diff --git a/README.md b/README.md
index 93e3358f024a..294f4cc6edc0 100644
--- a/README.md
+++ b/README.md
@@ -388,7 +388,8 @@ Current number of checkpoints: ** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
diff --git a/README_es.md b/README_es.md
index d4585a2b9559..4e262ab440a8 100644
--- a/README_es.md
+++ b/README_es.md
@@ -388,7 +388,8 @@ Número actual de puntos de control: ** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
diff --git a/README_hd.md b/README_hd.md
index d91e02d6bdd3..9102503b65a1 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -361,7 +361,8 @@ conda install -c huggingface transformers
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (बर्कले से) कागज के साथ [SqueezeBERT: कुशल तंत्रिका नेटवर्क के बारे में NLP को कंप्यूटर विज़न क्या सिखा सकता है?](https: //arxiv.org/abs/2006.11316) फॉरेस्ट एन. इनडोला, अल्बर्ट ई. शॉ, रवि कृष्णा, और कर्ट डब्ल्यू. केटज़र द्वारा।
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (माइक्रोसॉफ्ट से) साथ में कागज [स्वाइन ट्रांसफॉर्मर: शिफ्टेड विंडोज का उपयोग कर पदानुक्रमित विजन ट्रांसफॉर्मर](https://arxiv .org/abs/2103.14030) ज़ी लियू, युटोंग लिन, यू काओ, हान हू, यिक्सुआन वेई, झेंग झांग, स्टीफन लिन, बैनिंग गुओ द्वारा।
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft से) साथ वाला पेपर [Swin Transformer V2: स्केलिंग अप कैपेसिटी एंड रेजोल्यूशन](https:// ज़ी लियू, हान हू, युटोंग लिन, ज़ुलिआंग याओ, ज़ेंडा ज़ी, यिक्सुआन वेई, जिया निंग, यू काओ, झेंग झांग, ली डोंग, फुरु वेई, बैनिंग गुओ द्वारा arxiv.org/abs/2111.09883।
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (来自 Google AI)कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग और माइकल मटेना द्वारा साथ में पेपर [एक एकीकृत टेक्स्ट-टू-टेक्स्ट ट्रांसफॉर्मर के साथ स्थानांतरण सीखने की सीमा की खोज] (https://arxiv.org/abs/1910.10683) और यांकी झोउ और वेई ली और पीटर जे लियू।
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI से) साथ वाला पेपर [google-research/text-to-text-transfer- ट्रांसफॉर्मर](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग द्वारा और माइकल मटेना और यांकी झोउ और वेई ली और पीटर जे लियू।
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [पबटेबल्स-1एम: टूवर्ड्स कॉम्प्रिहेंसिव टेबल एक्सट्रैक्शन फ्रॉम अनस्ट्रक्चर्ड डॉक्यूमेंट्स ](https://arxiv.org/abs/2110.00061) ब्रैंडन स्मॉक, रोहित पेसाला, रॉबिन अब्राहम द्वारा पोस्ट किया गया।
diff --git a/README_ja.md b/README_ja.md
index f0cc1d31a3a9..171f7b0579f6 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -423,7 +423,8 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
diff --git a/README_ko.md b/README_ko.md
index 023d71f90d68..0c0b951aa8ee 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -338,7 +338,8 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 0f29ab657507..2a823dab8b43 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -362,7 +362,8 @@ conda install -c huggingface transformers
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (来自 Berkeley) 伴随论文 [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) 由 Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer 发布。
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (来自 Microsoft) 伴随论文 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) 由 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo 发布。
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (来自 Microsoft) 伴随论文 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) 由 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo 发布。
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (来自 University of Würzburg) 伴随论文 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) 由 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte 发布。
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (来自 Google AI) 伴随论文 [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) 由 Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu 发布。
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (来自 Google AI) 伴随论文 [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) 由 Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu 发布。
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (来自 Microsoft Research) 伴随论文 [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) 由 Brandon Smock, Rohith Pesala, Robin Abraham 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 93b23aa84431..86f35867a0ec 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -374,7 +374,8 @@ conda install -c huggingface transformers
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released with the paper [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 11f5c0b0d4fc..362fd0791aaf 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -438,6 +438,8 @@
title: Swin Transformer
- local: model_doc/swinv2
title: Swin Transformer V2
+ - local: model_doc/swin2sr
+ title: Swin2SR
- local: model_doc/table-transformer
title: Table Transformer
- local: model_doc/timesformer
@@ -564,4 +566,4 @@
- local: internal/file_utils
title: General Utilities
title: Internal Helpers
- title: API
+ title: API
\ No newline at end of file
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 01376ebed0ee..5d463e5f7dc6 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -175,6 +175,7 @@ The documentation is organized into five sections:
1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
@@ -342,6 +343,7 @@ Flax), PyTorch, and/or TensorFlow.
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/swin2sr.mdx b/docs/source/en/model_doc/swin2sr.mdx
new file mode 100644
index 000000000000..edb073d1ee38
--- /dev/null
+++ b/docs/source/en/model_doc/swin2sr.mdx
@@ -0,0 +1,57 @@
+
+
+# Swin2SR
+
+## Overview
+
+The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+Swin2R improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
+and fine-tuning, and hunger on data.
+
+The abstract from the paper is the following:
+
+*Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks.
+In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video".*
+
+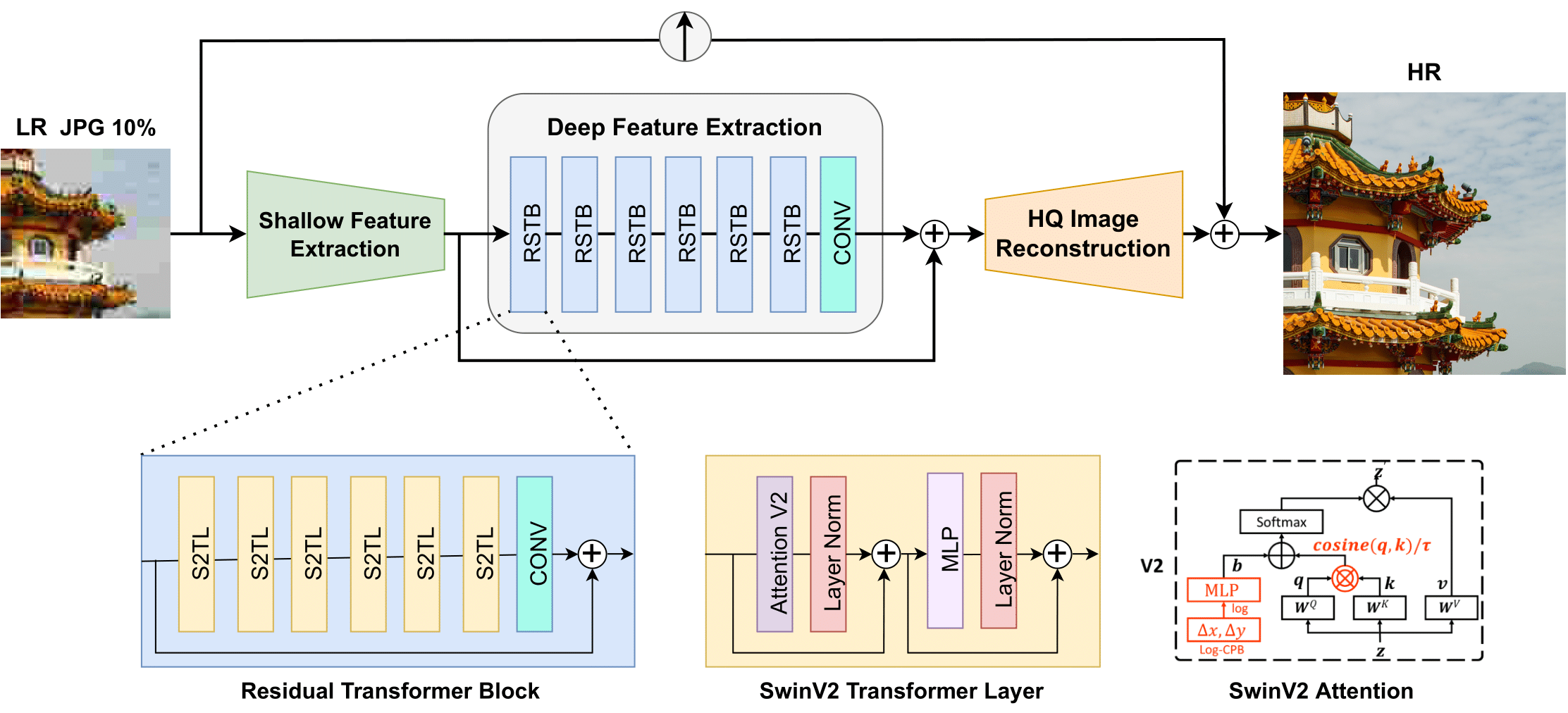 +
+ Swin2SR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/mv-lab/swin2sr).
+
+## Resources
+
+Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index f51cb5caf7ae..bcd2e1cebee6 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -373,6 +373,7 @@
"models.splinter": ["SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP", "SplinterConfig", "SplinterTokenizer"],
"models.squeezebert": ["SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "SqueezeBertConfig", "SqueezeBertTokenizer"],
"models.swin": ["SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP", "SwinConfig"],
+ "models.swin2sr": ["SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swin2SRConfig"],
"models.swinv2": ["SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swinv2Config"],
"models.switch_transformers": ["SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP", "SwitchTransformersConfig"],
"models.t5": ["T5_PRETRAINED_CONFIG_ARCHIVE_MAP", "T5Config"],
@@ -779,6 +780,7 @@
_import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
_import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.swin2sr"].append("Swin2SRImageProcessor")
_import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
_import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
_import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
@@ -2087,6 +2089,14 @@
"SwinPreTrainedModel",
]
)
+ _import_structure["models.swin2sr"].extend(
+ [
+ "SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Swin2SRForImageSuperResolution",
+ "Swin2SRModel",
+ "Swin2SRPreTrainedModel",
+ ]
+ )
_import_structure["models.swinv2"].extend(
[
"SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3630,6 +3640,7 @@
from .models.splinter import SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP, SplinterConfig, SplinterTokenizer
from .models.squeezebert import SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, SqueezeBertConfig, SqueezeBertTokenizer
from .models.swin import SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP, SwinConfig
+ from .models.swin2sr import SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP, Swin2SRConfig
from .models.swinv2 import SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP, Swinv2Config
from .models.switch_transformers import SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP, SwitchTransformersConfig
from .models.t5 import T5_PRETRAINED_CONFIG_ARCHIVE_MAP, T5Config
@@ -3978,6 +3989,7 @@
from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.swin2sr import Swin2SRImageProcessor
from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
from .models.vit import ViTFeatureExtractor, ViTImageProcessor
@@ -5052,6 +5064,12 @@
SwinModel,
SwinPreTrainedModel,
)
+ from .models.swin2sr import (
+ SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Swin2SRForImageSuperResolution,
+ Swin2SRModel,
+ Swin2SRPreTrainedModel,
+ )
from .models.swinv2 import (
SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST,
Swinv2ForImageClassification,
diff --git a/src/transformers/modeling_outputs.py b/src/transformers/modeling_outputs.py
index 57a01fa7c69c..1a38d75b4612 100644
--- a/src/transformers/modeling_outputs.py
+++ b/src/transformers/modeling_outputs.py
@@ -1204,6 +1204,34 @@ class DepthEstimatorOutput(ModelOutput):
attentions: Optional[Tuple[torch.FloatTensor]] = None
+@dataclass
+class ImageSuperResolutionOutput(ModelOutput):
+ """
+ Base class for outputs of image super resolution models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Reconstruction loss.
+ reconstruction (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Reconstructed images, possibly upscaled.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states
+ (also called feature maps) of the model at the output of each stage.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ reconstruction: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
@dataclass
class Wav2Vec2BaseModelOutput(ModelOutput):
"""
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 9c73d52fc174..342044e1f38d 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -148,6 +148,7 @@
splinter,
squeezebert,
swin,
+ swin2sr,
swinv2,
switch_transformers,
t5,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 4c7e4280e719..cb079657f839 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -145,6 +145,7 @@
("splinter", "SplinterConfig"),
("squeezebert", "SqueezeBertConfig"),
("swin", "SwinConfig"),
+ ("swin2sr", "Swin2SRConfig"),
("swinv2", "Swinv2Config"),
("switch_transformers", "SwitchTransformersConfig"),
("t5", "T5Config"),
@@ -291,6 +292,7 @@
("splinter", "SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("squeezebert", "SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swin2sr", "SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swinv2", "SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("switch_transformers", "SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("t5", "T5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -459,6 +461,7 @@
("splinter", "Splinter"),
("squeezebert", "SqueezeBERT"),
("swin", "Swin Transformer"),
+ ("swin2sr", "Swin2SR"),
("swinv2", "Swin Transformer V2"),
("switch_transformers", "SwitchTransformers"),
("t5", "T5"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index ea08c0fe8dc5..a2065abe5827 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -73,6 +73,7 @@
("resnet", "ConvNextImageProcessor"),
("segformer", "SegformerImageProcessor"),
("swin", "ViTImageProcessor"),
+ ("swin2sr", "Swin2SRImageProcessor"),
("swinv2", "ViTImageProcessor"),
("table-transformer", "DetrImageProcessor"),
("timesformer", "VideoMAEImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 7fef8a21a03b..ad6285fc011c 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -141,6 +141,7 @@
("splinter", "SplinterModel"),
("squeezebert", "SqueezeBertModel"),
("swin", "SwinModel"),
+ ("swin2sr", "Swin2SRModel"),
("swinv2", "Swinv2Model"),
("switch_transformers", "SwitchTransformersModel"),
("t5", "T5Model"),
diff --git a/src/transformers/models/swin2sr/__init__.py b/src/transformers/models/swin2sr/__init__.py
new file mode 100644
index 000000000000..3b0c885a7dc3
--- /dev/null
+++ b/src/transformers/models/swin2sr/__init__.py
@@ -0,0 +1,80 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_swin2sr": ["SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swin2SRConfig"],
+}
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_swin2sr"] = [
+ "SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Swin2SRForImageSuperResolution",
+ "Swin2SRModel",
+ "Swin2SRPreTrainedModel",
+ ]
+
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_swin2sr"] = ["Swin2SRImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_swin2sr import SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP, Swin2SRConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_swin2sr import (
+ SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Swin2SRForImageSuperResolution,
+ Swin2SRModel,
+ Swin2SRPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_swin2sr import Swin2SRImageProcessor
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/swin2sr/configuration_swin2sr.py b/src/transformers/models/swin2sr/configuration_swin2sr.py
new file mode 100644
index 000000000000..4547b5848a1b
--- /dev/null
+++ b/src/transformers/models/swin2sr/configuration_swin2sr.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Swin2SR Transformer model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "caidas/swin2sr-classicalsr-x2-64": (
+ "https://huggingface.co/caidas/swin2sr-classicalsr-x2-64/resolve/main/config.json"
+ ),
+}
+
+
+class Swin2SRConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Swin2SRModel`]. It is used to instantiate a Swin
+ Transformer v2 model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the Swin Transformer v2
+ [caidas/swin2sr-classicalsr-x2-64](https://huggingface.co/caidas/swin2sr-classicalsr-x2-64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 64):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 1):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ embed_dim (`int`, *optional*, defaults to 180):
+ Dimensionality of patch embedding.
+ depths (`list(int)`, *optional*, defaults to `[6, 6, 6, 6, 6, 6]`):
+ Depth of each layer in the Transformer encoder.
+ num_heads (`list(int)`, *optional*, defaults to `[6, 6, 6, 6, 6, 6]`):
+ Number of attention heads in each layer of the Transformer encoder.
+ window_size (`int`, *optional*, defaults to 8):
+ Size of windows.
+ mlp_ratio (`float`, *optional*, defaults to 2.0):
+ Ratio of MLP hidden dimensionality to embedding dimensionality.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether or not a learnable bias should be added to the queries, keys and values.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings and encoder.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ drop_path_rate (`float`, *optional*, defaults to 0.1):
+ Stochastic depth rate.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder. If string, `"gelu"`, `"relu"`,
+ `"selu"` and `"gelu_new"` are supported.
+ use_absolute_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether or not to add absolute position embeddings to the patch embeddings.
+ patch_norm (`bool`, *optional*, defaults to `True`):
+ Whether or not to add layer normalization after patch embedding.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ upscale (`int`, *optional*, defaults to 2):
+ The upscale factor for the image. 2/3/4/8 for image super resolution, 1 for denoising and compress artifact
+ reduction
+ img_range (`float`, *optional*, defaults to 1.):
+ The range of the values of the input image.
+ resi_connection (`str`, *optional*, defaults to `"1conv"`):
+ The convolutional block to use before the residual connection in each stage.
+ upsampler (`str`, *optional*, defaults to `"pixelshuffle"`):
+ The reconstruction reconstruction module. Can be 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None.
+
+ Example:
+
+ ```python
+ >>> from transformers import Swin2SRConfig, Swin2SRModel
+
+ >>> # Initializing a Swin2SR caidas/swin2sr-classicalsr-x2-64 style configuration
+ >>> configuration = Swin2SRConfig()
+
+ >>> # Initializing a model (with random weights) from the caidas/swin2sr-classicalsr-x2-64 style configuration
+ >>> model = Swin2SRModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "swin2sr"
+
+ attribute_map = {
+ "hidden_size": "embed_dim",
+ "num_attention_heads": "num_heads",
+ "num_hidden_layers": "num_layers",
+ }
+
+ def __init__(
+ self,
+ image_size=64,
+ patch_size=1,
+ num_channels=3,
+ embed_dim=180,
+ depths=[6, 6, 6, 6, 6, 6],
+ num_heads=[6, 6, 6, 6, 6, 6],
+ window_size=8,
+ mlp_ratio=2.0,
+ qkv_bias=True,
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ drop_path_rate=0.1,
+ hidden_act="gelu",
+ use_absolute_embeddings=False,
+ patch_norm=True,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ upscale=2,
+ img_range=1.0,
+ resi_connection="1conv",
+ upsampler="pixelshuffle",
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.depths = depths
+ self.num_layers = len(depths)
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+ self.qkv_bias = qkv_bias
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_absolute_embeddings = use_absolute_embeddings
+ self.path_norm = patch_norm
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.upscale = upscale
+ self.img_range = img_range
+ self.resi_connection = resi_connection
+ self.upsampler = upsampler
diff --git a/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py b/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
new file mode 100644
index 000000000000..38a11496f7ee
--- /dev/null
+++ b/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
@@ -0,0 +1,278 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Swin2SR checkpoints from the original repository. URL: https://github.com/mv-lab/swin2sr"""
+
+import argparse
+
+import torch
+from PIL import Image
+from torchvision.transforms import Compose, Normalize, Resize, ToTensor
+
+import requests
+from transformers import Swin2SRConfig, Swin2SRForImageSuperResolution, Swin2SRImageProcessor
+
+
+def get_config(checkpoint_url):
+ config = Swin2SRConfig()
+
+ if "Swin2SR_ClassicalSR_X4_64" in checkpoint_url:
+ config.upscale = 4
+ elif "Swin2SR_CompressedSR_X4_48" in checkpoint_url:
+ config.upscale = 4
+ config.image_size = 48
+ config.upsampler = "pixelshuffle_aux"
+ elif "Swin2SR_Lightweight_X2_64" in checkpoint_url:
+ config.depths = [6, 6, 6, 6]
+ config.embed_dim = 60
+ config.num_heads = [6, 6, 6, 6]
+ config.upsampler = "pixelshuffledirect"
+ elif "Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR" in checkpoint_url:
+ config.upscale = 4
+ config.upsampler = "nearest+conv"
+ elif "Swin2SR_Jpeg_dynamic" in checkpoint_url:
+ config.num_channels = 1
+ config.upscale = 1
+ config.image_size = 126
+ config.window_size = 7
+ config.img_range = 255.0
+ config.upsampler = ""
+
+ return config
+
+
+def rename_key(name, config):
+ if "patch_embed.proj" in name and "layers" not in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ if "patch_embed.norm" in name:
+ name = name.replace("patch_embed.norm", "embeddings.patch_embeddings.layernorm")
+ if "layers" in name:
+ name = name.replace("layers", "encoder.stages")
+ if "residual_group.blocks" in name:
+ name = name.replace("residual_group.blocks", "layers")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "q_bias" in name:
+ name = name.replace("q_bias", "query.bias")
+ if "k_bias" in name:
+ name = name.replace("k_bias", "key.bias")
+ if "v_bias" in name:
+ name = name.replace("v_bias", "value.bias")
+ if "cpb_mlp" in name:
+ name = name.replace("cpb_mlp", "continuous_position_bias_mlp")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "patch_embed.projection")
+
+ if name == "norm.weight":
+ name = "layernorm.weight"
+ if name == "norm.bias":
+ name = "layernorm.bias"
+
+ if "conv_first" in name:
+ name = name.replace("conv_first", "first_convolution")
+
+ if (
+ "upsample" in name
+ or "conv_before_upsample" in name
+ or "conv_bicubic" in name
+ or "conv_up" in name
+ or "conv_hr" in name
+ or "conv_last" in name
+ or "aux" in name
+ ):
+ # heads
+ if "conv_last" in name:
+ name = name.replace("conv_last", "final_convolution")
+ if config.upsampler in ["pixelshuffle", "pixelshuffle_aux", "nearest+conv"]:
+ if "conv_before_upsample.0" in name:
+ name = name.replace("conv_before_upsample.0", "conv_before_upsample")
+ if "upsample.0" in name:
+ name = name.replace("upsample.0", "upsample.convolution_0")
+ if "upsample.2" in name:
+ name = name.replace("upsample.2", "upsample.convolution_1")
+ name = "upsample." + name
+ elif config.upsampler == "pixelshuffledirect":
+ name = name.replace("upsample.0.weight", "upsample.conv.weight")
+ name = name.replace("upsample.0.bias", "upsample.conv.bias")
+ else:
+ pass
+ else:
+ name = "swin2sr." + name
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ stage_num = int(key_split[1])
+ block_num = int(key_split[4])
+ dim = config.embed_dim
+
+ if "weight" in key:
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.query.weight"
+ ] = val[:dim, :]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.key.weight"
+ ] = val[dim : dim * 2, :]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.value.weight"
+ ] = val[-dim:, :]
+ else:
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.query.bias"
+ ] = val[:dim]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.key.bias"
+ ] = val[dim : dim * 2]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.value.bias"
+ ] = val[-dim:]
+ pass
+ else:
+ orig_state_dict[rename_key(key, config)] = val
+
+ return orig_state_dict
+
+
+def convert_swin2sr_checkpoint(checkpoint_url, pytorch_dump_folder_path, push_to_hub):
+ config = get_config(checkpoint_url)
+ model = Swin2SRForImageSuperResolution(config)
+ model.eval()
+
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")
+ new_state_dict = convert_state_dict(state_dict, config)
+ missing_keys, unexpected_keys = model.load_state_dict(new_state_dict, strict=False)
+
+ if len(missing_keys) > 0:
+ raise ValueError("Missing keys when converting: {}".format(missing_keys))
+ for key in unexpected_keys:
+ if not ("relative_position_index" in key or "relative_coords_table" in key or "self_mask" in key):
+ raise ValueError(f"Unexpected key {key} in state_dict")
+
+ # verify values
+ url = "https://github.com/mv-lab/swin2sr/blob/main/testsets/real-inputs/shanghai.jpg?raw=true"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ processor = Swin2SRImageProcessor()
+ # pixel_values = processor(image, return_tensors="pt").pixel_values
+
+ image_size = 126 if "Jpeg" in checkpoint_url else 256
+ transforms = Compose(
+ [
+ Resize((image_size, image_size)),
+ ToTensor(),
+ Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+ ]
+ )
+ pixel_values = transforms(image).unsqueeze(0)
+
+ if config.num_channels == 1:
+ pixel_values = pixel_values[:, 0, :, :].unsqueeze(1)
+
+ outputs = model(pixel_values)
+
+ # assert values
+ if "Swin2SR_ClassicalSR_X2_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 512, 512])
+ expected_slice = torch.tensor(
+ [[-0.7087, -0.7138, -0.6721], [-0.8340, -0.8095, -0.7298], [-0.9149, -0.8414, -0.7940]]
+ )
+ elif "Swin2SR_ClassicalSR_X4_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.7775, -0.8105, -0.8933], [-0.7764, -0.8356, -0.9225], [-0.7976, -0.8686, -0.9579]]
+ )
+ elif "Swin2SR_CompressedSR_X4_48" in checkpoint_url:
+ # TODO values didn't match exactly here
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.8035, -0.7504, -0.7491], [-0.8538, -0.8124, -0.7782], [-0.8804, -0.8651, -0.8493]]
+ )
+ elif "Swin2SR_Lightweight_X2_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 512, 512])
+ expected_slice = torch.tensor(
+ [[-0.7669, -0.8662, -0.8767], [-0.8810, -0.9962, -0.9820], [-0.9340, -1.0322, -1.1149]]
+ )
+ elif "Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.5238, -0.5557, -0.6321], [-0.6016, -0.5903, -0.6391], [-0.6244, -0.6334, -0.6889]]
+ )
+
+ assert (
+ outputs.reconstruction.shape == expected_shape
+ ), f"Shape of reconstruction should be {expected_shape}, but is {outputs.reconstruction.shape}"
+ assert torch.allclose(outputs.reconstruction[0, 0, :3, :3], expected_slice, atol=1e-3)
+ print("Looks ok!")
+
+ url_to_name = {
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X2_64.pth": (
+ "swin2SR-classical-sr-x2-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X4_64.pth": (
+ "swin2SR-classical-sr-x4-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_CompressedSR_X4_48.pth": (
+ "swin2SR-compressed-sr-x4-48"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_Lightweight_X2_64.pth": (
+ "swin2SR-lightweight-x2-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR.pth": (
+ "swin2SR-realworld-sr-x4-64-bsrgan-psnr"
+ ),
+ }
+ model_name = url_to_name[checkpoint_url]
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving image processor to {pytorch_dump_folder_path}")
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"caidas/{model_name}")
+ processor.push_to_hub(f"caidas/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X2_64.pth",
+ type=str,
+ help="URL of the original Swin2SR checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the converted model to the hub.")
+
+ args = parser.parse_args()
+ convert_swin2sr_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/swin2sr/image_processing_swin2sr.py b/src/transformers/models/swin2sr/image_processing_swin2sr.py
new file mode 100644
index 000000000000..c5c5458d8aa7
--- /dev/null
+++ b/src/transformers/models/swin2sr/image_processing_swin2sr.py
@@ -0,0 +1,175 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Swin2SR."""
+
+from typing import Optional, Union
+
+import numpy as np
+
+from transformers.utils.generic import TensorType
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature
+from ...image_transforms import get_image_size, pad, rescale, to_channel_dimension_format
+from ...image_utils import ChannelDimension, ImageInput, is_batched, to_numpy_array, valid_images
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class Swin2SRImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Swin2SR image processor.
+
+ Args:
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_pad: bool = True,
+ pad_size: int = 8,
+ **kwargs
+ ) -> None:
+ super().__init__(**kwargs)
+
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.pad_size = pad_size
+
+ def rescale(
+ self, image: np.ndarray, scale: float, data_format: Optional[Union[str, ChannelDimension]] = None, **kwargs
+ ) -> np.ndarray:
+ """
+ Rescale an image by a scale factor. image = image * scale.
+
+ Args:
+ image (`np.ndarray`):
+ Image to rescale.
+ scale (`float`):
+ The scaling factor to rescale pixel values by.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+
+ Returns:
+ `np.ndarray`: The rescaled image.
+ """
+ return rescale(image, scale=scale, data_format=data_format, **kwargs)
+
+ def pad(self, image: np.ndarray, size: int, data_format: Optional[Union[str, ChannelDimension]] = None):
+ """
+ Pad an image to make the height and width divisible by `size`.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ size (`int`):
+ The size to make the height and width divisible by.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+
+ Returns:
+ `np.ndarray`: The padded image.
+ """
+ old_height, old_width = get_image_size(image)
+ pad_height = (old_height // size + 1) * size - old_height
+ pad_width = (old_width // size + 1) * size - old_width
+
+ return pad(image, ((0, pad_height), (0, pad_width)), mode="symmetric", data_format=data_format)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_pad: Optional[bool] = None,
+ pad_size: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Whether to pad the image to make the height and width divisible by `window_size`.
+ pad_size (`int`, *optional*, defaults to `32`):
+ The size of the sliding window for the local attention.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ """
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_pad = do_pad if do_pad is not None else self.do_pad
+ pad_size = pad_size if pad_size is not None else self.pad_size
+
+ if not is_batched(images):
+ images = [images]
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image=image, scale=rescale_factor) for image in images]
+
+ if do_pad:
+ images = [self.pad(image, size=pad_size) for image in images]
+
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/swin2sr/modeling_swin2sr.py b/src/transformers/models/swin2sr/modeling_swin2sr.py
new file mode 100644
index 000000000000..0edc2feea883
--- /dev/null
+++ b/src/transformers/models/swin2sr/modeling_swin2sr.py
@@ -0,0 +1,1204 @@
+# coding=utf-8
+# Copyright 2022 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Swin2SR Transformer model."""
