 的方式 且用 Enumeration 时不支持 fail-fast(遍历过程中如果元素被修改会导致遍历失败,可以用 Iterator 的 remove 方法避免这种情况)
- key 规则:HashTable 直接使用对象的 hashCode,HashMap 重新计算 hash 值
- 都是使用桶数组(数组+链表)实现
- 1.7 之前的 ConcurrentHashMap 对桶数组进行了分段,并且在每一个分段上都用 ReentrantLock 锁进行了保护
- 1.8 之后的 ConcurrentHashMap 采用数组+链表+红黑树的方式实现,而加锁则采用 CAS 和 synchronized 实现
- ConcurrentHashMap 支持 fail-safe (遍历过程中如果元素被修改不会有任何影响),因为 ConcurrentHashMap 的迭代器是弱一致性
Stream 有以下特性及优点:
- 无存储。Stream 不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java 容器或 I/O channel 等
- 为函数式编程而生。对 Stream 的任何修改都不会修改背后的数据源,比如对 Stream 执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新 Stream
- 惰式执行。Stream 上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行
- 可消费性。Stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成
- HotSpot VM:绝对的主流,Oracle 开发
- JRockit VM:JDK7 开始已废除
- J9 VM:IBM 开发的一个高度模块化的 JVM
- Zing VM:Azul System 公司开发
Java 虚拟机的内存空间分为 5 个部分:
- 程序计数器(PC,Program Counter Register))
- 程序计数器是一块较小的内存空间,是当前线程正在执行的那条字节码指令的地址。若当前线程正在执行的是一个本地方法,那么此时程序计数器为 Undefined
- 作用
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制
- 在多线程情况下,程序计数器记录的是当前线程执行的位置,从而当线程切换回来时,就知道上次线程执行到哪了
- 特点
- 是一块较小的内存空间
- 线程私有,每条线程都有自己的程序计数器
- 生命周期:随着线程的创建而创建,随着线程的结束而销毁
- 是唯一一个不会出现 OutOfMemoryError 的内存区域
- Java 虚拟机栈(Java Virtual Machine Stack) - Java 虚拟机栈是描述 Java 方法运行过程的内存模型 - Java 虚拟机栈会为每一个即将运行的 Java 方法创建一块叫做“栈帧”的区域,用于存放该方法运行过程中的一些信息(局部变量表、操作数栈 、动态链接、方法出口信息等) - 入栈栈出栈过程: - 当方法运行过程中需要创建局部变量时,就将局部变量的值存入栈帧中的局部变量表中 - Java 虚拟机栈的栈顶的栈帧是当前正在执行的活动栈,也就是当前正在执行的方法,PC 寄存器也会指向这个地址 - 只有这个活动的栈帧的本地变量可以被操作数栈使用,当在这个栈帧中调用另一个方法,与之对应的栈帧又会被创建,新创建的栈帧压入栈顶,变为当前的活动栈帧 - 方法结束后,当前栈帧被移出,栈帧的返回值变成新的活动栈帧中操作数栈的一个操作数。如果没有返回值,那么新的活动栈帧中操作数栈的操作数没有变化 - 特点: - 局部变量表随着栈帧的创建而创建,它的大小在编译时确定,创建时只需分配事先规定的大小即可。在方法运行过程中,局部变量表的大小不会发生改变 - Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError - StackOverFlowError 若 Java 虚拟机栈的大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度时(常见于死循环),抛出 StackOverFlowError 异常 - OutOfMemoryError 若允许动态扩展,那么当线程请求栈时内存用完了,无法再动态扩展时,抛出 OutOfMemoryError 异常 - Java 虚拟机栈也是线程私有,随着线程创建而创建,随着线程的结束而销毁
- 本地方法栈(Native Method Stack)
- 本地方法栈是为 JVM 运行 Native 方法准备的空间,由于很多 Native 方法都是用 C 语言实现的,所以它通常又叫 C 栈。它与 Java 虚拟机栈实现的功能类似,只不过本地方法栈是描述本地方法运行过程的内存模型
- 栈帧变化过程:
- 本地方法被执行时,在本地方法栈也会创建一块栈帧,用于存放该方法的局部变量表、操作数栈、动态链接、方法出口信息等
- 方法执行结束后,相应的栈帧也会出栈,并释放内存空间。也会抛出 StackOverFlowError 和 OutOfMemoryError 异常
- 堆(Heap)
- 堆是用来存放对象的内存空间,几乎所有的对象都存储在堆中
- 特点:
- 线程共享,整个 Java 虚拟机只有一个堆,所有的线程都访问同一个堆。而程序计数器、Java 虚拟机栈、本地方法栈都是一个线程对应一个
- 在虚拟机启动时创建
- 是垃圾回收的主要场所
- 进一步可分为:新生代(Eden 区 From Survior To Survivor)、老年代
- 堆的大小既可以固定也可以扩展,但对于主流的虚拟机,堆的大小是可扩展的,因此当线程请求分配内存,但堆已满,且内存已无法再扩展时,就抛出 OutOfMemoryError 异常
- 方法区(Method Area)
- Java 虚拟机规范中定义方法区是堆的一个逻辑部分。方法区存放以下信息:
- 已经被虚拟机加载的类信息
- 常量
- 静态变量
- 即时编译器编译后的代码
- 特点:
- 线程共享。 方法区是堆的一个逻辑部分,因此和堆一样,都是线程共享的。整个虚拟机中只有一个方法区
- 永久代。 方法区中的信息一般需要长期存在,而且它又是堆的逻辑分区,因此用堆的划分方法,把方法区称为“永久代”
- 内存回收效率低。 方法区中的信息一般需要长期存在,回收一遍之后可能只有少量信息无效。主要回收目标是:对常量池的回收;对类型的卸载
- Java 虚拟机规范对方法区的要求比较宽松。 和堆一样,允许固定大小,也允许动态扩展,还允许不实现垃圾回收
- 运行时常量池
- 方法区中存放:类信息、常量、静态变量、即时编译器编译后的代码。常量就存放在运行时常量池中
- 当类被 Java 虚拟机加载后, .class 文件中的常量就存放在方法区的运行时常量池中。而且在运行期间,可以向常量池中添加新的常量。如 String 类的 intern() 方法就能在运行期间向常量池中添加字符串常量
- Java 虚拟机规范中定义方法区是堆的一个逻辑部分。方法区存放以下信息:
- JDK 1.8 同 JDK 1.7 比,最大的差别就是:元数据区取代了永久代
- 元空间的本质和永久代类似,都是对 JVM 规范中方法区的实现(不再存储字符串)
- 不过元空间与永久代之间最大的区别在于:元数据空间并不在虚拟机中,而是使用本地内存
- 字符串存在永久代中,容易出现性能问题和内存溢出
- 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
- 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
- 将 HotSpot 与 JRockit 合二为一
- 直接内存是除 Java 虚拟机之外的内存,但也可能被 Java 使用
- 在 NIO 中引入了一种基于通道和缓冲的 IO 方式。它可以通过调用本地方法直接分配 Java 虚拟机之外的内存,然后通过一个存储在堆中的 DirectByteBuffer 对象直接操作该内存,而无须先将外部内存中的数据复制到堆中再进行操作,从而提高了数据操作的效率
- 直接内存的大小不受 Java 虚拟机控制,但既然是内存,当内存不足时就会抛出 OutOfMemoryError 异常
- 直接内存与堆内存比较:
- 直接内存申请空间耗费更高的性能
- 直接内存读取 IO 的性能要优于普通的堆内存
- 直接内存作用链: 本地 IO -> 直接内存 -> 本地 IO
- 堆内存作用链:本地 IO -> 直接内存 -> 非直接内存 -> 直接内存 -> 本地 IO
Java 对象保存在内存中时,由以下三部分组成:
- 对象头(Header)
- 实例数据(Instance Data)
- 对齐填充字节(Padding)
- 对象头(Header)
- java 的对象头由以下三部分组成:
- Mark Word:Mark Word 记录了哈希码、GC 分代年龄、是否偏向锁、锁标志位、线程持有的锁、偏向线程 ID、偏向时间戳、重量级锁(ObjectMonitor)的指针等对象和锁有关的信息,Mark Word 在 32 位 JVM 中的长度是 32bit,在 64 位 JVM 中长度是 64bit,详细介绍见:https://img2018.cnblogs.com/blog/1515111/201910/1515111-20191016112055764-565022567.png
- 指向类的指针
- 数组长度(只有数组对象才有)
- java 的对象头由以下三部分组成:
- 实例数据(Instance Data)
- 实例数据部分就是成员变量的值,其中包括父类成员变量和本类成员变量
- 对齐填充字节(Padding)
- 用于确保对象的总长度为 8 字节的整数倍,HotSpot VM 的自动内存管理系统要求对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。对齐填充并不是必然存在,也没有特别的含义,它仅仅起着占位符的作用
{kind=link}
- 类加载检查
- 虚拟机在解析.class 文件时,若遇到一条 new 指令,首先它会去检查常量池中是否有这个类的符号引用,并且检查这个符号引用所代表的类是否已被加载、解析和初始化过。如果没有,那么必须先执行相应的类加载过程
- 为新生对象分配内存
- 对象所需内存的大小在类加载完成后便可完全确定,接下来从堆中划分一块对应大小的内存空间给新的对象。分配堆中内存有两种方式:
- 指针碰撞
- 如果 Java 堆中内存绝对规整(说明采用的是“复制算法”或“标记整理法”),空闲内存和已使用内存中间放着一个指针作为分界点指示器,那么分配内存时只需要把指针向空闲内存挪动一段与对象大小一样的距离,这种分配方式称为“指针碰撞”
- 空闲列表
- 如果 Java 堆中内存并不规整,已使用的内存和空闲内存交错(说明采用的是标记-清除法,有碎片),此时没法简单进行指针碰撞, VM 必须维护一个列表,记录其中哪些内存块空闲可用。分配之时从空闲列表中找到一块足够大的内存空间划分给对象实例。这种方式称为“空闲列表”
- 初始化
- 分配完内存后,为对象中的成员变量赋上初始值,设置对象头信息,调用对象的构造函数方法进行初始化。至此,整个对象的创建过程就完成了
- 对象的访问方式
- 句柄访问方式
- 堆中需要有一块叫做“句柄池”的内存空间,句柄中包含了对象实例数据与类型数据各自的具体地址信息
- 引用类型的变量存放的是该对象的句柄地址(reference)。访问对象时,首先需要通过引用类型的变量找到该对象的句柄,然后根据句柄中对象的地址找到对象
- 直接指针访问方式
- 引用类型的变量直接存放对象的地址,从而不需要句柄池,通过引用能够直接访问对象。但对象所在的内存空间需要额外的策略存储对象所属的类信息的地址
- HotSpot 采用第二种方式,即直接指针方式来访问对象,只需要一次寻址操作,所以在性能上比句柄访问方式快一倍。但像上面所说,它需要额外的策略来存储对象在方法区中类信息的地址
- 句柄访问方式
- 浅拷贝:只复制一个对象,对象内部存在的指向其他对象数组或者引用则不复制
- 深拷贝:对象及对象内部的引用均复制
- 无论是浅拷贝还是深拷贝,都需要实现 Object.clone() 方法,默认为浅拷贝
- 如果需要实现深克隆,可以通过重写 Object 类的 clone()方法实现,也可以通过序列化(Serialization)等方式来实现
- 若一个对象不被任何对象或变量引用,那么它就是无效对象,需要被回收
- 判定对象是否存活的方式
- 引用计数法
- 在对象头维护着一个 counter 计数器,对象被引用一次则计数器 +1;若引用失效则计数器 -1。当计数器为 0 时,就认为该对象无效
- 缺陷:如果两个对象相互引用,引用计数法会判定这两个对象还在使用,所占用的内存将无法回收,造成内存泄露
- 可达性分析法
- 所有和 GC Roots 直接或间接关联的对象都是有效对象,和 GC Roots 没有关联的对象就是无效对象
- GC Roots 是指:
- Java 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中引用的对象
- 方法区中常量引用的对象
- 方法区中类静态属性引用的对象
- GC Roots 并不包括堆中对象所引用的对象,这样就不会有循环引用的问题
- 目前 Java 虚拟机的主流垃圾回收器采取的是可达性分析算法
- 引用计数法
- 为什么要 Stop-the-world?
