面向对象数据库 —— 引入了 Python 中类的特性,如:继承、重写、方法、动态属性等。
该软件使用 MongoDB 来持久化数据,并在 Python 层面利用软件算法模拟出继承等特性。
如果你不需要使用继承、重写等特性,而只是需要一个用来操作 MongoDB 的 ODM,我们为你准备了另一款更合适的工具 —— oomongo 。
主页 | Github | PyPi | 微信 | 邮箱 | 捐赠
{kind=link}
{kind=link}
你可以通过 Github-Issues、微信 与我联系。
pip install oodb
教程 (查看美化版 👈)
本文将以最简洁的方式向你介绍核心知识,而不会让你被繁琐的术语所淹没。
from pymongo import MongoClient
from oodb import OOM, Row, mc, mf, mo, mpyclass OOM_2(OOM):
def mkconn(self):
return MongoClient(host='localhost', port=27017) # MongoDB 连接器,用来写入和读取数据
oom = OOM_2() # 账户OOM
db = oom['泉州市'] # 库OOM
sheet = db['希望小学'] # 表OOM【增、删、改、查】的方法名称分别为:insert、delete、update、find 。
row1 = {'姓名':'小一', '年龄':11, '幸运数字':[1, 2, 3], '成绩':{'语文':81, '数学':82}}
row2 = {'姓名':'小二', '年龄':12, '幸运数字':[2, 3, 4], '成绩':{'语文':82, '数学':83}}
row3 = {'姓名':'小三', '年龄':13, '幸运数字':[3, 4, 5], '成绩':{'语文':83, '数学':84}}
row4 = {'姓名':'小四', '年龄':14, '幸运数字':[4, 5, 6], '成绩':{'语文':84, '数学':85}}
row5 = {'姓名':'小五', '年龄':15, '幸运数字':[5, 6, 7], '成绩':{'语文':85, '数学':86}}
row6 = {'姓名':'小六', '年龄':16, '幸运数字':[6, 7, 8], '成绩':{'语文':86, '数学':87}}| 功能 | 代码 | 备注 |
|---|---|---|
| 增(1 条) | sheet.insert( row1 ) | / |
| 增(批量) | sheet.insert( row2, row3 ) | / |
| 删 | sheet.delete( ) | / |
| 改 | sheet.update( {'年龄': 100} ) | / |
| 查 | for row in sheet.find( ): print( row['姓名'] ) |
find 方法返回的是一个迭代器,因此需要使用 for 循环获取 row 对象 |
删除、修改、查询时,可传递 limit 参数来限制行数:
| 功能 | 代码 |
|---|---|
| 删 | sheet.delete( limit=10 ) |
| 改 | sheet.update( {'年龄': 100}, limit=10 ) |
| 查 | for row in sheet.find( limit=10 ): print( row['姓名'] ) |
row1 = {'姓名':'小一', '年龄':11, '幸运数字':[1, 2, 3], '成绩':{'语文':81, '数学':82}}
row2 = {'姓名':'小二', '年龄':12, '幸运数字':[2, 3, 4], '成绩':{'语文':82, '数学':83}}
row3 = {'姓名':'小三', '年龄':13, '幸运数字':[3, 4, 5], '成绩':{'语文':83, '数学':84}}
r1 = sheet.insert( row1 )
r2 = sheet.insert( row2, row3 )方法1:使用 insert 添加数据成功后,row1~row3 已各自多了一个叫‘_id’的键,该键的值即分配到的主键。
方法2:
r1.inserted_id
r2.inserted_ids让我们以 iPhone15 为例子来讲解【继承】。
我们发现,iPhone15 的不同版本是由【性能】和【外观】这两个维度组合而成的。因此,假如我们要新增一个【128G-黑色】版本的对象,我们可以这样做:
1、创建 基础数据、128G性能数据、黑色外观数据 三条数据:
info_base = {'操作系统': 'iOS', 'CPU型号': 'A16', '屏幕尺寸': '6.1英寸'}
info_128G = {'内存': '128G', '价格': 4849}
