1. /bin 存放可执行的二进制文件
2. /include/myslam 存放slam工程模块的头文件,只要是.h 引用头文件时时
需写 include "myslam/xxx.h"不容易和其他库混淆
3. /src 存放源代码文件 主要是.cpp文件
4. /test 存放测试用的文件 也是 .cpp文件
5. /lib 存放编译好的库文件
6. /config 存放配置文件
7. /cmake_modules 存放第三方库的cmake文件 例如使用g2o eigen库时
0.1版本 类
Frame 帧 Frame::Ptr frame
Camera 相机模型 Camera::Ptr camera_
MapPoint 特征点/路标点 MapPoint::Ptr map_point
Map 管理特征点 保存所有的特征点/路标 和关键帧
Config 提供配置参数
CMAKE_MINIMUM_REQUIRED( VERSION 2.8 ) # 设定版本
PROJECT( slam ) # 设定工程名
SET( CMAKE_CXX_COMPILER "g++") # 设定编译器
# 设定 可执行 二进制文件 的目录=========
# 二进制就是可以直接运行的程序
SET( EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin)
# 设定存放 编译出来 的库文件的目录=====
# 库文件呢,就是为这些二进制提供函数的啦
SET( LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
# 并且把该目录设为 连接目录
LINK_DIRECTORIES( ${PROJECT_SOURCE_DIR}/lib)
# 设定头文件目录
INCLUDE_DIRECTORIES( ${PROJECT_SOURCE_DIR}/include)
# 增加子文件夹,也就是进入 源代码 文件夹继续构建
ADD_SUBDIRECTORY( ${PROJECT_SOURCE_DIR}/src)
# 增加一个可执行的二进制
ADD_EXECUTABLE( main main.cpp )
# =========================================
# 增加PCL库的依赖
FIND_PACKAGE( PCL REQUIRED COMPONENTS common io )
# 增加opencv的依赖
FIND_PACKAGE( OpenCV REQUIRED )
# 添加头文件和库文件
ADD_DEFINITIONS( ${PCL_DEFINITIONS} )
INCLUDE_DIRECTORIES( ${PCL_INCLUDE_DIRS} )
LINK_LIBRARIES( ${PCL_LIBRARY_DIRS} )
ADD_EXECUTABLE( generate_pointcloud generatePointCloud.cpp )
TARGET_LINK_LIBRARIES( generate_pointcloud ${OpenCV_LIBS}
${PCL_LIBRARIES} )
# 自检函数库=======
# 最后,在 src/CMakeLists.txt 中加入以下几行,将 slamBase.cpp 编译成一个库,供将来调用:
ADD_LIBRARY( slambase slamBase.cpp )
TARGET_LINK_LIBRARIES( slambase
${OpenCV_LIBS}
${PCL_LIBRARIES} )
// generatePointCloud.cpp
// https://www.cnblogs.com/gaoxiang12/p/4652478.html
// 部分头文件省略
// 定义点云类型
typedef pcl::PointXYZRGBA PointT; # 点类型
typedef pcl::PointCloud<PointT> PointCloud; # 点云类型
/*
我们使用OpenCV的imread函数读取图片。在OpenCV2里,图像是以矩阵(cv::MAt)作为基本的数据结构。
Mat结构既可以帮你管理内存、像素信息,还支持一些常见的矩阵运算,是非常方便的结构。
彩色图像含有R,G,B三个通道,每个通道占8个bit(也就是unsigned char),故称为8UC3(8位unsigend char, 3通道)结构。
而深度图则是单通道的图像,每个像素由16个bit组成(也就是C++里的unsigned short),像素的值代表该点离传感器的距离。
通常1000的值代表1米,所以我们把camera_factor设置成1000.
这样,深度图里每个像素点的读数除以1000,就是它离你的真实距离了。
*/
// 相机内参
const double camera_factor = 1000; // 深度值放大倍数
const double camera_cx = 325.5;
const double camera_cy = 253.5;
const double camera_fx = 518.0;
const double camera_fy = 519.0;
// 点云变量
// 使用智能指针,创建一个空点云。这种指针用完会自动释放。
PointCloud::Ptr cloud ( new PointCloud );
// 遍历深度图
// 按照“先列后行”的顺序,遍历了整张深度图。
for (int m = 0; m < depth.rows; m++) // 每一行
for (int n=0; n < depth.cols; n++) // 每一列
{
// 获取深度图中(m,n)处的值
ushort d = depth.ptr<ushort>(m)[n];
// 深度图第m行,第n行的数据可以使用depth.ptr<ushort>(m) [n]来获取。
// 其中,cv::Mat的ptr函数会返回指向该图像第m行数据的头指针。
// 然后加上位移n后,这个指针指向的数据就是我们需要读取的数据啦。
// d 可能没有值,若如此,跳过此点
if (d == 0)
continue;
// d 存在值,则向点云增加一个点
PointT p;
// 计算这个点的空间坐标
p.z = double(d) / camera_factor;
p.x = (n - camera_cx) * p.z / camera_fx;
p.y = (m - camera_cy) * p.z / camera_fy;
// 从rgb图像中获取它的颜色
// rgb是三通道的BGR格式图,所以按下面的顺序获取颜色
p.b = rgb.ptr<uchar>(m)[n*3];
p.g = rgb.ptr<uchar>(m)[n*3+1];
p.r = rgb.ptr<uchar>(m)[n*3+2];
// 把p加入到点云中
cloud->points.push_back( p );
}// include/slamBase.h 库头文件
/*************************************************************************
> File Name: rgbd-slam-tutorial-gx/part III/code/include/slamBase.h
> Author: xiang gao
> Mail: [email protected]
> Created Time: 2015年07月18日 星期六 15时14分22秒
> 说明:rgbd-slam教程所用到的基本函数(C风格)
************************************************************************/
# pragma once
// 各种头文件
// C++标准库
#include <fstream>
#include <vector>
using namespace std;
// OpenCV
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
//PCL
#include <pcl/io/pcd_io.h>
#include <pcl/point_types.h>
// 类型定义
typedef pcl::PointXYZRGBA PointT;
typedef pcl::PointCloud<PointT> PointCloud;
// 相机内参结构===============================
// 把相机参数封装成了一个结构体,
struct CAMERA_INTRINSIC_PARAMETERS
{
double cx, cy, fx, fy, scale;
};
// 另外还声明了 image2PointCloud 和 point2dTo3d 两个函数
// 函数接口
// image2PonitCloud 将rgb图转换为点云
PointCloud::Ptr image2PointCloud( cv::Mat& rgb, cv::Mat& depth, CAMERA_INTRINSIC_PARAMETERS& camera );
// point2dTo3d 将单个点从图像坐标转换为空间坐标
// input: 3维点Point3f (u,v,d)
cv::Point3f point2dTo3d( cv::Point3f& point, CAMERA_INTRINSIC_PARAMETERS& camera );// src/slamBase.cpp
/*************************************************************************
> File Name: src/slamBase.cpp
> Author: xiang gao
> Mail: [email protected]
> Implementation of slamBase.h
> Created Time: 2015年07月18日 星期六 15时31分49秒
************************************************************************/
#include "slamBase.h"
// image2PonitCloud 将rgb图转 换为 点云====================
PointCloud::Ptr image2PointCloud( cv::Mat& rgb, cv::Mat& depth, CAMERA_INTRINSIC_PARAMETERS& camera )
{
PointCloud::Ptr cloud ( new PointCloud );
for (int m = 0; m < depth.rows; m++)
for (int n=0; n < depth.cols; n++)
{
// 获取深度图中(m,n)处的值
ushort d = depth.ptr<ushort>(m)[n];
// d 可能没有值,若如此,跳过此点
if (d == 0)
continue;
// d 存在值,则向点云增加一个点
PointT p;
// 小萝卜2号:关于图像上下翻转问题,是因为opencv定义的坐标系和pcl_viewer显示坐标系不同,opencv是x右y下,而pcl显示是x右y上。
// 解决方法:找到群主程序image2PointCloud函数中,把计算点空间坐标的公式的p.y值添加负号,
// 这样y方向就可以正常显示了,so easy。(或许还有别的方法)
// 计算这个点的空间坐标
p.z = double(d) / camera.scale;
p.x = (n - camera.cx) * p.z / camera.fx;
p.y = (m - camera.cy) * p.z / camera.fy;
// 从rgb图像中获取它的颜色
// rgb是三通道的BGR格式图,所以按下面的顺序获取颜色
p.b = rgb.ptr<uchar>(m)[n*3];
p.g = rgb.ptr<uchar>(m)[n*3+1];
p.r = rgb.ptr<uchar>(m)[n*3+2];
// 把p加入到点云中
cloud->points.push_back( p );
}
// 设置并保存点云
cloud->height = 1;
cloud->width = cloud->points.size();
cloud->is_dense = false;
return cloud;
}
// point2dTo3d 将单个点从图像坐标转换为空间坐标
// input: 3维点Point3f (u,v,d)
cv::Point3f point2dTo3d( cv::Point3f& point, CAMERA_INTRINSIC_PARAMETERS& camera )
{
cv::Point3f p; // 3D 点
p.z = double( point.z ) / camera.scale;
p.x = ( point.x - camera.cx) * p.z / camera.fx;
p.y = ( point.y - camera.cy) * p.z / camera.fy;
return p;
}
# 自检函数库=======
# 最后,在 src/CMakeLists.txt 中加入以下几行,将 slamBase.cpp 编译成一个库,供将来调用:
ADD_LIBRARY( slambase slamBase.cpp )
TARGET_LINK_LIBRARIES( slambase
${OpenCV_LIBS}
${PCL_LIBRARIES} )
用基于特征的方法(feature-based)或直接的方法(direct method)来解。
虽说直接法已经有了一定的发展,但目前主流的方法还是基于特征点的方式。
在后者的方法中,首先你需要知道图像里的“特征”,以及这些特征的一一对应关系。
假设我们有两个帧:F1和F2. 并且,我们获得了两组一一对应的 特征点:
P={p1,p2,…,pN}∈F1
Q={q1,q2,…,qN}∈F2
其中p和q都是 R3 中的点。
我们的目的是求出一个旋转矩阵R和位移矢量t,使得:
∀i, pi = R*qi + t
然而实际当中由于误差的存在,等号基本是不可能的。所以我们通过最小化一个误差来求解R,t:
min R,t ∑i=1/N * ∥pi−(R*qi + t)∥2
这个问题可以用经典的ICP算法求解。其核心是奇异值分解(SVD)。 我们将调用OpenCV中的函数求解此问题,
那么从这个数学问题上来讲,我们的关键就是要获取一组一一对应的空间点,
这可以通过图像的特征匹配来完成。
提示:由于OpenCV中没有提供ICP,我们在实现中使用PnP进行求解。 2d-3d
// detectFeatures.cpp
/*************************************************************************
> File Name: detectFeatures.cpp
> Author: xiang gao
> Mail: [email protected]
> 特征提取与匹配
> Created Time: 2015年07月18日 星期六 16时00分21秒
************************************************************************/
#include<iostream>
#include "slamBase.h"
using namespace std;
// OpenCV 特征检测模块
#include <opencv2/features2d/features2d.hpp>
// #include <opencv2/nonfree/nonfree.hpp> // use this if you want to use SIFT or SURF
#include <opencv2/calib3d/calib3d.hpp>
int main( int argc, char** argv )
{
// 声明并从data文件夹里读取两个rgb与深度图
cv::Mat rgb1 = cv::imread( "./data/rgb1.png");
cv::Mat rgb2 = cv::imread( "./data/rgb2.png");
cv::Mat depth1 = cv::imread( "./data/depth1.png", -1);
cv::Mat depth2 = cv::imread( "./data/depth2.png", -1);
// 声明特征提取器 与 描述子提取器
cv::Ptr<cv::FeatureDetector> detector;
cv::Ptr<cv::DescriptorExtractor> descriptor;
// 构建提取器,默认两者都为 ORB
// 如果使用 sift, surf ,之前要初始化nonfree模块=========
