We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化。Plusar已经在Yahoo的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa以及Yahoo的KV存储。 Pulsar之所以能够称为下一代消息队列,主要是因为以下特性:
从最上层来看,一个Plusar单元由若干个集群组成,单元内的集群可以互相之前复制数据, plusar中通常有以下几种组件:
在Kafka和RocketMQ中,Broker负责消息数据的存储以及consumer消费位移的存储等,而Plusar中的broker和他们两个有所不同,plusar中的broker是一个无状态的节点,主要负责三件事情:
消息会被先发布到BookKeeper中,然后会在Broker本地内存中缓存一份,因此一般来说消息的读取都会从从内存中读取,因此第一条中所说的查找topic所有者就是说,因为BookKeeper中的一个ledger只允许一个writer,因此我们可以调用rest接口获取到某一个topic当前的所有者。
BookKeeper是一个可横向扩展的、错误容忍的、低延迟的分布式存储服务,BookKeeper中最基本的单位是记录,实际上就一个字节数组,而记录的数组称之为ledger,BK会将记录复制到多个bookies,存储ledger的节点叫做bookies,从而获得更高的可用性和错误容忍性。从设计阶段BK就考虑到了各种故障,Bookies可以宕机、丢数据、脏数据,但是主要整个集群中有足够的Bookies服务的行为就是正确的。 在Pulsar中,每个分区topic是由若干个ledger组成的,而ledger是一个append-only的数据结构,只允许单个writer,ledger中的每条记录会被复制到多个bookies中,一个ledger被关闭后(例如broker宕机了或者达到了一定的大小)就只支持读取,而当ledger中的数据不再需要的时候(例如所有的消费者都已经消费了这个ledger中的消息)就会被删除。
Bookkeeper的主要优势在于它可以保证在出现故障时在ledger的读取一致性。因为ledger只能被同时被一个writer写入,因为没有竞争,BK可以更高效的实现写入。在Broker宕机后重启时,Plusar会启动一个恢复的操作,从ZK中读取最后一个写入的Ledger并读取最后一个已提交的记录,然后所有的消费者也都被保证能看到同样的内容。
我们知道Kafka在0.8版本之前是将消费进度存储到ZK中的,但是ZK本质上基于单个日志的中心服务,简单来讲,ZK的性能不会随着你增加更多的节点而线性增加,会只会相反减少,因为更多的节点意味着需要将日志同步到更多的节点,性能也会随之下降,因此QPS也会受单机性能影响,因此0.8版本之后就将消费进度存储到了Kafka的Topic中,而RocketMQ最初的版本也类似,有几种不同的实现例如ZK、数据库等,目前版本采用的是存储到本机文件系统中,而Plusar采用了和Kafka类似的思想,Plusar将消费进度也存储到了BK的ledger中。
Plusar中的元数据主要存储到ZK中,例如不同可用区相关的配置会存在全局的ZK中,集群内部的ZK用于存储例如某个topic的数据写入到了那些Ledger、Broker目前的一些埋点数据等等
发布订阅系统中最核心的概念是topic,简单来说,topic可以理解为一个管道,producer可以往这个管道丢消息,consumer可以从这个管道的另一端读取消息,但是这里可以有多个consumer同时从这个管道读取消息。 每个topic可以划分为多个分区,同一个topic下的不同分区所包含的消息都是不同的。每个消息在被添加到一个分区后都会分配一个唯一的offset,在同一个分区内消息是有序的,因此客户端可以根据比如说用户ID进行一个哈希取模从而使得整个用户的消息都发往整个分区,从而一定程度上避免race condition的问题。 通过分区,将大量的消息分散到不同的节点处理从而获得高吞吐。默认情况下,plusar的topic都是非分区的,但是支持通过cli或者接口创建一定分区数目的topic。 默认情况下Plusar会自动均衡Producer和Consumer,但有时候客户端想要根据自己的业务规则也进行路由,Plusar默认支持以下几种规则:单分区、轮询、哈希、自定义(即自己实现相关接口来定制路由规则)
消费决定了消息具体是如何被分发到消费者的,Plusar支持几种不同的消费模式: exclusive、shared、failover。图示如下:
Plusar作为下一代分布式消息队列,拥有非常多吸引人的特性,也弥补了一些其他竞品的短板,例如地域复制、多租户、扩展性、读写隔离等等。
The text was updated successfully, but these errors were encountered:
Plusar 支持哪些协议?
Sorry, something went wrong.
@nicklv 客户端SDK的话支持Java、C++、Python,其他语言可以用WebSocket
No branches or pull requests
Pulsar简介
Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化。Plusar已经在Yahoo的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa以及Yahoo的KV存储。
Pulsar之所以能够称为下一代消息队列,主要是因为以下特性:
架构概述
从最上层来看,一个Plusar单元由若干个集群组成,单元内的集群可以互相之前复制数据, plusar中通常有以下几种组件:
Broker
在Kafka和RocketMQ中,Broker负责消息数据的存储以及consumer消费位移的存储等,而Plusar中的broker和他们两个有所不同,plusar中的broker是一个无状态的节点,主要负责三件事情:
消息会被先发布到BookKeeper中,然后会在Broker本地内存中缓存一份,因此一般来说消息的读取都会从从内存中读取,因此第一条中所说的查找topic所有者就是说,因为BookKeeper中的一个ledger只允许一个writer,因此我们可以调用rest接口获取到某一个topic当前的所有者。
BookKeeper
BookKeeper是一个可横向扩展的、错误容忍的、低延迟的分布式存储服务,BookKeeper中最基本的单位是记录,实际上就一个字节数组,而记录的数组称之为ledger,BK会将记录复制到多个bookies,存储ledger的节点叫做bookies,从而获得更高的可用性和错误容忍性。从设计阶段BK就考虑到了各种故障,Bookies可以宕机、丢数据、脏数据,但是主要整个集群中有足够的Bookies服务的行为就是正确的。