info_黑 = {'边框颜色': '黑', '后盖颜色': '黑'}2、把这三条数据插入到数据库,并获取对应的 _id 值:
[id_base, id_128G, id_黑] = sheet.insert( info_base, info_128G, info_黑 ).inserted_ids3、创建【128G-黑色】版本数据,插入到数据库,并获取对应的 _id 值:
id_128G_黑 = sheet.insert({'版本名称': '128G-黑色'}, bases=[id_base, id_128G, id_黑]).inserted_id查询【128G-黑色】版本对象的信息:
row_128G_黑 = next( sheet[mc.版本名称 == '128G-黑色'].find() )
for key in ('版本名称', '操作系统', '内存', '边框颜色'): # row_128G_黑 继承了 row_base, row_128G, row_黑, 因此具有它们的属性及其值
print(row_128G_黑[key])
# >>> 128G-黑色
# >>> iOS
# >>> 128G
# >>> 黑# 创建【白色外观】数据,插入到数据库,并获取对应的 _id 值:
id_白 = sheet.insert({'边框颜色': '白', '后盖颜色': '白'}).inserted_id
# 创建【128G-白色】版本数据,插入到数据库,并获取对应的 _id 值:
id_128G_白 = sheet.insert({'版本名称': '128G-白色'}, bases=[id_白, id_128G_黑]).inserted_id查询【128G-白色】版本对象的信息:
row_128G_白 = next( sheet[mc.版本名称 == '128G-白色'].find() )
for key in ('版本名称', '操作系统', '内存', '边框颜色'):
print(row_128G_白[key])
# >>> 128G-白色
# >>> iOS
# >>> 128G
# >>> 白在以上示例中,当我们新增【128G-白色】版本对象时,继承了 row_白 和 row_128G_黑 ,这两个父对象都具有 边框颜色 属性,前者的该属性值为“白”,后者的该属性值为“黑”。最后,当我们打印 row_128G_白 对象的 边框颜色 属性时,打印出来的结果为 白 。
当一个对象继承自多个父对象,并且对于某一属性,这些父对象的该属性值各不相同时,子对象在表现该属性值时,会遵循【C3线性化算法】:
1、首先,子对象会在自身的属性中查找该属性,如果找到了,则立即返回该属性值。
2、如果在自身的属性中找不到该属性,则会按照从左往右的顺序,先从左边第 1 个父对象中查找,如果查找不到则再从第 2 个父对象中查找……直到在某个父对象中找到该属性时,则立即返回属性值。
假如苹果公司与中国联通公司合作,推出了【128G-白色-联通合作】版本的 iPhone15 ,其各方面参数与【128G-白色】版本唯一的区别就是版本名称改成了“128G-白色-联通合作”,此时,我们可以利用【重写】的特性方便地新增一个【128G-白色-联通合作】版本的对象:
id_128G_白_联通合作 = sheet.insert({'版本名称': '128G-白色-联通合作'}, bases=[id_128G_白]).inserted_id在此例中,我们在新增 row_128G_白_联通合作 对象时,继承了 row_128G_白 对象,并重写了 版本名称 属性。
让我们定义一个方法:该方法接收一个 name 参数,然后返回一个字符串 —— [<当前时间>] 你好,<name>!我是【<版本名称>】版本的 iPhone15,很高兴成为你的移动助理! 。
# 创建对象方法
@mpy.method
def say_hello(self: 'Row', name: 'str'):
import time
版本名称 = self['版本名称']
return f"[{int(time.time())}] 你好,{name}!我是【{版本名称}】版本的 iPhone15,很高兴成为你的移动助理!"
# 将对象方法赋值给基对象base, 它的子孙对象都将继承此方法
base_obj = next( sheet[mc._id == id_base].find() )
base_obj.update({'say_hello': say_hello})
# 调用对象方法
for _id in [id_128G_黑, id_128G_白, id_128G_白_联通合作]:
obj = next( sheet[mc._id == _id].find() )
say_hello = obj['say_hello']
print(say_hello('程序猿'))