// cv::initModule_nonfree();
// _detector = cv::FeatureDetector::create( "SIFT" );
// _descriptor = cv::DescriptorExtractor::create( "SIFT" );
detector = cv::FeatureDetector::create("ORB");
descriptor = cv::DescriptorExtractor::create("ORB");
// 使用 _detector->detect()函数提取关键点==============================
// 关键点是一种cv::KeyPoint的类型。
// 带有 Point2f pt 这个成员变量,指这个关键点的像素坐标。
// kp1[i].pt 获取 这个关键点的像素坐标 (u,v) ==================
// 此外,有的关键点还有半径、角度等参数,画在图里就会像一个个的圆一样。
vector< cv::KeyPoint > kp1, kp2; // 关键点
detector->detect( rgb1, kp1 ); // 提取关键点
detector->detect( rgb2, kp2 );
cout<<"Key points of two images: "<<kp1.size()<<", "<<kp2.size()<<endl;
// 可视化, 显示关键点
cv::Mat imgShow;
cv::drawKeypoints( rgb1, kp1, imgShow, cv::Scalar::all(-1), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS );
cv::imshow( "keypoints", imgShow );
cv::imwrite( "./data/keypoints.png", imgShow );
cv::waitKey(0); //暂停等待一个按键
// 计算描述子===================================================
// 在 keypoint 上计算描述子。
// 描述子是一个cv::Mat的矩阵结构,
// 它的每一行代表一个对应于Keypoint的特征向量。
// 当两个keypoint的描述子越相似,说明这两个关键点也就越相似。
// 我们正是通过这种相似性来检测图像之间的运动的。
cv::Mat desp1, desp2;
descriptor->compute( rgb1, kp1, desp1 );
descriptor->compute( rgb2, kp2, desp2 );
// 匹配描述子===================================================
// 对上述的描述子进行匹配。
// 在OpenCV中,你需要选择一个匹配算法,
// 例如粗暴式(bruteforce),近似最近邻(Fast Library for Approximate Nearest Neighbour, FLANN)等等。
// 这里我们构建一个FLANN的匹配算法:
vector< cv::DMatch > matches;
// cv::BFMatcher matcher; // 暴力匹配,穷举
cv::FlannBasedMatcher matcher; // 近似最近邻
matcher.match( desp1, desp2, matches );
cout<<"Find total "<<matches.size()<<" matches."<<endl;
// 匹配完成后,算法会返回一些 DMatch 结构。该结构含有以下几个成员:
// queryIdx 源特征描述子的索引(也就是第一张图像,第一个参数代表的desp1)。
// trainIdx 目标特征描述子的索引(第二个图像,第二个参数代表的desp2)
// distance 匹配距离,越大表示匹配越差。 matches[i].distance
// matches.size() 总数
// 有了匹配后,可以用drawMatch函数画出匹配的结果:
// 可视化:显示匹配的特征
cv::Mat imgMatches;
cv::drawMatches( rgb1, kp1, rgb2, kp2, matches, imgMatches );
cv::imshow( "matches", imgMatches );
cv::imwrite( "./data/matches.png", imgMatches );
cv::waitKey( 0 );
// 筛选匹配,把距离太大的去掉
// 这里使用的准则是去掉大于四倍最小距离的匹配
// 筛选的准则是:去掉大于最小距离四倍的匹配。====================================
vector< cv::DMatch > goodMatches;
double minDis = 9999;
for ( size_t i=0; i<matches.size(); i++ )
{
if ( matches[i].distance < minDis )
minDis = matches[i].distance;
}
cout<<"min dis = "<<minDis<<endl;// 最好的匹配===============
for ( size_t i=0; i<matches.size(); i++ )
{
if (matches[i].distance < 10*minDis)
goodMatches.push_back( matches[i] );// 筛选出来的 剩下的较好的匹配
}
// 显示 good matches
cout<<"good matches="<<goodMatches.size()<<endl;
cv::drawMatches( rgb1, kp1, rgb2, kp2, goodMatches, imgMatches );
cv::imshow( "good matches", imgMatches );
cv::imwrite( "./data/good_matches.png", imgMatches );
cv::waitKey(0);
// 计算图像间的运动关系
// 关键函数:cv::solvePnPRansac()
// 为调用此函数准备必要的参数
// 第一个帧的三维点
vector<cv::Point3f> pts_obj;// desp1 的2d点 利用深度值 转换成 3d点
// 第二个帧的图像点
vector< cv::Point2f > pts_img;
// 相机内参
CAMERA_INTRINSIC_PARAMETERS C;
C.cx = 325.5;
C.cy = 253.5;
C.fx = 518.0;
C.fy = 519.0;
C.scale = 1000.0;
for (size_t i=0; i<goodMatches.size(); i++)
{
// query 是第一个, train 是第二个
cv::Point2f p = kp1[goodMatches[i].queryIdx].pt; // 2d点==============
// 获取d是要小心!x是向右的,y是向下的,所以y才是行,x是列!!!!!!!!
ushort d = depth1.ptr<ushort>( int(p.y) )[ int(p.x) ];// 从深度图 取得深度===
if (d == 0)
continue;// 跳过深度值异常的点=============
pts_img.push_back( cv::Point2f( kp2[goodMatches[i].trainIdx].pt ) );// 图像2 关键点对应的 2d像素点
// 将(u,v,d)转成(x,y,z)=======================
cv::Point3f pt ( p.x, p.y, d );
cv::Point3f pd = point2dTo3d( pt, C );
pts_obj.push_back( pd );// 图像1 关键点对应 2d像素点 对应的 3d点
}
// 相机内参数矩阵K ===============================
double camera_matrix_data[3][3] =
{
{C.fx, 0, C.cx},
{0, C.fy, C.cy},
{0, 0, 1}
};
// 构建相机矩阵
cv::Mat cameraMatrix( 3, 3, CV_64F, camera_matrix_data );// 8字节
cv::Mat rvec, tvec, inliers;
// 求解pnp 3d点 2d点 相机内参数矩阵K 旋转向量 rvec 平移向量tvec
cv::solvePnPRansac( pts_obj, pts_img, cameraMatrix, cv::Mat(), rvec, tvec, false, 100, 1.0, 100, inliers );
// 这个就叫做“幸福的家庭都是相似的,不幸的家庭各有各的不幸”吧。
// 你这样理解也可以。ransac适用于数据噪声比较大的场合
cout<<"inliers: "<<inliers.rows<<endl; // ransac 随机采样一致性 得到的内点数量
cout<<"R="<<rvec<<endl;
cout<<"t="<<tvec<<endl;
// 画出inliers匹配
vector< cv::DMatch > matchesShow; // 好的匹配
for (size_t i=0; i<inliers.rows; i++)
{
matchesShow.push_back( goodMatches[inliers.ptr<int>(i)[0]] );// inliers 第i行的地一个参数为 匹配点id
}
cv::drawMatches( rgb1, kp1, rgb2, kp2, matchesShow, imgMatches );
cv::imshow( "inlier matches", imgMatches );
cv::imwrite( "./data/inliers.png", imgMatches );
cv::waitKey( 0 );
return 0;
}
// 装进slamBase库中,
// 在 include/slamBase.h 扩展 以下代码
// 我们把关键帧和PnP的结果都封成了结构体,以便将来别的程序调用==========
// FRAME 帧结构=============== 结构体
struct FRAME
{
cv::Mat rgb, depth; // 该帧对应的 彩色图 与深度图
cv::Mat desp; // 特征描述子 集 一行对应一个关键点
vector<cv::KeyPoint> kp; // 关键点 集 kp[i].pt 是关键点对应的像素坐标
};
// PnP 结果 2d-3d 配置结果===== 结构体
struct RESULT_OF_PNP
{
cv::Mat rvec, tvec;
int inliers; // 内点数量=====!!!!
};
// computeKeyPointsAndDesp 同时提取关键点与特征描述子========引用传递==============
void computeKeyPointsAndDesp( FRAME & frame, string detector, string descriptor );
// estimateMotion 2d-3d pnp配准 计算两个帧之间的运动==========引用传递==============
// 输入:帧1和帧2, 相机内参
RESULT_OF_PNP estimateMotion( FRAME & frame1, FRAME & frame2, CAMERA_INTRINSIC_PARAMETERS& camera );
// 提取关键点与特征描述子函数 2d-3d-pnp配准函数 src/slamBase.cpp=========================
// computeKeyPointsAndDesp 同时提取关键点与特征描述子============引用传递==============
void computeKeyPointsAndDesp( FRAME & frame, string detector, string descriptor )
{
cv::Ptr<cv::FeatureDetector> _detector; // 关键点检测
cv::Ptr<cv::DescriptorExtractor> _descriptor; // 描述子计算
cv::initModule_nonfree(); // 如果使用 SIFI / SURF 的话========
_detector = cv::FeatureDetector::create( detector.c_str() );
_descriptor = cv::DescriptorExtractor::create( descriptor.c_str() );
if (!_detector || !_descriptor)
{
cerr<<"Unknown detector or discriptor type !"<<detector<<","<<descriptor<<endl;
return;
}
_detector->detect( frame.rgb, frame.kp ); // 检测关键点
_descriptor->compute( frame.rgb, frame.kp, frame.desp );// 计算描述子
return;
}
// estimateMotion 计算两个帧之间的运动==========================================================
// 输入:帧1和帧2
// 输出:rvec 和 tvec
RESULT_OF_PNP estimateMotion( FRAME& frame1, FRAME& frame2, CAMERA_INTRINSIC_PARAMETERS& camera )
{
static ParameterReader pd; // // 好关键点阈值 参数 读取==============
vector< cv::DMatch > matches;// 匹配点对
cv::FlannBasedMatcher matcher;// 快速最近邻 匹配器============
matcher.match( frame1.desp, frame2.desp, matches );// 对两个关键帧的关键点 进行匹配
cout<<"find total "<<matches.size()<<" matches."<<endl;
// 初步筛选 好的匹配点对==========================
vector< cv::DMatch > goodMatches;
double minDis = 9999;
double good_match_threshold = atof( pd.getData( "good_match_threshold" ).c_str() );// 好关键点阈值 读取
for ( size_t i=0; i<matches.size(); i++ )
{
if ( matches[i].distance < minDis )
minDis = matches[i].distance; // 最好的匹配点对 对应的匹配距离
}
for ( size_t i=0; i<matches.size(); i++ )
{
if (matches[i].distance < good_match_threshold*minDis)
goodMatches.push_back( matches[i] ); // 筛选下来的 好的 匹配点对
}
cout<<"good matches: "<<goodMatches.size()<<endl;
// 第一个帧的三维点
vector<cv::Point3f> pts_obj; // 2d 关键点对应的像素点 + 对应的深度距离 根据相机参数 转换得到
// 第二个帧的图像点
vector< cv::Point2f > pts_img;// 2d 关键点对应的像素点
// 从匹配点对 获取 2d-3d点对 ===========================
for (size_t i=0; i<goodMatches.size(); i++)
{
// query 是第一个, train 是第二个 得到的是 关键点的id
cv::Point2f p = frame1.kp[goodMatches[i].queryIdx].pt;// .pt 获取关键点对应的 像素点
// 获取d是要小心!x是向右的,y是向下的,所以y才是行,x是列!