- 在多线程环境下,其他线程可能会更新已经访问过的对象中的引用,从而造成误报(将 引用设置为 null)或者漏报(将引用设置为未被访问过的对象)。
- 一旦从原引用访问已经被回收了的对象,则很有 可能会直接导致 Java 虚拟机崩溃
- 所以需要停止其他非垃圾回收线程的工作,直到完成垃圾回收。这也就造成了 垃圾回收所谓的暂停时间(GC pause)
- Java 虚拟机中的 Stop-the-world 是通过安全点(safepoint)机制来实现的。当 Java 虚拟机 收到 Stop-the-world 请求,它便会等待所有的线程都到达安全点,才允许请求 Stop-the-world 的线程进行独占的工作
- 回收的范围
- 堆中无效对象
- JVM 会判断此对象是否有必要执行 finalize() 方法,如果对象没有覆盖 finalize() 方法,或者 finalize() 方法已经被虚拟机调用过,那么视为“没有必要执行”。那么对象基本上就真的被回收了
- 如果对象被判定为有必要执行 finalize() 方法,那么对象会被放入一个 F-Queue 队列中,虚拟机会以较低的优先级执行这些 finalize()方法,但不会确保所有的 finalize() 方法都会执行结束。如果 finalize() 方法出现耗时操作,虚拟机就直接停止指向该方法,将对象清除
- 如果在执行 finalize() 方法时,将 this 赋给了某一个引用,那么该对象就重生了。如果没有,那么就会被垃圾收集器清除
- 任何一个对象的 finalize() 方法只会被系统自动调用一次,如果对象面临下一次回收,它的 finalize() 方法不会被再次执行
- 方法区内存
- 方法区中存放生命周期较长的类信息、常量、静态变量,每次垃圾收集只有少量的垃圾被清除。方法区中主要清除两种垃圾:
- 废弃常量
- 只要常量池中的常量不被任何变量或对象引用,那么这些常量就会被清除掉
- 无用的类(Class 的回收条件)
- 判定一个类是否是“无用的类”,条件较为苛刻,需要满足以下条件
- 该类的所有对象都已经被清除
- 加载该类的 ClassLoader 已经被回收
- 该类的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
- 判定一个类是否是“无用的类”,条件较为苛刻,需要满足以下条件
- 废弃常量
- 方法区中存放生命周期较长的类信息、常量、静态变量,每次垃圾收集只有少量的垃圾被清除。方法区中主要清除两种垃圾:
- 堆中无效对象
- 标记-清除算法
- 标记的过程:遍历所有的 GC Roots,然后将所有 GC Roots 可达的对象标记为存活的对象
- 清除的过程:遍历堆中所有的对象,将没有标记的对象全部清除掉。与此同时,清除那些被标记过的对象的标记,以便下次的垃圾回收
- 缺点:
- 效率问题:标记和清除两个过程的效率都不高
- 空间问题:标记清除之后会产生大量不连续的内存碎片,碎片太多可能导致以后需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作
- 复制算法(新生代)
- 将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完,需要进行垃圾收集时,就将存活者的对象复制到另一块上面,然后将第一块内存全部清除
- 缺点:内存缩小为原来的一半,浪费空间
- 优点:不会有内存碎片的问题
- 为了解决空间利用率问题,可以将内存分为三块: Eden、From Survivor、To Survivor,比例是 8:1:1,每次使用 Eden 和其中一块 Survivor。回收时,将 Eden 和 Survivor 中还存活的对象一次性复制到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才使用的 Survivor 空间。这样只有 10% 的内存被浪费
- 但是我们无法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够,需要依赖其他内存(指老年代)进行分配担保
- 为对象分配内存空间时,如果 Eden+Survivor 中空闲区域无法装下该对象,会触发 MinorGC 进行垃圾收集。但如果 Minor GC 过后依然有超过 10% 的对象存活,这样存活的对象直接通过分配担保机制进入老年代,然后再将新对象存入 Eden 区
- 标记-整理算法(老年代)
- 标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历 GC Roots,然后将存活的对象标记
- 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段
- 这是一种老年代的垃圾收集算法。老年代的对象一般寿命比较长,因此每次垃圾回收会有大量对象存活,如果采用复制算法,每次需要复制大量存活的对象,效率很低
- 根据对象存活周期的不同,将内存划分为几块。一般是把 Java 堆分为新生代和老年代,针对各个年代的特点采用最适当的收集算法:
- 新生代:复制算法
- 老年代:标记-清除算法、标记-整理算法
- 新生代垃圾收集器
- Serial 垃圾收集器(单线程)
- 只开启一条 GC 线程进行垃圾回收,并且在垃圾收集过程中停止一切用户线程(Stop The World)
- 一般客户端应用所需内存较小,不会创建太多对象,而且堆内存不大,因此垃圾收集器回收时间短,即使在这段时间停止一切用户线程,也不会感觉明显卡顿。因此 Serial 垃圾收集器适合客户端使用
- ParNew 垃圾收集器(多线程)
- ParNew 是 Serial 的多线程版本。由多条 GC 线程并行地进行垃圾清理。但清理过程依然需要 Stop The World
- ParNew 追求“低停顿时间”,与 Serial 唯一区别就是使用了多线程进行垃圾收集,在多 CPU 环境下性能比 Serial 会有一定程度的提升;但线程切换需要额外的开销,因此在单 CPU 环境中表现不如 Serial
- Parallel Scavenge 垃圾收集器(多线程)
- Parallel Scavenge 和 ParNew 一样,都是多线程、新生代垃圾收集器。但是两者有巨大的不同点:
- Parallel Scavenge:追求 CPU 吞吐量,能够在较短时间内完成指定任务,因此适合没有交互的后台计算。
- ParNew:追求降低用户停顿时间,适合交互式应用
- Parallel Scavenge 和 ParNew 一样,都是多线程、新生代垃圾收集器。但是两者有巨大的不同点:
- Serial 垃圾收集器(单线程)
- 老年代垃圾收集器
- Serial Old 垃圾收集器(单线程)
- Serial Old 收集器是 Serial 的老年代版本,都是单线程收集器,只启用一条 GC 线程,都适合客户端应用。它们唯一的区别就是:Serial Old 工作在老年代,使用“标记-整理”算法;Serial 工作在新生代,使用“复制”算法
- Parallel Old 垃圾收集器(多线程)
- Parallel Old 收集器是 Parallel Scavenge 的老年代版本,追求 CPU 吞吐量
- CMS 垃圾收集器
- CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿
- 具体流程:
- 初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记
- 并发标记:使用多条标记线程,与用户线程并发执行。此过程进行可达性分析,标记出所有废弃对象。速度很慢
- 重新标记:Stop The World,使用多条标记线程并发执行,将刚才并发标记过程中新出现的废弃对象标记出来
- 并发清除:只使用一条 GC 线程,与用户线程并发执行,清除刚才标记的对象。这个过程非常耗时
- 浮动垃圾
- 如果在初始标记阶段被标记为活着,并发运行过程中“死亡”,remark 过程无法纠正,因此变为浮动垃圾,需等待下次 gc 的到来
- 解决方案:
- 有个 VM 参数设置可以让扫描新生代之前进行一次 young gc,但 gc 是虚拟机自动调度,不保证一定执行。 JVM 有参数可让虚拟机强制执行一次 young gc(但是会导致 STW 停顿时间变长)
- 并发标记与并发清除过程耗时最长,且可以与用户线程一起工作,因此,总体上说,CMS 收集器的内存回收过程是与用户线程一起并发执行的
- 缺点:
- 吞吐量低
- 无法处理浮动垃圾,导致频繁 Full GC
- 使用“标记-清除”算法产生碎片空间
- 对于产生碎片空间的问题,可以通过开启 -XX:+UseCMSCompactAtFullCollection,在每次 Full GC 完成后都会进行一次内存压缩整理,将零散在各处的对象整理到一块
- 还可以设置参数 -XX:CMSFullGCsBeforeCompaction 告诉 CMS,经过了 N 次 Full GC 之后再进行一次内存整理
- CMS 已经在 JDK 9 中 被标记为废弃(deprecated)
- Serial Old 垃圾收集器(单线程)
- G1 通用垃圾收集器
- 介绍地址
- G1 是一款面向服务端应用的垃圾收集器,它没有新生代和老年代的概念,而是将堆划分为一块块独立的 Region。当要进行垃圾收集时,首先估计每个 Region 中垃圾的数量,每次都从垃圾回收价值最大的 Region 开始回收,因此可以获得最大的回收效率
- 从整体上看, G1 是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片
- 具体流程:
- 初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记
- 并发标记:使用一条标记线程与用户线程并发执行。此过程进行可达性分析,速度很慢
- 最终标记:Stop The World,使用多条标记线程并发执行
- 筛选回收:回收废弃对象,此时也要 Stop The World,并使用多条筛选回收线程并发执行
- 一个对象和它内部所引用的对象可能不在同一个 Region 中,那么当垃圾回收时,是否需要扫描整个堆内存才能完整地进行一次可达性分析?
