Brandon Smock,Rohith Pesala,Robin Abraham在PubTables-1M: Towards comprehensive table extraction from unstructured documents中提出了表格变换器模型。作者引入了一个新的数据集PubTables-1M,以对比不结构化文档中的表格提取、表格结构识别和功能分析的进展。作者训练了2个DETR模型,一个用于表格检测,一个用于表格结构识别,被称为表格变换器。
论文的摘要如下:
最近,在将机器学习应用于从不结构化文档中推断和提取表格结构方面取得了重要进展。然而,最大的挑战之一仍然是创建具有完整、明确的大规模真实数据集。为了解决这个问题,我们开发了一个新的更全面的表格提取数据集,称为PubTables-1M。PubTables-1M包含了来自科学文章的近百万个表格,支持多种输入模态,并包含了详细的表头和位置信息,对于各种建模方法都是有用的。它还通过一种新颖的规范化过程解决了先前数据集中观察到的一个显著的真实性不一致性问题,被称为过分分割。我们证明,这些改进在训练性能上显著提高,使得对表格结构识别的模型性能评估更加可靠。此外,我们还展示了在不需要这些任务的任何特殊定制的情况下,在PubTables-1M上训练的基于transformer的目标检测模型在检测、结构识别和功能分析等三个任务上都能取得出色的结果。
提示:
- 作者发布了两个模型,一个用于文档中的表格检测,一个用于表格结构识别(即识别表格中的行、列等)。
- 你可以使用[
AutoImageProcessor] API来为模型准备图像和可选目标。这将在幕后加载一个[DetrImageProcessor]。
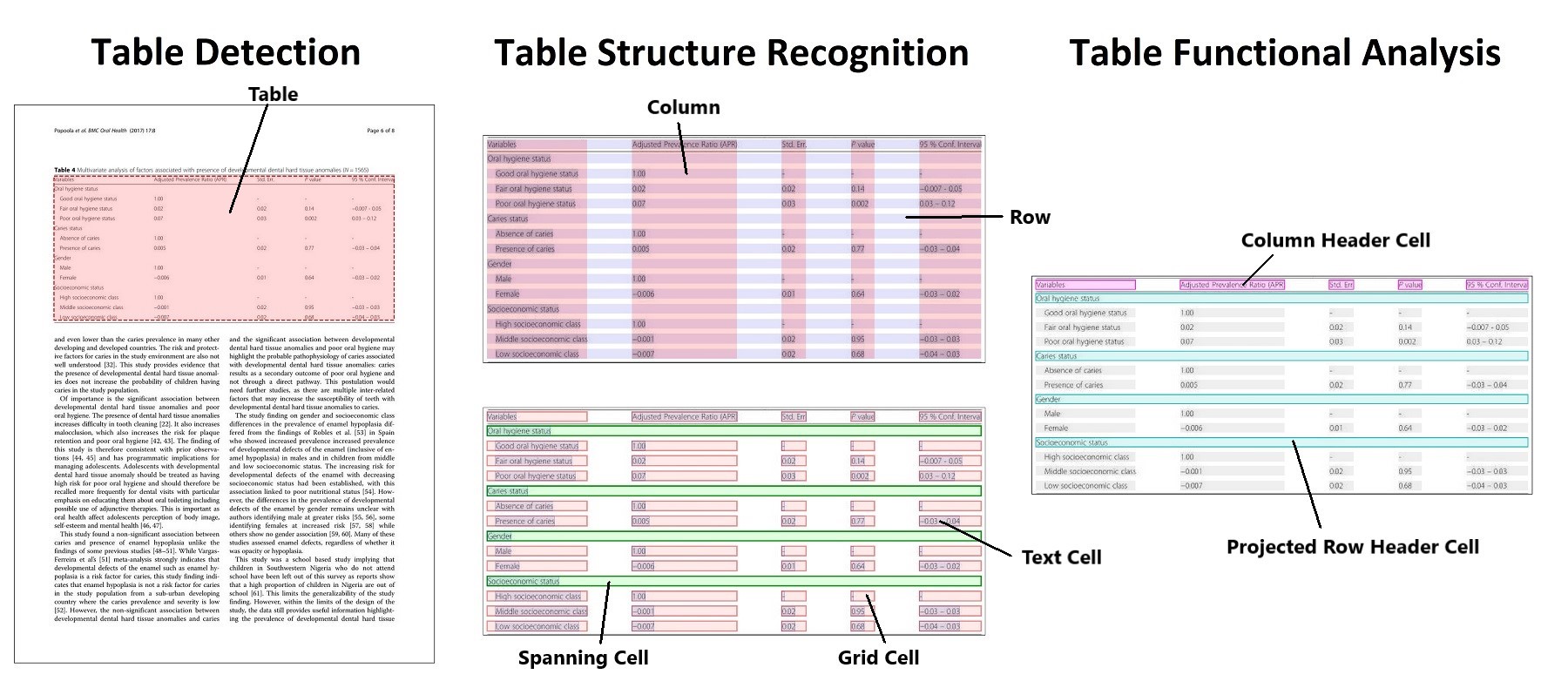
明确表格检测和表格结构识别。引用自原始论文。
[[autodoc]] TableTransformerConfig
[[autodoc]] TableTransformerModel - forward
[[autodoc]] TableTransformerForObjectDetection - forward