+
+
+import collections.abc
+import math
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, ImageSuperResolutionOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_swin2sr import Swin2SRConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "Swin2SRConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "caidas/swin2sr-classicalsr-x2-64"
+_EXPECTED_OUTPUT_SHAPE = [1, 64, 768]
+
+
+SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "caidas/swin2SR-classical-sr-x2-64",
+ # See all Swin2SR models at https://huggingface.co/models?filter=swin2sr
+]
+
+
+@dataclass
+class Swin2SREncoderOutput(ModelOutput):
+ """
+ Swin2SR encoder's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each stage) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Copied from transformers.models.swin.modeling_swin.window_partition
+def window_partition(input_feature, window_size):
+ """
+ Partitions the given input into windows.
+ """
+ batch_size, height, width, num_channels = input_feature.shape
+ input_feature = input_feature.view(
+ batch_size, height // window_size, window_size, width // window_size, window_size, num_channels
+ )
+ windows = input_feature.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, num_channels)
+ return windows
+
+
+# Copied from transformers.models.swin.modeling_swin.window_reverse
+def window_reverse(windows, window_size, height, width):
+ """
+ Merges windows to produce higher resolution features.
+ """
+ num_channels = windows.shape[-1]
+ windows = windows.view(-1, height // window_size, width // window_size, window_size, window_size, num_channels)
+ windows = windows.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, height, width, num_channels)
+ return windows
+
+
+# Copied from transformers.models.swin.modeling_swin.drop_path
+def drop_path(input, drop_prob=0.0, training=False, scale_by_keep=True):
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinDropPath with Swin->Swin2SR
+class Swin2SRDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+class Swin2SREmbeddings(nn.Module):
+ """
+ Construct the patch and optional position embeddings.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.patch_embeddings = Swin2SRPatchEmbeddings(config)
+ num_patches = self.patch_embeddings.num_patches
+
+ if config.use_absolute_embeddings:
+ self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
+ else:
+ self.position_embeddings = None
+
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.window_size = config.window_size
+
+ def forward(self, pixel_values: Optional[torch.FloatTensor]) -> Tuple[torch.Tensor]:
+ embeddings, output_dimensions = self.patch_embeddings(pixel_values)
+
+ if self.position_embeddings is not None:
+ embeddings = embeddings + self.position_embeddings
+
+ embeddings = self.dropout(embeddings)
+
+ return embeddings, output_dimensions
+
+
+class Swin2SRPatchEmbeddings(nn.Module):
+ def __init__(self, config, normalize_patches=True):
+ super().__init__()
+ num_channels = config.embed_dim
+ image_size, patch_size = config.image_size, config.patch_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ patches_resolution = [image_size[0] // patch_size[0], image_size[1] // patch_size[1]]
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.projection = nn.Conv2d(num_channels, config.embed_dim, kernel_size=patch_size, stride=patch_size)
+ self.layernorm = nn.LayerNorm(config.embed_dim) if normalize_patches else None
+
+ def forward(self, embeddings: Optional[torch.FloatTensor]) -> Tuple[torch.Tensor, Tuple[int]]:
+ embeddings = self.projection(embeddings)
+ _, _, height, width = embeddings.shape
+ output_dimensions = (height, width)
+ embeddings = embeddings.flatten(2).transpose(1, 2)
+
+ if self.layernorm is not None:
+ embeddings = self.layernorm(embeddings)
+
+ return embeddings, output_dimensions
+
+
+class Swin2SRPatchUnEmbeddings(nn.Module):
+ r"""Image to Patch Unembedding"""
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.embed_dim = config.embed_dim
+
+ def forward(self, embeddings, x_size):
+ batch_size, height_width, num_channels = embeddings.shape
+ embeddings = embeddings.transpose(1, 2).view(batch_size, self.embed_dim, x_size[0], x_size[1]) # B Ph*Pw C
+ return embeddings
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2PatchMerging with Swinv2->Swin2SR
+class Swin2SRPatchMerging(nn.Module):
+ """
+ Patch Merging Layer.
+
+ Args:
+ input_resolution (`Tuple[int]`):
+ Resolution of input feature.
+ dim (`int`):
+ Number of input channels.
+ norm_layer (`nn.Module`, *optional*, defaults to `nn.LayerNorm`):
+ Normalization layer class.
+ """
+
+ def __init__(self, input_resolution: Tuple[int], dim: int, norm_layer: nn.Module = nn.LayerNorm) -> None:
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(2 * dim)
+
+ def maybe_pad(self, input_feature, height, width):
+ should_pad = (height % 2 == 1) or (width % 2 == 1)
+ if should_pad:
+ pad_values = (0, 0, 0, width % 2, 0, height % 2)
+ input_feature = nn.functional.pad(input_feature, pad_values)
+
+ return input_feature
+
+ def forward(self, input_feature: torch.Tensor, input_dimensions: Tuple[int, int]) -> torch.Tensor:
+ height, width = input_dimensions
+ # `dim` is height * width
+ batch_size, dim, num_channels = input_feature.shape
+
+ input_feature = input_feature.view(batch_size, height, width, num_channels)
+ # pad input to be disible by width and height, if needed
+ input_feature = self.maybe_pad(input_feature, height, width)
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_0 = input_feature[:, 0::2, 0::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_1 = input_feature[:, 1::2, 0::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_2 = input_feature[:, 0::2, 1::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_3 = input_feature[:, 1::2, 1::2, :]
+ # [batch_size, height/2 * width/2, 4*num_channels]
+ input_feature = torch.cat([input_feature_0, input_feature_1, input_feature_2, input_feature_3], -1)
+ input_feature = input_feature.view(batch_size, -1, 4 * num_channels) # [batch_size, height/2 * width/2, 4*C]
+
+ input_feature = self.reduction(input_feature)
+ input_feature = self.norm(input_feature)
+
+ return input_feature
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2SelfAttention with Swinv2->Swin2SR
+class Swin2SRSelfAttention(nn.Module):
+ def __init__(self, config, dim, num_heads, window_size, pretrained_window_size=[0, 0]):
+ super().__init__()
+ if dim % num_heads != 0:
+ raise ValueError(
+ f"The hidden size ({dim}) is not a multiple of the number of attention heads ({num_heads})"
+ )
+
+ self.num_attention_heads = num_heads
+ self.attention_head_size = int(dim / num_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+ self.window_size = (
+ window_size if isinstance(window_size, collections.abc.Iterable) else (window_size, window_size)
+ )
+ self.pretrained_window_size = pretrained_window_size
+ self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
+ # mlp to generate continuous relative position bias
+ self.continuous_position_bias_mlp = nn.Sequential(
+ nn.Linear(2, 512, bias=True), nn.ReLU(inplace=True), nn.Linear(512, num_heads, bias=False)
+ )
+
+ # get relative_coords_table
+ relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
+ relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
+ relative_coords_table = (
+ torch.stack(meshgrid([relative_coords_h, relative_coords_w], indexing="ij"))
+ .permute(1, 2, 0)
+ .contiguous()
+ .unsqueeze(0)
+ ) # [1, 2*window_height - 1, 2*window_width - 1, 2]
+ if pretrained_window_size[0] > 0:
+ relative_coords_table[:, :, :, 0] /= pretrained_window_size[0] - 1
+ relative_coords_table[:, :, :, 1] /= pretrained_window_size[1] - 1
+ else:
+ relative_coords_table[:, :, :, 0] /= self.window_size[0] - 1
+ relative_coords_table[:, :, :, 1] /= self.window_size[1] - 1
+ relative_coords_table *= 8 # normalize to -8, 8
+ relative_coords_table = (
+ torch.sign(relative_coords_table) * torch.log2(torch.abs(relative_coords_table) + 1.0) / math.log2(8)
+ )
+ self.register_buffer("relative_coords_table", relative_coords_table, persistent=False)
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij"))
+ coords_flatten = torch.flatten(coords, 1)
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous()
+ relative_coords[:, :, 0] += self.window_size[0] - 1
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1)
+ self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+
+ self.query = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(self.all_head_size, self.all_head_size, bias=False)
+ self.value = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ batch_size, dim, num_channels = hidden_states.shape
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # cosine attention
+ attention_scores = nn.functional.normalize(query_layer, dim=-1) @ nn.functional.normalize(
+ key_layer, dim=-1
+ ).transpose(-2, -1)
+ logit_scale = torch.clamp(self.logit_scale, max=math.log(1.0 / 0.01)).exp()
+ attention_scores = attention_scores * logit_scale
+ relative_position_bias_table = self.continuous_position_bias_mlp(self.relative_coords_table).view(
+ -1, self.num_attention_heads
+ )
+ # [window_height*window_width,window_height*window_width,num_attention_heads]
+ relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
+ )
+ # [num_attention_heads,window_height*window_width,window_height*window_width]
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
+ attention_scores = attention_scores + relative_position_bias.unsqueeze(0)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in Swin2SRModel forward() function)
+ mask_shape = attention_mask.shape[0]
+ attention_scores = attention_scores.view(
+ batch_size // mask_shape, mask_shape, self.num_attention_heads, dim, dim
+ ) + attention_mask.unsqueeze(1).unsqueeze(0)
+ attention_scores = attention_scores + attention_mask.unsqueeze(1).unsqueeze(0)
+ attention_scores = attention_scores.view(-1, self.num_attention_heads, dim, dim)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinSelfOutput with Swin->Swin2SR
+class Swin2SRSelfOutput(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(dim, dim)
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2Attention with Swinv2->Swin2SR
+class Swin2SRAttention(nn.Module):
+ def __init__(self, config, dim, num_heads, window_size, pretrained_window_size=0):
+ super().__init__()
+ self.self = Swin2SRSelfAttention(
+ config=config,
+ dim=dim,
+ num_heads=num_heads,
+ window_size=window_size,
+ pretrained_window_size=pretrained_window_size
+ if isinstance(pretrained_window_size, collections.abc.Iterable)
+ else (pretrained_window_size, pretrained_window_size),
+ )
+ self.output = Swin2SRSelfOutput(config, dim)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(hidden_states, attention_mask, head_mask, output_attentions)
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinIntermediate with Swin->Swin2SR
+class Swin2SRIntermediate(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(dim, int(config.mlp_ratio * dim))
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinOutput with Swin->Swin2SR
+class Swin2SROutput(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(int(config.mlp_ratio * dim), dim)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2Layer with Swinv2->Swin2SR
+class Swin2SRLayer(nn.Module):
+ def __init__(self, config, dim, input_resolution, num_heads, shift_size=0, pretrained_window_size=0):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.shift_size = shift_size
+ self.window_size = config.window_size
+ self.input_resolution = input_resolution
+ self.set_shift_and_window_size(input_resolution)
+ self.attention = Swin2SRAttention(
+ config=config,
+ dim=dim,
+ num_heads=num_heads,
+ window_size=self.window_size,
+ pretrained_window_size=pretrained_window_size
+ if isinstance(pretrained_window_size, collections.abc.Iterable)
+ else (pretrained_window_size, pretrained_window_size),
+ )
+ self.layernorm_before = nn.LayerNorm(dim, eps=config.layer_norm_eps)
+ self.drop_path = Swin2SRDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
+ self.intermediate = Swin2SRIntermediate(config, dim)
+ self.output = Swin2SROutput(config, dim)
+ self.layernorm_after = nn.LayerNorm(dim, eps=config.layer_norm_eps)
+
+ def set_shift_and_window_size(self, input_resolution):
+ target_window_size = (
+ self.window_size
+ if isinstance(self.window_size, collections.abc.Iterable)
+ else (self.window_size, self.window_size)
+ )
+ target_shift_size = (
+ self.shift_size
+ if isinstance(self.shift_size, collections.abc.Iterable)
+ else (self.shift_size, self.shift_size)
+ )
+ self.window_size = (
+ input_resolution[0] if input_resolution[0] <= target_window_size[0] else target_window_size[0]
+ )
+ self.shift_size = (
+ 0
+ if input_resolution
+ <= (
+ self.window_size
+ if isinstance(self.window_size, collections.abc.Iterable)
+ else (self.window_size, self.window_size)
+ )
+ else target_shift_size[0]
+ )
+
+ def get_attn_mask(self, height, width, dtype):
+ if self.shift_size > 0:
+ # calculate attention mask for shifted window multihead self attention
+ img_mask = torch.zeros((1, height, width, 1), dtype=dtype)
+ height_slices = (
+ slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None),
+ )
+ width_slices = (
+ slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None),
+ )
+ count = 0
+ for height_slice in height_slices:
+ for width_slice in width_slices:
+ img_mask[:, height_slice, width_slice, :] = count
+ count += 1
+
+ mask_windows = window_partition(img_mask, self.window_size)
+ mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+ else:
+ attn_mask = None
+ return attn_mask
+
+ def maybe_pad(self, hidden_states, height, width):
+ pad_right = (self.window_size - width % self.window_size) % self.window_size
+ pad_bottom = (self.window_size - height % self.window_size) % self.window_size
+ pad_values = (0, 0, 0, pad_right, 0, pad_bottom)
+ hidden_states = nn.functional.pad(hidden_states, pad_values)
+ return hidden_states, pad_values
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ self.set_shift_and_window_size(input_dimensions)
+ height, width = input_dimensions
+ batch_size, _, channels = hidden_states.size()
+ shortcut = hidden_states
+
+ # pad hidden_states to multiples of window size
+ hidden_states = hidden_states.view(batch_size, height, width, channels)
+ hidden_states, pad_values = self.maybe_pad(hidden_states, height, width)
+ _, height_pad, width_pad, _ = hidden_states.shape
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_hidden_states = torch.roll(hidden_states, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_hidden_states = hidden_states
+
+ # partition windows
+ hidden_states_windows = window_partition(shifted_hidden_states, self.window_size)
+ hidden_states_windows = hidden_states_windows.view(-1, self.window_size * self.window_size, channels)
+ attn_mask = self.get_attn_mask(height_pad, width_pad, dtype=hidden_states.dtype)
+ if attn_mask is not None:
+ attn_mask = attn_mask.to(hidden_states_windows.device)
+
+ attention_outputs = self.attention(
+ hidden_states_windows, attn_mask, head_mask, output_attentions=output_attentions
+ )
+
+ attention_output = attention_outputs[0]
+
+ attention_windows = attention_output.view(-1, self.window_size, self.window_size, channels)
+ shifted_windows = window_reverse(attention_windows, self.window_size, height_pad, width_pad)
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ attention_windows = torch.roll(shifted_windows, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
+ else:
+ attention_windows = shifted_windows
+
+ was_padded = pad_values[3] > 0 or pad_values[5] > 0
+ if was_padded:
+ attention_windows = attention_windows[:, :height, :width, :].contiguous()
+
+ attention_windows = attention_windows.view(batch_size, height * width, channels)
+ hidden_states = self.layernorm_before(attention_windows)
+ hidden_states = shortcut + self.drop_path(hidden_states)
+
+ layer_output = self.intermediate(hidden_states)
+ layer_output = self.output(layer_output)
+ layer_output = hidden_states + self.drop_path(self.layernorm_after(layer_output))
+
+ layer_outputs = (layer_output, attention_outputs[1]) if output_attentions else (layer_output,)
+ return layer_outputs
+
+
+class Swin2SRStage(nn.Module):
+ """
+ This corresponds to the Residual Swin Transformer Block (RSTB) in the original implementation.
+ """
+
+ def __init__(self, config, dim, input_resolution, depth, num_heads, drop_path, pretrained_window_size=0):
+ super().__init__()
+ self.config = config
+ self.dim = dim
+ self.layers = nn.ModuleList(
+ [
+ Swin2SRLayer(
+ config=config,
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ shift_size=0 if (i % 2 == 0) else config.window_size // 2,
+ pretrained_window_size=pretrained_window_size,
+ )
+ for i in range(depth)
+ ]
+ )
+
+ if config.resi_connection == "1conv":
+ self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
+ elif config.resi_connection == "3conv":
+ # to save parameters and memory
+ self.conv = nn.Sequential(
+ nn.Conv2d(dim, dim // 4, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim, 3, 1, 1),
+ )
+
+ self.patch_embed = Swin2SRPatchEmbeddings(config, normalize_patches=False)
+
+ self.patch_unembed = Swin2SRPatchUnEmbeddings(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ residual = hidden_states
+
+ height, width = input_dimensions
+ for i, layer_module in enumerate(self.layers):
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ layer_outputs = layer_module(hidden_states, input_dimensions, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ output_dimensions = (height, width, height, width)
+
+ hidden_states = self.patch_unembed(hidden_states, input_dimensions)
+ hidden_states = self.conv(hidden_states)
+ hidden_states, _ = self.patch_embed(hidden_states)
+
+ hidden_states = hidden_states + residual
+
+ stage_outputs = (hidden_states, output_dimensions)
+
+ if output_attentions:
+ stage_outputs += layer_outputs[1:]
+ return stage_outputs
+
+
+class Swin2SREncoder(nn.Module):
+ def __init__(self, config, grid_size):
+ super().__init__()
+ self.num_stages = len(config.depths)
+ self.config = config
+ dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+ self.stages = nn.ModuleList(
+ [
+ Swin2SRStage(
+ config=config,
+ dim=config.embed_dim,
+ input_resolution=(grid_size[0], grid_size[1]),
+ depth=config.depths[stage_idx],
+ num_heads=config.num_heads[stage_idx],
+ drop_path=dpr[sum(config.depths[:stage_idx]) : sum(config.depths[: stage_idx + 1])],
+ pretrained_window_size=0,
+ )
+ for stage_idx in range(self.num_stages)
+ ]
+ )
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple, Swin2SREncoderOutput]:
+ all_input_dimensions = ()
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ for i, stage_module in enumerate(self.stages):
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(stage_module), hidden_states, input_dimensions, layer_head_mask
+ )
+ else:
+ layer_outputs = stage_module(hidden_states, input_dimensions, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+ output_dimensions = layer_outputs[1]
+
+ input_dimensions = (output_dimensions[-2], output_dimensions[-1])
+ all_input_dimensions += (input_dimensions,)
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if output_attentions:
+ all_self_attentions += layer_outputs[2:]
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+
+ return Swin2SREncoderOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class Swin2SRPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = Swin2SRConfig
+ base_model_prefix = "swin2sr"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ torch.nn.init.trunc_normal_(module.weight.data, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, Swin2SREncoder):
+ module.gradient_checkpointing = value
+
+
+SWIN2SR_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
+ it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`Swin2SRConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+SWIN2SR_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Swin2SR Model transformer outputting raw hidden-states without any specific head on top.",
+ SWIN2SR_START_DOCSTRING,
+)
+class Swin2SRModel(Swin2SRPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ if config.num_channels == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+ else:
+ self.mean = torch.zeros(1, 1, 1, 1)
+ self.img_range = config.img_range
+
+ self.first_convolution = nn.Conv2d(config.num_channels, config.embed_dim, 3, 1, 1)
+ self.embeddings = Swin2SREmbeddings(config)
+ self.encoder = Swin2SREncoder(config, grid_size=self.embeddings.patch_embeddings.patches_resolution)
+
+ self.layernorm = nn.LayerNorm(config.embed_dim, eps=config.layer_norm_eps)
+ self.patch_unembed = Swin2SRPatchUnEmbeddings(config)
+ self.conv_after_body = nn.Conv2d(config.embed_dim, config.embed_dim, 3, 1, 1)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def pad_and_normalize(self, pixel_values):
+ _, _, height, width = pixel_values.size()
+
+ # 1. pad
+ window_size = self.config.window_size
+ modulo_pad_height = (window_size - height % window_size) % window_size
+ modulo_pad_width = (window_size - width % window_size) % window_size
+ pixel_values = nn.functional.pad(pixel_values, (0, modulo_pad_width, 0, modulo_pad_height), "reflect")
+
+ # 2. normalize
+ self.mean = self.mean.type_as(pixel_values)
+ pixel_values = (pixel_values - self.mean) * self.img_range
+
+ return pixel_values
+
+ @add_start_docstrings_to_model_forward(SWIN2SR_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, len(self.config.depths))
+
+ _, _, height, width = pixel_values.shape
+
+ # some preprocessing: padding + normalization
+ pixel_values = self.pad_and_normalize(pixel_values)
+
+ embeddings = self.first_convolution(pixel_values)
+ embedding_output, input_dimensions = self.embeddings(embeddings)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ input_dimensions,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ sequence_output = self.patch_unembed(sequence_output, (height, width))
+ sequence_output = self.conv_after_body(sequence_output) + embeddings
+
+ if not return_dict:
+ output = (sequence_output,) + encoder_outputs[1:]
+
+ return output
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class Upsample(nn.Module):
+ """Upsample module.
+
+ Args:
+ scale (`int`):
+ Scale factor. Supported scales: 2^n and 3.
+ num_features (`int`):
+ Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_features):
+ super().__init__()
+
+ self.scale = scale
+ if (scale & (scale - 1)) == 0:
+ # scale = 2^n
+ for i in range(int(math.log(scale, 2))):
+ self.add_module(f"convolution_{i}", nn.Conv2d(num_features, 4 * num_features, 3, 1, 1))
+ self.add_module(f"pixelshuffle_{i}", nn.PixelShuffle(2))
+ elif scale == 3:
+ self.convolution = nn.Conv2d(num_features, 9 * num_features, 3, 1, 1)
+ self.pixelshuffle = nn.PixelShuffle(3)
+ else:
+ raise ValueError(f"Scale {scale} is not supported. Supported scales: 2^n and 3.")
+
+ def forward(self, hidden_state):
+ if (self.scale & (self.scale - 1)) == 0:
+ for i in range(int(math.log(self.scale, 2))):
+ hidden_state = self.__getattr__(f"convolution_{i}")(hidden_state)
+ hidden_state = self.__getattr__(f"pixelshuffle_{i}")(hidden_state)
+
+ elif self.scale == 3:
+ hidden_state = self.convolution(hidden_state)
+ hidden_state = self.pixelshuffle(hidden_state)
+
+ return hidden_state
+
+
+class UpsampleOneStep(nn.Module):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+
+ Used in lightweight SR to save parameters.
+
+ Args:
+ scale (int):
+ Scale factor. Supported scales: 2^n and 3.
+ in_channels (int):
+ Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, in_channels, out_channels):
+ super().__init__()
+
+ self.conv = nn.Conv2d(in_channels, (scale**2) * out_channels, 3, 1, 1)
+ self.pixel_shuffle = nn.PixelShuffle(scale)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.pixel_shuffle(x)
+
+ return x
+
+
+class PixelShuffleUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.upsample = Upsample(config.upscale, num_features)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+
+ def forward(self, sequence_output):
+ x = self.conv_before_upsample(sequence_output)
+ x = self.activation(x)
+ x = self.upsample(x)
+ x = self.final_convolution(x)
+
+ return x
+
+
+class NearestConvUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+ if config.upscale != 4:
+ raise ValueError("The nearest+conv upsampler only supports an upscale factor of 4 at the moment.")
+
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.conv_up1 = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, sequence_output):
+ sequence_output = self.conv_before_upsample(sequence_output)
+ sequence_output = self.activation(sequence_output)
+ sequence_output = self.lrelu(
+ self.conv_up1(torch.nn.functional.interpolate(sequence_output, scale_factor=2, mode="nearest"))
+ )
+ sequence_output = self.lrelu(
+ self.conv_up2(torch.nn.functional.interpolate(sequence_output, scale_factor=2, mode="nearest"))
+ )
+ reconstruction = self.final_convolution(self.lrelu(self.conv_hr(sequence_output)))
+ return reconstruction
+
+
+class PixelShuffleAuxUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+
+ self.upscale = config.upscale
+ self.conv_bicubic = nn.Conv2d(config.num_channels, num_features, 3, 1, 1)
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.conv_aux = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+ self.conv_after_aux = nn.Sequential(nn.Conv2d(3, num_features, 3, 1, 1), nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(config.upscale, num_features)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+
+ def forward(self, sequence_output, bicubic, height, width):
+ bicubic = self.conv_bicubic(bicubic)
+ sequence_output = self.conv_before_upsample(sequence_output)
+ sequence_output = self.activation(sequence_output)
+ aux = self.conv_aux(sequence_output)
+ sequence_output = self.conv_after_aux(aux)
+ sequence_output = (
+ self.upsample(sequence_output)[:, :, : height * self.upscale, : width * self.upscale]
+ + bicubic[:, :, : height * self.upscale, : width * self.upscale]
+ )
+ reconstruction = self.final_convolution(sequence_output)
+
+ return reconstruction, aux
+
+
+@add_start_docstrings(
+ """
+ Swin2SR Model transformer with an upsampler head on top for image super resolution and restoration.