ushort d = frame1.depth.ptr<ushort>( int(p.y) )[ int(p.x) ];// y行,x列
if (d == 0)
continue; // 深度值不好 跳过
// 将(u,v,d)转成(x,y,z)
cv::Point3f pt ( p.x, p.y, d ); // 2d 关键点对应的像素点 + 对应的深度距离
cv::Point3f pd = point2dTo3d( pt, camera );// 根据相机参数 转换得到 3d点
pts_obj.push_back( pd );
pts_img.push_back( cv::Point2f( frame2.kp[goodMatches[i].trainIdx].pt ) );// 后一帧的 2d像素点
}
// 相机内参数矩阵 K =========================
double camera_matrix_data[3][3] =
{
{camera.fx, 0, camera.cx},
{0, camera.fy, camera.cy},
{0, 0, 1}
};
cout<<"solving pnp"<<endl;
// 构建相机矩阵
cv::Mat cameraMatrix( 3, 3, CV_64F, camera_matrix_data );
cv::Mat rvec, tvec, inliers;
// 求解pnp 3d点 2d点 相机内参数矩阵K 旋转向量 rvec 平移向量tvec
cv::solvePnPRansac( pts_obj, pts_img, cameraMatrix, cv::Mat(), rvec, tvec, false, 100, 1.0, 100, inliers );
// 旋转向量形式 3×1 rvec
// 这个就叫做“幸福的家庭都是相似的,不幸的家庭各有各的不幸”吧。
// 你这样理解也可以。ransac适用于数据噪声比较大的场合
RESULT_OF_PNP result; // 2D-3D匹配结果
result.rvec = rvec;
result.tvec = tvec;
result.inliers = inliers.rows; // 内点数量=====!!!!
return result; 返回
}
此外,我们还实现了一个简单的参数读取类。
这个类读取一个参数的文本文件,能够以关键字的形式提供文本文件中的变量。
// 装进slamBase库中,
// 在 include/slamBase.h 扩展 以下代码
// 参数读取类
class ParameterReader
{
public:
ParameterReader( string filename="./parameters.txt" )
{
ifstream fin( filename.c_str() );
if (!fin)
{
cerr<<"parameter file does not exist."<<endl;
return;
}
while(!fin.eof())// 知道文件结尾
{
string str;
getline( fin, str );// 每一行======
if (str[0] == '#')// [0]是开头的第一个字符
{
// 以‘#’开头的是注释
continue;
}
int pos = str.find("="); // 变量赋值等号 = 前后 无空格=====
if (pos == -1)
continue;// 没找到 =
string key = str.substr( 0, pos ); // 变量名字====
string value = str.substr( pos+1, str.length() );// 参数值 字符串
data[key] = value; // 装入字典========
if ( !fin.good() )
break;
}
}
string getData( string key ) // 按关键字 在 字典中查找========
{
map<string, string>::iterator iter = data.find(key);// 二叉树查找 log(n)
if (iter == data.end())
{
cerr<<"Parameter name "<<key<<" not found!"<<endl;
return string("NOT_FOUND");
}
return iter->second; // 返回对应关键字对应 的 值 iter->first 为 key iter->second 为值
}
public:
map<string, string> data; // 解析得到的参数字典
};
// 示例参数
它读的参数文件是长这个样子的:
# 这是一个参数文件
# 去你妹的yaml! 我再也不用yaml了!简简单单多好!
# 等号前后不能有空格
# part 4 里定义的参数
detector=ORB
descriptor=ORB
good_match_threshold=4
# camera
camera.cx=325.5;
camera.cy=253.5;
camera.fx=518.0;
camera.fy=519.0;
camera.scale=1000.0;
# 如果我们想更改特征类型,就只需在parameters.txt文件里进行修改,不必编译源代码了。
# 这对接下去的各种调试都会很有帮助。点云的拼接,实质上是对点云做变换的过程。这个变换往往是用变换矩阵(transform matrix)来描述的:
T=[R t
O 1]∈R4×4
该矩阵的左上部分 R 是一个3×3的旋转矩阵,它是一个正交阵。
右上部分 t 是3×1的位移矢量。
左下O是3×1的 !!!缩放矢量!!!!,在SLAM中通常取成0,
因为环境里的东西不太可能突然变大变小(又没有缩小灯)。
右下角是个1. 这样的一个阵可以对点或者其他东西进行齐次变换。
[X1 [X2
Y1 Y2
Z1 = T⋅ Z2
1] 1]
由于变换矩阵t 结合了 旋转R 和 平移t,是一种较为经济实用的表达方式。
它在机器人和许多三维空间相关的科学中都有广泛的应用。
PCL里提供了点云的变换函数,只要给定了变换矩阵,就能对移动整个点云:
pcl::transformPointCloud( input, output, T );
OpenCV认为旋转矩阵R,虽然有3×3 那么大,自由变量却只有三个,不够节省空间。
所以在OpenCV里使用了一个向量来表达旋转。
向量的方向是旋转轴,大小则是转过的弧度.
我们先用 罗德里格斯变换(Rodrigues)将旋转向量转换为矩阵,然后“组装”成变换矩阵。
代码如下:
// src/jointPointCloud.cpp===============================
/*****************************************************
> File Name: src/jointPointCloud.cpp
> Author: Xiang gao
> Mail: [email protected]
> Created Time: 2015年07月22日 星期三 20时46分08秒
**********************************************/
#include<iostream>
using namespace std;
#include "slamBase.h"
#include <opencv2/core/eigen.hpp>
#include <pcl/common/transforms.h> // 点云转换
#include <pcl/visualization/cloud_viewer.h> // 点云显示
// Eigen !
#include <Eigen/Core>
#include <Eigen/Geometry>
int main( int argc, char** argv )
{
// 参数读取器, 请见include/slamBase.h
ParameterReader pd;
// 声明两个帧,FRAME结构请见include/slamBase.h
FRAME frame1, frame2;
//本节要拼合data中的两对图像
//读取图像==============================
frame1.rgb = cv::imread( "./data/rgb1.png" );
frame1.depth = cv::imread( "./data/depth1.png", -1);//
frame2.rgb = cv::imread( "./data/rgb2.png" );
frame2.depth = cv::imread( "./data/depth2.png", -1 );
// 提取特征并计算描述子====================
cout<<"extracting features"<<endl;
string detecter = pd.getData( "detector" ); // 参数读取 特征检测器
string descriptor = pd.getData( "descriptor" ); // 描述子计算器
// 计算 特征点和描述子=
computeKeyPointsAndDesp( frame1, detecter, descriptor );
computeKeyPointsAndDesp( frame2, detecter, descriptor );
// 相机内参=========================================
CAMERA_INTRINSIC_PARAMETERS camera;
camera.fx = atof( pd.getData( "camera.fx" ).c_str()); // 参数读取 相机参数 字符串转换成 浮点型
camera.fy = atof( pd.getData( "camera.fy" ).c_str());
camera.cx = atof( pd.getData( "camera.cx" ).c_str());
camera.cy = atof( pd.getData( "camera.cy" ).c_str());
camera.scale = atof( pd.getData( "camera.scale" ).c_str() );
cout<<"solving pnp"<<endl;
// 求解 pnp 2d-3d 配准估计变换======================================
RESULT_OF_PNP result = estimateMotion( frame1, frame2, camera );
cout<<result.rvec<<endl<<result.tvec<<endl;
// 处理result
// 将 旋转向量 转化为 旋转矩阵
cv::Mat R;
cv::Rodrigues( result.rvec, R ); // 旋转向量 罗德里格斯变换 转换为 旋转矩阵
Eigen::Matrix3d r;// 3×3矩阵
cv::cv2eigen(R, r);
// 将平移向量 和 旋转矩阵 转换 成 变换矩阵
Eigen::Isometry3d T = Eigen::Isometry3d::Identity();
Eigen::AngleAxisd angle(r);// 旋转矩阵
cout<<"translation"<<endl; // 平移向量============
Eigen::Translation<double,3> trans(result.tvec.at<double>(0,0),
result.tvec.at<double>(0,1),
result.tvec.at<double>(0,2));// 多余??????=========
T = angle;// 旋转矩阵 赋值 给 变换矩阵 T
T(0,3) = result.tvec.at<double>(0,0); // 添加 平移部分
T(1,3) = result.tvec.at<double>(0,1);
T(2,3) = result.tvec.at<double>(0,2);
// 转换点云
cout<<"converting image to clouds"<<endl;
PointCloud::Ptr cloud1 = image2PointCloud( frame1.rgb, frame1.depth, camera ); // 帧1 对应的 点云
PointCloud::Ptr cloud2 = image2PointCloud( frame2.rgb, frame2.depth, camera ); // 针2 对应的 点云
// 合并点云
cout<<"combining clouds"<<endl;
PointCloud::Ptr output (new PointCloud());
pcl::transformPointCloud( *cloud1, *output, T.matrix() );// F1下的 c1点云 T*c1 --> F2下
*output += *cloud2;// 在 F2下 加和 两部分 点云 ========
pcl::io::savePCDFile("data/result.pcd", *output);
cout<<"Final result saved."<<endl;
pcl::visualization::CloudViewer viewer( "viewer" );
viewer.showCloud( output );
while( !viewer.wasStopped() )
{
}
return 0;
}
// 至此,我们已经实现了一个只有两帧的SLAM程序。然而,也许你还不知道,这已经是一个视觉里程计(Visual Odometry)啦!
// 只要不断地把进来的数据与上一帧对比,就可以得到完整的运动轨迹以及地图了呢!
// 以两两匹配为基础的里程计有明显的累积误差,我们需要通过回环检测来消除它。这也是我们后面几讲的主要内容啦!
// 我们先讲讲关键帧的处理,因为把每个图像都放进地图,会导致地图规模增长地太快,所以需要关键帧技术。
// 然后呢,我们要做一个SLAM后端,就要用到g2o啦!视频流数据 RGB+Depth 400M+ 取自nyuv2数据集
http://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
这可是一个国际上认可的,相当有名的数据集哦。如果你想要跑自己的数据,当然也可以,不过需要你进行一些预处理啦。
实际上和滤波器很像,通过不断的两两匹配,估计机器人当前的位姿,过去的就给丢弃了。
这个思路比较简单,实际当中也比较有效,能够保证局部运动的正确性。
旋转向量 和平移向量 变换成 变换矩阵T 放入库
// src/slamBase.cpp
// cvMat2Eigen
// 旋转向量 rvec 和 平移向量 tvec 变换成 变换矩阵T===========================
Eigen::Isometry3d cvMat2Eigen( cv::Mat& rvec, cv::Mat& tvec )
{
cv::Mat R;
// 旋转向量 rvec 变成 旋转矩阵==========
cv::Rodrigues( rvec, R );
// cv 3×3矩阵 转换成 Eigen 3×3 矩阵====
Eigen::Matrix3d r;
for ( int i=0; i<3; i++ )
for ( int j=0; j<3; j++ )
r(i,j) = R.at<double>(i,j);// 8×8字节 double
// 将平移向量 和 旋转矩阵 转换成 变换矩阵 T
Eigen::Isometry3d T = Eigen::Isometry3d::Identity();// 单位阵
Eigen::AngleAxisd angle(r);// 旋转矩阵 >>> Eigen 旋转轴
T = angle;// 旋转轴 >>> 变换矩阵
T(0,3) = tvec.at<double>(0,0); // 附加上 平移向量
T(1,3) = tvec.at<double>(1,0);
T(2,3) = tvec.at<double>(2,0);
return T;
}
前后两帧点云合并
// joinPointCloud
// 输入:原始点云,新来的帧 以及 它的位姿
// 输出:将新来帧加到原始帧后的图像
PointCloud::Ptr joinPointCloud( PointCloud::Ptr original, // 原始点云
FRAME& newFrame, // 新来的帧
Eigen::Isometry3d T, // 它的位姿,相对 原始点云的位姿
CAMERA_INTRINSIC_PARAMETERS& camera ) // 相机参数
{
// 新来的帧 根据 RGB 和 深度图 产生 一帧点云 =======
PointCloud::Ptr newCloud = image2PointCloud( newFrame.rgb, newFrame.depth, camera );
// 合并点云
PointCloud::Ptr output (new PointCloud());
pcl::transformPointCloud( *original, *output, T.matrix() );// 怎么是前面的点云 变换到 当前帧 下
*newCloud += *output; // 当前帧 点云 和变换的点云 加和
// Voxel grid 滤波降采样
static pcl::VoxelGrid<PointT> voxel;// 静态变量 体素格下采样,只会有一个 变量实体======================
static ParameterReader pd; // 静态变量 文件参数读取器
double gridsize = atof( pd.getData("voxel_grid").c_str() );// 体素格精度
voxel.setLeafSize( gridsize, gridsize, gridsize );// 设置体素格子 大小
voxel.setInputCloud( newCloud );// 输入点云
PointCloud::Ptr tmp( new PointCloud() );// 临时点云
voxel.filter( *tmp );// 滤波输出点云
return tmp;
}
新添加的参数
# part 5
# 数据相关=================
# 图片序列 起始 与 终止索引
start_index=1
end_index=700
# 数据 所在目录 =========
rgb_dir=../data/rgb_png/
rgb_extension=.png
depth_dir=../data/depth_png/
depth_extension=.png
# 点云分辨率 ============
voxel_grid=0.02
# 是否实时可视化 是否显示点云
visualize_pointcloud=yes
# 最小匹配数量
min_good_match=10 最少特征匹配数量
# 最小内点 数量 pnp求解 返回的 匹配点数
min_inliers=5
# 最大运动量 , 运动量过大也可能是噪声=======
max_norm=0.3
最后,利用之前写好的工具函数,实现一个VO:
src/visualOdometry.cpp
/*************************************************************************
> File Name: rgbd-slam-tutorial-gx/part V/src/visualOdometry.cpp
> Author: xiang gao
> Mail: [email protected]
> Created Time: 2015年08月01日 星期六 15时35分42秒
************************************************************************/
#include <iostream>
#include <fstream>
#include <sstream>
using namespace std;
#include "slamBase.h"
// 给定index,读取一帧数据
FRAME readFrame( int index, ParameterReader& pd );
// 度量运动的大小
double normofTransform( cv::Mat rvec, cv::Mat tvec );
int main( int argc, char** argv )
{
// 数据集==================================================================
ParameterReader pd;
int startIndex = atoi( pd.getData( "start_index" ).c_str() );// 起始图片
int endIndex = atoi( pd.getData( "end_index" ).c_str() );// 终止图片
// 初始化 initialize
cout<<"Initializing ..."<<endl;
int currIndex = startIndex; // 当前 索引 为 currIndex
FRAME lastFrame = readFrame( currIndex, pd ); // 上一帧数据
// 我们总是在比较 currFrame 和 lastFrame
string detector = pd.getData( "detector" ); // 特征检测
string descriptor = pd.getData( "descriptor" ); // 特征描述
CAMERA_INTRINSIC_PARAMETERS camera = getDefaultCamera();// 相机参数
computeKeyPointsAndDesp( lastFrame, detector, descriptor );// 计算 特征点与描述子
PointCloud::Ptr cloud = image2PointCloud( lastFrame.rgb, lastFrame.depth, camera );// 最开始的点云
pcl::visualization::CloudViewer viewer("viewer");// 点云可视化器
// 是否显示点云
bool visualize = pd.getData("visualize_pointcloud")==string("yes");
int min_inliers = atoi( pd.getData("min_inliers").c_str() ); // pnp求解位姿 最少内点数量
double max_norm = atof( pd.getData("max_norm").c_str() ); // 平移 运动
for ( currIndex=startIndex+1; currIndex<endIndex; currIndex++ )// 便利数据集
{
cout<<"Reading files "<< currIndex << endl;
FRAME currFrame = readFrame( currIndex, pd ); // 读取 currFrame rgb+深度图
computeKeyPointsAndDesp( currFrame, detector, descriptor );// 计算特征点+描述子
// 比较currFrame 和 lastFrame
RESULT_OF_PNP result = estimateMotion( lastFrame, currFrame, camera );// PNP获取位姿
if ( result.inliers < min_inliers ) // inliers 不够(匹配效果差),放弃该帧
continue;
// 计算运动范围是否太大 因为假设运动是连贯的,两帧之间不会隔的太远
double norm = normofTransform(result.rvec, result.tvec);
cout<<"norm = "<<norm<<endl;
if ( norm >= max_norm )// 运动量过大也可能是噪声=======
continue;
Eigen::Isometry3d T = cvMat2Eigen( result.rvec, result.tvec );// 旋转、平移向量转换成 变换矩阵
cout<<"T="<<T.matrix()<<endl;
cloud = joinPointCloud( cloud, currFrame, T, camera ); // 点云放在一起
if ( visualize == true )
viewer.showCloud( cloud ); // 可视化点云
// 当点云出现时,可按5显示颜色,然后按r重置视角,快速查看点云=====================================
// 可以调节parameters.txt中的voxel_grid值来设置点云分辨率。0.01表示每1cm3的格子里有一个点。===
lastFrame = currFrame;// 迭代上一帧
}
pcl::io::savePCDFile( "data/result.pcd", *cloud );//保存点云
return 0;
}
// 诉它我要读第几帧的数据,它就会乖乖的把数据给找出来,返回一个FRAME结构体。
// 从数据集中读取一帧数据 RGB+深度============================
FRAME readFrame( int index, ParameterReader& pd )
{
FRAME f;
string rgbDir = pd.getData("rgb_dir");// 数据集路径
string depthDir = pd.getData("depth_dir");
string rgbExt = pd.getData("rgb_extension");// 图片格式====
string depthExt = pd.getData("depth_extension");
stringstream ss;
ss<<rgbDir<<index<<rgbExt;// 组合成 文件路径名
string filename;
ss>>filename;
f.rgb = cv::imread( filename );// 读取文件 RGB
ss.clear();
filename.clear();
ss<<depthDir<<index<<depthExt;
ss>>filename;
f.depth = cv::imread( filename, -1 );// 深度图
return f;
}
// 估计一个运动的大小 =====================================
double normofTransform( cv::Mat rvec, cv::Mat tvec )
{
// 旋转大小 0~2*pi + 平移大小=============
return fabs(min(cv::norm(rvec), 2*M_PI - cv::norm(rvec)))+ fabs(cv::norm(tvec));
}
这个里程计有什么不足呢? 1. 一旦出现了错误匹配,整个程序就会跑飞。 2. 误差会累积。常见的现象是:相机转过去的过程能够做对,但转回来之后则出现明显的偏差。 3. 效率方面不尽如人意。在线的点云显示比较费时。
姿态图(原理部分)
姿态图,顾名思义,就是由相机姿态构成的一个图(graph)。
这里的图,是从图论的意义上来说的。
一个图由 节点 vertex 与 边 edge 构成:
G={V,E}.
在最简单的情况下,节点代表相机的各个姿态(四元数形式或矩阵形式):
vi=[x,y,z,qx,qy,qz,qw]= Ti=[R3×3 t3×1
O1×3 1]i
而边指的是两个节点间的变换:
Ei,j = Ti,j = [R3×3 t3×1
O1×3 1]i,j.
利用 边可以将两个节点进行变换,由于计算误差,变换不可能完全一致,就会出现误差
我们就可以优化一个不一致性误差:
min C = ∑i,j∥v'i − Ti,j * v'j∥2 . 非线性平方误差函数
v’ 是上面 pnp求解出来的初始变量值,最开始 误差C有一个初始值,可以使用梯度下降法来优化变量
v'(t+1) = v'(t) - 学习率*导数*C(t) , t 表示优化迭代id。
https://github.com/Ewenwan/MVision/blob/master/vSLAM/ch6/g2o_curve_fitting/main.cpp
调整v的值使得E缩小。最后,如果这个问题收敛的话,v的 变化 就会越来越小,E也收敛到一个极小值。
根据迭代策略的不同,又可分为Gauss-Netwon(GN)下山法,
Levenberg-Marquardt(LM)方法等等。
这个问题也称为Bundle Adjustment(BA),
我们通常使用LM方法优化这个非线性平方误差函数。
为什么说slam里的BA问题稀疏呢?因为同样的场景很少出现在许多位置中。
这导致上面的pose graph中,图G离全图很远,只有少部分的节点存在直接边的联系。
这就是姿态图的稀疏性。
求解BA的软件包有很多,感兴趣的读者可以去看wiki: https://en.wikipedia.org/wiki/Bundle_adjustment。我
们这里介绍的g2o(Generalized Graph Optimizer),就是近年很流行的一个图优化求解软件包。
要使用g2o,首先你需要下载并安装它:https://github.com/RainerKuemmerle/g2o。
安装依赖项:
sudo apt-get install libeigen3-dev libsuitesparse-dev libqt4-dev qt4-qmake libqglviewer-qt4-dev
1404或1604的最后一项改为 libqglviewer-dev 即可。
解压g2o并编译安装:
进入g2o的代码目录,并:
mkdir build
cd build
cmake ..
make
sudo make install
多说两句,你可以安装cmake-curses-gui这个包,
通过gui来选择你想编译的g2o模块并设定cmake编译过程中的flags。
例如,当你实在装不好上面的libqglviewer时,你可以选择不编译g2o可视化模块(把G2O_BUILD_APPS关掉),
这样即使没有libqglviewer,你也能编译过g2o。
cd build
ccmake ..