# >>> [1709654174] 你好,程序猿!我是【128G-黑色】版本的 iPhone15,很高兴成为你的移动助理!
# >>> [1709654174] 你好,程序猿!我是【128G-白色】版本的 iPhone15,很高兴成为你的移动助理!
# >>> [1709654174] 你好,程序猿!我是【128G-白色-联通合作】版本的 iPhone15,很高兴成为你的移动助理!1、使用 @mpy.method 装饰一个普通函数,该函数就会变成对象方法。
2、注意到这行代码 def say_hello(self: 'Row', name: 'str'): 中, 'Row' 和 'str' 被加了引号 —— 当我们为对象方法的参数做类型提示时,必须以字符串的格式。以下这种方式是错误的: def say_hello(self: Row, name: str): 。当然,类型提示只是用来让编辑器提示代码的,它可有可无,不是必要的。
3、可以在对象方法内导入并使用任何【标准库】和【第三方包】。
4、调用对象方法时,既可以使用位置传参,也可以使用关键词传参。例如,这两种方式都是可行的: say_hello('程序猿') 、 say_hello(name='程序猿') 。
5、对象方法是以人类易读的文本格式存储在 MongoDB 中的(查看图示),可直接通过 Navicat 等管理工具灵活修改。
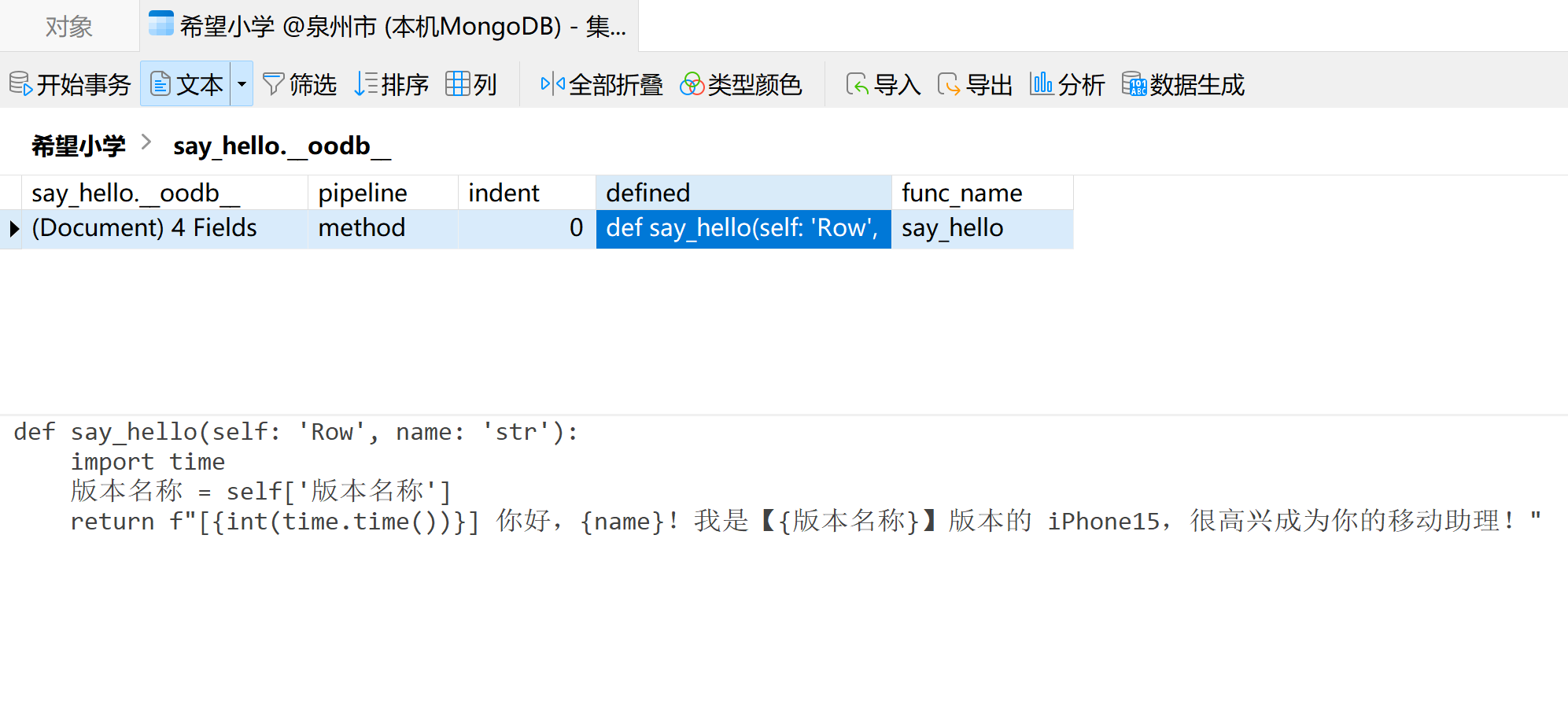{kind=link}
让我们用一个统计学生总数的案例来讲解【动态属性】。
# 新增四个班级对象
C1 = sheet.insert({'班级编号': 1, '学生数量': 10}).inserted_id
C2 = sheet.insert({'班级编号': 2, '学生数量': 20}).inserted_id
C3 = sheet.insert({'班级编号': 3, '学生数量': 30}).inserted_id
C4 = sheet.insert({'班级编号': 4, '学生数量': 40}).inserted_id
# 创建一个获取学生总数量的动态属性值
@mpy.dynamic(C1, C2, id3=C3, id4=C4)
def get_students_count(self: 'Row', id1, id2, id3, id4):
from oodb import Row # Row 在实例化时需要接收两个参数: (parent: Sheet, _id)
rows = [Row(parent=self.parent, _id=x) for x in (id1, id2, id3, id4)]
return sum( [x['学生数量'] for x in rows] )
# 新增一个年级对象,并将【动态属性值】赋值给【学生总数量】属性
gid = sheet.insert({'年级': '五年级', '学生总数量': get_students_count}).inserted_id
# 查询动态属性值
grade = next( sheet[mc._id == gid].find() )
print(grade['学生总数量']) # >>> 100如果我们修改某个班级的学生数量,年级的【学生总数量】的返回值也会相应变化:
next( sheet[mc._id == C1].find() ).update({'学生数量': 15})
print(grade['学生总数量']) # >>> 1051、使用 @mpy.dynamic(...) 装饰一个普通函数,该函数就会变成动态属性。
2、注意到这行代码 def get_students_count(self: 'Row', id1, id2, id3, id4): 中, 'Row' 被加了引号 —— 当我们为动态属性的参数做类型提示时,必须以字符串的格式。以下这种方式是错误的: def get_students_count(self: Row, id1, id2, id3, id4): 。当然,类型提示只是用来让编辑器提示代码的,它可有可无,不是必要的。
3、可以在动态属性内导入并使用任何【标准库】和【第三方包】。
4、创建动态属性时,必须将所需要的参数值在 @mpy.dynamic(...) 的括号内传入。比如:我们定义的 get_students_count 需要 id1, id2, id3, id4 这四个参数,相对应地,我们在 @mpy.dynamic(...) 中传递了 C1, C2, id3=C3, id4=C4 这四个参数值。传递参数值时,既可以使用位置传参,也可以使用关键词传参,例如: C1, C2 使用了位置传参,而 id3=C3, id4=C4 使用了关键词传参。
5、动态属性是以人类易读的文本格式存储在 MongoDB 中的(查看图示),可直接通过 Navicat 等管理工具灵活修改。
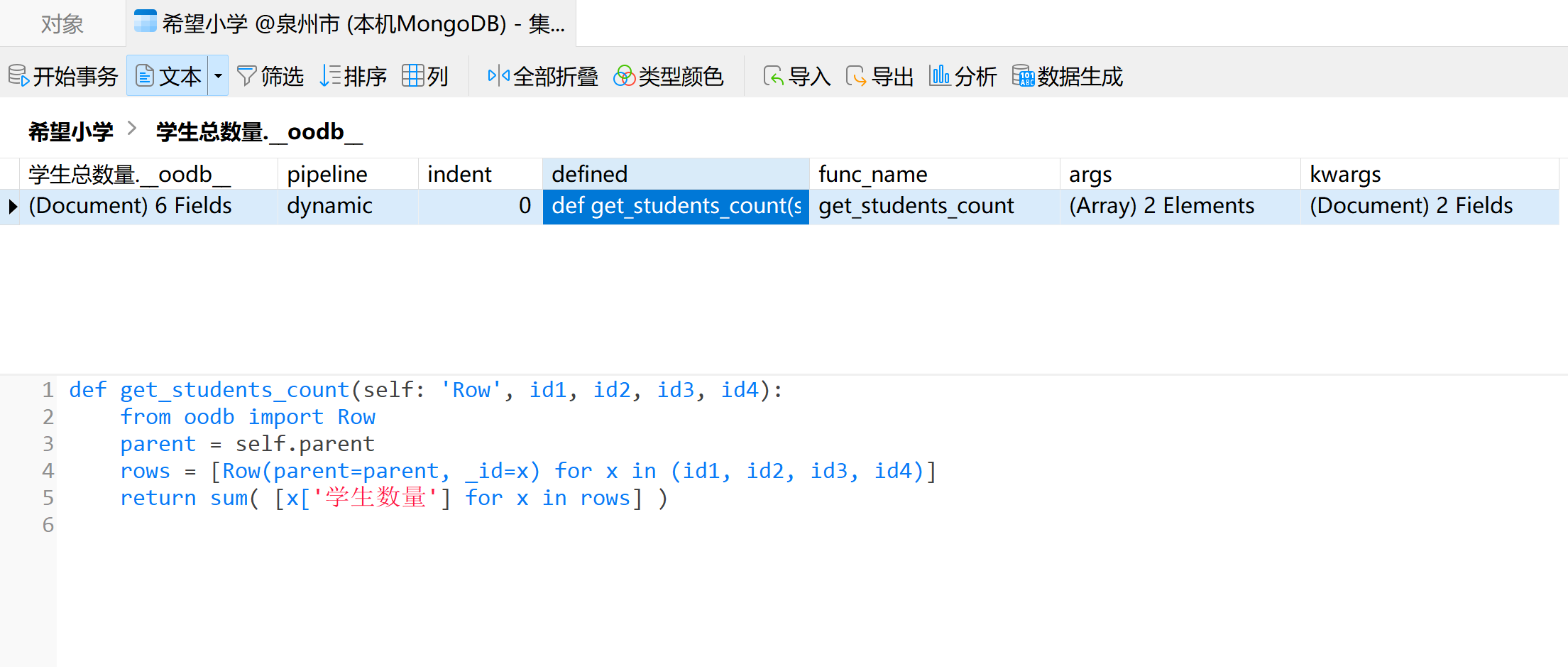{kind=link}
继承、方法、动态属性等特性都是动态解析的,当一个子对象继承一个父对象时,数据库中只会存储这两个对象的父子关系,而非把父对象的全部属性复制到子对象。因此:
1、当我们修改某个父对象的属性值时,仅该父对象的(在硬盘上的)实际存储值会发生变化,而它的子孙对象的(在硬盘上的)实际存储值不会发生任何变化,并且不会影响这两个对象的继承关系。
2、当我们欲修改任意一个对象的属性值时,除了使用 oodb(即本软件)的接口修改以外,也可以直接通过 Navicat 等管理工具手动修改,二者的效果是完全一致的。
筛选【年龄>13,且视力≧4.6,且性别为女】的数据,并进行查改删:
查询:sheet[mc.年龄 > 13][mc.视力 >= 4.6][mc.性别 == '女'].find( )
修改:sheet[mc.年龄 > 13][mc.视力 >= 4.6][mc.性别 == '女'].update( {'年级':'五年级', '爱好':'画画,跳绳'} )
删除:sheet[mc.年龄 > 13][mc.视力 >= 4.6][mc.性别 == '女'].delete( )
| 代码 | 解释 |
|---|---|
| mc.年龄 > 10 | 大于 |
| mc.年龄 >= 10 | 大于或等于 |
| mc.年龄 < 10 | 小于 |
| mc.年龄 <= 10 | 小于或等于 |
| mc.年龄 == 10 | 等于 |
| mc.年龄 != 10 | 不等于 |