在Pulsar中,每个分区topic是由若干个ledger组成的,而ledger是一个append-only的数据结构,只允许单个writer,ledger中的每条记录会被复制到多个bookies中,一个ledger被关闭后(例如broker宕机了或者达到了一定的大小)就只支持读取,而当ledger中的数据不再需要的时候(例如所有的消费者都已经消费了这个ledger中的消息)就会被删除。
Bookkeeper的主要优势在于它可以保证在出现故障时在ledger的读取一致性。因为ledger只能被同时被一个writer写入,因为没有竞争,BK可以更高效的实现写入。在Broker宕机后重启时,Plusar会启动一个恢复的操作,从ZK中读取最后一个写入的Ledger并读取最后一个已提交的记录,然后所有的消费者也都被保证能看到同样的内容。

我们知道Kafka在0.8版本之前是将消费进度存储到ZK中的,但是ZK本质上基于单个日志的中心服务,简单来讲,ZK的性能不会随着你增加更多的节点而线性增加,会只会相反减少,因为更多的节点意味着需要将日志同步到更多的节点,性能也会随之下降,因此QPS也会受单机性能影响,因此0.8版本之后就将消费进度存储到了Kafka的Topic中,而RocketMQ最初的版本也类似,有几种不同的实现例如ZK、数据库等,目前版本采用的是存储到本机文件系统中,而Plusar采用了和Kafka类似的思想,Plusar将消费进度也存储到了BK的ledger中。
元数据
Plusar中的元数据主要存储到ZK中,例如不同可用区相关的配置会存在全局的ZK中,集群内部的ZK用于存储例如某个topic的数据写入到了那些Ledger、Broker目前的一些埋点数据等等
Plusar核心概念
Topic
发布订阅系统中最核心的概念是topic,简单来说,topic可以理解为一个管道,producer可以往这个管道丢消息,consumer可以从这个管道的另一端读取消息,但是这里可以有多个consumer同时从这个管道读取消息。


每个topic可以划分为多个分区,同一个topic下的不同分区所包含的消息都是不同的。每个消息在被添加到一个分区后都会分配一个唯一的offset,在同一个分区内消息是有序的,因此客户端可以根据比如说用户ID进行一个哈希取模从而使得整个用户的消息都发往整个分区,从而一定程度上避免race condition的问题。
通过分区,将大量的消息分散到不同的节点处理从而获得高吞吐。默认情况下,plusar的topic都是非分区的,但是支持通过cli或者接口创建一定分区数目的topic。
默认情况下Plusar会自动均衡Producer和Consumer,但有时候客户端想要根据自己的业务规则也进行路由,Plusar默认支持以下几种规则:单分区、轮询、哈希、自定义(即自己实现相关接口来定制路由规则)
消费模式
消费决定了消息具体是如何被分发到消费者的,Plusar支持几种不同的消费模式: exclusive、shared、failover。图示如下:
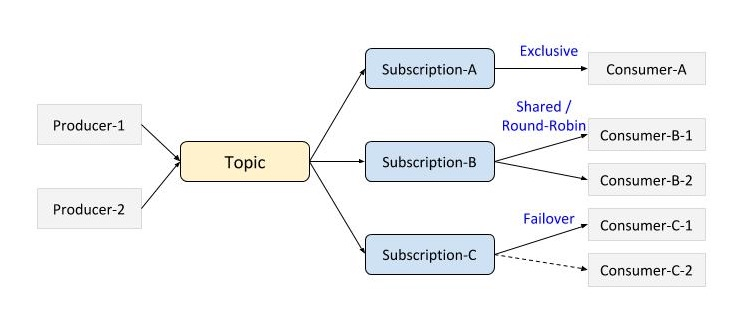
Plusar目前也支持另一种Reader接口,支持传入一个消息ID,例如说Message.Earliest来从最早的消息开始消费。
总结
Plusar作为下一代分布式消息队列,拥有非常多吸引人的特性,也弥补了一些其他竞品的短板,例如地域复制、多租户、扩展性、读写隔离等等。
The text was updated successfully, but these errors were encountered: