We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
There was an error while loading. Please reload this page.
1 parent 1b2e073 commit a0cf998Copy full SHA for a0cf998
第三章/爬取网页.md
@@ -0,0 +1,17 @@
1
+##爬取网页
2
+
3
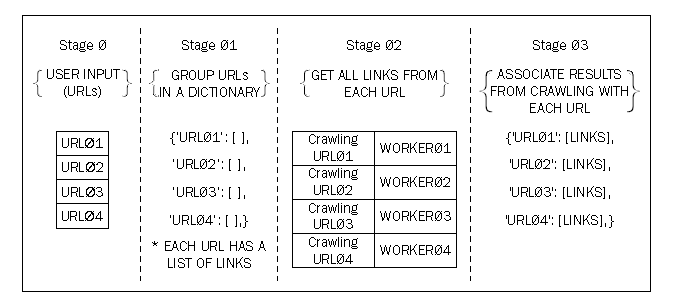
+贯穿本书的另一个正在研究的问题是是实现一个并行的网络爬虫。一个网络爬虫由一个浏览网页并从页面获取信息的电脑程序组成。被分析的场景是一个问题,在这个问题中,一个连续的网络爬虫是由一个可变数量的统一资源定位器(URLs),并且它要检索每个URL所提供的所有链接。想象到输入的URLs的数量相当的大,我们可以在以下方法中寻找并行性的解决方案:
4
5
+1. 在数据结构中,把所有的URLs分成组。
6
+2. 把数据URLs和任务关联起来,这样将会通过从每个URL获得信息来爬取网页。
7
+3. 以并行的workers来执行任务。
8
+4. 由于前一阶段的结果必须传给下一个阶段,这将会改进未加工的存储的数据,因此保存它们关联它们到原始的URLs。
9
10
+正如我们可以在有限的步骤中观察到为了一个提出的解决方案,可以与以下两个方法结合:
11
12
+* 数据分解:这发生在我们划分和关联URLs到任务上。
13
+* 用管道进行任务分解:这包含三个阶段的管道,这发生在我们链接接收、存储以及组织爬取的结果的任务。
14
15
+下图显示了解决方案:
16
17
+
0 commit comments