- 不需要,每个 Region 都有一个 Remembered Set,用于记录本区域中所有对象引用的对象所在的区域,进行可达性分析时,只要在 GC Roots 中再加上 Remembered Set 即可防止对整个堆内存进行遍历
- G1 GC 是一个响应时间优先的 GC 算法,它与 CMS 最大的不同是,用户可以设定整个 GC 过程的期望停顿时间,参数-XX:MaxGCPauseMillis 指定一个 G1 收集过程目标停顿时间,默认值 200ms,不过它不是硬性条件,只是期望值
- G1 GC 是一种兼顾吞吐量和停顿时间的 GC 实现,在 JDK 7u4 版本发行时被正式推出,是 JDK 9 以后的默认 GC 选 项
- 并发标记法---三色标记法
- 白色,没有被收集器表标记的对象
- 灰色,自身被标记到,但是其拥有的 field 字段引用到其他对象还没有被处理
- 黑色, 自己本身被标记,同时 field 引用的对象也被标记
- Partial GC:并不收集整个GC堆的模式
- Young GC:只收集young gen的GC
- Old GC:只收集old gen的GC。只有CMS的concurrent collection是这个模式
- Mixed GC:收集整个young gen以及部分old gen的GC。只有G1有这个模式
- Full GC:收集整个堆,包括young gen、old gen、perm gen(如果存在的话,JAVA8以后用metaspace代替)等所有部分的模式
- Minor GC vs Major GC/Full GC
- Minor GC:回收新生代(包括 Eden 和 Survivor 区域),因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快
- Major GC / Full GC: 回收老年代,出现了 Major GC,经常会伴随至少一次的 Minor GC,但这并非绝对。Major GC 的速度一般会比 Minor GC 慢 10 倍 以上
- 对象的内存分配,就是在堆上分配,对象主要分配在新生代的 Eden 区上,少数情况下可能直接分配在老年代,分配规则不固定,取决于当前使用的垃圾收集器组合以及相关的参数配置
- 内存分配规则:
- 对象优先在 Eden 分配
- 大多数情况下,对象在新生代 Eden 区中分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC
- 大对象直接进入老年代
- 大对象是指需要大量连续内存空间的 Java 对象,如很长的字符串或数据
- 一个大对象能够存入 Eden 区的概率比较小,发生分配担保的概率比较大,而分配担保需要涉及大量的复制,就会造成效率低
- 虚拟机提供了一个 -XX:PretenureSizeThreshold 参数,令大于这个设置值的对象直接在老年代分配,这样做的目的是避免在 Eden 区及两个 Survivor 区之间发生大量的内存复制
- 长期存活的对象将进入老年代
- JVM 给每个对象定义了一个对象年龄计数器。当新生代发生一次 Minor GC 后,存活下来的对象年龄 +1,当年龄超过一定值时,就将超过该值的所有对象转移到老年代中去
- 对象进入老年代的年龄默认为 15,可以使用 -XXMaxTenuringThreshold 设置新生代的最大年龄,只要超过该参数的新生代对象都会被转移到老年代中去
- 动态对象年龄判定
- 如果当前新生代的 Survivor 中,相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄 >= 该年龄的对象就可以直接进入老年代,无须等到 MaxTenuringThreshold 中要求的年龄
- 空间分配担保
- JDK 6 Update 24 之前的规则:
- 在发生 Minor GC 之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间
- 如果这个条件成立,Minor GC 可以确保是安全的
- 如果不成立,则虚拟机会查看 HandlePromotionFailure 值是否设置为允许担保失败
- 如果是,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小
- 如果大于,将尝试进行一次 Minor GC,尽管这次 Minor GC 是有风险的
- 如果小于,或者 HandlePromotionFailure 设置不允许冒险,那此时也要改为进行一次 Full GC
- JDK 6 Update 24 之后的规则变为:
- 只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小,就会进行 Minor GC,否则将进行 Full GC
- 通过清除老年代中废弃数据来扩大老年代空闲空间,以便给新生代作担保
- JDK 6 Update 24 之前的规则:
- 对象优先在 Eden 分配
- 可能会触发 Full GC 的情况:
- System.gc() 方法的调用
- 此方法的调用是建议 JVM 进行 Full GC,注意这只是建议而非一定,但在很多情况下它会触发 Full GC,从而增加 Full GC 的频率。通常情况下我们只需要让虚拟机自己去管理内存即可,我们可以通过 -XX:+ DisableExplicitGC 来禁止调用 System.gc()
- 老年代空间不足
- 老年代空间不足会触发 Full GC 操作,若进行该操作后空间依然不足,则会抛出 OOM 异常(java.lang.OutOfMemoryError: Java heap space)
- 永久代空间不足(JAVA8 之后废弃了永久代,)
- JVM 规范中运行时数据区域中的方法区,在 HotSpot 虚拟机中也称为永久代(Permanet Generation),存放一些类信息、常量、静态变量等数据,当系统要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,会触发 Full GC。如果经过 Full GC 仍然回收不了,那么 JVM 会抛出 OOM 异常(java.lang.OutOfMemoryError: PermGen space)
- CMS GC 时出现 promotion failed 和 concurrent mode failure
- promotion failed,就是上文所说的担保失败,而 concurrent mode failure 是在执行 CMS GC 的过程中同时有对象要放入老年代,而此时老年代空间不足造成的
- 统计得到的 Minor GC 晋升到旧生代的平均大小大于老年代的剩余空间
- System.gc() 方法的调用
- 字符串常量池
- Class 常量池:字面值常量(等号右边的值,int a = 123,123 为字面量)、符号引用(类和接口的全限定名、字段的名称和描述符、方法的名称和描述符)
- 运行时常量池
- Class 文件结构
- Class 文件是二进制文件,它的内容具有严格的规范,文件中没有任何空格,全都是连续的 0/1。Class 文件 中的所有内容被分为两种类型:无符号数、表
- 无符号数 无符号数表示 Class 文件中的值,这些值没有任何类型,但有不同的长度。u1、u2、u4、u8 分别代表 1/2/4/8 字节的无符号数
- 表 由多个无符号数或者其他表作为数据项构成的符合数据类型
- Class 文件具体由以下几个构成:
- 魔数
- Class 文件的头 4 个字节称为魔数,用来表示这个 Class 文件的类型
- 版本信息
- 紧接着魔数的 4 个字节是版本信息,5-6 字节表示次版本号,7-8 字节表示主版本号,它们表示当前 Class 文件中使用的是哪个版本的 JDK
- class 常量池
- 字面值常量:在程序中定义的字面量(等号右边的值,int a = 123,123 为字面量)
- 符号引用:符号引用就是我们定义的各种名字(类和接口的全限定名、字段的名称和描述符、方法的名称和描述符)
- 访问标志
- 在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口;是否定义为 public 类型;是否被 abstract/final 修饰
- 类索引、父类索引、接口索引集合
- 类索引和父类索引都是一个 u2 类型的数据,而接口索引集合是一组 u2 类型的数据的集合,Class 文件中由这三项数据来确定类的继承关系。类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名
- 字段表集合
- 字段表集合存储本类涉及到的成员变量,包括实例变量和类变量,但不包括方法中的局部变量
- 每一个字段表只表示一个成员变量,本类中的所有成员变量构成了字段表集合
- 方法表集合
- 方法表结构与属性表类似
- 方法表的属性表集合中有一张 Code 属性表,用于存储当前方法经编译器编译后的字节码指令
- 属性表集合
- 每个属性对应一张属性表
- 魔数
- Class 文件是二进制文件,它的内容具有严格的规范,文件中没有任何空格,全都是连续的 0/1。Class 文件 中的所有内容被分为两种类型:无符号数、表
- 类的生命周期
- 类从被加载到虚拟机内存开始,到卸载出内存为止,它的整个生命周期包括以下 7 个阶段:
- 加载:查找和导入 Class 文件
- 通过类的全限定名获取该类的二进制字节流
- 将二进制字节流所代表的静态结构转化为方法区的运行时数据结构
- 在内存中创建一个代表该类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口
- 校验:检查载入 Class 文件数据的正确性
- 准备:给类的静态变量分配存储空间
- 解析:虚拟机将常量池内的符号引用替换为直接引用
- 初始化:执行类构造器 () 方法,对类的静态变量,静态代码块执行初始化操作
- () 方法不需要显式调用父类构造器,虚拟机会保证在子类的 () 方法执行之前,父类的 () 方法已经执行完毕
- () 方法不是必需的,如果一个类没有静态语句块,也没有对类变量的赋值操作,那么编译器可以不为这个类生成 () 方法
- 接口中不能使用静态代码块,但接口也需要通过 () 方法为接口中定义的静态成员变量显式初始化。但接口与类不同,接口的 () 方法不需要先执行父类的 () 方法,只有当父接口中定义的变量使用时,父接口才会初始化
- 虚拟机会保证一个类的 () 方法在多线程环境中被正确加锁、同步。如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的 () 方法
- 使用
- 卸载
- 加载:查找和导入 Class 文件
- 其中验证、准备、解析 3 个阶段统称为连接(把类的二进制数据合并到 JRE 中)
- 类加载的过程
- 介绍地址
- 类加载过程包括 5 个阶段:加载、验证、准备、解析和初始化
- 类从被加载到虚拟机内存开始,到卸载出内存为止,它的整个生命周期包括以下 7 个阶段:
- 类加载过程中“初始化”开始的时机
- Java 虚拟机规范没有强制约束类加载过程的第一阶段(即:加载)什么时候开始,但对于“初始化”阶段,有着严格的规定。有且仅有 5 种情况必须立即对类进行“初始化”:
- 在遇到 new、putstatic、getstatic、invokestatic 字节码指令时,如果类尚未初始化,则需要先触发其初始化
- 对类进行反射调用时,如果类还没有初始化,则需要先触发其初始化
- 初始化一个类时,如果其父类还没有初始化,则需要先初始化父类
- 虚拟机启动时,用于需要指定一个包含 main() 方法的主类,虚拟机会先初始化这个主类
- 当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF_getStatic、REF_putStatic、REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类还没初始化,则需要先触发其初始化
- 这 5 种场景中的行为称为对一个类进行主动引用,除此之外,其它所有引用类的方式都不会触发初始化,称为被动引用
- Java 虚拟机规范没有强制约束类加载过程的第一阶段(即:加载)什么时候开始,但对于“初始化”阶段,有着严格的规定。有且仅有 5 种情况必须立即对类进行“初始化”:
- 接口的加载过程
- 接口加载过程与类加载过程稍有不同
- 当一个类在初始化时,要求其父类全部都已经初始化过了,但是一个接口在初始化时,并不要求其父接口全部都完成了初始化,当真正用到父接口的时候才会初始化
- “非数组类”与“数组类”加载比较
- 非数组类加载阶段可以使用系统提供的引导类加载器,也可以由用户自定义的类加载器完成,开发人员可以通过定义自己的类加载器控制字节流的获取方式(如重写一个类加载器的 loadClass() 方法)
- 数组类本身不通过类加载器创建,它是由 Java 虚拟机直接创建的,再由类加载器创建数组中的元素类
- 类加载器
- 启动类加载器(Bootstrap ClassLoader)
- C++实现,它负责将 <JAVA_HOME>/lib 路径下的核心类库或-Xbootclasspath 参数指定的路径下的 jar 包加载到内存中
- 只加载包名为 java、javax、sun 等开头的类
- 不允许开发者调用