+ """,
+ SWIN2SR_START_DOCSTRING,
+)
+class Swin2SRForImageSuperResolution(Swin2SRPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.swin2sr = Swin2SRModel(config)
+ self.upsampler = config.upsampler
+ self.upscale = config.upscale
+
+ # Upsampler
+ num_features = 64
+ if self.upsampler == "pixelshuffle":
+ self.upsample = PixelShuffleUpsampler(config, num_features)
+ elif self.upsampler == "pixelshuffle_aux":
+ self.upsample = PixelShuffleAuxUpsampler(config, num_features)
+ elif self.upsampler == "pixelshuffledirect":
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(config.upscale, config.embed_dim, config.num_channels)
+ elif self.upsampler == "nearest+conv":
+ # for real-world SR (less artifacts)
+ self.upsample = NearestConvUpsampler(config, num_features)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.final_convolution = nn.Conv2d(config.embed_dim, config.num_channels, 3, 1, 1)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SWIN2SR_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=ImageSuperResolutionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, ImageSuperResolutionOutput]:
+ r"""
+ Returns:
+
+ Example:
+ ```python
+ >>> import torch
+ >>> from transformers import Swin2SRFeatureExtractor, Swin2SRForImageSuperResolution
+ >>> from datasets import load_dataset
+
+ >>> feature_extractor = Swin2SRFeatureExtractor.from_pretrained("openai/whisper-base")
+ >>> model = Swin2SRForImageSuperResolution.from_pretrained("openai/whisper-base")
+
+ >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ >>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
+ >>> input_features = inputs.input_features
+ >>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
+ >>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
+ >>> list(last_hidden_state.shape)
+ [1, 2, 512]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ height, width = pixel_values.shape[2:]
+
+ if self.config.upsampler == "pixelshuffle_aux":
+ bicubic = nn.functional.interpolate(
+ pixel_values,
+ size=(height * self.upscale, width * self.upscale),
+ mode="bicubic",
+ align_corners=False,
+ )
+
+ outputs = self.swin2sr(
+ pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ if self.upsampler in ["pixelshuffle", "pixelshuffledirect", "nearest+conv"]:
+ reconstruction = self.upsample(sequence_output)
+ elif self.upsampler == "pixelshuffle_aux":
+ reconstruction, aux = self.upsample(sequence_output, bicubic, height, width)
+ aux = aux / self.swin2sr.img_range + self.swin2sr.mean
+ else:
+ reconstruction = pixel_values + self.final_convolution(sequence_output)
+
+ reconstruction = reconstruction / self.swin2sr.img_range + self.swin2sr.mean
+ reconstruction = reconstruction[:, :, : height * self.upscale, : width * self.upscale]
+
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not supported at the moment")
+
+ if not return_dict:
+ output = (reconstruction,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageSuperResolutionOutput(
+ loss=loss,
+ reconstruction=reconstruction,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index 1e839e767f6f..c73afc096607 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -21,7 +21,6 @@
from typing import Optional, Tuple, Union
import torch
-import torch.nn.functional as F
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -494,7 +493,9 @@ def forward(
query_layer = self.transpose_for_scores(mixed_query_layer)
# cosine attention
- attention_scores = F.normalize(query_layer, dim=-1) @ F.normalize(key_layer, dim=-1).transpose(-2, -1)
+ attention_scores = nn.functional.normalize(query_layer, dim=-1) @ nn.functional.normalize(
+ key_layer, dim=-1
+ ).transpose(-2, -1)
logit_scale = torch.clamp(self.logit_scale, max=math.log(1.0 / 0.01)).exp()
attention_scores = attention_scores * logit_scale
relative_position_bias_table = self.continuous_position_bias_mlp(self.relative_coords_table).view(
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e65176d09bf8..2fbcab395fb1 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -5288,6 +5288,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class Swin2SRForImageSuperResolution(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Swin2SRModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Swin2SRPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index b9e0b80d0d76..b8f1b3fa13ef 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -367,6 +367,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class Swin2SRImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class VideoMAEFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/swin2sr/__init__.py b/tests/models/swin2sr/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/models/swin2sr/test_image_processing_swin2sr.py b/tests/models/swin2sr/test_image_processing_swin2sr.py
new file mode 100644
index 000000000000..393a44ecface
--- /dev/null
+++ b/tests/models/swin2sr/test_image_processing_swin2sr.py
@@ -0,0 +1,193 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Swin2SRImageProcessor
+ from transformers.image_transforms import get_image_size
+
+
+class Swin2SRImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ pad_size=8,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.pad_size = pad_size
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ "pad_size": self.pad_size,
+ }
+
+ def prepare_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+ """
+
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ if equal_resolution:
+ image_inputs = []
+ for i in range(self.batch_size):
+ image_inputs.append(
+ np.random.randint(
+ 255, size=(self.num_channels, self.max_resolution, self.max_resolution), dtype=np.uint8
+ )
+ )
+ else:
+ image_inputs = []
+ for i in range(self.batch_size):
+ width, height = np.random.choice(np.arange(self.min_resolution, self.max_resolution), 2)
+ image_inputs.append(np.random.randint(255, size=(self.num_channels, width, height), dtype=np.uint8))
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ if torchify:
+ image_inputs = [torch.from_numpy(x) for x in image_inputs]
+
+ return image_inputs
+
+
+@require_torch
+@require_vision
+class Swin2SRImageProcessingTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = Swin2SRImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = Swin2SRImageProcessingTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "rescale_factor"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
+ self.assertTrue(hasattr(feature_extractor, "pad_size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def calculate_expected_size(self, image):
+ old_height, old_width = get_image_size(image)
+ size = self.feature_extract_tester.pad_size
+
+ pad_height = (old_height // size + 1) * size - old_height
+ pad_width = (old_width // size + 1) * size - old_width
+ return old_height + pad_height, old_width + pad_width
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(np.array(image_inputs[0]))
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(image_inputs[0])
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(image_inputs[0])
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
diff --git a/tests/models/swin2sr/test_modeling_swin2sr.py b/tests/models/swin2sr/test_modeling_swin2sr.py
new file mode 100644
index 000000000000..5bd54d7a79f9
--- /dev/null
+++ b/tests/models/swin2sr/test_modeling_swin2sr.py
@@ -0,0 +1,321 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Swin2SR model. """
+import inspect
+import unittest
+
+from transformers import Swin2SRConfig
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import Swin2SRForImageSuperResolution, Swin2SRModel
+ from transformers.models.swin2sr.modeling_swin2sr import SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Swin2SRImageProcessor
+
+
+class Swin2SRModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ patch_size=1,
+ num_channels=3,
+ embed_dim=16,
+ depths=[1, 2, 1],
+ num_heads=[2, 2, 4],
+ window_size=2,
+ mlp_ratio=2.0,
+ qkv_bias=True,
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ drop_path_rate=0.1,
+ hidden_act="gelu",
+ use_absolute_embeddings=False,
+ patch_norm=True,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ is_training=True,
+ scope=None,
+ use_labels=False,
+ upscale=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.depths = depths
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+ self.qkv_bias = qkv_bias
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_absolute_embeddings = use_absolute_embeddings
+ self.patch_norm = patch_norm
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.is_training = is_training
+ self.scope = scope
+ self.use_labels = use_labels
+ self.upscale = upscale
+
+ # here we set some attributes to make tests pass
+ self.num_hidden_layers = len(depths)
+ self.hidden_size = embed_dim
+ self.seq_length = (image_size // patch_size) ** 2
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return Swin2SRConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ embed_dim=self.embed_dim,
+ depths=self.depths,
+ num_heads=self.num_heads,
+ window_size=self.window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=self.qkv_bias,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ drop_path_rate=self.drop_path_rate,
+ hidden_act=self.hidden_act,
+ use_absolute_embeddings=self.use_absolute_embeddings,
+ path_norm=self.patch_norm,
+ layer_norm_eps=self.layer_norm_eps,
+ initializer_range=self.initializer_range,
+ upscale=self.upscale,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = Swin2SRModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.embed_dim, self.image_size, self.image_size)
+ )
+
+ def create_and_check_for_image_super_resolution(self, config, pixel_values, labels):
+ model = Swin2SRForImageSuperResolution(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ expected_image_size = self.image_size * self.upscale
+ self.parent.assertEqual(
+ result.reconstruction.shape, (self.batch_size, self.num_channels, expected_image_size, expected_image_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class Swin2SRModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (Swin2SRModel, Swin2SRForImageSuperResolution) if is_torch_available() else ()
+
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Swin2SRModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Swin2SRConfig, embed_dim=37)
+
+ def test_config(self):
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_for_image_super_resolution(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_super_resolution(*config_and_inputs)
+
+ @unittest.skip(reason="Swin2SR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Swin2SR does not support training yet")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="Swin2SR does not support training yet")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = Swin2SRModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ # overwriting because of `logit_scale` parameter
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if "logit_scale" in name:
+ continue
+ if param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ expected_num_attentions = len(self.model_tester.depths)
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ window_size_squared = config.window_size**2
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_heads[0], window_size_squared, window_size_squared],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 1, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_heads[0], window_size_squared, window_size_squared],
+ )
+
+
+@require_vision
+@require_torch
+@slow
+class Swin2SRModelIntegrationTest(unittest.TestCase):
+ def test_inference_image_super_resolution_head(self):
+ processor = Swin2SRImageProcessor()
+ model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-classical-sr-x2-64").to(torch_device)
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size([1, 3, 976, 1296])
+ self.assertEqual(outputs.reconstruction.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[0.5458, 0.5546, 0.5638], [0.5526, 0.5565, 0.5651], [0.5396, 0.5426, 0.5621]]
+ ).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.reconstruction[0, 0, :3, :3], expected_slice, atol=1e-4))
diff --git a/utils/check_repo.py b/utils/check_repo.py
index da0d6df8b039..ec6f73134d13 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -146,6 +146,7 @@
# should **not** be the rule.
IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
# models to ignore for model xxx mapping
+ "Swin2SRForImageSuperResolution",
"CLIPSegForImageSegmentation",
"CLIPSegVisionModel",
"CLIPSegTextModel",
+
+ Swin2SR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/mv-lab/swin2sr).
+
+## Resources
+
+Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index f51cb5caf7ae..bcd2e1cebee6 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -373,6 +373,7 @@
"models.splinter": ["SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP", "SplinterConfig", "SplinterTokenizer"],
"models.squeezebert": ["SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "SqueezeBertConfig", "SqueezeBertTokenizer"],
"models.swin": ["SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP", "SwinConfig"],
+ "models.swin2sr": ["SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swin2SRConfig"],
"models.swinv2": ["SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swinv2Config"],
"models.switch_transformers": ["SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP", "SwitchTransformersConfig"],
"models.t5": ["T5_PRETRAINED_CONFIG_ARCHIVE_MAP", "T5Config"],
@@ -779,6 +780,7 @@
_import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
_import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.swin2sr"].append("Swin2SRImageProcessor")
_import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
_import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
_import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
@@ -2087,6 +2089,14 @@
"SwinPreTrainedModel",
]
)
+ _import_structure["models.swin2sr"].extend(
+ [
+ "SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Swin2SRForImageSuperResolution",
+ "Swin2SRModel",
+ "Swin2SRPreTrainedModel",
+ ]
+ )
_import_structure["models.swinv2"].extend(
[
"SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3630,6 +3640,7 @@
from .models.splinter import SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP, SplinterConfig, SplinterTokenizer
from .models.squeezebert import SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, SqueezeBertConfig, SqueezeBertTokenizer
from .models.swin import SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP, SwinConfig
+ from .models.swin2sr import SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP, Swin2SRConfig
from .models.swinv2 import SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP, Swinv2Config
from .models.switch_transformers import SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP, SwitchTransformersConfig
from .models.t5 import T5_PRETRAINED_CONFIG_ARCHIVE_MAP, T5Config
@@ -3978,6 +3989,7 @@
from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.swin2sr import Swin2SRImageProcessor
from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
from .models.vit import ViTFeatureExtractor, ViTImageProcessor
@@ -5052,6 +5064,12 @@
SwinModel,
SwinPreTrainedModel,
)
+ from .models.swin2sr import (
+ SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Swin2SRForImageSuperResolution,
+ Swin2SRModel,
+ Swin2SRPreTrainedModel,
+ )
from .models.swinv2 import (
SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST,
Swinv2ForImageClassification,
diff --git a/src/transformers/modeling_outputs.py b/src/transformers/modeling_outputs.py
index 57a01fa7c69c..1a38d75b4612 100644
--- a/src/transformers/modeling_outputs.py
+++ b/src/transformers/modeling_outputs.py
@@ -1204,6 +1204,34 @@ class DepthEstimatorOutput(ModelOutput):
attentions: Optional[Tuple[torch.FloatTensor]] = None
+@dataclass
+class ImageSuperResolutionOutput(ModelOutput):
+ """
+ Base class for outputs of image super resolution models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Reconstruction loss.
+ reconstruction (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Reconstructed images, possibly upscaled.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states
+ (also called feature maps) of the model at the output of each stage.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ reconstruction: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
@dataclass
class Wav2Vec2BaseModelOutput(ModelOutput):
"""
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 9c73d52fc174..342044e1f38d 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -148,6 +148,7 @@
splinter,
squeezebert,
swin,
+ swin2sr,
swinv2,
switch_transformers,
t5,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 4c7e4280e719..cb079657f839 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -145,6 +145,7 @@
("splinter", "SplinterConfig"),
("squeezebert", "SqueezeBertConfig"),
("swin", "SwinConfig"),
+ ("swin2sr", "Swin2SRConfig"),
("swinv2", "Swinv2Config"),
("switch_transformers", "SwitchTransformersConfig"),
("t5", "T5Config"),
@@ -291,6 +292,7 @@
("splinter", "SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("squeezebert", "SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swin2sr", "SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swinv2", "SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("switch_transformers", "SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("t5", "T5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -459,6 +461,7 @@
("splinter", "Splinter"),
("squeezebert", "SqueezeBERT"),
("swin", "Swin Transformer"),
+ ("swin2sr", "Swin2SR"),
("swinv2", "Swin Transformer V2"),
("switch_transformers", "SwitchTransformers"),
("t5", "T5"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index ea08c0fe8dc5..a2065abe5827 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -73,6 +73,7 @@
("resnet", "ConvNextImageProcessor"),
("segformer", "SegformerImageProcessor"),
("swin", "ViTImageProcessor"),
+ ("swin2sr", "Swin2SRImageProcessor"),
("swinv2", "ViTImageProcessor"),
("table-transformer", "DetrImageProcessor"),
("timesformer", "VideoMAEImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 7fef8a21a03b..ad6285fc011c 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -141,6 +141,7 @@
("splinter", "SplinterModel"),
("squeezebert", "SqueezeBertModel"),
("swin", "SwinModel"),
+ ("swin2sr", "Swin2SRModel"),
("swinv2", "Swinv2Model"),
("switch_transformers", "SwitchTransformersModel"),
("t5", "T5Model"),
diff --git a/src/transformers/models/swin2sr/__init__.py b/src/transformers/models/swin2sr/__init__.py
new file mode 100644
index 000000000000..3b0c885a7dc3
--- /dev/null
+++ b/src/transformers/models/swin2sr/__init__.py
@@ -0,0 +1,80 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_swin2sr": ["SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP", "Swin2SRConfig"],
+}
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_swin2sr"] = [
+ "SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Swin2SRForImageSuperResolution",
+ "Swin2SRModel",
+ "Swin2SRPreTrainedModel",
+ ]
+
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_swin2sr"] = ["Swin2SRImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_swin2sr import SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP, Swin2SRConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_swin2sr import (
+ SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Swin2SRForImageSuperResolution,
+ Swin2SRModel,
+ Swin2SRPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_swin2sr import Swin2SRImageProcessor
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/swin2sr/configuration_swin2sr.py b/src/transformers/models/swin2sr/configuration_swin2sr.py
new file mode 100644
index 000000000000..4547b5848a1b
--- /dev/null
+++ b/src/transformers/models/swin2sr/configuration_swin2sr.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Swin2SR Transformer model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "caidas/swin2sr-classicalsr-x2-64": (
+ "https://huggingface.co/caidas/swin2sr-classicalsr-x2-64/resolve/main/config.json"
+ ),
+}
+
+
+class Swin2SRConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Swin2SRModel`]. It is used to instantiate a Swin
+ Transformer v2 model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the Swin Transformer v2
+ [caidas/swin2sr-classicalsr-x2-64](https://huggingface.co/caidas/swin2sr-classicalsr-x2-64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 64):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 1):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ embed_dim (`int`, *optional*, defaults to 180):
+ Dimensionality of patch embedding.
+ depths (`list(int)`, *optional*, defaults to `[6, 6, 6, 6, 6, 6]`):
+ Depth of each layer in the Transformer encoder.
+ num_heads (`list(int)`, *optional*, defaults to `[6, 6, 6, 6, 6, 6]`):
+ Number of attention heads in each layer of the Transformer encoder.
+ window_size (`int`, *optional*, defaults to 8):
+ Size of windows.
+ mlp_ratio (`float`, *optional*, defaults to 2.0):
+ Ratio of MLP hidden dimensionality to embedding dimensionality.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether or not a learnable bias should be added to the queries, keys and values.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings and encoder.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ drop_path_rate (`float`, *optional*, defaults to 0.1):
+ Stochastic depth rate.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder. If string, `"gelu"`, `"relu"`,
+ `"selu"` and `"gelu_new"` are supported.
+ use_absolute_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether or not to add absolute position embeddings to the patch embeddings.
+ patch_norm (`bool`, *optional*, defaults to `True`):
+ Whether or not to add layer normalization after patch embedding.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ upscale (`int`, *optional*, defaults to 2):
+ The upscale factor for the image. 2/3/4/8 for image super resolution, 1 for denoising and compress artifact
+ reduction
+ img_range (`float`, *optional*, defaults to 1.):
+ The range of the values of the input image.
+ resi_connection (`str`, *optional*, defaults to `"1conv"`):
+ The convolutional block to use before the residual connection in each stage.
+ upsampler (`str`, *optional*, defaults to `"pixelshuffle"`):
+ The reconstruction reconstruction module. Can be 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None.