make
sudo make install
安装成功后,你可以在/usr/local/include/g2o中找到它的头文件,而在/usr/local/lib中找到它的库文件。
使用g2o
安装完成后,我们把g2o引入自己的cmake工程:
# 添加g2o的依赖
# 因为g2o不是常用库,要添加它的findg2o.cmake文件
LIST( APPEND CMAKE_MODULE_PATH ${PROJECT_SOURCE_DIR}/cmake_modules )
SET( G2O_ROOT /usr/local/include/g2o )
FIND_PACKAGE( G2O )
# CSparse
FIND_PACKAGE( CSparse )
INCLUDE_DIRECTORIES( ${G2O_INCLUDE_DIR} ${CSPARSE_INCLUDE_DIR} )
同时,在代码根目录下新建cmake_modules文件夹,
把g2o代码目录下的cmake_modules里的东西都拷进来,
保证cmake能够顺利找到g2o。
// src/slamEnd.cpp===========================================================
/*************************************************************************
> File Name: rgbd-slam-tutorial-gx/part V/src/visualOdometry.cpp
> Author: xiang gao
> Mail: [email protected]
> Created Time: 2015年08月15日 星期六 15时35分42秒
* add g2o slam end to visual odometry
************************************************************************/
#include <iostream>
#include <fstream>
#include <sstream>
using namespace std;
#include "slamBase.h"
// G2O图优化===============================================
#include <g2o/types/slam3d/types_slam3d.h>//顶点类型
#include <g2o/core/sparse_optimizer.h> // 稀疏优化
#include <g2o/core/block_solver.h> // 矩阵分块
#include <g2o/core/factory.h>
#include <g2o/core/optimization_algorithm_factory.h>
#include <g2o/core/optimization_algorithm_gauss_newton.h>// GN 优化
#include <g2o/core/robust_kernel.h>// 核函数
#include <g2o/core/robust_kernel_factory.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
// 莱文贝格-马夸特方法(Levenberg–Marquardt algorithm)能提供数非线性最小化(局部最小)的数值解。
#include <g2o/solvers/eigen/linear_solver_eigen.h>
// 给定index,读取一帧数据
FRAME readFrame( int index, ParameterReader& pd );
// 估计一个运动的大小
double normofTransform( cv::Mat rvec, cv::Mat tvec );
int main( int argc, char** argv )
{
// 数据集==================================================================
// 前面部分和vo是一样的
ParameterReader pd;
int startIndex = atoi( pd.getData( "start_index" ).c_str() );
int endIndex = atoi( pd.getData( "end_index" ).c_str() );
// initialize 初始化=============================
cout<<"Initializing ..."<<endl;
int currIndex = startIndex; // 当前索引为currIndex
FRAME lastFrame = readFrame( currIndex, pd ); // 上一帧数据
// 我们总是在比较currFrame和lastFrame
string detector = pd.getData( "detector" );
string descriptor = pd.getData( "descriptor" );
CAMERA_INTRINSIC_PARAMETERS camera = getDefaultCamera();
computeKeyPointsAndDesp( lastFrame, detector, descriptor ); // 关键点和描述子
PointCloud::Ptr cloud = image2PointCloud( lastFrame.rgb, lastFrame.depth, camera );// 点云
pcl::visualization::CloudViewer viewer("viewer");
// 是否显示点云
bool visualize = pd.getData("visualize_pointcloud")==string("yes");
int min_inliers = atoi( pd.getData("min_inliers").c_str() );// pnp 匹配内点数量
double max_norm = atof( pd.getData("max_norm").c_str() ); // 最大运动 阈值
/*******************************
// 新增:有关g2o的初始化
*******************************/
// 选择优化方法
typedef g2o::BlockSolver_6_3 SlamBlockSolver; // 矩阵块求解器 优化变量 6维度
typedef g2o::LinearSolverEigen< SlamBlockSolver::PoseMatrixType > SlamLinearSolver;
// 类型选择 ==========================
// 由于我们是3D的slam,所以顶点取成了相机姿态:g2o::VertexSE3,
// 而边则是连接两个VertexSE3的边:g2o::EdgeSE3。 4×4的变换矩阵,
// 如果你想用别的类型的顶点(如2Dslam,路标点),你可以看看/usr/local/include/g2o/types/下的文件,
// 基本上涵盖了各种slam的应用,应该能满足你的需求。
// 初始化求解器
SlamLinearSolver* linearSolver = new SlamLinearSolver();
linearSolver->setBlockOrdering( false );
SlamBlockSolver* blockSolver = new SlamBlockSolver( linearSolver );
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg( blockSolver );
g2o::SparseOptimizer globalOptimizer; // 最后用的就是这个东东
globalOptimizer.setAlgorithm( solver );
// 不要输出调试信息
globalOptimizer.setVerbose( false );
// 向globalOptimizer增加第一个顶点====================================
g2o::VertexSE3* v = new g2o::VertexSE3();
v->setId( currIndex );
v->setEstimate( Eigen::Isometry3d::Identity() ); //估计为单位矩阵
v->setFixed( true ); // 第一个顶点固定,不用优化
globalOptimizer.addVertex( v );
int lastIndex = currIndex; // 上一帧的id
for ( currIndex=startIndex+1; currIndex<endIndex; currIndex++ )
{
cout<<"Reading files "<<currIndex<<endl;
FRAME currFrame = readFrame( currIndex,pd ); // 读取currFrame
computeKeyPointsAndDesp( currFrame, detector, descriptor );// 计算特征点和描述子
// 比较currFrame 和 lastFrame
RESULT_OF_PNP result = estimateMotion( lastFrame, currFrame, camera );// pnp估计位姿
if ( result.inliers < min_inliers ) //inliers不够,放弃该帧
continue;
// 计算运动范围是否太大
double norm = normofTransform(result.rvec, result.tvec);
cout<<"norm = "<<norm<<endl;
if ( norm >= max_norm )
continue;
Eigen::Isometry3d T = cvMat2Eigen( result.rvec, result.tvec );
cout<<"T="<<T.matrix()<<endl;
// 去掉可视化的话,会快一些
if ( visualize == true )
{
cloud = joinPointCloud( cloud, currFrame, T, camera );// 点晕加到一起
viewer.showCloud( cloud );
}
// 向g2o中增加这个顶点与上一帧顶点联系的边
// 顶点部分
// 顶点只需设定id即可
g2o::VertexSE3 *v = new g2o::VertexSE3();
v->setId( currIndex );
v->setEstimate( Eigen::Isometry3d::Identity() );// 定点 带估计=====
globalOptimizer.addVertex(v);
// 边部分
g2o::EdgeSE3* edge = new g2o::EdgeSE3();
// 连接此边的两个顶点id
edge->vertices() [0] = globalOptimizer.vertex( lastIndex );
edge->vertices() [1] = globalOptimizer.vertex( currIndex );
// 信息矩阵 6自由度变量 的 协方差矩阵的逆 为 6×6 矩阵====================================
Eigen::Matrix<double, 6, 6> information = Eigen::Matrix< double, 6,6 >::Identity();
// 信息矩阵是 协方差矩阵的逆,表示我们对边的精度的预先估计
// 因为pose为6D的,信息矩阵是6*6的阵,假设位置和角度的估计精度均为0.1且互相独立
// 那么协方差则为对角为0.01的矩阵,信息阵则为100的矩阵 倒数=================================
information(0,0) = information(1,1) = information(2,2) = 100;// 角度值 信息 误差权值
information(3,3) = information(4,4) = information(5,5) = 100;// 平移值 信息 误差权值
// 也可以将角度设大一些,表示对角度的估计更加准确
edge->setInformation( information );
// 边的估计即是pnp求解之结果 ======================
edge->setMeasurement( T );
// 将此边加入图中
globalOptimizer.addEdge(edge);
lastFrame = currFrame;
lastIndex = currIndex;
}
// 优化所有边
cout<<"optimizing pose graph, vertices: "<<globalOptimizer.vertices().size()<<endl;
globalOptimizer.save("./data/result_before.g2o");
globalOptimizer.initializeOptimization();
globalOptimizer.optimize( 100 ); //可以指定优化步数
globalOptimizer.save( "./data/result_after.g2o" );
cout<<"Optimization done."<<endl;
globalOptimizer.clear();
return 0;
// g2o的优化结果是存储在一个.g2o的文本文件里的,你可以用gedit等编辑软件打开它。
// 这个文件前面是顶点的定义,包含 ID, x,y,z,qx,qy,qz,qw。后边则是边的定义:ID1, ID2, dx, T 以及信息阵的上半角。
// 实际上,你也可以自己写个程序去生成这样一个文件,交给g2o去优化,写文本文件不会有啥困难的啦。
// 这个文件也可以用g2o_viewer打开,你还能直观地看到里面的节点与边的位置。
// 同时你可以选一个优化方法对该图进行优化,这样你可以直观地看到优化的过程哦。
}
FRAME readFrame( int index, ParameterReader& pd )
{
FRAME f;
string rgbDir = pd.getData("rgb_dir");
string depthDir = pd.getData("depth_dir");
string rgbExt = pd.getData("rgb_extension");
string depthExt = pd.getData("depth_extension");
stringstream ss;
ss<<rgbDir<<index<<rgbExt;
string filename;
ss>>filename;
f.rgb = cv::imread( filename ); // RGB
ss.clear();
filename.clear();
ss<<depthDir<<index<<depthExt;
ss>>filename;
f.depth = cv::imread( filename, -1 ); // 深度图
f.frameID = index;
return f;
}
// 估计一个运动的大小 =====================================
double normofTransform( cv::Mat rvec, cv::Mat tvec )
{
// 旋转大小 0~2*pi + 平移大小=============
return fabs(min(cv::norm(rvec), 2*M_PI-cv::norm(rvec)))+ fabs(cv::norm(tvec));
}
程序分析:
1. 关键帧的提取。
把每一帧都拼到地图是去是不明智的。
因为帧与帧之间距离很近,导致地图需要频繁更新,浪费时间与空间。
所以,我们希望,当机器人的运动超过一定间隔,就增加一个“关键帧”。
最后只需把关键帧拼到地图里就行了。
2. 回环的检测。
回环的本质是识别曾经到过的地方。
最简单的回环检测策略,就是把新来的关键帧与之前所有的关键帧进行比较,
不过这样会导致越往后,需要比较的帧越多。
所以,稍微快速一点的方法是在过去的帧里随机挑选一些,与之进行比较。
更进一步的,也可以用图像处理/模式识别的方法计算图像间的相似性,对相似的图像进行检测。
以下为伪码:
1. 初始化关键帧序列:F,并将第一帧f0放入F。
2. 对于新来的一帧I,计算 关键帧序列 F中最后一个关键帧帧 与 当前帧I 的 运动,并估计该运动的大小e。
有以下几种可能性:
a. 若e>Eerror,说明运动太大,可能是计算错误,丢弃该帧;
b. 若没有匹配上(match太少),说明该帧图像质量不高,丢弃;
c. 若e<Ekey,说明离前一个关键帧很近,虽然估计正确单同样丢弃;
d. 剩下的情况,只有是特征匹配成功,运动估计正确,同时又离上一个关键帧有一定距离,
则把当前帧I作为新的关键帧,进入回环检测程序。
3. 回环检测程序
A. 近距离回环。
匹配 当前帧 I 与 关键帧序列 F 末尾m个关键帧。
匹配成功时,在图里增加一条边,回环约束。
B. 随机回环。MC思想
随机在 关键帧序列 F里取n个帧,与I进行匹配。
若匹配上,同样在图里增加一条边。
4. 结尾处理
将 筛选出来的帧I 放入关键帧序列 F 的末尾。
若有新的数据,则回2;
若无,则进行优化与地图拼接。
在线跑的话呢,可以定时进行一次优化与拼图。
或者,在成功检测到回环时,同时检测这两个帧附近的帧,那样得到的边就更多啦。
再有呢,如果要做实用的程序,还要考虑机器人如何运动,如果跟丢了怎么进行恢复等一些实际的问题呢。
/*************************************************************************
> File Name: rgbd-slam-tutorial-gx/part V/src/visualOdometry.cpp
> Author: xiang gao
> Mail: [email protected]
> Created Time: 2015年08月15日 星期六 15时35分42秒
* add g2o slam end to visual odometry
* add keyframe and simple loop closure
************************************************************************/
#include <iostream>
#include <fstream>
#include <sstream>
using namespace std;
#include "slamBase.h"
// 点云可视化=================
#include <pcl/filters/voxel_grid.h>
#include <pcl/filters/passthrough.h>
// G2O图优化==================
#include <g2o/types/slam3d/types_slam3d.h>
#include <g2o/core/sparse_optimizer.h>
#include <g2o/core/block_solver.h>
#include <g2o/core/factory.h>
#include <g2o/core/optimization_algorithm_factory.h>
#include <g2o/core/optimization_algorithm_gauss_newton.h>
#include <g2o/solvers/eigen/linear_solver_eigen.h>
#include <g2o/core/robust_kernel.h>
#include <g2o/core/robust_kernel_impl.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
// 把g2o的定义放到前面===================================
typedef g2o::BlockSolver_6_3 SlamBlockSolver;
typedef g2o::LinearSolverEigen< SlamBlockSolver::PoseMatrixType > SlamLinearSolver;
// 给定index,读取一帧数据=====
FRAME readFrame( int index, ParameterReader& pd );
// 估计一个运动的大小=========
double normofTransform( cv::Mat rvec, cv::Mat tvec );
// 关键帧选取 ==============枚举变量
enum CHECK_RESULT {
NOT_MATCHED=0, // 两帧无匹配
TOO_FAR_AWAY, // 相隔太远
TOO_CLOSE, // 相隔太近
KEYFRAME}; // 相隔正好,可作为关键帧=====