- 扩展类加载器(Extension ClassLoader)
- 由 Java 实现,是 Launcher 的静态内部类,它负责加载<JAVA_HOME>/lib/ext 目录下或者由系统变量-Djava.ext.dir 指定位路径中的类库
- 开发者可以直接使用标准扩展类加载器,也可以自定义实现
- 应用程序类加载器(Application ClassLoader)
- 由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,所以一般也称它为“系统类加载器”
- 由 Java 实现,它负责加载系统类路径 java -classpath 或-D java.class.path 指定路径下的类库
- 开发者可以直接使用系统类加载器
- 如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器
- 一个类如果被系统类加载器和扩展类加载器加载两次,会在方法区产生两个不同的类,彼此不可见,并且在堆中生成不同 Class 实例,instanceof 的结果为 false
- 启动类加载器(Bootstrap ClassLoader)
- 双亲委派模型
- 介绍地址
- 双亲委派模型是描述类加载器之间的层次关系。它要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。(父子关系一般不会以继承的关系实现,而是以组合关系来复用父加载器的代码)
- 工作过程:
- 如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,依次递归
- 因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(找不到所需的类)时,子加载器才会尝试自己去加载
- 在 java.lang.ClassLoader 中的 loadClass() 方法中实现该过程
- 为什么使用双亲委派模型
- 像 java.lang.Object 这些存放在 rt.jar 中的类,无论使用哪个类加载器加载,最终都会委派给最顶端的启动类加载器加载,从而使得不同加载器加载的 Object 类都是同一个
- 相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个 java.lang.Object 类,并放在 classpath 下,那么系统将会出现多个不同的 Object 类,类之间的比较结果及类的唯一性将无法保证,Java 类型体系中最基础的行为也就无法保证
- jps
- jps:显示当前运行的 java 进程列表以及相关参数
- jps -q:只显示 pid,不显示 class 名称,jar 文件名和传递给 main 方法的参数
- jps -m:输出传递给 main 方法的参数
- jps -v:输出传递给 JVM 的参数
- jps -l pid:输出应用程序 main class 的完整 package 名 或者 应用程序的 jar 文件完整路径名
- jstack:生成 java 虚拟机当前时刻的线程快照
- jmap
- jmap:用于打印指定 Java 进程(或核心文件、远程调试服务器)的共享对象内存映射或堆内存细节
- jmap -histo pid:查看 java 堆(heap)中的对象数量及大小
- jmap -heap pid:查看到该进程的堆栈以及 GC 信息
- jstat -gc pid:查看 GC 状况
- jinfo:输出 java 进程、core 文件或远程 debug 服务器的配置信息,等同于 jps -v
- javap:可以对代码反编译,也可以查看 java 编译器生成的字节码
{kind=link}
ObjectMonitor 不仅是重量级锁的实现,还是 Object 的 wait/notify/notifyAll 方法的底层核心实现
ObjectMonitor 主要组成:
- _count:记录 owner 线程获取锁的次数
- _owner:指向持有 ObjectMonitor 对象的线程
- _WaitSet:存放处于 wait 状态的线程队列
- _EntryList:存放处于等待锁 block 状态的线程队列
- _recursions:记录锁的重入次数
ObjectMonitor 实现原理:
- JAVA 对象头的 Mark Word 中会存放 ObjectMonitor 的指针,根据该指针可以获取到 ObjectMonitor
- 线程想要获取 ObjectMonitor 锁时,首先会进入_EntryList 队列
- 当某个线程获取到对象的 monitor 后,进入_Owner 区域,设置为当前线程,同时计数器_count 加 1
- 如果线程调用了 wait()方法,则会进入_WaitSet 队列。它会释放 monitor 锁,即将_owner 赋值为 null,_count 自减 1,进入_WaitSet 队列阻塞等待
- 如果其他线程调用 notify() / notifyAll() ,会唤醒_WaitSet 中的某个线程,该线程再次尝试获取 monitor 锁,成功即进入_Owner 区域
- 释放监视锁时,线程退出临界区,将 monitor 的 owner 设为 null
- 单线程 happen-before 原则:在同一个线程中,书写在前面的操作 happen-before 后面的操作
- 锁的 happen-before 原则:同一个锁的 unlock 操作 happen-before 此锁的 lock 操作
- volatile 的 happen-before 原则:对一个 volatile 变量的写操作 happen-before 对此变量的任意操作(当然也包括写操作了)
- happen-before 的传递性原则:如果 A 操作 happen-before B 操作,B 操作 happen-before C 操作,那么 A 操作 happen-before C 操作
- 线程启动的 happen-before 原则:同一个线程的 start 方法 happen-before 此线程的其它方法
- 线程中断的 happen-before 原则:对线程 interrupt 方法的调用 happen-before 被中断线程的检测到中断发送的代码
- 线程终结的 happen-before 原则:线程中的所有操作都 happen-before 线程的终止检测
- 对象创建的 happen-before 原则:一个对象的初始化完成先于他的 finalize 方法调用
在执行程序时,为了提高性能,编译器和处理器会对指令做重排序:
- 编译器优化重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
- 指令级并行的重排序:如果不存 l 在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
- 内存系统的重排序:处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行
可以通过插入特定类型的 Memory Barrier 来禁止特定类型的编译器重排序和处理器重排序
- 内存屏障,又称内存栅栏,是一个 CPU 指令,作用:
- 保证特定操作的执行顺序
- 影响某些数据(或则是某条指令的执行结果)的内存可见性,使数据对其他 CPU 变得可见(指刷新到主内存),读取时也只能从主内存加载最新的值
java 内存模型 volatile 是基于 Memory Barrier 实现的
- 不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不会改变
- 编译器、runtime 和处理器都必须遵守 as-if-serial 语义
- 强引用(StrongReference):使用 new 关键字创建的对象都是强引用,垃圾回收器不会回收有强引用的对象
- 软引用(SoftReference):如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存
- 弱引用(WeakReference):垃圾回收器一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存
- 虚引用(PhantomReference):虚引用并不会决定对象的生命周期,如果一个对象仅持有 虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收,虚引用必须和引用队列(ReferenceQueue)联合使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中
-
ThreadLoal 变量,线程局部变量,同一个 ThreadLocal 所包含的对象,在不同的 Thread 中有不同的副本
-
一个线程内可以存在多个 ThreadLocal 对象
-
ThreadLocal 内部维护了一个 ThreadLocalMap 对象(类似 HashMap),ThreadLocalMap 是 TreadLocal 的静态内部类
-
内存泄露问题:
- ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用(因为 ThreadLocalMap 一直存在,强引用的话,K 和 V 都不会被回收),可能会被随时回收
- 如果 ThreadLocal Key 被回收,那么此时 ThreadLocalMap 里的一组 KV 的 K 就是 null 了
- 因此只要 ThreadLocalMap 不被回收,那么这里 K 为 null 的 V 就一直占用着内存,造成内存泄露
- 解决方案:
- 在 ThreadLocal 的 get()、set()、remove()的时候都会清除线程 ThreadLocalMap 里所有 key 为 null 的 value
- 建议业务方每次使用完 ThreadLocal,都调用它的 remove()方法清除数据
-
源码:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocal.ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } ThreadLocal.ThreadLocalMap getMap(Thread t) { return t.threadLocals; } void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocal.ThreadLocalMap(this, firstValue); } public T get() { //同set方法类似获取对应线程中的ThreadLocalMap实例 Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } //为空返回初始化值 return setInitialValue(); } private T setInitialValue() { //获取初始化值,默认为null(如果没有子类进行覆盖) T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); //不为空不用再初始化,直接调用set操作设值 if (map != null) map.set(this, value); else //第一次初始化,createMap在上面介绍set()的时候有介绍过。 createMap(t, value); return value; }
{kind=link}
- sun.misc.Unsafe 类,它可以提供硬件级别的原子操作,它可以获取某个属性在内存中的位置,也可以修改对象的字段值,其底层是用 C/C++ 实现
- 大致可分为内存操作、compareAndSwap、Class 相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类
- compareAndSwap:执行 CPU 的 cmpxchg 指令(汇编指令),比较内存值 A 是否和预期值 B 相等,如果相等,则将新值 V 赋给内存值 A
CAS 全称是 compare and swap,即比较并交换,它是一种原子操作,同时 CAS 是一种乐观机制。java.util.concurrent 包很多功能都是建立在 CAS 之上
CAS 的缺点:
- ABA 问题
- 循环时间长开销大。CAS 操作如果长时间不成功,会导致其一直自旋,给 CPU 带来非常大的开销
- 只能保证一个共享变量的原子操作,Java 从 1.5 开始 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行 CAS 操作
CAS 需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是 A,后来变成了 B,然后又变成了 A,那么 CAS 进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA 问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”(JAVA 中的 AtomicStampedReference 也是采用类似方案实现)
