Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。
Kubernetes 控制器会监视资源的创建/更新/删除事件,并触发 Reconcile 函数作为响应。整个调整过程被称作 “Reconcile Loop”(调谐循环)或者 “Sync Loop”(同步循环)。Reconcile 是一个使用 object(Resource 的实例)的命名空间和 object 名来调用的函数,使 object 的实际状态与 object 的 Spec 中定义的状态保持一致。调用完成后,Reconcile 会将 object 的状态更新为当前实际状态。
每个控制器内部都有两个核心组件:Informer/SharedInformer 和 Workqueue。其中 Informer/SharedInformer 负责 watch Kubernetes 资源对象的状态变化,然后将相关事件(evenets)发送到 Workqueue 中,最后再由控制器的 worker 从 Workqueue 中取出事件交给控制器处理程序进行处理。
事件 = 动作(create, update 或 delete) + 资源的 key(以 namespace/name 的形式表示)
控制器的主要作用是 watch 资源对象的当前状态和期望状态,然后发送指令来调整当前状态,使之更接近期望状态。为了获得资源对象当前状态的详细信息,控制器需要向 API Server 发送请求。
但频繁地调用 API Server 非常消耗集群资源,因此为了能够多次 get 和 list 对象,Kubernetes 开发人员最终决定使用 client-go 库提供的缓存机制。控制器并不需要频繁调用 API Server,只有当资源对象被创建,修改或删除时,才需要获取相关事件。client-go 库提供了 Listwatcher 接口用来获得某种资源的全部 Object,缓存在内存中;然后,调用 Watch API 去 watch 这种资源,去维护这份缓存;最后就不再调用 Kubernetes 的任何 API :
lw := cache.NewListWatchFromClient(
client,
&v1.Pod{},
api.NamespaceAll,
fieldSelector)上面的这些所有工作都是在 Informer 中完成的,Informer 的数据结构如下所示:
store, controller := cache.NewInformer {
&cache.ListWatch{},
&v1.Pod{},
resyncPeriod,
cache.ResourceEventHandlerFuncs{},尽管 Informer 还没有在 Kubernetes 的代码中被广泛使用(目前主要使用 SharedInformer,下文我会详述),但如果你想编写一个自定义的控制器,它仍然是一个必不可少的概念。
你可以把 Informer 理解为 API Server 与控制器之间的事件代理,把 Workqueue 理解为存储事件的数据结构。
下面是用于构造 Informer 的三种模式:
ListWatcher 是对某个特定命名空间中某个特定资源的 list 和 watch 函数的集合。这样做有助于控制器只专注于某种特定资源。fieldSelector 是一种过滤器,它用来缩小资源搜索的范围,让控制器只检索匹配特定字段的资源。Listwatcher 的数据结构如下所示:
cache.ListWatch {
listFunc := func(options metav1.ListOptions) (runtime.Object, error) {
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Do().