| mc.年级 == mf.isin( '初三', '高二' ) | 若字段值是传入值的成员,则符合 |
| mc.年龄 == mf.notin( 10, 30, 45 ) | 若字段值不是传入值的成员,则符合 |
| mc.爱好 == mf.contain_all( '画画', '足球' ) | 若(列表)字段值包含传入值的所有元素,则符合 |
| mc.爱好 == mf.contain_any( '画画', '足球' ) | 若(列表)字段值包含传入值的至少1个元素,则符合 |
| mc.爱好 == mf.contain_none( '画画', '足球' ) | 若(列表)字段值不包含传入值的任何元素,则符合 |
| mc.姓名 == mf.re( '小' ) | 正则匹配 |
| [mc.年龄 > 3][mc.年龄 < 100] | 交集(方式一) |
| [ (mc.年龄 > 3) & (mc.年龄 < 100) ] | 交集(方式二) |
| [(mc.年龄<30)| (mc.年龄>30) | (mc.年龄==30) | (mc.年龄==None)] | 并集 |
| [ (mc.年龄 > 3) - (mc.年龄 > 100) ] | 差集 |
| [ ~(mc.年龄 > 100) ] | 补集 |
注:
1、isin、notin 用于判断(普通)字段的值是否传入值的成员,针对普通字段。
2、contain_any、contain_none 用于判断传入值是否(列表)字段的值的成员,针对列表字段。
3、isin、notin、contain_all、contain_any、contain_none 的传入值都不必是同类型的数据,以 isin 为例:可以这样使用:mc.tag == mf.isin( 3, 3.5, '学生', None ),传入值含有 int、float、str、NoneType 等多种类型。
4、成员运算符未传入任何值时的处理方式:
| 代码 | 处理方式 |
|---|---|
| mc.年级 == mf.isin( ) | 所有数据都 不符合 |
| mc.年级 == mf.notin( ) | 所有数据都 符合 |
| mc.爱好 == mf.contain_all( ) | 所有数据都 符合 |
| mc.爱好 == mf.contain_any( ) | 所有数据都 不符合 |
| mc.爱好 == mf.contain_none( ) | 所有数据都 符合 |
5、四种集合运算可以相互嵌套,且可以无限嵌套。
筛选【年龄>13或视力≧4.6、且姓名含有‘小’、且年龄不高于15】的数据:
查询:sheet[(mc.年龄>13) | (mc.视力>=4.6)][mc.姓名 == mf.re('小')][~(mc.年龄>15)].find( )
修改:sheet[(mc.年龄>13) | (mc.视力>=4.6)][mc.姓名 == mf.re('小')][~(mc.年龄>15)].update( {'年级':'初三'} )
删除:sheet[(mc.年龄>13) | (mc.视力>=4.6)][mc.姓名 == mf.re('小')][~(mc.年龄>15)].delete( )
可使用 mc.xxx.xxx.xxx... 的形式来表示子孙元素。