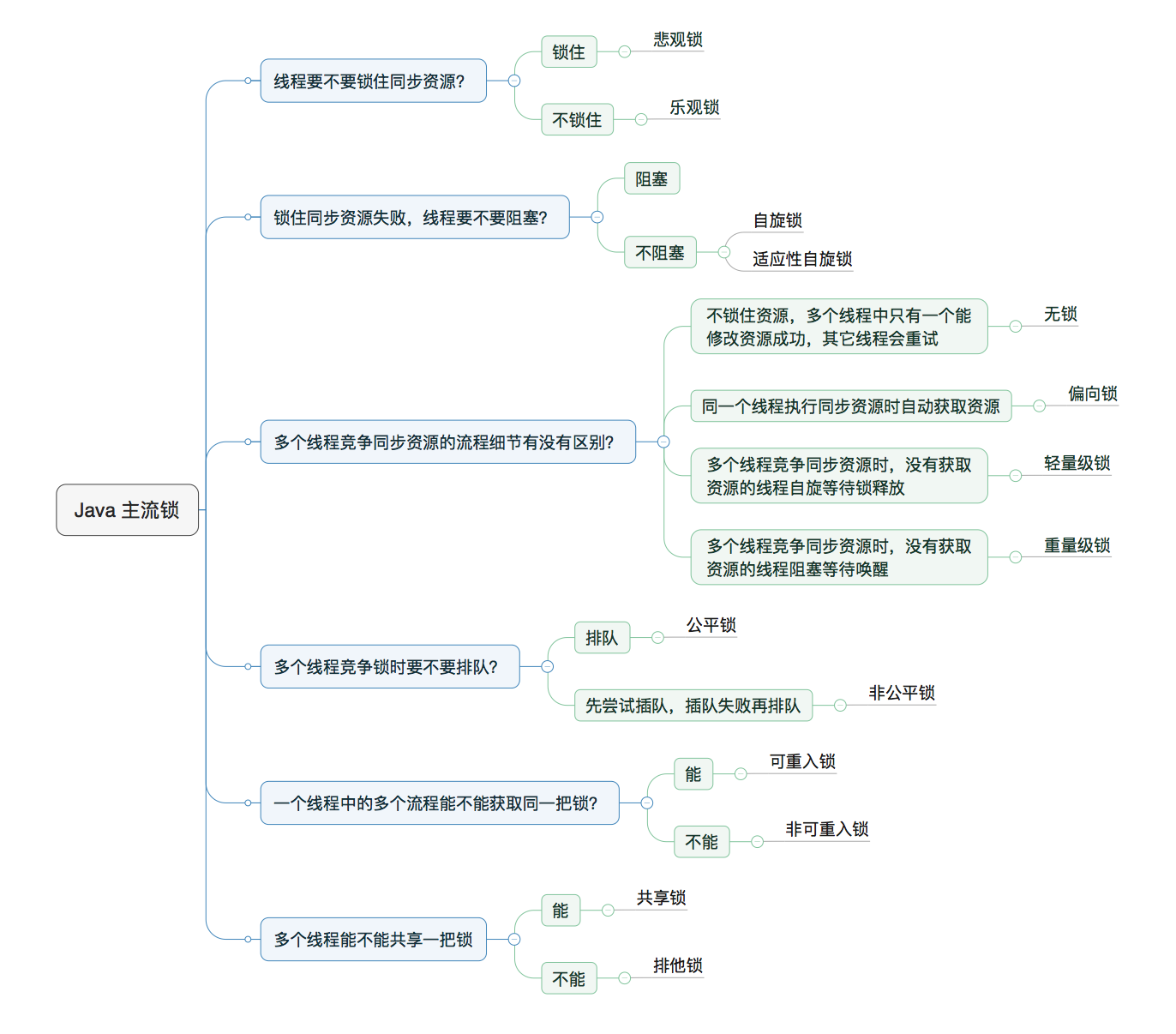
- 悲观锁:悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java 中,synchronized 关键字和 Lock 的实现类都是悲观锁
- 乐观锁:乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作,乐观锁在 Java 中是通过使用无锁编程来实现,最常采用的是 CAS 算法,Java 原子类中的递增操作就通过 CAS 自旋实现的
- 自旋锁:阻塞或唤醒一个 Java 线程需要操作系统切换 CPU 状态来完成,如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长,为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销,这就是自旋锁
- 自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度
- JDK1.4.2 中引入了自旋锁,可以使线程在没有取得锁时不被挂起而是执行若干个空循环,如果若干个空循环之后,线程获得了锁则继续执行,如果仍然没有获取锁则被挂起。使用-XX:+UseSpinning 来开启,使用-XX:PreBlockSpin 参数来设置自旋锁的等待次数。JDK 6 中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)
- 自适应自旋锁:自适应的自旋锁,意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源
- 无锁:没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功,无锁的标志位为“01”
- 偏向锁:偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。偏向锁在 JDK 6 及以后的 JVM 里是默认启用的。可以通过 JVM 参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态,偏向锁的标志位为“01”,
- 轻量级锁:当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能,轻量级锁的锁标志位为“00”
- 重量级锁:基于 ObjectMonitor 实现,当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁,重量级锁的对象头的 Mark Word 中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态,重量级锁的锁标志位为“10”
- 锁升级过程:无锁-->偏向锁-->轻量级锁-->重量级锁
- 公平锁:公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程最终都能获取到锁。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大
- 非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待,但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的情况。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程。缺点是处于等待队列中的线程可能会一直获取不到锁,或者等很久才能获取到锁
- 可重入锁:可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者 class),不会因为之前已经获取过还没释放而阻塞。Java 中 ReentrantLock 和 synchronized 都是可重入锁,可重入锁的作用和优点是可一定程度避免死锁
- 非可重入锁:当前线程在获取对象锁之前需要将对象的锁释放掉。可能会出现该对象锁已被当前线程所持有,导致锁无法释放,进而出现死锁的问题
- 共享锁:共享锁是指该锁可被多个线程所持有
- 排他锁:排他锁也叫独享锁,是指该锁一次只能被一个线程所持有
- 原子性:确保线程互斥的访问同步代码
- 可见性:保证共享变量的修改能够及时可见(对一个变量 unlock 操作之前,必须要同步到主内存中;如果对一个变量进行 lock 操作,则将会清空工作内存中此变量的值,在执行引擎使用此变量前,需要重新从主内存中 load 操作或 assign 操作初始化变量值)
- 有序性:有效解决重排序问题(一个 unlock 操作先行发生(happen-before)于后面对同一个锁的 lock 操作)
- 同步普通方法,锁的是当前对象
- 同步静态方法,锁的是当前 Class 对象
- 同步块,锁的是代码块中的对象
- 同步代码块的实现原理:通过进入、退出对象监视器(Monitor)来实现同步块的同步的,具体实现是在编译之后在同步代码块调用前加入一个 monitor.enter 指令,在代码块之后和异常处插入 monitor.exit 的指令
- 同步方法的实现原理:添加了 synchronized 关键字的方法,编译后的 class 会有 ACC_SYNCHRONIZED 标记,当调用一个设置了 ACC_SYNCHRONIZED 标志的方法时,执行线程需要先获得 monitor 锁,然后开始执行方法,方法执行之后再释放 monitor 锁,当方法不管是正常 return 还是抛出异常都会释放对应的 monitor 锁,在这期间,如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住
- 每个对象维护一个加锁计数器,为 0 表示可以被其他线程获得锁,不为 0 时,只有当前锁的线程才能再次获得锁
- 同步方法和同步代码块底层都是通过 monitor 来实现同步的
锁升级:
- 将原来的重量级锁改成了偏向锁-->轻量级锁-->重量级锁的逐步升级方式
- 默认锁为偏向锁,对只有一个线程执行同步代码的场景有大幅度优化效果
- 当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁
- 当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁
锁优化
- 加入适应性自旋锁
- 从原来的一旦获取不到就阻塞、状态切换,转变为在有的时候可以借助于较小的 CPU 浪费避免状态切换的开销
- 锁消除(锁删除):
- 编译器在运行时,会删除不必要的加锁操作,对一些“代码上要求同步,但是被检测到不可能存在共享数据竞争”的锁进行消除(根据代码逃逸技术,如果判断到一段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁)
- 锁粗化(锁合并):
- 如果虚拟机检测到有一串零碎的操作都是对同一对象的加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部
- 抽象的队列式的同步器,AQS 定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的 ReentrantLock、Semaphore、CountDownLatch 等
- AQS 核心是通过一个共享变量来同步状态,变量的状态由子类去维护,共享变量的修改都是通过 Unsafe 类提供的 CAS 操作完成的
- AQS 定义两种资源共享方式:Exclusive(独占模式)和 Share(共享模式)
- 独占模式:定义了 tryAcquire 和 tryRelease 两个方法,只有一个线程能执行,如 ReentrantLock
- 共享模式:定义了 tryAcquireShared 和 tryReleaseShared 两个方法,多个线程可同时执行,如 Semaphore/CountDownLatch
- ReentrantLock 是 Java 在 JDK1.5 引入的显式锁,通过重写了 AQS 的 tryAcquire 和 tryRelease 方法实现的 lock 和 unlock
- ReentrantLock 里面有一个内部类 Sync,Sync 继承 AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在 Sync 中实现的。它有公平锁 FairSync 和非公平锁 NonfairSync 两个子类,ReentrantLock 默认使用非公平锁,也可以通过构造器来显式的指定使用公平锁
- lock 方法调用 CAS 方法设置 state 的值
- 如果 state 等于期望值 0(代表锁没有被占用),那么就将 state 更新为 1(代表该线程获取锁成功),然后执行 setExclusiveOwnerThread 方法直接将该线程设置成锁的所有者
- 如果 CAS 设置 state 的值失败,即 state 不等于 0,代表锁正在被占领着,则执行 acquire(1)
- acquire 会调用 nonfairTryAcquire 方法,首先调用 getState 方法获取 state 的值,如果 state 的值为 0(之前占领锁的线程刚好释放了锁),那么用 CAS 这是 state 的值,设置成功则将该线程设置成锁的所有者,并且返回 true。如果 state 的值不为 0,那就调用 getExclusiveOwnerThread 方法查看占用锁的线程是不是自己,如果是的话那就直接将 state + 1,然后返回 true。如果 state 不为 0 且锁的所有者又不是自己,那就返回 false,然后线程会进入到同步队列中
- 公平可重入锁:当 state=0 时,先判断当前线程是否位于同步队列中的第一个,如果是第一个则尝试获取锁,如果不是第一个,加到同步队列的队尾,确保获取锁的顺序是按照队列的顺序来
- 非公平可重入锁:当 state=0 时,不管同步队列是否为空,新的线程都会直接调用 tryAcquire 方法尝试获取锁,从而变成非公平锁
- 判断当前线程是不是锁的所有者,如果不是则抛出异常
- 如果当前线程是锁的所有者,判断此次释放锁后 state 的值是否为 0
- 如果此次释放锁后 state 的值是 0,则代表锁有没有重入,然后将锁的所有者设置成 null 且返回 true,唤醒同步队列中的后继节点进行锁的获取
- 如果此次释放锁后 state 的值不是 0,则代表锁发生了重入,则不唤醒同步队列
ReentrantLock 通过 Condition 对象,也就是条件队列实现了和 wait、notify、notifyAll 相同的语义(因为只有在同步队列中的线程才能去获取锁,所以通过 Condition 对象的 wait 和 signal 方法能实现等待/通知机制)
实现原理:
- 线程在获取 aqs 锁成功后发现需要等待资源(比如消费者发现没有东西消费,于是需要停下来等待生产者生产出东西后通知它),于是调用 Condition.await(既然能调用 await 说明线程此时已经获取了锁)
- 线程释放掉 aqs 的锁,从 aqs 的等待队列转移到 Condition 的等待队列,等待其他线程通过 signal 把它唤起
- 其他线程通过 signal 把 Condition 等待队列的头结点线程重新放回到 aqs 的队列,然后通过 LockSupport 唤起该线程
- 在 await 上等待的线程被唤醒后再尝试去获取 aqs 的锁,成功后于是 await 结束
实现案例(Dubbo):
if (! isDone()) {//response != null
long start = System.currentTimeMillis();
lock.lock();
try {
while (! isDone()) {
//等待请求成功后的signal唤醒操作,如果超时,也算失败
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (! isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}- 线程调用 CAS 方法设置 state 的值,如果 state != 0 的话,则表示获取锁失败
死锁是指一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象
- 互斥。共享资源 X 和 Y 只能被一个线程占用
- 占有且等待。线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X
- 不可抢占。其他线程不能强行抢占线程 T1 占有的资源,因为不可抢占,所以要等待
- 循环等待。线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待
- 破坏互斥条件
- 允许进程同时访问某些资源,这种方法受制于实际场景,不太容易实现条件
- 破坏不抢占条件
- 允许进程强行从占有者那里夺取某些资源,占有资源的进程不能再申请占有其他资源,必须释放手上的资源之后才能发起申请,这个其实也很难找到适用场景
- 破坏持有并等待条件
- 进程在运行前申请得到所有的资源,否则该进程不能进入准备执行状态。这个方法看似有点用处,但是它的缺点是可能导致资源利用率和进程并发性降低