+
+ Example:
+
+ ```python
+ >>> from transformers import Swin2SRConfig, Swin2SRModel
+
+ >>> # Initializing a Swin2SR caidas/swin2sr-classicalsr-x2-64 style configuration
+ >>> configuration = Swin2SRConfig()
+
+ >>> # Initializing a model (with random weights) from the caidas/swin2sr-classicalsr-x2-64 style configuration
+ >>> model = Swin2SRModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "swin2sr"
+
+ attribute_map = {
+ "hidden_size": "embed_dim",
+ "num_attention_heads": "num_heads",
+ "num_hidden_layers": "num_layers",
+ }
+
+ def __init__(
+ self,
+ image_size=64,
+ patch_size=1,
+ num_channels=3,
+ embed_dim=180,
+ depths=[6, 6, 6, 6, 6, 6],
+ num_heads=[6, 6, 6, 6, 6, 6],
+ window_size=8,
+ mlp_ratio=2.0,
+ qkv_bias=True,
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ drop_path_rate=0.1,
+ hidden_act="gelu",
+ use_absolute_embeddings=False,
+ patch_norm=True,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ upscale=2,
+ img_range=1.0,
+ resi_connection="1conv",
+ upsampler="pixelshuffle",
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.depths = depths
+ self.num_layers = len(depths)
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+ self.qkv_bias = qkv_bias
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_absolute_embeddings = use_absolute_embeddings
+ self.path_norm = patch_norm
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.upscale = upscale
+ self.img_range = img_range
+ self.resi_connection = resi_connection
+ self.upsampler = upsampler
diff --git a/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py b/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
new file mode 100644
index 000000000000..38a11496f7ee
--- /dev/null
+++ b/src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
@@ -0,0 +1,278 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Swin2SR checkpoints from the original repository. URL: https://github.com/mv-lab/swin2sr"""
+
+import argparse
+
+import torch
+from PIL import Image
+from torchvision.transforms import Compose, Normalize, Resize, ToTensor
+
+import requests
+from transformers import Swin2SRConfig, Swin2SRForImageSuperResolution, Swin2SRImageProcessor
+
+
+def get_config(checkpoint_url):
+ config = Swin2SRConfig()
+
+ if "Swin2SR_ClassicalSR_X4_64" in checkpoint_url:
+ config.upscale = 4
+ elif "Swin2SR_CompressedSR_X4_48" in checkpoint_url:
+ config.upscale = 4
+ config.image_size = 48
+ config.upsampler = "pixelshuffle_aux"
+ elif "Swin2SR_Lightweight_X2_64" in checkpoint_url:
+ config.depths = [6, 6, 6, 6]
+ config.embed_dim = 60
+ config.num_heads = [6, 6, 6, 6]
+ config.upsampler = "pixelshuffledirect"
+ elif "Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR" in checkpoint_url:
+ config.upscale = 4
+ config.upsampler = "nearest+conv"
+ elif "Swin2SR_Jpeg_dynamic" in checkpoint_url:
+ config.num_channels = 1
+ config.upscale = 1
+ config.image_size = 126
+ config.window_size = 7
+ config.img_range = 255.0
+ config.upsampler = ""
+
+ return config
+
+
+def rename_key(name, config):
+ if "patch_embed.proj" in name and "layers" not in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ if "patch_embed.norm" in name:
+ name = name.replace("patch_embed.norm", "embeddings.patch_embeddings.layernorm")
+ if "layers" in name:
+ name = name.replace("layers", "encoder.stages")
+ if "residual_group.blocks" in name:
+ name = name.replace("residual_group.blocks", "layers")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "q_bias" in name:
+ name = name.replace("q_bias", "query.bias")
+ if "k_bias" in name:
+ name = name.replace("k_bias", "key.bias")
+ if "v_bias" in name:
+ name = name.replace("v_bias", "value.bias")
+ if "cpb_mlp" in name:
+ name = name.replace("cpb_mlp", "continuous_position_bias_mlp")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "patch_embed.projection")
+
+ if name == "norm.weight":
+ name = "layernorm.weight"
+ if name == "norm.bias":
+ name = "layernorm.bias"
+
+ if "conv_first" in name:
+ name = name.replace("conv_first", "first_convolution")
+
+ if (
+ "upsample" in name
+ or "conv_before_upsample" in name
+ or "conv_bicubic" in name
+ or "conv_up" in name
+ or "conv_hr" in name
+ or "conv_last" in name
+ or "aux" in name
+ ):
+ # heads
+ if "conv_last" in name:
+ name = name.replace("conv_last", "final_convolution")
+ if config.upsampler in ["pixelshuffle", "pixelshuffle_aux", "nearest+conv"]:
+ if "conv_before_upsample.0" in name:
+ name = name.replace("conv_before_upsample.0", "conv_before_upsample")
+ if "upsample.0" in name:
+ name = name.replace("upsample.0", "upsample.convolution_0")
+ if "upsample.2" in name:
+ name = name.replace("upsample.2", "upsample.convolution_1")
+ name = "upsample." + name
+ elif config.upsampler == "pixelshuffledirect":
+ name = name.replace("upsample.0.weight", "upsample.conv.weight")
+ name = name.replace("upsample.0.bias", "upsample.conv.bias")
+ else:
+ pass
+ else:
+ name = "swin2sr." + name
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ stage_num = int(key_split[1])
+ block_num = int(key_split[4])
+ dim = config.embed_dim
+
+ if "weight" in key:
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.query.weight"
+ ] = val[:dim, :]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.key.weight"
+ ] = val[dim : dim * 2, :]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.value.weight"
+ ] = val[-dim:, :]
+ else:
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.query.bias"
+ ] = val[:dim]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.key.bias"
+ ] = val[dim : dim * 2]
+ orig_state_dict[
+ f"swin2sr.encoder.stages.{stage_num}.layers.{block_num}.attention.self.value.bias"
+ ] = val[-dim:]
+ pass
+ else:
+ orig_state_dict[rename_key(key, config)] = val
+
+ return orig_state_dict
+
+
+def convert_swin2sr_checkpoint(checkpoint_url, pytorch_dump_folder_path, push_to_hub):
+ config = get_config(checkpoint_url)
+ model = Swin2SRForImageSuperResolution(config)
+ model.eval()
+
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")
+ new_state_dict = convert_state_dict(state_dict, config)
+ missing_keys, unexpected_keys = model.load_state_dict(new_state_dict, strict=False)
+
+ if len(missing_keys) > 0:
+ raise ValueError("Missing keys when converting: {}".format(missing_keys))
+ for key in unexpected_keys:
+ if not ("relative_position_index" in key or "relative_coords_table" in key or "self_mask" in key):
+ raise ValueError(f"Unexpected key {key} in state_dict")
+
+ # verify values
+ url = "https://github.com/mv-lab/swin2sr/blob/main/testsets/real-inputs/shanghai.jpg?raw=true"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ processor = Swin2SRImageProcessor()
+ # pixel_values = processor(image, return_tensors="pt").pixel_values
+
+ image_size = 126 if "Jpeg" in checkpoint_url else 256
+ transforms = Compose(
+ [
+ Resize((image_size, image_size)),
+ ToTensor(),
+ Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+ ]
+ )
+ pixel_values = transforms(image).unsqueeze(0)
+
+ if config.num_channels == 1:
+ pixel_values = pixel_values[:, 0, :, :].unsqueeze(1)
+
+ outputs = model(pixel_values)
+
+ # assert values
+ if "Swin2SR_ClassicalSR_X2_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 512, 512])
+ expected_slice = torch.tensor(
+ [[-0.7087, -0.7138, -0.6721], [-0.8340, -0.8095, -0.7298], [-0.9149, -0.8414, -0.7940]]
+ )
+ elif "Swin2SR_ClassicalSR_X4_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.7775, -0.8105, -0.8933], [-0.7764, -0.8356, -0.9225], [-0.7976, -0.8686, -0.9579]]
+ )
+ elif "Swin2SR_CompressedSR_X4_48" in checkpoint_url:
+ # TODO values didn't match exactly here
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.8035, -0.7504, -0.7491], [-0.8538, -0.8124, -0.7782], [-0.8804, -0.8651, -0.8493]]
+ )
+ elif "Swin2SR_Lightweight_X2_64" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 512, 512])
+ expected_slice = torch.tensor(
+ [[-0.7669, -0.8662, -0.8767], [-0.8810, -0.9962, -0.9820], [-0.9340, -1.0322, -1.1149]]
+ )
+ elif "Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR" in checkpoint_url:
+ expected_shape = torch.Size([1, 3, 1024, 1024])
+ expected_slice = torch.tensor(
+ [[-0.5238, -0.5557, -0.6321], [-0.6016, -0.5903, -0.6391], [-0.6244, -0.6334, -0.6889]]
+ )
+
+ assert (
+ outputs.reconstruction.shape == expected_shape
+ ), f"Shape of reconstruction should be {expected_shape}, but is {outputs.reconstruction.shape}"
+ assert torch.allclose(outputs.reconstruction[0, 0, :3, :3], expected_slice, atol=1e-3)
+ print("Looks ok!")
+
+ url_to_name = {
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X2_64.pth": (
+ "swin2SR-classical-sr-x2-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X4_64.pth": (
+ "swin2SR-classical-sr-x4-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_CompressedSR_X4_48.pth": (
+ "swin2SR-compressed-sr-x4-48"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_Lightweight_X2_64.pth": (
+ "swin2SR-lightweight-x2-64"
+ ),
+ "https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR.pth": (
+ "swin2SR-realworld-sr-x4-64-bsrgan-psnr"
+ ),
+ }
+ model_name = url_to_name[checkpoint_url]
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving image processor to {pytorch_dump_folder_path}")
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"caidas/{model_name}")
+ processor.push_to_hub(f"caidas/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_ClassicalSR_X2_64.pth",
+ type=str,
+ help="URL of the original Swin2SR checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the converted model to the hub.")
+
+ args = parser.parse_args()
+ convert_swin2sr_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/swin2sr/image_processing_swin2sr.py b/src/transformers/models/swin2sr/image_processing_swin2sr.py
new file mode 100644
index 000000000000..c5c5458d8aa7
--- /dev/null
+++ b/src/transformers/models/swin2sr/image_processing_swin2sr.py
@@ -0,0 +1,175 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Swin2SR."""
+
+from typing import Optional, Union
+
+import numpy as np
+
+from transformers.utils.generic import TensorType
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature
+from ...image_transforms import get_image_size, pad, rescale, to_channel_dimension_format
+from ...image_utils import ChannelDimension, ImageInput, is_batched, to_numpy_array, valid_images
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class Swin2SRImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Swin2SR image processor.
+
+ Args:
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_pad: bool = True,
+ pad_size: int = 8,
+ **kwargs
+ ) -> None:
+ super().__init__(**kwargs)
+
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.pad_size = pad_size
+
+ def rescale(
+ self, image: np.ndarray, scale: float, data_format: Optional[Union[str, ChannelDimension]] = None, **kwargs
+ ) -> np.ndarray:
+ """
+ Rescale an image by a scale factor. image = image * scale.
+
+ Args:
+ image (`np.ndarray`):
+ Image to rescale.
+ scale (`float`):
+ The scaling factor to rescale pixel values by.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+
+ Returns:
+ `np.ndarray`: The rescaled image.
+ """
+ return rescale(image, scale=scale, data_format=data_format, **kwargs)
+
+ def pad(self, image: np.ndarray, size: int, data_format: Optional[Union[str, ChannelDimension]] = None):
+ """
+ Pad an image to make the height and width divisible by `size`.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ size (`int`):
+ The size to make the height and width divisible by.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+
+ Returns:
+ `np.ndarray`: The padded image.
+ """
+ old_height, old_width = get_image_size(image)
+ pad_height = (old_height // size + 1) * size - old_height
+ pad_width = (old_width // size + 1) * size - old_width
+
+ return pad(image, ((0, pad_height), (0, pad_width)), mode="symmetric", data_format=data_format)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_pad: Optional[bool] = None,
+ pad_size: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Whether to pad the image to make the height and width divisible by `window_size`.
+ pad_size (`int`, *optional*, defaults to `32`):
+ The size of the sliding window for the local attention.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ """
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_pad = do_pad if do_pad is not None else self.do_pad
+ pad_size = pad_size if pad_size is not None else self.pad_size
+
+ if not is_batched(images):
+ images = [images]
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image=image, scale=rescale_factor) for image in images]
+
+ if do_pad:
+ images = [self.pad(image, size=pad_size) for image in images]
+
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/swin2sr/modeling_swin2sr.py b/src/transformers/models/swin2sr/modeling_swin2sr.py
new file mode 100644
index 000000000000..0edc2feea883
--- /dev/null
+++ b/src/transformers/models/swin2sr/modeling_swin2sr.py
@@ -0,0 +1,1204 @@
+# coding=utf-8
+# Copyright 2022 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Swin2SR Transformer model."""
+
+
+import collections.abc
+import math
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, ImageSuperResolutionOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_swin2sr import Swin2SRConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "Swin2SRConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "caidas/swin2sr-classicalsr-x2-64"
+_EXPECTED_OUTPUT_SHAPE = [1, 64, 768]
+
+
+SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "caidas/swin2SR-classical-sr-x2-64",
+ # See all Swin2SR models at https://huggingface.co/models?filter=swin2sr
+]
+
+
+@dataclass
+class Swin2SREncoderOutput(ModelOutput):
+ """
+ Swin2SR encoder's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each stage) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Copied from transformers.models.swin.modeling_swin.window_partition
+def window_partition(input_feature, window_size):
+ """
+ Partitions the given input into windows.
+ """
+ batch_size, height, width, num_channels = input_feature.shape
+ input_feature = input_feature.view(
+ batch_size, height // window_size, window_size, width // window_size, window_size, num_channels
+ )
+ windows = input_feature.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, num_channels)
+ return windows
+
+
+# Copied from transformers.models.swin.modeling_swin.window_reverse
+def window_reverse(windows, window_size, height, width):
+ """
+ Merges windows to produce higher resolution features.
