Provides wicked fast and scalable streaming log nomming via Apache Spark. Spark is useful for simple processing and filtering distributed tasks to complex data analysis.
data -> message broker -> Apache Spark nomming -> message broker -> elasticsearch

- Apache Spark v1.6.1 (provided by maven) Using a local cluster for now. If you want to use an external Spark cluster (I didn't test this yet):
docker run -it --rm --volume "$(pwd)":/lognom -p 8088:8088 -p 8042:8042 -p 4040:4040 --name spark --hostname sandbox sequenceiq/spark:1.4.1 bash
- Scala v2.11.8 (provided by maven)
- Jedis v2.7 (provided by maven)
- spark-redis (packaged internally)
- Redis v3.2.1 (external)
- Elasticsearch-spark 2.3.2 (provided by maven)
- Elasticsearch 2.3.2 (external)
docker run --rm --name redis-logs redis
Clean and build packages:
mvn clean package -DskipTests
Start it up:
mvn exec:java -Dexec.mainClass="org.squishyspace.lognom.LogNom"
Make your changes in ./src/main/scala/org.squishyspace/LogNom.scala
Redis/Kafka data comes into Apache Spark as a data stream (DStream).
A sliding window is used to batch up the stream in n seconds batches.
Batch processing happens on the Spark cluster.
The DStream object is an RDD (Resilient Distributed Dataset) over time.
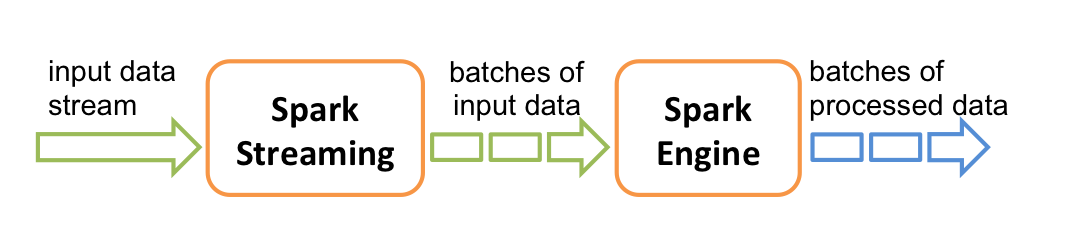
Elasticsearch data is represented as a native RDD.
Best to read Spark's guide, but i'll sum the main points up here.
RDDs support transformations and actions. Transformations create a new data set from an existing one, changed in some way, and an action does something with the changed data. Transformations are instantaneously queued up and computation does not actually begin across the cluster until an action is performed.