- 破坏循环等待条件
- 对资源事先分类编号,按号分配。这种方式可以有效提高资源的利用率和系统吞吐量,但是增加了系统开销,增大了进程对资源的占用时间
- 数据库死锁:通常因为数据库操作的锁竞争导致,可以通过销毁线程解决
- 资源池耗尽死锁:通常因为多线程共用连接所致,可以通过增大连接池或者降低单线程使用的连接数来避免
- 多线程死锁:通常因为多线程的锁循环依赖所致,可以通过对锁的使用优化来避免,例如死锁检测、排序、超时时间等方法
- jconsole 查看死锁
- jstack 查看死锁
public class JavaTest {
@Test
public void test() {
final Object lockA = new Object();
final Object lockB = new Object();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (lockA) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB) {
}
System.out.println("finish A");
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (lockB) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockA) {
}
System.out.println("finish B");
}
}
}).start();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- NEW:初始状态,线程被构建,但未调用 start()方法
- RUNNABLE:运行状态,调用 start()方法后。在 java 线程中,将操作系统线程的就绪和运行统称运行状态
- BLOCKED:阻塞状态,线程等待进入 synchronized 代码块或方法中,等待获取锁
- WAITING:等待状态,线程可调用 wait、join 等操作使自己陷入等待状态,并等待其他线程做出特定操作(如 notify 或中断)
- TIMED_WAITING:超时等待,线程调用 sleep(timeout)、wait(timeout)等操作进入超时等待状态,超时后自行返回
- TERMINATED:终止状态,线程运行结束
- 新建(New)
- 初始状态,线程被构建,但未调用 start()方法
- 此时 JVM 为其分配内存,并初始化其成员变量的值
- 可运行/就绪(Runnable)
- 当调用了 start()方法,线程就处于可运行状态
- 此时 JVM 会为其创建方法调用栈和程序计数器
- 此时线程 等待系统为其分配 CPU 时间片,并不是说执行了 start()方法就立即执行
- 调用 start()方法与 run()方法的区别:
- 调用 start()方法来启动线程,系统会把该 run()方法当成线程执行体来处理
- 但如果直接调用线程对象的 run()方法,则 run()方法立即就会被执行,而且在 run()方法返回之前其他线程无法并发执行
- 也就是说,系统把线程对象当成一个普通对象,而 run()方法也是一个普通方法,而不是线程执行体
- 只能对处于新建状态的线程调用 start()方法,否则将引发 IllegaIThreadStateExccption 异常
- 如何让子线程调用 start()方法之后立即执行而非"等待执行":
- 程序可以使用 Thread.sleep(1) 来让当前运行的线程(主线程)睡眠 1 毫秒,1 毫秒就够了
- 因为在这 1 毫秒内 CPU 不会空闲,它会去执行另一个处于就绪状态的线程,这样就可以让子线程立即开始执行
- 运行(Running)
- 当 CPU 开始调度处于 就绪状态 的线程时,此时线程获得了 CPU 时间片才得以真正开始执行 run()方法的线程执行体,则该线程处于 运行状态
- 每个 CPU 在任何时刻都只能让一个线程处于运行状态
- 阻塞(Blocked)
- 处于运行状态的线程在某些情况下,让出 CPU 并暂时停止自己的运行,进入 阻塞状态
- 当发生如下情况时,线程将会进入阻塞状态:
- 线程调用 sleep()方法,主动放弃所占用的处理器资源,暂时进入中断状态(不会释放持有的对象锁),时间到后等待系统分配 CPU 继续执行
- 线程调用一个阻塞式 IO 方法,在该方法返回之前,该线程被阻塞
- 线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有
- 程序调用了线程的 suspend 方法将线程挂起
- 线程调用 wait,等待 notify/notifyAll 唤醒时(会释放持有的对象锁)
- 阻塞状态分类:
- 等待阻塞:运行状态中的 线程执行 wait()方法,使本线程进入到等待阻塞状态
- 同步阻塞:线程在 获取 synchronized 同步锁失败(因为锁被其它线程占用),它会进入到同步阻塞状态
- 其他阻塞:通过调用线程的 sleep()或 join()或发出 I/O 请求 时,线程会进入到阻塞状态。当 sleep()状态超时、join()等待线程终止或者超时、或者 I/O 处理完毕 时,线程重新转入就绪状态
- 在阻塞状态的线程只能进入就绪状态,无法直接进入运行状态。而就绪和运行状态之间的转换通常不受程序控制,而是由系统线程调度所决定。当处于就绪状态的线程获得处理器资源时,该线程进入运行状态;当处于运行状态的线程失去处理器资源时,该线程进入就绪状态
- 等待(WAITING)状态
- 线程处于 无限制等待状态,等待一个特殊的事件来重新唤醒,例如:
- 通过 wait()方法进行等待的线程等待一个 notify()或者 notifyAll()方法
- 通过 join()方法进行等待的线程等待目标线程运行结束而唤醒
- 以上两种一旦通过相关事件唤醒线程,线程就进入了 就绪(RUNNABLE)状态 继续运行
- 线程处于 无限制等待状态,等待一个特殊的事件来重新唤醒,例如:
- ** 时限等待(TIMED_WAITING)状态**
- 线程进入了一个 时限等待状态,例如:
- sleep(3000),等待 3 秒后线程重新进行 就绪(RUNNABLE)状态 继续运行
- 线程进入了一个 时限等待状态,例如:
- 死亡(Dead)
- 线程会以如下 3 种方式结束,结束后就处于 死亡状态:
- run()或 call()方法执行完成,线程正常结束
- 线程抛出一个未捕获的 Exception 或 Error
- 直接调用该线程 stop()方法来结束该线程—该方法容易导致死锁,通常不推荐使用
- 处于死亡状态的线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。 如果在一个死去的线程上调用 start()方法,会抛出 java.lang.IllegalThreadStateException 异常
- 终止(TERMINATED)状态
- 线程执行完毕后,进入终止(TERMINATED)状态
- 线程会以如下 3 种方式结束,结束后就处于 死亡状态:
Thread.stop()、Thread.suspend、Thread.resume、Runtime.runFinalizersOnExit 这些终止线程运行的方法已经被废弃了,使用它们是极端不安全的
-
正常执行完 run 方法,然后结束掉
-
控制循环条件和判断条件的标识符来结束掉线程
class MyThread extends Thread { int i=0; @Override public void run() { while (true) { if(i==10) break; i++; System.out.println(i); } } }
- Object.wait()方法需要在 synchronized 块中执行
- Object.wait()不带时间的,需要另一个线程使用 Object.notify()唤醒
- Object.wait()带时间的,假如没有被 notify,到时间了会自动唤醒,这时又分好两种情况,一是立即获取到了锁,线程自然会继续执行;二是没有立即获取锁,线程进入同步队列等待获取锁
- 如果在 wait()之前执行了 notify()会抛出 IllegalMonitorStateException 异常
- wait():让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法”,当前线程被唤醒(进入“就绪状态”)。
- wait(long timeout):让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量”,当前线程被唤醒(进入“就绪状态”)。
- wait(long timeout, int nanos):让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量”,当前线程被唤醒(进入“就绪状态”)
- notify 方法仅仅唤醒一个线程,令线程开始执行。所以,如果有多个线程等待一个对象的时候,这个方法只能唤醒一个线程。而唤醒的线程的选择是依赖于操作系统对于线程的管理
- notifyAll 方法会唤醒所有等待改对象的线程,哪一个线程会优先执行取决于操作系统的线程调度
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
synchronized (myThread) {
try {
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}运行结果:
before wait
before notify
after notify
after wait- Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁
- Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去
- Thread.sleep()到时间了会自动唤醒,然后继续执行
- Object.wait()不带时间的,需要另一个线程使用 Object.notify()唤醒
- Object.wait()带时间的,假如没有被 notify,到时间了会自动唤醒,这时又分好两种情况,一是立即获取到了锁,线程自然会继续执行;二是没有立即获取锁,线程进入同步队列等待获取锁
- Object.wait()和 Condition.await()的原理是基本一致的,不同的是 Condition.await()底层是调用 LockSupport.park()来实现阻塞当前线程的
- 从功能上来说,Thread.sleep()和 LockSupport.park()方法类似,都是阻塞当前线程的执行,且都不会释放当前线程占有的锁资源; Thread.sleep()没法从外部唤醒,只能自己醒过来
- LockSupport.park()方法可以被另一个线程调用 LockSupport.unpark()方法唤醒
- Thread.sleep()方法声明上抛出了 InterruptedException 中断异常,所以调用者需要捕获这个异常或者再抛出; LockSupport.park()方法不需要捕获中断异常
- Thread.sleep()本身就是一个 native 方法; LockSupport.park()底层是调用的 Unsafe 的 native 方法
- Object.wait()方法需要在 synchronized 块中执行; LockSupport.park()可以在任意地方执行
- Object.wait()方法声明抛出了中断异常,调用者需要捕获或者再抛出
- LockSupport.park()不需要捕获中断异常
- Object.wait()不带超时的,需要另一个线程执行 notify()来唤醒,但不一定继续执行后续内容
- LockSupport.park()不带超时的,需要另一个线程执行 unpark()来唤醒,一定会继续执行后续内容
- 如果在 wait()之前执行了 notify()会怎样? 抛出 IllegalMonitorStateException 异常
- 如果在 park()之前执行了 unpark()会怎样? 线程不会被阻塞,直接跳过 park(),继续执行后续内容
- wait/notify
- synchronized 同步方法或者同步代码块
- volatile
- ReentrantLock
- ThreadLocal
- BlockingQueue
- JUC 包中的原子变量类
实现原理:
-
通过调用 Unsafe 的 park 和 unpark(CAS 操作)对线程进行阻塞/放行操作
-
具体流程:
