某日,sentry上报了一个问题,打开详情查看,原来是主站调用某服务超时了。好家伙,这不得看看那个服务里到底发生了什么事情。 于是乎又去找寻了一番,发现被调用的服务没有什么可疑的地方,日志也没有问题,那到底发生了什么事情呢?
在我们目前的架构演化中,一种趋势是由单体系统向微服务转化,我司也是如此。当我们进行微服务拆分后,一个请求将会经过多个服务。 这时,如果在链路上某个服务出现了问题,排查问题要花上不少时间。基于此,链路追踪应运而生。
链路追踪的概念最先由google提出,随后为了解决不同的追踪系统API的兼容问题,诞生了 OpenTracing 规范。 作为CNCF(云原生计算基金会)的第三个项目(前两个分别是Kubernetes和Prometheus),业内主流的链路追踪系统基本全都支持。
首先,我们来了解下基本概念:
- Trace: 调用链,一个完整的请求链路
- Span: 一次调用过程,可能是一次方法调用,一个程序块调用,或者一次RPC/数据库访问
- Span Context: Span的上下文信息,包括Trace id,Span id以及其它需要传递到下游服务的内容。 通过Span Context,可以把不同进程里的Span关联到相应的Trace上
那链路追踪到底怎么实现呢,我们看看下面两张图, 分别代表了逐级调用和并行调用两种情况


一次完整的调用链中,每次调用都带上标记链路的trace id,标记调用的span id以及标记上级调用的parent span id, 在调用开始和结束时分别记录下时间。
通过些信息,我们就能还原出本次调用链中的用到的所有服务,同时还能清晰地看出调用的顺序、层级和每次调用花费的时间,还可以在Span Context中自定义的tag来追加我们所需要的信息
了解完协议,我们来看看具体地实现。我司目前使用Elastic APM来进行链路追踪和性能分析。
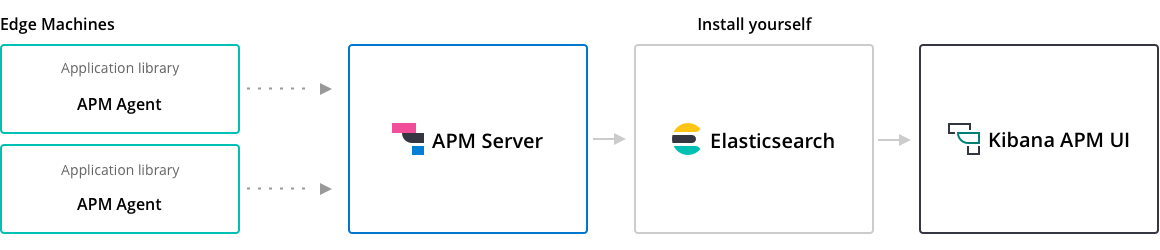
上图是apm的架构,agent会自动在调用中注入tracing相关的内容,并上报到apm server,经过处理后在kibana apm ui中展示。
我们目前的服务调用中存在http和grpc两种方式,在实践中发现,对于grpc的调用,没有合并展示到完整的调用链中。如下图所示。