查询【语文成绩>80】的数据:
sheet[mc.成绩.语文 > 80].find()MongoDB 支持各种特殊的字段名,如:数字、符号、emoji 表情,这些字符在 Python 中不是合法变量名,因此使用 mc.1、mc.+ 等格式会报错,可用 mc['1']、mc['+']、mc['👈'] 这种格式代替。
变量 mc 无字段提示功能,输入‘mc.’后,编辑器不会提示可选字段。
为了获得字段提示功能,可自建一个‘mc2’:
class mc2(mc):
姓名 = 年龄 = 幸运数字 = None
class 成绩:
语文 = 数学 = None
sheet[mc.姓名 == '小王'][mc2.年龄 > 10].find()
sheet[mc.姓名 == '小王'][mc2.成绩.语文 > 80].find()注:
1、mc2 与 mc 用法完全一致,可混用。
2、mc2 设置字段提示后,仅具备提示效果,而不产生任何实际约束。
| 功能 | 代码 |
|---|---|
| 统计库的数量 | oom.len( ) |
| 统计表的数量 | db.len( ) |
| 统计行的数量 | sheet.len( ) |
| 统计符合条件的行的数量 | sheet[ mc.age > 8 ].len( ) |
| 获取库名清单 | oom.get_db_names( ) |
| 获取表名清单 | db.get_sheet_names( ) |
| 删除某个库 | db.delete_db( ) |
| 删除某张表 | sheet.delete_sheet( ) |
for db in oom:
for sheet in db:
print(sheet.sheet_name)由于新年到了,令所有学生的年龄增加 1 岁:
sheet.update( {'年龄': mo.inc( 1 )} )| 语法 | 含义 |
|---|---|
| mo.inc( 1.5 ) | 自增 1.5 |
| mo.inc( -1.5 ) | 自减 1.5 |
| mo.add( 1, 2, 3 ) | 向列表字段添加元素,仅当被添加的元素不存在时才添加 |
| mo.push( 1, 2, 3 ) | 向列表字段添加元素,无论被添加的元素是否存在都添加 |
| mo.pull( 15 ) | 从列表字段删除 1 个等于 15 的值 |
| mo.popfirst | 从列表字段删除第 1 个元素 |
| mo.poplast | 从列表字段删除最后 1 个元素 |
| mo.rename( '新名称' ) | 重命名字段 |
| mo.unset | 删除字段 |
| mo.delete | 删除字段(与 mo.unset 等价) |
示例:
sheet[mc.姓名=='小六'].update({
'姓名': 'xiaoliu', # 修改为‘xiaoliu’
'年龄': mo.inc(6), # 自增6
'幸运数字': mo.push(666), # 添加666
'视力': mo.rename('眼力'), # 字段名改为‘眼力’
'籍贯': mo.delete, # 删除此字段
'成绩.语文': 60, # 改为60分
'成绩.数学': mo.inc(-6) # 减6分
})