public static void park(Object blocker) { // 获取当前线程 Thread t = Thread.currentThread(); // 设置Blocker setBlocker(t, blocker); // 获取许可 UNSAFE.park(false, 0L); // 重新可运行后再此设置Blocker setBlocker(t, null); } public static void park() { // 获取许可,设置时间为无限长,直到可以获取许可 UNSAFE.park(false, 0L); } public static void parkNanos(Object blocker, long nanos) { if (nanos > 0) { // 时间大于0 // 获取当前线程 Thread t = Thread.currentThread(); // 设置Blocker setBlocker(t, blocker); // 获取许可,并设置了时间 UNSAFE.park(false, nanos); // 设置许可 setBlocker(t, null); } } public static void parkUntil(Object blocker, long deadline) { // 获取当前线程 Thread t = Thread.currentThread(); // 设置Blocker setBlocker(t, blocker); UNSAFE.park(true, deadline); // 设置Blocker为null setBlocker(t, null); } private static void setBlocker(Thread t, Object arg) { // 设置线程t的parkBlocker字段的值为arg UNSAFE.putObject(t, parkBlockerOffset, arg); } public static void unpark(Thread thread) { if (thread != null) // 线程为不空 UNSAFE.unpark(thread); // 释放该线程许可 }
-
底层 park 和 unpark 的原理:
int _count = 0; //初始值是0 void park(){ //说明有人调用过unpark,本次park不阻塞 if(_count>0){ _count=0 return; } block() } void unPark(){ //说明有人park,唤醒它 if(_count<1){ unblock() } _count=1 }
- ReentrantReadWriteLock 有两把锁:ReadLock 和 WriteLock,由词知意,一个读锁一个写锁,合称“读写锁”,读锁和写锁的锁主体都是 Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是排他锁
- 如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠 CAS 保证)增加读状态,成功获取读锁
- 读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是“1<<16”。所以读写锁才能实现读读的过程共享,而读写、写读、写写的过程互斥
- 如果有线程正在读,写线程需要等待读线程释放锁后才能获取写锁,即读的过程中不允许写,这是一种悲观的读锁
- StampedLock 控制锁有三种模式(写,读,乐观读),一个 StampedLock 状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据 stamp,它用相应的锁状态表示并控制访问,数字 0 表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁
- 乐观读锁:读的过程中也允许获取写锁后写入,这相对于 ReadWriteLock 而言,性能有大幅提升
- CountDownLatch 基于 AQS 实现,允许一个或者多个线程一直等待,直到一组其它操作执行完成,采用 AQS 的共享模式实现,await 时执行 CAS 后加入到同步队列并执行 LockSupport 的 park,countDown 时执行 CAS,直到 state=0 时执行 LockSupport 的 unpark 方法
- 需要指定一个整数值,此值是线程将要等待的操作数。当某个线程为了要执行这些操作而等待时,需要调用 await 方法。await 方法让线程进入休眠状态直到所有等待的操作完成为止。当等待的某个操作执行完成,它使用 countDown 方法来减少 CountDownLatch 类的内部计数器。当内部计数器递减为 0 时,CountDownLatch 会唤醒所有调用 await 方法而休眠的线程们
- CyclicBarrier 基于 ReentrantLock 和 AQS 实现,控制多个线程执行自有操作后一直等待,所有的线程必须等待对方,直到所有的线程到达屏障,然后继续运行,是用来协同多线程一起工作的
- CyclicBarrier 维护了一个 count,表示总线程数,调用 dowait 方法时,先将 count 减一,使用 ReentrantLock 确保 count 的计数准确,再判断 count=0
- 如果 count=0,唤醒 AQS 的同步队列中的所有线程,并重新初始化循环屏障(所以 CyclicBarrier 可以重用)
- 如果 count 不等于 0,将线程加入到 AQS 的同步队列中进行等待
Phaser 是 JDK 7 新增的一个同步辅助类,它可以实现 CyclicBarrier 和 CountDownLatch 类似的功能,而且它支持对任务的动态调整,并支持分层结构来实现多线程多阶段执行
- 基于 AQS 实现,用 state 来保存信号量的令牌数。tryRelease 会增加令牌数,acquireShared 会减少令牌数,有公平策略和非公平策略两种实现方式
- Exchanger 用于两个线程之间的数据交换(只能同步两个线程)。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange()方法交换数据,当一个线程先执行 exchange()方法后,它会一直等待第二个线程也执行 exchange()方法,当这两个线程到达同步点时,这两个线程就可以交换数据了
- 在 JDK5 中 Exchanger 被设计成一个容量为 1 的容器,存放一个等待线程,直到有另外线程到来就会发生数据交换,然后清空容器,等到下一个到来的线程
- 从 JDK6 开始,Exchanger 用了类似 ConcurrentMap 的分段思想,提供了多个 slot,增加了并发执行时的吞吐量
使用案例:
public class Test {
static class Producer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Producer(String name, Exchanger<Integer> exchanger) {
super("Producer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
for (int i=1; i<5; i++) {
try {
TimeUnit.SECONDS.sleep(1);
data = i;
System.out.println(getName()+" 交换前:" + data);
data = exchanger.exchange(data);
System.out.println(getName()+" 交换后:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Consumer(String name, Exchanger<Integer> exchanger) {
super("Consumer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
while (true) {
data = 0;
System.out.println(getName()+" 交换前:" + data);
try {
TimeUnit.SECONDS.sleep(1);
data = exchanger.exchange(data);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName()+" 交换后:" + data);
}
}
}
public static void main(String[] args) throws InterruptedException {
Exchanger<Integer> exchanger = new Exchanger<Integer>();
new Producer("", exchanger).start();
new Consumer("", exchanger).start();
TimeUnit.SECONDS.sleep(7);
System.exit(-1);
}
}输出结果:
Consumer- 交换前:0
Producer- 交换前:1
Consumer- 交换后:1
Consumer- 交换前:0
Producer- 交换后:0
Producer- 交换前:2
Producer- 交换后:0
Consumer- 交换后:2
Consumer- 交换前:0
Producer- 交换前:3
Producer- 交换后:0
Consumer- 交换后:3
Consumer- 交换前:0
Producer- 交换前:4
Producer- 交换后:0
Consumer- 交换后:4
Consumer- 交换前:0- 单向阻塞队列,有界队列
- 当队列长度达到临界值,再添加元素时会阻塞线程
- 如果从空队列中获取元素,消费线程也会阻塞
- 不允许 null
- 支持抛异常、特定值、阻塞、超时四种类型的操作方法
- 通过 ReentrantLock 和 Condition 实现阻塞操作,当长度达到临界值,就触发 condition.await,当临界值元素出队后,触发 condition.signal 方法释放锁
- 双端阻塞队列,BlockingDeque 接口继承自 BlockingQueue 接口
- 当队列长度达到临界值,再添加元素时会阻塞线程
- 如果从空队列中获取元素,消费线程也会阻塞
- 不允许 null
- 支持抛异常、特定值、阻塞、超时四种类型的操作方法
- 通过 ReentrantLock 和 Condition 实现阻塞操作,当长度达到临界值,就触发 condition.await,当临界值元素出队后,触发 condition.signal 方法释放锁
- ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里,以 FIFO(先进先出)的顺序对元素进行存储
- 长度只能在初始化时设定,因为它是基于数组实现的,也就具有数组的特性: 一旦初始化,大小就无法修改
- LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储,以 FIFO(先进先出)的顺序对元素进行存储
- 如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限
- 基于 ReentrantLock 和 Condition 实现
- 除了可以双端读写之外,其他方面与单向链式阻塞队列相同
- ConcurerntLinkedQueue 一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序
- 内部使用 CAS 来保证线程安全
- 除了可以双端读写之外,其他方面与 ConcurrentLinkedQueue 相同
- DelayQueue 基于 BlockingQueue 实现,对元素进行持有直到一个特定的延迟到期。注入其中的元素必须实现 java.util.concurrent.Delayed 接口
- DelayQueue 将会在每个元素的 getDelay() 方法返回的值的时间段之后才释放掉该元素。如果返回的是 0 或者负值,延迟将被认为过期,该元素将会在 DelayQueue 的下一次 take 被调用的时候被释放掉
- Delayed 接口也继承了 java.lang.Comparable 接口,这也就意味着 Delayed 对象之间可以进行对比。这个可能在对 DelayQueue 队列中的元素进行排序时有用,因此它们可以根据过期时间进行有序释放
- PriorityBlockingQueue 是一个无界的并发队列。它使用了和类 java.util.PriorityQueue 一样的排序规则,所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口(用于实现优先级),对于具有相等优先级(compare() == 0)的元素并不强制任何特定行为
- Iterator 并不能保证它对元素的遍历是以优先级为序的
- SynchronousQueue 内部同时只能够容纳一个元素,基于 CAS 和 LockSupport 实现
- JDK 7 新增,单向链表实现的无界阻塞队列,通过 CAS 实现并发访问,队列元素使用 FIFO(先进先出)方式
- LinkedTransferQueue 可以说是 SynchronousQueue、LinkedBlockingQueue、ConcurrentLinkedQueue 三者的合集,使用 CAS 代替 ReentrantLock 来提高性能,同时不限制队列长度
- 当 put 时,如果有等待的线程,就直接将元素异步移交给等待线程, 否则直接进入队列
- 当 transfer 时,如果有等待的线程,会阻塞线程,直到消费者拿到数据才返回