// 和最近一个关键帧进行匹配,关键帧检测,适当时需要在g2o中键入 关键帧节点=======
// 函数声明==检查关键帧===
CHECK_RESULT checkKeyframes( FRAME& f1, FRAME& f2,
g2o::SparseOptimizer& opti,
bool is_loops=false );
// 检测近距离的回环=======
void checkNearbyLoops( vector<FRAME>& frames, FRAME& currFrame, g2o::SparseOptimizer& opti );
// 随机检测回环==========
void checkRandomLoops( vector<FRAME>& frames, FRAME& currFrame, g2o::SparseOptimizer& opti );
int main( int argc, char** argv )
{
// 前面部分和vo是一样的
ParameterReader pd;// 参数读取
int startIndex = atoi( pd.getData( "start_index" ).c_str() );
int endIndex = atoi( pd.getData( "end_index" ).c_str() );
// 所有的关键帧都放在了这里
vector< FRAME > keyframes;// 关键帧集合 , 这里关键帧 和普通帧 结构对象上无区别====
// initialize 初始化========================
cout<<"Initializing ..."<<endl;
int currIndex = startIndex; // 当前索引为currIndex
FRAME currFrame = readFrame( currIndex, pd ); // 上一帧数据
string detector = pd.getData( "detector" );
string descriptor = pd.getData( "descriptor" );
CAMERA_INTRINSIC_PARAMETERS camera = getDefaultCamera();
computeKeyPointsAndDesp( currFrame, detector, descriptor );
PointCloud::Ptr cloud = image2PointCloud( currFrame.rgb, currFrame.depth, camera );
/*******************************
// 新增:有关g2o的初始化
*******************************/
// 初始化求解器
SlamLinearSolver* linearSolver = new SlamLinearSolver();
linearSolver->setBlockOrdering( false );
SlamBlockSolver* blockSolver = new SlamBlockSolver( linearSolver );
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg( blockSolver );
g2o::SparseOptimizer globalOptimizer; // 最后用的就是这个东东
globalOptimizer.setAlgorithm( solver );
// 不要输出调试信息
globalOptimizer.setVerbose( false );
// 向globalOptimizer增加第一个顶点
g2o::VertexSE3* v = new g2o::VertexSE3();
v->setId( currIndex );
v->setEstimate( Eigen::Isometry3d::Identity() ); //估计为单位矩阵,世界坐标系
v->setFixed( true ); //第一个顶点固定,不用优化
globalOptimizer.addVertex( v );
keyframes.push_back( currFrame );// 第一帧就作为关键帧,其实可以根据关键点数量超过阈值,才作为地一个关键帧
double keyframe_threshold = atof( pd.getData("keyframe_threshold").c_str() );// 关键帧阈值,距离
bool check_loop_closure = pd.getData("check_loop_closure")==string("yes"); // 回环检测====
for ( currIndex=startIndex+1; currIndex<endIndex; currIndex++ )
{
cout<<"Reading files "<<currIndex<<endl;
FRAME currFrame = readFrame( currIndex,pd ); // 读取currFrame
computeKeyPointsAndDesp( currFrame, detector, descriptor ); //提取特征
// 和上一个关键帧进行匹配=============================================================
CHECK_RESULT result = checkKeyframes( keyframes.back(), currFrame, globalOptimizer );
//匹配该帧与keyframes里最后一帧
switch (result) // 根据匹配结果不同采取不同策略
{
case NOT_MATCHED:
//没匹配上,直接跳过=========
cout<<RED"Not enough inliers."<<endl;
break;
case TOO_FAR_AWAY:
// 太近了,也直接跳==========
cout<<RED"Too far away, may be an error."<<endl;
break;
case TOO_CLOSE:
// 太远了,可能出错了========
cout<<RESET"Too close, not a keyframe"<<endl;
break;
case KEYFRAME:// 可以作为关键帧=======================
cout<<GREEN"This is a new keyframe"<<endl;
// 不远不近,刚好==========
/**
* This is important!!
* This is important!!
* This is important!!
* (very important so I've said three times!)
*/
// 检测回环=======================
if (check_loop_closure)
{
checkNearbyLoops( keyframes, currFrame, globalOptimizer );// 近距离回环检测,需要修改G2O优化结构
checkRandomLoops( keyframes, currFrame, globalOptimizer );// 随机回环检测
}
keyframes.push_back( currFrame ); // 加入到关键帧=============
break;
default:
break;
}
}
// 离线 优化 ==============================================================================
cout<<RESET"optimizing pose graph, vertices: "<<globalOptimizer.vertices().size()<<endl;
globalOptimizer.save("./result_before.g2o");
globalOptimizer.initializeOptimization();
globalOptimizer.optimize( 100 ); //可以指定优化步数
globalOptimizer.save( "./result_after.g2o" );
cout<<"Optimization done."<<endl;
// 拼接点云地图
cout<<"saving the point cloud map..."<<endl;
PointCloud::Ptr output ( new PointCloud() ); //全局地图
PointCloud::Ptr tmp ( new PointCloud() );
pcl::VoxelGrid<PointT> voxel; // 网格滤波器,调整地图分辨率
pcl::PassThrough<PointT> pass; // z方向区间滤波器,由于rgbd相机的有效深度区间有限,把太远的去掉
pass.setFilterFieldName("z");
pass.setFilterLimits( 0.0, 4.0 ); //4m以上就不要了 保留相机前方 0~4m范围
double gridsize = atof( pd.getData( "voxel_grid" ).c_str() ); //分辨图可以在parameters.txt里调
voxel.setLeafSize( gridsize, gridsize, gridsize );// 体素格滤波======
for (size_t i=0; i<keyframes.size(); i++)
{
// 从g2o里取出一帧
g2o::VertexSE3* vertex = dynamic_cast<g2o::VertexSE3*>(globalOptimizer.vertex( keyframes[i].frameID ));
Eigen::Isometry3d pose = vertex->estimate(); // 该帧优化后的位姿
PointCloud::Ptr newCloud = image2PointCloud( keyframes[i].rgb, keyframes[i].depth, camera ); //转成点云
// 以下是滤波
voxel.setInputCloud( newCloud );
voxel.filter( *tmp );
pass.setInputCloud( tmp );
pass.filter( *newCloud );
// 之前的工程是 将之前的点晕转换到 当前点云下 =================
// 不过这里 pose.matrix() 在 checkKeyframes 加入的是 PNP 估计出来的逆矩阵
// 原来是 f1 ---> f2
// 逆矩阵 之后是 f2 ----> f1
// 把 点云 变换 后 加入全局地图中 当前点云
pcl::transformPointCloud( *newCloud, *tmp, pose.matrix() );
*output += *tmp;
tmp->clear(); // 滤波点云清空
newCloud->clear();// 新点云清空
}
voxel.setInputCloud( output );
voxel.filter( *tmp ); // 最后整体滤波==================
//存储
pcl::io::savePCDFile( "./result.pcd", *tmp );
cout<<"Final map is saved."<<endl;
return 0;
}
// 从数据集中读取一帧==========
FRAME readFrame( int index, ParameterReader& pd )
{
FRAME f;
string rgbDir = pd.getData("rgb_dir");
string depthDir = pd.getData("depth_dir");
string rgbExt = pd.getData("rgb_extension");
string depthExt = pd.getData("depth_extension");
stringstream ss;
ss<<rgbDir<<index<<rgbExt;
string filename;
ss>>filename;
f.rgb = cv::imread( filename );
ss.clear();
filename.clear();
ss<<depthDir<<index<<depthExt;
ss>>filename;
f.depth = cv::imread( filename, -1 );
f.frameID = index;
return f;
}
// 运动量大小===========
double normofTransform( cv::Mat rvec, cv::Mat tvec )
{
return fabs(min(cv::norm(rvec), 2*M_PI-cv::norm(rvec)))+ fabs(cv::norm(tvec));
}
// 和最近一个关键帧进行匹配,关键帧检测,适当时需要在g2o中键入 关键帧节点=======
CHECK_RESULT checkKeyframes( FRAME& f1, FRAME& f2, g2o::SparseOptimizer& opti, bool is_loops)
{
static ParameterReader pd;
static int min_inliers = atoi( pd.getData("min_inliers").c_str() ); // pnp 内点数量
static double max_norm = atof( pd.getData("max_norm").c_str() ); // 运动量太大 阈值
static double keyframe_threshold = atof( pd.getData("keyframe_threshold").c_str() );// 关键帧 运动量阈值,小于就太小
static double max_norm_lp = atof( pd.getData("max_norm_lp").c_str() ); // 运动距离
static CAMERA_INTRINSIC_PARAMETERS camera = getDefaultCamera(); // 相机参数======
// 比较f1 和 f2
RESULT_OF_PNP result = estimateMotion( f1, f2, camera );// pnp 估计帧间运动
if ( result.inliers < min_inliers ) //inliers不够,放弃该帧
return NOT_MATCHED; // 未匹配上
// 计算运动范围是否太大
double norm = normofTransform(result.rvec, result.tvec);// 计算运动量
if ( is_loops == false )
{
if ( norm >= max_norm ) // 运动量过大阈值
return TOO_FAR_AWAY; // too far away, may be error
}
else
{
if ( norm >= max_norm_lp) // 运动量过大阈值
return TOO_FAR_AWAY;
}
if ( norm <= keyframe_threshold )
return TOO_CLOSE; // too adjacent frame
// 剩下的就是运动量杠杆好===========================
// 向g2o中增加这个顶点与上一帧联系的边
// 顶点部分
// 顶点只需设定id即可
if (is_loops == false)
{
g2o::VertexSE3 *v = new g2o::VertexSE3();
v->setId( f2.frameID );
v->setEstimate( Eigen::Isometry3d::Identity() );
opti.addVertex(v);
}
// 边部分
g2o::EdgeSE3* edge = new g2o::EdgeSE3();
// 连接此边的两个顶点id
edge->setVertex( 0, opti.vertex(f1.frameID ));
edge->setVertex( 1, opti.vertex(f2.frameID ));
edge->setRobustKernel( new g2o::RobustKernelHuber() );//
// 回环检测是很怕"false positive"的,即“将实际上不同的地方当成了同一处”,这会导致地图出现明显的不一致。
// 所以,在使用g2o时,要在边里添加"robust kernel",保证一两个错误的边不会影响整体结果。
// 信息矩阵
Eigen::Matrix<double, 6, 6> information = Eigen::Matrix< double, 6,6 >::Identity();
// 信息矩阵是协方差矩阵的逆,表示我们对边的精度的预先估计
// 因为pose为6D的,信息矩阵是6*6的阵,假设位置和角度的估计精度均为0.1且互相独立
// 那么协方差则为对角为0.01的矩阵,信息阵则为100的矩阵
information(0,0) = information(1,1) = information(2,2) = 100; // 角度信息
information(3,3) = information(4,4) = information(5,5) = 100; // 平移量信息
// 也可以将角度设大一些,表示对角度的估计更加准确
edge->setInformation( information );
// 边的估计即是pnp求解之结果
Eigen::Isometry3d T = cvMat2Eigen( result.rvec, result.tvec );
// edge->setMeasurement( T );
edge->setMeasurement( T.inverse() ); // 相反的 ,就是 f2---> f1
// 将此边加入图中
opti.addEdge(edge);
return KEYFRAME;
}
// 局部回环检测==========
void checkNearbyLoops( vector<FRAME>& frames, FRAME& currFrame, g2o::SparseOptimizer& opti )
{
static ParameterReader pd;
static int nearby_loops = atoi( pd.getData("nearby_loops").c_str() );
// 就是把currFrame和 frames里末尾几个测一遍
if ( frames.size() <= nearby_loops )
{
// no enough keyframes, check everyone
for (size_t i=0; i<frames.size(); i++)
{
checkKeyframes( frames[i], currFrame, opti, true );
}
}
else
{
// check the nearest ones
for (size_t i = frames.size()-nearby_loops; i<frames.size(); i++)
{
checkKeyframes( frames[i], currFrame, opti, true );
}
}
}
// 随机回环检测,得到全局回环=============
void checkRandomLoops( vector<FRAME>& frames, FRAME& currFrame, g2o::SparseOptimizer& opti )
{
static ParameterReader pd;
static int random_loops = atoi( pd.getData("random_loops").c_str() );
srand( (unsigned int) time(NULL) );
// 随机取一些帧进行检测
if ( frames.size() <= random_loops )
{
// no enough keyframes, check everyone
for (size_t i=0; i<frames.size(); i++)
{
checkKeyframes( frames[i], currFrame, opti, true );
}
}
else
{
// randomly check loops
for (int i=0; i<random_loops; i++)
{
int index = rand()%frames.size();
checkKeyframes( frames[index], currFrame, opti, true );
}
}
}
会换检测效果

咖啡台左侧有明显的人通过的痕迹,导致地图上出现了他的身影(帅哥你好拉风):
包括:
更好的数学模型(新的滤波器/图优化理论);
新的视觉特征/不使用特征的直接方法;
动态物体/人的处理;
地图描述/点云地图优化/语义地图
长时间/大规模/自动化slam
Q:用PCL的cloudviewer把点云显示出来,为什么会是上下颠倒?