+ """
+ num_channels = windows.shape[-1]
+ windows = windows.view(-1, height // window_size, width // window_size, window_size, window_size, num_channels)
+ windows = windows.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, height, width, num_channels)
+ return windows
+
+
+# Copied from transformers.models.swin.modeling_swin.drop_path
+def drop_path(input, drop_prob=0.0, training=False, scale_by_keep=True):
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinDropPath with Swin->Swin2SR
+class Swin2SRDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+class Swin2SREmbeddings(nn.Module):
+ """
+ Construct the patch and optional position embeddings.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.patch_embeddings = Swin2SRPatchEmbeddings(config)
+ num_patches = self.patch_embeddings.num_patches
+
+ if config.use_absolute_embeddings:
+ self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
+ else:
+ self.position_embeddings = None
+
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.window_size = config.window_size
+
+ def forward(self, pixel_values: Optional[torch.FloatTensor]) -> Tuple[torch.Tensor]:
+ embeddings, output_dimensions = self.patch_embeddings(pixel_values)
+
+ if self.position_embeddings is not None:
+ embeddings = embeddings + self.position_embeddings
+
+ embeddings = self.dropout(embeddings)
+
+ return embeddings, output_dimensions
+
+
+class Swin2SRPatchEmbeddings(nn.Module):
+ def __init__(self, config, normalize_patches=True):
+ super().__init__()
+ num_channels = config.embed_dim
+ image_size, patch_size = config.image_size, config.patch_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ patches_resolution = [image_size[0] // patch_size[0], image_size[1] // patch_size[1]]
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.projection = nn.Conv2d(num_channels, config.embed_dim, kernel_size=patch_size, stride=patch_size)
+ self.layernorm = nn.LayerNorm(config.embed_dim) if normalize_patches else None
+
+ def forward(self, embeddings: Optional[torch.FloatTensor]) -> Tuple[torch.Tensor, Tuple[int]]:
+ embeddings = self.projection(embeddings)
+ _, _, height, width = embeddings.shape
+ output_dimensions = (height, width)
+ embeddings = embeddings.flatten(2).transpose(1, 2)
+
+ if self.layernorm is not None:
+ embeddings = self.layernorm(embeddings)
+
+ return embeddings, output_dimensions
+
+
+class Swin2SRPatchUnEmbeddings(nn.Module):
+ r"""Image to Patch Unembedding"""
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.embed_dim = config.embed_dim
+
+ def forward(self, embeddings, x_size):
+ batch_size, height_width, num_channels = embeddings.shape
+ embeddings = embeddings.transpose(1, 2).view(batch_size, self.embed_dim, x_size[0], x_size[1]) # B Ph*Pw C
+ return embeddings
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2PatchMerging with Swinv2->Swin2SR
+class Swin2SRPatchMerging(nn.Module):
+ """
+ Patch Merging Layer.
+
+ Args:
+ input_resolution (`Tuple[int]`):
+ Resolution of input feature.
+ dim (`int`):
+ Number of input channels.
+ norm_layer (`nn.Module`, *optional*, defaults to `nn.LayerNorm`):
+ Normalization layer class.
+ """
+
+ def __init__(self, input_resolution: Tuple[int], dim: int, norm_layer: nn.Module = nn.LayerNorm) -> None:
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(2 * dim)
+
+ def maybe_pad(self, input_feature, height, width):
+ should_pad = (height % 2 == 1) or (width % 2 == 1)
+ if should_pad:
+ pad_values = (0, 0, 0, width % 2, 0, height % 2)
+ input_feature = nn.functional.pad(input_feature, pad_values)
+
+ return input_feature
+
+ def forward(self, input_feature: torch.Tensor, input_dimensions: Tuple[int, int]) -> torch.Tensor:
+ height, width = input_dimensions
+ # `dim` is height * width
+ batch_size, dim, num_channels = input_feature.shape
+
+ input_feature = input_feature.view(batch_size, height, width, num_channels)
+ # pad input to be disible by width and height, if needed
+ input_feature = self.maybe_pad(input_feature, height, width)
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_0 = input_feature[:, 0::2, 0::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_1 = input_feature[:, 1::2, 0::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_2 = input_feature[:, 0::2, 1::2, :]
+ # [batch_size, height/2, width/2, num_channels]
+ input_feature_3 = input_feature[:, 1::2, 1::2, :]
+ # [batch_size, height/2 * width/2, 4*num_channels]
+ input_feature = torch.cat([input_feature_0, input_feature_1, input_feature_2, input_feature_3], -1)
+ input_feature = input_feature.view(batch_size, -1, 4 * num_channels) # [batch_size, height/2 * width/2, 4*C]
+
+ input_feature = self.reduction(input_feature)
+ input_feature = self.norm(input_feature)
+
+ return input_feature
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2SelfAttention with Swinv2->Swin2SR
+class Swin2SRSelfAttention(nn.Module):
+ def __init__(self, config, dim, num_heads, window_size, pretrained_window_size=[0, 0]):
+ super().__init__()
+ if dim % num_heads != 0:
+ raise ValueError(
+ f"The hidden size ({dim}) is not a multiple of the number of attention heads ({num_heads})"
+ )
+
+ self.num_attention_heads = num_heads
+ self.attention_head_size = int(dim / num_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+ self.window_size = (
+ window_size if isinstance(window_size, collections.abc.Iterable) else (window_size, window_size)
+ )
+ self.pretrained_window_size = pretrained_window_size
+ self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
+ # mlp to generate continuous relative position bias
+ self.continuous_position_bias_mlp = nn.Sequential(
+ nn.Linear(2, 512, bias=True), nn.ReLU(inplace=True), nn.Linear(512, num_heads, bias=False)
+ )
+
+ # get relative_coords_table
+ relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
+ relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
+ relative_coords_table = (
+ torch.stack(meshgrid([relative_coords_h, relative_coords_w], indexing="ij"))
+ .permute(1, 2, 0)
+ .contiguous()
+ .unsqueeze(0)
+ ) # [1, 2*window_height - 1, 2*window_width - 1, 2]
+ if pretrained_window_size[0] > 0:
+ relative_coords_table[:, :, :, 0] /= pretrained_window_size[0] - 1
+ relative_coords_table[:, :, :, 1] /= pretrained_window_size[1] - 1
+ else:
+ relative_coords_table[:, :, :, 0] /= self.window_size[0] - 1
+ relative_coords_table[:, :, :, 1] /= self.window_size[1] - 1
+ relative_coords_table *= 8 # normalize to -8, 8
+ relative_coords_table = (
+ torch.sign(relative_coords_table) * torch.log2(torch.abs(relative_coords_table) + 1.0) / math.log2(8)
+ )
+ self.register_buffer("relative_coords_table", relative_coords_table, persistent=False)
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij"))
+ coords_flatten = torch.flatten(coords, 1)
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous()
+ relative_coords[:, :, 0] += self.window_size[0] - 1
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1)
+ self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+
+ self.query = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(self.all_head_size, self.all_head_size, bias=False)
+ self.value = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ batch_size, dim, num_channels = hidden_states.shape
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # cosine attention
+ attention_scores = nn.functional.normalize(query_layer, dim=-1) @ nn.functional.normalize(
+ key_layer, dim=-1
+ ).transpose(-2, -1)
+ logit_scale = torch.clamp(self.logit_scale, max=math.log(1.0 / 0.01)).exp()
+ attention_scores = attention_scores * logit_scale
+ relative_position_bias_table = self.continuous_position_bias_mlp(self.relative_coords_table).view(
+ -1, self.num_attention_heads
+ )
+ # [window_height*window_width,window_height*window_width,num_attention_heads]
+ relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
+ )
+ # [num_attention_heads,window_height*window_width,window_height*window_width]
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
+ attention_scores = attention_scores + relative_position_bias.unsqueeze(0)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in Swin2SRModel forward() function)
+ mask_shape = attention_mask.shape[0]
+ attention_scores = attention_scores.view(
+ batch_size // mask_shape, mask_shape, self.num_attention_heads, dim, dim
+ ) + attention_mask.unsqueeze(1).unsqueeze(0)
+ attention_scores = attention_scores + attention_mask.unsqueeze(1).unsqueeze(0)
+ attention_scores = attention_scores.view(-1, self.num_attention_heads, dim, dim)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinSelfOutput with Swin->Swin2SR
+class Swin2SRSelfOutput(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(dim, dim)
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2Attention with Swinv2->Swin2SR
+class Swin2SRAttention(nn.Module):
+ def __init__(self, config, dim, num_heads, window_size, pretrained_window_size=0):
+ super().__init__()
+ self.self = Swin2SRSelfAttention(
+ config=config,
+ dim=dim,
+ num_heads=num_heads,
+ window_size=window_size,
+ pretrained_window_size=pretrained_window_size
+ if isinstance(pretrained_window_size, collections.abc.Iterable)
+ else (pretrained_window_size, pretrained_window_size),
+ )
+ self.output = Swin2SRSelfOutput(config, dim)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(hidden_states, attention_mask, head_mask, output_attentions)
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinIntermediate with Swin->Swin2SR
+class Swin2SRIntermediate(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(dim, int(config.mlp_ratio * dim))
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.swin.modeling_swin.SwinOutput with Swin->Swin2SR
+class Swin2SROutput(nn.Module):
+ def __init__(self, config, dim):
+ super().__init__()
+ self.dense = nn.Linear(int(config.mlp_ratio * dim), dim)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.swinv2.modeling_swinv2.Swinv2Layer with Swinv2->Swin2SR
+class Swin2SRLayer(nn.Module):
+ def __init__(self, config, dim, input_resolution, num_heads, shift_size=0, pretrained_window_size=0):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.shift_size = shift_size
+ self.window_size = config.window_size
+ self.input_resolution = input_resolution
+ self.set_shift_and_window_size(input_resolution)
+ self.attention = Swin2SRAttention(
+ config=config,
+ dim=dim,
+ num_heads=num_heads,
+ window_size=self.window_size,
+ pretrained_window_size=pretrained_window_size
+ if isinstance(pretrained_window_size, collections.abc.Iterable)
+ else (pretrained_window_size, pretrained_window_size),
+ )
+ self.layernorm_before = nn.LayerNorm(dim, eps=config.layer_norm_eps)
+ self.drop_path = Swin2SRDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
+ self.intermediate = Swin2SRIntermediate(config, dim)
+ self.output = Swin2SROutput(config, dim)
+ self.layernorm_after = nn.LayerNorm(dim, eps=config.layer_norm_eps)
+
+ def set_shift_and_window_size(self, input_resolution):
+ target_window_size = (
+ self.window_size
+ if isinstance(self.window_size, collections.abc.Iterable)
+ else (self.window_size, self.window_size)
+ )
+ target_shift_size = (
+ self.shift_size
+ if isinstance(self.shift_size, collections.abc.Iterable)
+ else (self.shift_size, self.shift_size)
+ )
+ self.window_size = (
+ input_resolution[0] if input_resolution[0] <= target_window_size[0] else target_window_size[0]
+ )
+ self.shift_size = (
+ 0
+ if input_resolution
+ <= (
+ self.window_size
+ if isinstance(self.window_size, collections.abc.Iterable)
+ else (self.window_size, self.window_size)
+ )
+ else target_shift_size[0]
+ )
+
+ def get_attn_mask(self, height, width, dtype):
+ if self.shift_size > 0:
+ # calculate attention mask for shifted window multihead self attention
+ img_mask = torch.zeros((1, height, width, 1), dtype=dtype)
+ height_slices = (
+ slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None),
+ )
+ width_slices = (
+ slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None),
+ )
+ count = 0
+ for height_slice in height_slices:
+ for width_slice in width_slices:
+ img_mask[:, height_slice, width_slice, :] = count
+ count += 1
+
+ mask_windows = window_partition(img_mask, self.window_size)
+ mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+ else:
+ attn_mask = None
+ return attn_mask
+
+ def maybe_pad(self, hidden_states, height, width):
+ pad_right = (self.window_size - width % self.window_size) % self.window_size
+ pad_bottom = (self.window_size - height % self.window_size) % self.window_size
+ pad_values = (0, 0, 0, pad_right, 0, pad_bottom)
+ hidden_states = nn.functional.pad(hidden_states, pad_values)
+ return hidden_states, pad_values
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ self.set_shift_and_window_size(input_dimensions)
+ height, width = input_dimensions
+ batch_size, _, channels = hidden_states.size()
+ shortcut = hidden_states
+
+ # pad hidden_states to multiples of window size
+ hidden_states = hidden_states.view(batch_size, height, width, channels)
+ hidden_states, pad_values = self.maybe_pad(hidden_states, height, width)
+ _, height_pad, width_pad, _ = hidden_states.shape
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_hidden_states = torch.roll(hidden_states, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_hidden_states = hidden_states
+
+ # partition windows
+ hidden_states_windows = window_partition(shifted_hidden_states, self.window_size)
+ hidden_states_windows = hidden_states_windows.view(-1, self.window_size * self.window_size, channels)
+ attn_mask = self.get_attn_mask(height_pad, width_pad, dtype=hidden_states.dtype)
+ if attn_mask is not None:
+ attn_mask = attn_mask.to(hidden_states_windows.device)
+
+ attention_outputs = self.attention(
+ hidden_states_windows, attn_mask, head_mask, output_attentions=output_attentions
+ )
+
+ attention_output = attention_outputs[0]
+
+ attention_windows = attention_output.view(-1, self.window_size, self.window_size, channels)
+ shifted_windows = window_reverse(attention_windows, self.window_size, height_pad, width_pad)
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ attention_windows = torch.roll(shifted_windows, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
+ else:
+ attention_windows = shifted_windows
+
+ was_padded = pad_values[3] > 0 or pad_values[5] > 0
+ if was_padded:
+ attention_windows = attention_windows[:, :height, :width, :].contiguous()
+
+ attention_windows = attention_windows.view(batch_size, height * width, channels)
+ hidden_states = self.layernorm_before(attention_windows)
+ hidden_states = shortcut + self.drop_path(hidden_states)
+
+ layer_output = self.intermediate(hidden_states)
+ layer_output = self.output(layer_output)
+ layer_output = hidden_states + self.drop_path(self.layernorm_after(layer_output))
+
+ layer_outputs = (layer_output, attention_outputs[1]) if output_attentions else (layer_output,)
+ return layer_outputs
+
+
+class Swin2SRStage(nn.Module):
+ """
+ This corresponds to the Residual Swin Transformer Block (RSTB) in the original implementation.