- 参考 CopyOnWriteArrayList 和 ArrayList 的区别
- 基于 CopyOnWriteArrayList 实现,在 add 时,会调用 addIfAbsent,由于每次 add 时都要进行数组遍历,因此性能会略低于 CopyOnWriteArrayList
- 基于 ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现
- set 的元素可以根据它们的自然顺序进行排序,也可以根据创建 set 时所提供的 Comparator 进行排序,具体取决于使用的构造方法
参见 ConcurrentHashMap 原理
参见 ConcurrentSkipListMap 原理
- 基础类型:AtomicBoolean,AtomicInteger,AtomicLong
- 数组:AtomicIntegerArray,AtomicLongArray,BooleanArray
- 引用:AtomicReference,AtomicMarkedReference,AtomicStampedReference(解决 ABA 问题)
- FieldUpdater:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater(可以对指定"类的 'volatile long'类型的成员"进行原子更新。基于反射原理实现的)
AtomicInteger 内部维护了一个 volatile 修饰的 int value ,以及 value 在 AtomicInteger 对象中的内存偏移量 valueOffset(通过 unsafe.objectFieldOffset 获得)
compareAndSet(int expect, int update)
- 通过 Unsafe 执行 CPU 的 cmpxchg 指令,比较内存中的值和期望值 expect 是否相等
- 如果相等则将 value 设置为 update
- 如果不相等则返回 false
getAndIncrement()
- 调用 unsafe.getAndAddInt 方法,执行 do-while 循环
- 循环内,先调用 unsafe.getIntVolatile(object, offset)获取到 value 值
- 再通过 Unsafe 执行 CPU 的 cmpxchg 指令,比较 getIntVolatile 方法获取到的值和内存中 value 的实际值是否相等
- 如果相等,则将新值(value+1)赋给 value
- 如果不相等,则一直重复 do-while 循环,直到相等并设置成功为止
public final int getAndIncrement() { return U.getAndAddInt(this, VALUE, 1); } public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; } public final int getAndAddInt(Object o, long offset, int delta) { int v; do { v = getIntVolatile(o, offset); } while (!weakCompareAndSetInt(o, offset, v, v + delta)); return v; }
incrementAndGet()
- 和 getAndIncrement 类似,只不过是先修改 value 的值,再返回(原来的 value+1)
- ForkJoinPool 是 JDK 7 加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现
- Executors 是一个工具类,用其可以创建 ExecutorService、ScheduledExecutorService、ThreadFactory、Callable 等对象
- FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future 接口,所以 FutureTask 既能当做一个 Runnable 直接被 Thread 执行,也能作为 Future 用来得到 Callable 的计算结果
- FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等,常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行
- FutureTask 的线程安全由 CAS 来保证
- 当执行 FutureTask 类的 get 方法时,会把主线程封装成 WaitNode 节点并保存在 waiters 链表中, 并调用 LockSupport.park 方法阻塞等待运行结果,FutureTask 任务执行完成后,通过 UNSAFE 设置 waiters 相应的 waitNode 为 null,并通过 LockSupport.unpark 方法唤醒主线程
- Future 被用于作为一个异步计算结果的引用
- 提供一个 isDone() 方法来检查计算任务是否完成。当任务完成时,get() 方法用来接收计算任务的结果
- 介绍地址
- CompletableFuture 实现了 Future 和 CompletionStage 接口,且提供了许多关于创建,链式调用和组合多个 Future 的便利方法集,而且有广泛的异常处理支持
- 主要作用:
- 主动完成计算
- get():返回计算的结果或者抛出一个 unchecked 异常(CompletionException)
- getNow():如果结果已经计算完则返回结果或者抛出异常,否则返回给定的 valueIfAbsent 值
- join():返回计算的结果或者抛出一个 unchecked 异常(CompletionException),它和 get 对抛出的异常的处理有些细微的区别
- 计算结果完成时的处理
- 当 CompletableFuture 的计算结果完成,或者抛出异常的时候,可以选择执行特定的 Action(whenComplete、whenCompleteAsync、exceptionally)
- 转换
- 类似 stream api 的 map 功能(thenApply、thenApplyAsync)
- 纯消费(执行 Action)
- CompletableFuture 提供了一种处理结果的方法,只对结果执行 Action,而不返回新的计算值(thenAccept、thenAcceptAsync)
- thenAcceptBoth 以及相关方法提供了类似的功能,当两个 CompletionStage 都正常完成计算的时候,就会执行提供的 action,它用来组合另外一个异步的结果
- runAfterBoth 是当两个 CompletionStage 都正常完成计算的时候,执行一个 Runnable,这个 Runnable 并不使用计算的结果
- 组合
- CompletableFuture 提供了一组方法接收一个 Function 作为参数,这个 Function 的输入是当前的 CompletableFuture 的计算值,返回结果将是一个新的 CompletableFuture(thenCompose、thenComposeAsync)
- Either
- acceptEither 方法是当任意一个 CompletionStage 完成的时候,参数 action 就会被执行
- 辅助方法 allOf 和 anyOf
- allOf 方法是当所有的 CompletableFuture 都执行完后执行计算
- anyOf 方法是当任意一个 CompletableFuture 执行完后就会执行计算,计算的结果相同
- 主动完成计算
线程池,能够对线程进行统一分配,调优和监控,核心参数有 int corePoolSize、int maximumPoolSize、long keepAliveTime、TimeUnit unit、BlockingQueue workQueue、ThreadFactory threadFactory、RejectedExecutionHandler handler
- 线程池首先当前运行的线程数量是否少于 corePoolSize,如果少于,则创建新线程来执行任务
- 当线程数达到 corePoolSize 后,后续的任务(Runnable)将放入 workQueue
- 当 workQueue 也满了之后,则继续开启新线程执行任务,直到总线程数达到 maximumPoolSize 为止
- 当总线程数达到 maximumPoolSize,之后再有新的任务,则交给拒绝策略(RejectedExecutionHandler)来处理
- newFixedThreadPool(coun t):定长线程池,最多可同时执行 count 个任务,线程池的线程数量达 corePoolSize 后,即使线程池没有可执行任务时,也不会释放线程,具体实现为 new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()),因此,工作队列为无界队列,导致 maximumPoolSize 和 keepAliveTime 以及 handler 将会是个无用参数,且永远不会执行拒绝策略
- newSingleThreadExecutor:只有一个线程,如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行,由于使用了无界队列,所以也不会执行拒绝策略
- newCachedThreadPool:实现为 new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue()),最大线程数可达到 Integer.MAX_VALUE,即 2147483647
- AbortPolicy: 直接抛出异常,默认策略
- CallerRunsPolicy: 用调用者所在的线程来执行任务
- DiscardOldestPolicy: 丢弃阻塞队列中靠最前的任务,并执行当前任务
- DiscardPolicy: 直接丢弃任务
- shutdown:将线程池里的线程状态设置成 SHUTDOWN 状态, 然后中断所有没有正在执行任务的线程
- shutdownNow:将线程池里的线程状态设置成 STOP 状态, 然后停止所有正在执行或暂停任务的线程
- 只要调用这两个关闭方法中的任意一个, isShutDown() 返回 true, 当所有任务都成功关闭了, isTerminated()返回 true
- execute:execute –> addWorker –>runworker (getTask)
- submit:submit 的任务,会等待线程池 execute,并返回 FutureTask,FutureTask 可以取消任务或者等待任务执行完毕后获取结果
- 在添加任务到工作队列时使用了 ReentrantLock(worker 的添加必须是串行的,因此需要加锁)
- shutdown 时使用了 ReentrantLock 加锁
- 线程池状态变更(advanceRunState())时使用了 CAS,保证线程池状态变更的线程安全性
- ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种
- 使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收不需要时间调度的任务(这些任务通过 ExecutorService 来执行)
- 使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列 DelayQueue 的一种。相比 ThreadPoolExecutor 也简化了执行机制
- 支持可选的 run-after-shutdown 参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务
- DelayedWorkQueue: 这是 ScheduledThreadPoolExecutor 为存储周期或延迟任务专门定义的一个延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。它内部只允许存储 RunnableScheduledFuture 类型的任务。与 DelayQueue 的不同之处就是它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 是利用了 PriorityQueue 的二叉堆结构)
- ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整 maximumPoolSize 对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为 Integer.MAX_VALUE)
- Executors.newSingleThreadScheduledExecutor 创建的线程池保证内部只有一个线程执行任务,并且线程数不可扩展;而通过 Executors.newScheduledThreadPool(1, threadFactory)创建的线程池可以通过 setCorePoolSize 方法来修改核心线程数