MarkupLM模型在MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding中由Junlong Li,Yiheng Xu,Lei Cui,Furu Wei提出。与原始的BERT不同,MarkupLM模型应用于HTML页面而不是原始文本文档。该模型增加了额外的嵌入层,以提高性能,类似于LayoutLM。
该模型可用于Web页面上的问题回答或Web页面上的信息提取等任务。它在两个重要基准测试中取得了最先进的结果:
论文的摘要如下:
多模态文本、布局和图像的预训练在可视化丰富的文档理解(VrDU)方面取得了显著进展,尤其是对于选择固定布局文档,例如扫描文档图像。然而,仍然有大量的数字文档,其中布局信息不是固定的,需要进行互动和动态渲染以用于可视化,从而使现有的基于布局的预训练方法难于应用。在本文中,我们提出了作为HTML/XML其他标记语言的骨干的MarkupLM,用于具有标记语言(如基于HTML/XML的文档)的文档理解任务的预训练,即预训练文本和标记信息。实验结果表明,预训练的MarkupLM在几个文档理解任务上显著优于现有的强基线模型。预训练模型和代码将公开可用。
提示:
- 除了
input_ids之外,[~MarkupLMModel.forward]还期望有两个额外的输入,即xpath_tags_seq和xpath_subs_seq。这些是输入序列中每个token的XPATH标记和下标。 - 一个可以使用[
MarkupLMProcessor]来为模型准备所有数据。有关详细信息,请参阅使用指南。 - 可以在这里找到演示笔记本。
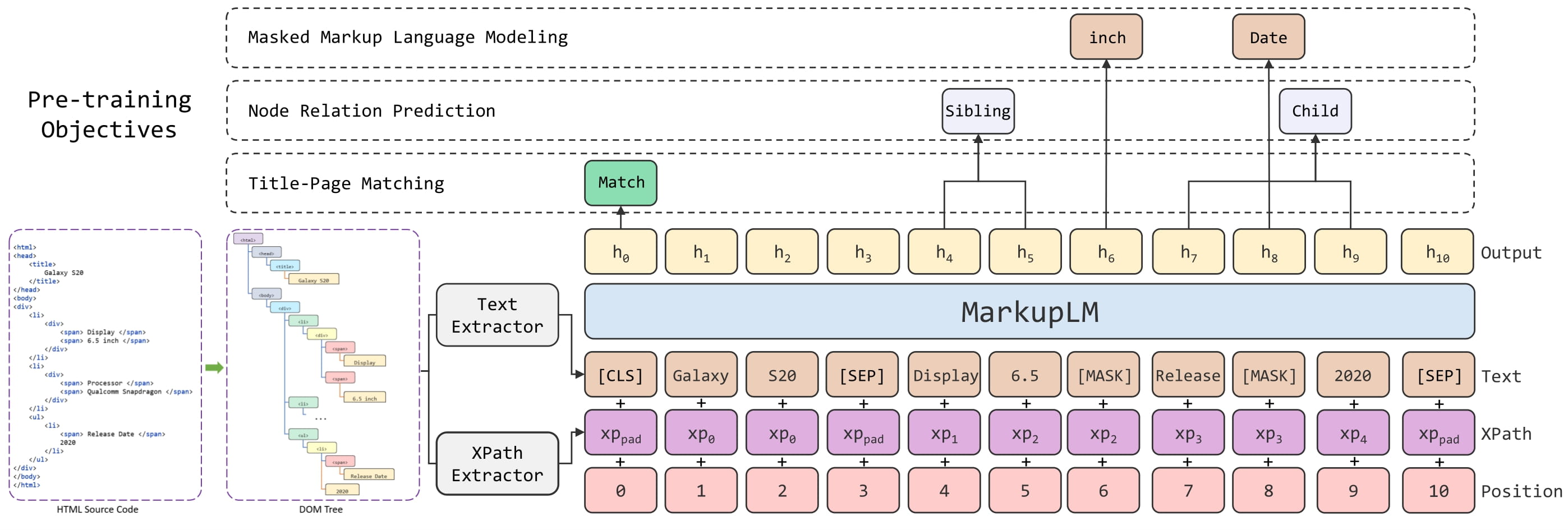
MarkupLM架构。取自 原始论文。
为模型准备数据的最简单方法是使用[MarkupLMProcessor],它在内部结合了特征提取器([MarkupLMFeatureExtractor])和标记器([MarkupLMTokenizer]或[MarkupLMTokenizerFast])。特征提取器用于从HTML字符串中提取所有节点和XPATH,并将它们提供给标记器,将它们转换为模型的token级输入(例如input_ids等)。注意,你仍然可以单独使用特征提取器和标记器,如果你只想处理其中一个任务。
from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
feature_extractor = MarkupLMFeatureExtractor()
tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
processor = MarkupLMProcessor(feature_extractor, tokenizer)简而言之,你可以将HTML字符串(和可能的其他数据)提供给[MarkupLMProcessor],它将创建模型所需的输入。在内部,处理器首先使用[MarkupLMFeatureExtractor]获取节点和相应的XPATH列表。然后将节点和XPATH提供给[MarkupLMTokenizer]或[MarkupLMTokenizerFast],将它们转换为token级的input_ids、attention_mask、token_type_ids、xpath_subs_seq、xpath_tags_seq。可以选择性地向处理器提供节点标签,它们将被转换为token级的labels。
[MarkupLMFeatureExtractor]在内部使用Beautiful Soup,一个用于从HTML和XML文件中提取数据的Python库。请注意,你仍然可以使用你选择的自定义解析解决方案,并将节点和XPATH自己提供给[MarkupLMTokenizer]或[MarkupLMTokenizerFast]。
总共有5种用例支持处理器。下面我们列出了所有这些用例。请注意,每个用例都适用于批处理和非批处理输入(我们为非批处理输入进行说明)。
用例1:网页分类(训练,推理)+token分类(推理),parse_html = True
这是最简单的情况,处理器将使用特征提取器从HTML中获取所有节点和XPATH。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>Here is my website.</p>
... </body>
... </html>"""
>>> # 注意,你还可以在此处添加所有标记器参数,如填充、截断等
>>> encoding = processor(html_string, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例2:网页分类(训练,推理)+token分类(推理),parse_html=False
如果已经获取了所有节点和XPATH,就不需要特征提取器。在这种情况下,应将节点和相应的XPATH直接提供给处理器,并确保将parse_html设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例3:token分类(训练),parse_html=False
对于token分类任务(例如SWDE),你还可以提供相应的节点标签,以便训练模型。处理器将把它们转换为token级别的labels。默认情况下,它只会为一个词的第一个子词进行标记,并将其余的子词标记为-100,这是PyTorch的CrossEntropyLoss的ignore_index。如果你希望标记一个词的所有子词,可以将标记器初始化为only_label_first_subword设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> node_labels = [1, 2, 2, 1]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])用例4:网页问答(推理),parse_html=True
对于Web页面上的问答任务,你可以向处理器提供问题。默认情况下,处理器将使用特征提取器获取所有节点和XPATH,并创建[CLS]问题token[SEP]单词token[SEP]。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>My name is Niels.</p>
... </body>
... </html>"""
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例5:网页问答(推理),parse_html=False
对于问答任务(例如WebSRC),你可以向处理器提供问题。如果你已经自己提取了所有节点和XPATH,请直接提供它们给处理器。确保将parse_html设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> question = "What's his name?"
>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])[[autodoc]] MarkupLMConfig - all
[[autodoc]] MarkupLMFeatureExtractor - call
[[autodoc]] MarkupLMTokenizer - build_inputs_with_special_tokens - get_special_tokens_mask - create_token_type_ids_from_sequences - save_vocabulary
[[autodoc]] MarkupLMTokenizerFast - all
[[autodoc]] MarkupLMProcessor - call
[[autodoc]] MarkupLMModel - forward
[[autodoc]] MarkupLMForSequenceClassification - forward
[[autodoc]] MarkupLMForTokenClassification - forward
[[autodoc]] MarkupLMForQuestionAnswering - forward