根据我们上文对追踪机制的了解,猜测问题应该出在调用grpc服务时trace id和span context没有传递下去。 不妨先看看http方式是如何处理的, 翻看源码,可以知道,在调用其他http服务时,apm会自动在header中传递TRACEPARENT_HEADER_NAME和TRACEPARENT_LEGACY_HEADER_NAME, 其中TRACEPARENT_LEGACY_HEADER_NAME是兼容旧版本的。
def _set_disttracing_headers(headers, trace_parent, transaction):
trace_parent_str = trace_parent.to_string()
headers[constants.TRACEPARENT_HEADER_NAME] = trace_parent_str
if transaction.tracer.config.use_elastic_traceparent_header:
headers[constants.TRACEPARENT_LEGACY_HEADER_NAME] = trace_parent_str
if trace_parent.tracestate:
headers[constants.TRACESTATE_HEADER_NAME] = trace_parent.tracestate再看看处理grpc的源码,不难发现在处理调用时,apm会从context中去获取对应的trace信息,这也印证了我们的猜想。既然找到了问题,那就撸起袖子干。
func NewUnaryServerInterceptor(o ...ServerOption) grpc.UnaryServerInterceptor {
opts := serverOptions{
tracer: apm.DefaultTracer,
recover: false,
requestIgnorer: DefaultServerRequestIgnorer(),
}
for _, o := range o {
o(&opts)
}
return func(
ctx context.Context,
req interface{},
info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler,
) (resp interface{}, err error) {
if !opts.tracer.Recording() || opts.requestIgnorer(info) {
return handler(ctx, req)
}
tx, ctx := startTransaction(ctx, opts.tracer, info.FullMethod)
defer tx.End()
// TODO(axw) define context schema for RPC,
// including at least the peer address.
defer func() {
r := recover()
if r != nil {
e := opts.tracer.Recovered(r)
e.SetTransaction(tx)
e.Context.SetFramework("grpc", grpc.Version)
e.Handled = opts.recover
e.Send()
if opts.recover {
err = status.Errorf(codes.Internal, "%s", r)
} else {
panic(r)
}
}
}()
resp, err = handler(ctx, req)
setTransactionResult(tx, err)
return resp, err
}
}
func startTransaction(ctx context.Context, tracer *apm.Tracer, name string) (*apm.Transaction, context.Context) {
var opts apm.TransactionOptions
if md, ok := metadata.FromIncomingContext(ctx); ok {
traceContext, ok := getIncomingMetadataTraceContext(md, elasticTraceparentHeader)
if !ok {
traceContext, _ = getIncomingMetadataTraceContext(md, w3cTraceparentHeader)
}
opts.TraceContext = traceContext
}
tx := tracer.StartTransactionOptions(name, "request", opts)
tx.Context.SetFramework("grpc", grpc.Version)
return tx, apm.ContextWithTransaction(ctx, tx)
}找到调用grpc的入口,在metadata中传入TRACEPARENT_HEADER_NAME即可。
from elasticapm.conf.constants import TRACEPARENT_HEADER_NAME
from elasticapm.traces import capture_span, execution_context
def _wrap_stub(timeout, retry_times=3):
def wrap_unary(func):
@fn.wraps(func)
def wrapper(*args, **kwargs):
kwargs.setdefault("timeout", timeout)
retry = retry_times
# add trace info
transaction = execution_context.get_transaction()
if transaction:
kwargs["metadata"] = ((TRACEPARENT_HEADER_NAME, transaction.trace_parent.to_string()),)
with capture_span(func._method.decode(), "grpc"):
while retry:
try:
return func(*args, **kwargs)
except grpc.RpcError as err:
if err.code() == grpc.StatusCode.UNAVAILABLE:
retry -= 1
time.sleep(random.random() / 10)
else:
raise err
except InactiveRpcError as ex:
raise Error(ex) from ex
return wrapper
def decorator(func):
for key in dir(func):
if key[0].isupper() and isinstance(getattr(func, key), grpc.UnaryUnaryMultiCallable):
setattr(func, key, wrap_unary(getattr(func, key)))
return func
return decorator调整完成后,最终效果如下图所示,可以看到每次调用的时间,同时以不同的颜色区分出在不同服务中的调用,直观清晰地展示了一个完整的调用链。

随着微服务的普及,系统架构变得越来越复杂。链路追踪可以帮助我们了解系统的行为,在出现问题的时候,提高定位问题的速度。 但是,仅仅通过链路追踪,只能还原整个调用链,我们还需要通过查看日志来了解问题的具体原因,通过性能监控来找出系统的瓶颈。 值得关注的是,OpenTracing与 OpenCensus(业界两强之一,由最早提出Tracing概念的google发起)项目整合成了OpenTelemetry, 标志着Metrics、Tracing、Logging在未来有望全部统一。