小萝卜2号:关于图像上下翻转问题,是因为opencv定义的坐标系和pcl_viewer显示坐标系不同,opencv是x右y下,而pcl显示是x右y上。
解决方法:找到群主程序image2PointCloud函数中,把计算点空间坐标的公式的p.y值添加负号,
这样y方向就可以正常显示了,so easy。(或许还有别的方法)
Octomap采用八叉树数据结构存储三维环境的概率占据地图。
RGBD SLAM的目的有两个:估计机器人的轨迹,并建立正确的地图。地图有很多种表达方式,
比如特征点地图、网格地图、拓扑地图等等。
我们使用的地图形式主要是点云地图。在程序中,我们根据优化后的位姿,拼接点云,最后构成地图。
这种做法很简单,但有一些明显的缺陷:
1. 地图形式不紧凑。
点云地图通常规模很大,一张640×480的图像,会产生30万个空间点,即使经过一些滤波之后,pcd文件也是很大的。
点云地图提供了很多不必要的细节。对于地毯上的褶皱、阴暗处的影子,我们并不特别关心这些东西。
把它们放在地图里是浪费空间。
2. 处理重叠的方式不够好。
在构建点云时,我们直接按照估计位姿拼在了一起。在
位姿存在误差时,会导致地图出现明显的重叠。
例如一个电脑屏变成了两个,原本方的边界变成了多边形。
对重叠地区的处理方式应该更好一些
3. 难以用于导航
说起地图的用处,第一就是导航啦!有了地图,就可以指挥机器人从A点到B点运动,岂不是很方便的事? 但是,给你一张点云地图,是否有些傻眼了呢?我至少得知道哪些地方可通过, 哪些地方不可通过,才能完成导航呀!光有点是不够的!
octomap就是为此而设计的!亲,你没有看错,它可以优雅地压缩、更新地图,并且分辨率可调!
它以八叉树(octotree,后面会讲)的形式存储地图,相比点云,能够省下大把的空间。
octomap建立的地图大概是这样子的:(从左到右是不同的分辨率)

由于八叉树的原因,它的地图像是很多个小方块组成的(很像minecraft)。
当分辨率较高时,方块很小;分辨率较低时,方块很大。每个方块表示该格被占据的概率。
因此你可以查询某个方块或点“是否可以通过”,从而实现不同层次的导航。
简而言之,环境较大时采用较低分辨率,而较精细的导航可采用较高分辨率.
1. 八叉树
有八个子节点的树!是不是很厉害呢?至于为什么要分成八个子节点,
想象一下一个正方形的方块的三个面各切一刀,不就变成八块了嘛!
如果你想象不出来,请看下图: 切一刀->2块--> 再切一刀->4块-->再切一刀->8块 8卦

实际的数据结构呢,就是一个树根不断地往下扩,每次分成八个枝,直到叶子为止。
叶子节点代表了分辨率最高的情况。例如分辨率设成0.01m,那么每个叶子就是一个1cm见方的小方块了呢!
每个小方块都有一个数描述它是否被占据。在最简单的情况下,可以用0-1两个数表示(太简单了所以没什么用)。
通常还是用0~1之间的浮点数表示它被占据的概率。0.5表示未确定,越大则表示被占据的可能性越高,反之亦然。
由于它是八叉树,那么一个节点的八个孩子都有一定的概率被占据或不被占据啦!(下图是一棵八叉树)。
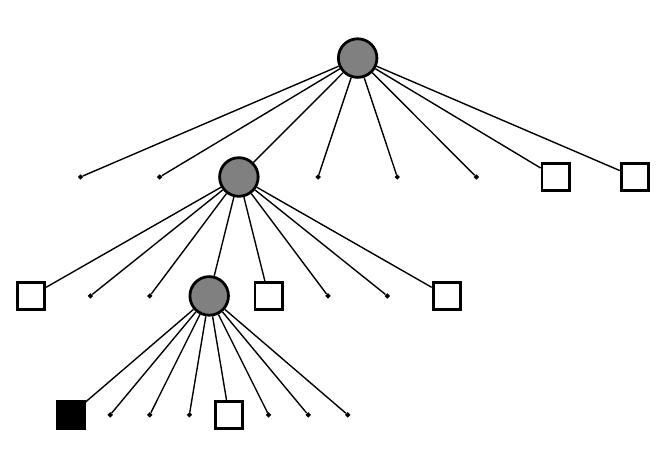
用树结构的好处时:当某个节点的子结点都“占据”或“不占据”或“未确定”时,就可以把它给剪掉!
换句话说,如果没必要进一步描述更精细的结构(孩子节点)时,我们只要一个粗方块(父节点)的信息就够了。
这可以省去很多的存储空间。因为我们不用存一个“全八叉树”呀!
2. 八叉树的更新
在八叉树中,我们用概率来表达一个叶子是否被占据。为什么不直接用0-1表达呢?
因为在对环境的观测过程中,由于噪声的存在,某个方块有时可能被观测到是“占据”的,
过了一会儿,在另一些方块中又是“不占据”的。有时“占据”的时候多,有时“不占据”的时候多。
这一方面可能是由于环境本身有动态特征(例如桌子被挪走了),另一方面(多数时候)可能是由于噪声。
根据八叉树的推导,假设t=1,…,T时刻,观测的数据为z1,…,zT,那么第n个叶子节点记录的信息为:
p(n|z1:zT) = [ 1+ (1-p(n|zT))/p(n|ZT) * (1-p(n|z1:zT-1))/p(n|z1:zT-1) * p(n)/(1-p(n)) ]^(-1)
logit 变换 把 0~1概率 映射到 全实数R空间 -无穷大 ~ +无穷大
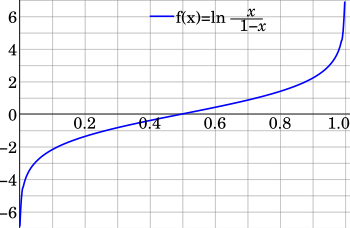
p = 0~1 上图中的x
a = logit(p) = log(p/(1-p)) 范围为 -无穷大 ~ +无穷大
反过来可以得到
exp(a) = p/(1-p) ===>
exp(a) = p(1+exp(a)) ====>
p = exp(a)/(1+exp(a)) = 1/(1+exp(-a)) // sigmod(a) 神经网络激活函数
-无穷大 ~ +无穷大 映射为 0~1
我们对 p() 取logit 变换得到
L(P) = L(n|z1:zT) = L(n|z1:zT-1) + L(n|zT) 每一次的logit变换值 只是前面观测的 + 当前次概率的logit值
然后我们再对 logit值 求反变换 得到其概率值p!!!!!!!!!!!!!方便计算=========================
每新来一个就直接加到原来的上面
此外还要加一个最大最小值的限制。最后转换回原来的概率即可。
八叉树中的父亲节点占据概率,可以根据孩子节点的数值进行计算。比较简单的是取平均值或最大值。
如果把八叉树按照占据概率进行渲染,不确定的方块渲染成透明的,
确定占据的渲染成不透明的,就能看到我们平时见到的那种东西啦!
octomap本身的数学原理还是简单的。不过它的可视化做的比较好。
下载
https://github.com/Ewenwan/octomap
api 文档
http://octomap.github.io/octomap/doc/
安装
mkdir build
cd build
cmake ..
make
事实上,octomap的代码主要含两个模块:本身的octomap和可视化工具octovis。
octovis依赖于qt4和qglviewer,所以如果你没有装这两个依赖,
请安装它们:sudo apt-get install libqt4-dev qt4-qmake libqglviewer-dev
如果编译没有给出任何警告,恭喜你编译成功!