Get()
}
watchFunc := func(options metav1.ListOptions) (watch.Interface, error) {
options.Watch = true
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Watch()
}
}Resource Event Handler 用来处理相关资源发生变化的事件:
type ResourceEventHandlerFuncs struct {
AddFunc func(obj interface{})
UpdateFunc func(oldObj, newObj interface{})
DeleteFunc func(obj interface{})
}- AddFunc : 当资源创建时被调用
- UpdateFunc : 当已经存在的资源被修改时就会调用
UpdateFunc。oldObj表示资源的最近一次已知状态。如果 Informer 向 API Server 重新同步,则不管资源有没有发生更改,都会调用UpdateFunc。 - DeleteFunc : 当已经存在的资源被删除时就会调用
DeleteFunc。该函数会获取资源的最近一次已知状态,如果无法获取,就会得到一个类型为DeletedFinalStateUnknown的对象。
ResyncPeriod 用来设置控制器遍历缓存中的资源以及执行 UpdateFunc 的频率。这样做可以周期性地验证资源的当前状态是否与期望状态匹配。
如果控制器错过了 update 操作或者上一次操作失败了,ResyncPeriod 将会起到很大的弥补作用。如果你想编写自定义控制器,不要把周期设置太短,否则系统负载会非常高。
通过上文我们已经了解到,Informer 会将资源缓存在本地以供自己后续使用。但 Kubernetes 中运行了很多控制器,有很多资源需要管理,难免会出现以下这种重叠的情况:一个资源受到多个控制器管理。
为了应对这种场景,可以通过 SharedInformer 来创建一份供多个控制器共享的缓存。这样就不需要再重复缓存资源,也减少了系统的内存开销。使用了 SharedInformer 之后,不管有多少个控制器同时读取事件,SharedInformer 只会调用一个 Watch API 来 watch 上游的 API Server,大大降低了 API Server 的负载。实际上 kube-controller-manager 就是这么工作的。
SharedInformer 提供 hooks 来接收添加、更新或删除某个资源的事件通知。还提供了相关函数用于访问共享缓存并确定何时启用缓存,这样可以减少与 API Server 的连接次数,降低 API Server 的重复序列化成本和控制器的重复反序列化成本。
lw := cache.NewListWatchFromClient(…)
sharedInformer := cache.NewSharedInformer(lw, &api.Pod{}, resyncPeriod)由于 SharedInformer 提供的缓存是共享的,所以它无法跟踪每个控制器,这就需要控制器自己实现排队和重试机制。因此,大多数 Resource Event Handler 所做的工作只是将事件放入消费者工作队列中。
每当资源被修改时,Resource Event Handler 就会放入一个 key 到 Workqueue 中。key 的表示形式为 /,如果提供了 ,key 的表示形式就是 。每个事件都以 key 作为标识,因此每个消费者(控制器)都可以使用 workers 从 Workqueue 中读取 key。所有的读取动作都是串行的,这就保证了不会出现两个 worker 同时读取同一个 key 的情况。
Workqueue 在 client-go 库中的位置为 client-go/util/workqueue,支持的队列类型包括延迟队列,定时队列和速率限制队列。下面是速率限制队列的一个示例:
queue :=
workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())Workqueue 提供了很多函数来处理 key,每个 key 在 Workqueue 中的生命周期如下图所示:
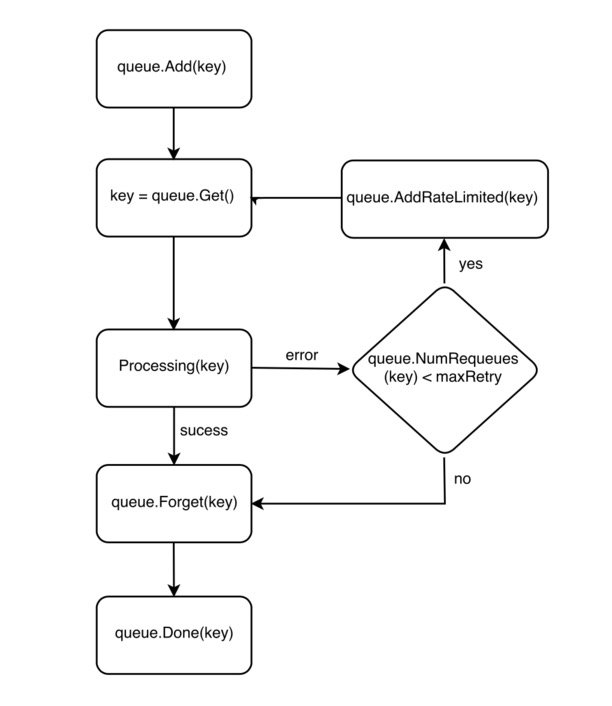
如果处理事件失败,控制器就会调用 AddRateLimited() 函数将事件的 key 放回 Workqueue 以供后续重试(如果重试次数没有达到上限)。如果处理成功,控制器就会调用 Forget() 函数将事件的 key 从 Workqueue 中移除。注意:该函数仅仅只是让 Workqueue 停止跟踪事件历史,如果想从 Workqueue 中完全移除事件,需要调用 Done() 函数。