使用octovis查看示例地图
在bin/文件夹中,存放着编译出来可执行文件。为了直观起见,我们直接看一个示例地图:
bin/octovis octomap/share/data/geb079.bt
octovis会打开这个地图并显示。它的UI是长这样的。你可以玩玩菜单里各种东西(虽然也不多,我就不一一介绍UI怎么玩了),
能看出这是一层楼的扫描图。octovis是一个比较实用的工具,你生成的各种octomap地图都可以用它来看。
(所以你可以把octovis放到/usr/local/bin/下,省得以后还要找。)
/*************************************************************************
> File Name: src/pcd2octomap.cpp
> Author: Gao Xiang
> Mail: [email protected]
> Created Time: 2015年12月12日 星期六 15时51分45秒
将命令行参数1作为输入文件,参数2作为输出文件,把输入的pcd格式点云转换成octomap格式的点云。
通过这个例子,你可以学会如何创建一个简单的OcTree对象并往里面添加新的点。
调用: bin/pcd2octomap data/sample.pcd data/sample.bt
这个octomap里只存储了点的空间信息,而没有颜色信息。
我按照高度给它染色了,否则它应该就是灰色的。
通过octomap,我们能查看每个小方块是否可以通行,从而实现导航的工作。
octomap存储的文件后缀名是.bt(二进制文件)和.ot(普通文件),前者相对更小一些。
不过octomap文件普遍都很小,所以也不差这么些容量。
如果你存成了其他后缀名,octovis可能认不出来。
************************************************************************/
#include <iostream>
#include <assert.h>
// pcl==========
#include <pcl/io/pcd_io.h>
#include <pcl/point_types.h>
// octomap =====
#include <octomap/octomap.h>
// 命名空间======
using namespace std;
int main( int argc, char** argv )
{
if (argc != 3)
{
cout<<"Usage: pcd2octomap <input_file> <output_file>"<<endl;
return -1;
}
string input_file = argv[1], output_file = argv[2];
pcl::PointCloud<pcl::PointXYZRGBA> cloud;
pcl::io::loadPCDFile<pcl::PointXYZRGBA> ( input_file, cloud );// 载入点云
cout<<"point cloud loaded, piont size = "<<cloud.points.size()<<endl;
//声明octomap变量
cout<<"copy data into octomap..."<<endl;
// 创建八叉树对象,参数为分辨率,这里设成了0.05=========
octomap::OcTree tree( 0.05 ); // ColorOcTree 可存储颜色信息
for (auto p:cloud.points)// 每一个点云中的点 范围for c++11标准
{
// 将点云里的点插入到octomap中
tree.updateNode( octomap::point3d(p.x, p.y, p.z), true );// xyz类型
}
// 更新octomap==================
tree.updateInnerOccupancy();
// 存储octomap==================
tree.writeBinary( output_file );
cout<<"done."<<endl;
return 0;
}
cmakelists
# 增加PCL库的依赖
FIND_PACKAGE( PCL REQUIRED COMPONENTS common io )
# SET设置变量 支持C++11 -O2 优化等级
SET(CMAKE_C_FLAGS "${CMAK_C_FLAGS} -g -Wall -O2 -std=c11")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -Wall -O2 -std=c++11")
# 支持C++14, when gcc version > 5.1, use -std=c++14 instead of c++1y
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -Wall -O2 -std=c++1y")
# 添加头文件和库文件
ADD_DEFINITIONS( ${PCL_DEFINITIONS} )
INCLUDE_DIRECTORIES( ${PCL_INCLUDE_DIRS} )
LINK_LIBRARIES( ${PCL_LIBRARY_DIRS} )
# octomap
FIND_PACKAGE( octomap REQUIRED )
INCLUDE_DIRECTORIES( ${OCTOMAP_INCLUDE_DIRS} )
ADD_EXECUTABLE( pcd2octomap pcd2octomap.cpp )
TARGET_LINK_LIBRARIES( pcd2octomap
${PCL_LIBRARIES}
${OCTOMAP_LIBRARIES})
ADD_EXECUTABLE( pcd2colorOctomap pcd2colorOctomap.cpp )
TARGET_LINK_LIBRARIES( pcd2colorOctomap
${PCL_LIBRARIES}
${OCTOMAP_LIBRARIES})
FIND_PACKAGE(OpenCV REQUIRED)
ADD_EXECUTABLE( joinmap joinMap.cpp )
TARGET_LINK_LIBRARIES( joinmap
${OCTOMAP_LIBRARIES}
${OpenCV_LIBS})
// octomap提供了 ColorOcTree 类,能够帮你存储颜色信息。下面我们就来做一个保存颜色信息的示例。
// 代码见:src/pcd2colorOctomap.cpp
/*************************************************************************
> File Name: src/pcd2colorOctomap.cpp
> Author: Gao Xiang
> Mail: [email protected]
> Created Time: 2015年12月12日 星期六 15时51分45秒
调用
bin/pcd2colorOctomap data/sample.pcd data/sample.ot
这段代码会编译出pcd2colorOctomap这个程序,完成带颜色的转换。不过,后缀名改成了.ot文件。
颜色信息能够更好地帮助我们辨认结果是否正确,给予一个直观的印象。
************************************************************************/
#include <iostream>
#include <assert.h>
//pcl=======================
#include <pcl/io/pcd_io.h>
#include <pcl/point_types.h>
//octomap =================
#include <octomap/octomap.h>
#include <octomap/ColorOcTree.h>
using namespace std;
int main( int argc, char** argv )
{
if (argc != 3)
{
cout<<"Usage: pcd2colorOctomap <input_file> <output_file>"<<endl;
return -1;
}
string input_file = argv[1], output_file = argv[2];
pcl::PointCloud<pcl::PointXYZRGBA> cloud;
pcl::io::loadPCDFile<pcl::PointXYZRGBA> ( input_file, cloud ); // 载入pcl点云
cout<<"point cloud loaded, piont size = "<<cloud.points.size()<<endl;
//声明octomap变量
cout<<"copy data into octomap..."<<endl;
// 创建带颜色的八叉树对象,参数为分辨率,这里设成了0.05
octomap::ColorOcTree tree( 0.05 );// ColorOcTree 带颜色 octomap
for (auto p:cloud.points)
{
// 将点云里的点插入到octomap中
tree.updateNode( octomap::point3d(p.x, p.y, p.z), true );//插入点
}
// 设置颜色
for (auto p:cloud.points)
{
tree.integrateNodeColor( p.x, p.y, p.z, p.r, p.g, p.b );// 设置颜色
}
// 更新octomap===================
tree.updateInnerOccupancy();
// 存储octomap, 注意要存成.ot文件而非.bt文件===!!!!!!!!!
tree.write( output_file );
cout<<"done."<<endl;
return 0;
}
前两个例程中,我们都是对单个pcd文件进行了处理。实际做slam时,我们需要拼接很多帧的octomap。
为了做这样一个示例,我从自己的实验数据中取出了一小段。
这一小段总共含有五张图像(因为github并不适合传大量数据),它们存放在data/rgb_index和data/dep_index下。
我的slam程序估计了这五个关键帧的位置,放在data/trajectory.txt中。
它的格式是:帧编号 x y z qx qy qz qw (位置+姿态四元数)。
事实上它是从一个g2o文件中拷出来的。
你可以用g2o_viewer data/result_after.g2o来看整个轨迹。
/*************************************************************************
> File Name: src/joinMap.cpp
> Author: Gao Xiang
> Mail: [email protected]
> Created Time: 2015年12月13日 星期日 14时37分05秒
************************************************************************/
#include <iostream>
#include <vector>
// octomap ================
#include <octomap/octomap.h>
#include <octomap/ColorOcTree.h>
#include <octomap/math/Pose6D.h>
// opencv 用于图像数据读取与处理===========
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
// 使用Eigen的Geometry模块处理3d运动======
#include <Eigen/Core>
#include <Eigen/Geometry>
// pcl============================
#include <pcl/common/transforms.h>
#include <pcl/point_types.h>
// boost.format 字符串处理
#include <boost/format.hpp>
using namespace std;
// 全局变量:相机矩阵
// 更好的写法是存到参数文件中,但为方便起见我就直接这样做了
float camera_scale = 1000;
float camera_cx = 325.5;
float camera_cy = 253.5;
float camera_fx = 518.0;
float camera_fy = 519.0;
int main( int argc, char** argv )
{
// 读关键帧编号=====================================
ifstream fin( "./data/keyframe.txt" );
vector<int> keyframes;
vector< Eigen::Isometry3d > poses;
// 把文件 ./data/keyframe.txt 里的数据读取到vector中
while( fin.peek() != EOF )
{
int index_keyframe;
fin>>index_keyframe;
if (fin.fail()) break;
keyframes.push_back( index_keyframe );
}
fin.close();
cout<<"load total "<<keyframes.size()<<" keyframes. "<<endl;
// 读关键帧姿态======================================
// 我的代码中使用了Eigen来存储姿态,类似的,也可以用octomath::Pose6D来做这件事
fin.open( "./data/trajectory.txt" );
while( fin.peek() != EOF )
{
int index_keyframe;
float data[7]; // 三个位置加一个 姿态四元数 x,y,z, w,ux,uy,uz
fin>>index_keyframe;
for ( int i=0; i<7; i++ )
{
fin>>data[i];
cout<<data[i]<<" ";
}
cout<<endl;
if (fin.fail()) break;
// 注意这里的顺序。g2o文件四元数按 qx, qy, qz, qw来存==================
// 但Eigen初始化按照qw, qx, qy, qz来做==============
Eigen::Quaterniond q( data[6], data[3], data[4], data[5] );// 姿态四元数
Eigen::Isometry3d T(q);// 用 姿态四元数 初始化 变换矩阵T
T(0,3) = data[0]; T(1,3) = data[1]; T(2,3) = data[2];
poses.push_back( T );
}
fin.close();
// 拼合全局地图
octomap::ColorOcTree tree( 0.05 ); //全局map 带颜色
// 注意我们的做法是 先把图像 转换至 pcl的点云,进行姿态变换,最后存储成octomap
// 因为octomap的 颜色信息 不是特别方便处理,所以采用了这种迂回的方式
// 所以,如果不考虑颜色,那不必转成pcl点云,而可以直接使用 octomap::Pointcloud 结构
for ( size_t i=0; i<keyframes.size(); i++ )
{
pcl::PointCloud<pcl::PointXYZRGBA> cloud;
cout<<"converting "<<i<<"th keyframe ..." <<endl;
int k = keyframes[i];
Eigen::Isometry3d& pose = poses[i]; // 每一帧的 位姿
// 生成第k帧的点云,拼接至全局octomap上
boost::format fmt ("./data/rgb_index/%d.ppm" );
cv::Mat rgb = cv::imread( (fmt % k).str().c_str() );
fmt = boost::format("./data/dep_index/%d.pgm" );
cv::Mat depth = cv::imread( (fmt % k).str().c_str(), -1 );
// 从rgb, depth生成点云,运算方法见《一起做》第二讲
// 第一次遍历用于生成空间点云 pcl==============================
for ( int m=0; m<depth.rows; m++ )
for ( int n=0; n<depth.cols; n++ )
{
ushort d = depth.ptr<ushort> (m) [n];// 深度值
if (d == 0)
continue;
float z = float(d) / camera_scale;
float x = (n - camera_cx) * z / camera_fx;
float y = (m - camera_cy) * z / camera_fy;
pcl::PointXYZRGBA p;
p.x = x; p.y = y; p.z = z;
uchar* rgbdata = &rgb.ptr<uchar>(m)[n*3];
uchar b = rgbdata[0];
uchar g = rgbdata[1];
uchar r = rgbdata[2];
p.r = r; p.g = g; p.b = b;
cloud.points.push_back( p );
}
// 将cloud旋转之后插入全局地图
pcl::PointCloud<pcl::PointXYZRGBA>::Ptr temp( new pcl::PointCloud<pcl::PointXYZRGBA>() );
pcl::transformPointCloud( cloud, *temp, pose.matrix() ); // 转换到当前枕坐标系下
octomap::Pointcloud cloud_octo; // 当前帧octo点云==========================
for (auto p:temp->points) // 遍例每一个 pcl点云
cloud_octo.push_back( p.x, p.y, p.z );
// 总octo点云 中插入 octo 点云============================
// insertPointCloud会比单纯的插入点更好一些。octomap里的pointcloud是一种射线的形式,
// 只有末端才存在被占据的点,中途的点则是没被占据的。这会使一些重叠地方处理的更好。
tree.insertPointCloud( cloud_octo,
octomap::point3d( pose(0,3), pose(1,3), pose(2,3) ) );//按当前帧的位置 插入
for (auto p:temp->points)
tree.integrateNodeColor( p.x, p.y, p.z, p.r, p.g, p.b );//加入颜色
}
tree.updateInnerOccupancy();// 更新
tree.write( "./data/map.ot" );// 保存
cout<<"done."<<endl;
return 0;
}