+ """
+
+ def __init__(self, config, dim, input_resolution, depth, num_heads, drop_path, pretrained_window_size=0):
+ super().__init__()
+ self.config = config
+ self.dim = dim
+ self.layers = nn.ModuleList(
+ [
+ Swin2SRLayer(
+ config=config,
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ shift_size=0 if (i % 2 == 0) else config.window_size // 2,
+ pretrained_window_size=pretrained_window_size,
+ )
+ for i in range(depth)
+ ]
+ )
+
+ if config.resi_connection == "1conv":
+ self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
+ elif config.resi_connection == "3conv":
+ # to save parameters and memory
+ self.conv = nn.Sequential(
+ nn.Conv2d(dim, dim // 4, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim, 3, 1, 1),
+ )
+
+ self.patch_embed = Swin2SRPatchEmbeddings(config, normalize_patches=False)
+
+ self.patch_unembed = Swin2SRPatchUnEmbeddings(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ residual = hidden_states
+
+ height, width = input_dimensions
+ for i, layer_module in enumerate(self.layers):
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ layer_outputs = layer_module(hidden_states, input_dimensions, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ output_dimensions = (height, width, height, width)
+
+ hidden_states = self.patch_unembed(hidden_states, input_dimensions)
+ hidden_states = self.conv(hidden_states)
+ hidden_states, _ = self.patch_embed(hidden_states)
+
+ hidden_states = hidden_states + residual
+
+ stage_outputs = (hidden_states, output_dimensions)
+
+ if output_attentions:
+ stage_outputs += layer_outputs[1:]
+ return stage_outputs
+
+
+class Swin2SREncoder(nn.Module):
+ def __init__(self, config, grid_size):
+ super().__init__()
+ self.num_stages = len(config.depths)
+ self.config = config
+ dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+ self.stages = nn.ModuleList(
+ [
+ Swin2SRStage(
+ config=config,
+ dim=config.embed_dim,
+ input_resolution=(grid_size[0], grid_size[1]),
+ depth=config.depths[stage_idx],
+ num_heads=config.num_heads[stage_idx],
+ drop_path=dpr[sum(config.depths[:stage_idx]) : sum(config.depths[: stage_idx + 1])],
+ pretrained_window_size=0,
+ )
+ for stage_idx in range(self.num_stages)
+ ]
+ )
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ input_dimensions: Tuple[int, int],
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple, Swin2SREncoderOutput]:
+ all_input_dimensions = ()
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ for i, stage_module in enumerate(self.stages):
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(stage_module), hidden_states, input_dimensions, layer_head_mask
+ )
+ else:
+ layer_outputs = stage_module(hidden_states, input_dimensions, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+ output_dimensions = layer_outputs[1]
+
+ input_dimensions = (output_dimensions[-2], output_dimensions[-1])
+ all_input_dimensions += (input_dimensions,)
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if output_attentions:
+ all_self_attentions += layer_outputs[2:]
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+
+ return Swin2SREncoderOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class Swin2SRPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = Swin2SRConfig
+ base_model_prefix = "swin2sr"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ torch.nn.init.trunc_normal_(module.weight.data, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, Swin2SREncoder):
+ module.gradient_checkpointing = value
+
+
+SWIN2SR_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
+ it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`Swin2SRConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+SWIN2SR_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Swin2SR Model transformer outputting raw hidden-states without any specific head on top.",
+ SWIN2SR_START_DOCSTRING,
+)
+class Swin2SRModel(Swin2SRPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ if config.num_channels == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+ else:
+ self.mean = torch.zeros(1, 1, 1, 1)
+ self.img_range = config.img_range
+
+ self.first_convolution = nn.Conv2d(config.num_channels, config.embed_dim, 3, 1, 1)
+ self.embeddings = Swin2SREmbeddings(config)
+ self.encoder = Swin2SREncoder(config, grid_size=self.embeddings.patch_embeddings.patches_resolution)
+
+ self.layernorm = nn.LayerNorm(config.embed_dim, eps=config.layer_norm_eps)
+ self.patch_unembed = Swin2SRPatchUnEmbeddings(config)
+ self.conv_after_body = nn.Conv2d(config.embed_dim, config.embed_dim, 3, 1, 1)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def pad_and_normalize(self, pixel_values):
+ _, _, height, width = pixel_values.size()
+
+ # 1. pad
+ window_size = self.config.window_size
+ modulo_pad_height = (window_size - height % window_size) % window_size
+ modulo_pad_width = (window_size - width % window_size) % window_size
+ pixel_values = nn.functional.pad(pixel_values, (0, modulo_pad_width, 0, modulo_pad_height), "reflect")
+
+ # 2. normalize
+ self.mean = self.mean.type_as(pixel_values)
+ pixel_values = (pixel_values - self.mean) * self.img_range
+
+ return pixel_values
+
+ @add_start_docstrings_to_model_forward(SWIN2SR_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, len(self.config.depths))
+
+ _, _, height, width = pixel_values.shape
+
+ # some preprocessing: padding + normalization
+ pixel_values = self.pad_and_normalize(pixel_values)
+
+ embeddings = self.first_convolution(pixel_values)
+ embedding_output, input_dimensions = self.embeddings(embeddings)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ input_dimensions,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ sequence_output = self.patch_unembed(sequence_output, (height, width))
+ sequence_output = self.conv_after_body(sequence_output) + embeddings
+
+ if not return_dict:
+ output = (sequence_output,) + encoder_outputs[1:]
+
+ return output
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class Upsample(nn.Module):
+ """Upsample module.
+
+ Args:
+ scale (`int`):
+ Scale factor. Supported scales: 2^n and 3.
+ num_features (`int`):
+ Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_features):
+ super().__init__()
+
+ self.scale = scale
+ if (scale & (scale - 1)) == 0:
+ # scale = 2^n
+ for i in range(int(math.log(scale, 2))):
+ self.add_module(f"convolution_{i}", nn.Conv2d(num_features, 4 * num_features, 3, 1, 1))
+ self.add_module(f"pixelshuffle_{i}", nn.PixelShuffle(2))
+ elif scale == 3:
+ self.convolution = nn.Conv2d(num_features, 9 * num_features, 3, 1, 1)
+ self.pixelshuffle = nn.PixelShuffle(3)
+ else:
+ raise ValueError(f"Scale {scale} is not supported. Supported scales: 2^n and 3.")
+
+ def forward(self, hidden_state):
+ if (self.scale & (self.scale - 1)) == 0:
+ for i in range(int(math.log(self.scale, 2))):
+ hidden_state = self.__getattr__(f"convolution_{i}")(hidden_state)
+ hidden_state = self.__getattr__(f"pixelshuffle_{i}")(hidden_state)
+
+ elif self.scale == 3:
+ hidden_state = self.convolution(hidden_state)
+ hidden_state = self.pixelshuffle(hidden_state)
+
+ return hidden_state
+
+
+class UpsampleOneStep(nn.Module):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+
+ Used in lightweight SR to save parameters.
+
+ Args:
+ scale (int):
+ Scale factor. Supported scales: 2^n and 3.
+ in_channels (int):
+ Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, in_channels, out_channels):
+ super().__init__()
+
+ self.conv = nn.Conv2d(in_channels, (scale**2) * out_channels, 3, 1, 1)
+ self.pixel_shuffle = nn.PixelShuffle(scale)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.pixel_shuffle(x)
+
+ return x
+
+
+class PixelShuffleUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.upsample = Upsample(config.upscale, num_features)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+
+ def forward(self, sequence_output):
+ x = self.conv_before_upsample(sequence_output)
+ x = self.activation(x)
+ x = self.upsample(x)
+ x = self.final_convolution(x)
+
+ return x
+
+
+class NearestConvUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+ if config.upscale != 4:
+ raise ValueError("The nearest+conv upsampler only supports an upscale factor of 4 at the moment.")
+
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.conv_up1 = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_features, num_features, 3, 1, 1)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, sequence_output):
+ sequence_output = self.conv_before_upsample(sequence_output)
+ sequence_output = self.activation(sequence_output)
+ sequence_output = self.lrelu(
+ self.conv_up1(torch.nn.functional.interpolate(sequence_output, scale_factor=2, mode="nearest"))
+ )
+ sequence_output = self.lrelu(
+ self.conv_up2(torch.nn.functional.interpolate(sequence_output, scale_factor=2, mode="nearest"))
+ )
+ reconstruction = self.final_convolution(self.lrelu(self.conv_hr(sequence_output)))
+ return reconstruction
+
+
+class PixelShuffleAuxUpsampler(nn.Module):
+ def __init__(self, config, num_features):
+ super().__init__()
+
+ self.upscale = config.upscale
+ self.conv_bicubic = nn.Conv2d(config.num_channels, num_features, 3, 1, 1)
+ self.conv_before_upsample = nn.Conv2d(config.embed_dim, num_features, 3, 1, 1)
+ self.activation = nn.LeakyReLU(inplace=True)
+ self.conv_aux = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+ self.conv_after_aux = nn.Sequential(nn.Conv2d(3, num_features, 3, 1, 1), nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(config.upscale, num_features)
+ self.final_convolution = nn.Conv2d(num_features, config.num_channels, 3, 1, 1)
+
+ def forward(self, sequence_output, bicubic, height, width):
+ bicubic = self.conv_bicubic(bicubic)
+ sequence_output = self.conv_before_upsample(sequence_output)
+ sequence_output = self.activation(sequence_output)
+ aux = self.conv_aux(sequence_output)
+ sequence_output = self.conv_after_aux(aux)
+ sequence_output = (
+ self.upsample(sequence_output)[:, :, : height * self.upscale, : width * self.upscale]
+ + bicubic[:, :, : height * self.upscale, : width * self.upscale]
+ )
+ reconstruction = self.final_convolution(sequence_output)
+
+ return reconstruction, aux
+
+
+@add_start_docstrings(
+ """
+ Swin2SR Model transformer with an upsampler head on top for image super resolution and restoration.
+ """,
+ SWIN2SR_START_DOCSTRING,
+)
+class Swin2SRForImageSuperResolution(Swin2SRPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.swin2sr = Swin2SRModel(config)
+ self.upsampler = config.upsampler
+ self.upscale = config.upscale
+
+ # Upsampler
+ num_features = 64
+ if self.upsampler == "pixelshuffle":
+ self.upsample = PixelShuffleUpsampler(config, num_features)
+ elif self.upsampler == "pixelshuffle_aux":
+ self.upsample = PixelShuffleAuxUpsampler(config, num_features)
+ elif self.upsampler == "pixelshuffledirect":
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(config.upscale, config.embed_dim, config.num_channels)
+ elif self.upsampler == "nearest+conv":
+ # for real-world SR (less artifacts)
+ self.upsample = NearestConvUpsampler(config, num_features)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.final_convolution = nn.Conv2d(config.embed_dim, config.num_channels, 3, 1, 1)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SWIN2SR_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=ImageSuperResolutionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, ImageSuperResolutionOutput]:
+ r"""
+ Returns:
+
+ Example:
+ ```python
+ >>> import torch
+ >>> from transformers import Swin2SRFeatureExtractor, Swin2SRForImageSuperResolution
+ >>> from datasets import load_dataset
+
+ >>> feature_extractor = Swin2SRFeatureExtractor.from_pretrained("openai/whisper-base")
+ >>> model = Swin2SRForImageSuperResolution.from_pretrained("openai/whisper-base")
+
+ >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ >>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
+ >>> input_features = inputs.input_features
+ >>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
+ >>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
+ >>> list(last_hidden_state.shape)
+ [1, 2, 512]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ height, width = pixel_values.shape[2:]
+
+ if self.config.upsampler == "pixelshuffle_aux":
+ bicubic = nn.functional.interpolate(
+ pixel_values,
+ size=(height * self.upscale, width * self.upscale),
+ mode="bicubic",
+ align_corners=False,
+ )
+
+ outputs = self.swin2sr(
+ pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ if self.upsampler in ["pixelshuffle", "pixelshuffledirect", "nearest+conv"]:
+ reconstruction = self.upsample(sequence_output)
+ elif self.upsampler == "pixelshuffle_aux":
+ reconstruction, aux = self.upsample(sequence_output, bicubic, height, width)
+ aux = aux / self.swin2sr.img_range + self.swin2sr.mean
+ else:
+ reconstruction = pixel_values + self.final_convolution(sequence_output)
+
+ reconstruction = reconstruction / self.swin2sr.img_range + self.swin2sr.mean
+ reconstruction = reconstruction[:, :, : height * self.upscale, : width * self.upscale]
+
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not supported at the moment")
+
+ if not return_dict:
+ output = (reconstruction,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageSuperResolutionOutput(
+ loss=loss,
+ reconstruction=reconstruction,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index 1e839e767f6f..c73afc096607 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -21,7 +21,6 @@
from typing import Optional, Tuple, Union
import torch
-import torch.nn.functional as F
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -494,7 +493,9 @@ def forward(
query_layer = self.transpose_for_scores(mixed_query_layer)
# cosine attention
- attention_scores = F.normalize(query_layer, dim=-1) @ F.normalize(key_layer, dim=-1).transpose(-2, -1)
+ attention_scores = nn.functional.normalize(query_layer, dim=-1) @ nn.functional.normalize(
+ key_layer, dim=-1
+ ).transpose(-2, -1)
logit_scale = torch.clamp(self.logit_scale, max=math.log(1.0 / 0.01)).exp()
attention_scores = attention_scores * logit_scale
relative_position_bias_table = self.continuous_position_bias_mlp(self.relative_coords_table).view(
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e65176d09bf8..2fbcab395fb1 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -5288,6 +5288,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class Swin2SRForImageSuperResolution(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Swin2SRModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Swin2SRPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index b9e0b80d0d76..b8f1b3fa13ef 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -367,6 +367,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class Swin2SRImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class VideoMAEFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/swin2sr/__init__.py b/tests/models/swin2sr/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/models/swin2sr/test_image_processing_swin2sr.py b/tests/models/swin2sr/test_image_processing_swin2sr.py
new file mode 100644
index 000000000000..393a44ecface
--- /dev/null
+++ b/tests/models/swin2sr/test_image_processing_swin2sr.py
@@ -0,0 +1,193 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Swin2SRImageProcessor
+ from transformers.image_transforms import get_image_size
+
+
+class Swin2SRImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ pad_size=8,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.pad_size = pad_size
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ "pad_size": self.pad_size,
+ }
+
+ def prepare_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+ """
+
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ if equal_resolution:
+ image_inputs = []
+ for i in range(self.batch_size):
+ image_inputs.append(
+ np.random.randint(
+ 255, size=(self.num_channels, self.max_resolution, self.max_resolution), dtype=np.uint8
+ )
+ )
+ else:
+ image_inputs = []
+ for i in range(self.batch_size):
+ width, height = np.random.choice(np.arange(self.min_resolution, self.max_resolution), 2)
+ image_inputs.append(np.random.randint(255, size=(self.num_channels, width, height), dtype=np.uint8))
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ if torchify:
+ image_inputs = [torch.from_numpy(x) for x in image_inputs]
+
+ return image_inputs
+
+
+@require_torch
+@require_vision
+class Swin2SRImageProcessingTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = Swin2SRImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = Swin2SRImageProcessingTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "rescale_factor"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
+ self.assertTrue(hasattr(feature_extractor, "pad_size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def calculate_expected_size(self, image):
+ old_height, old_width = get_image_size(image)
+ size = self.feature_extract_tester.pad_size
+
+ pad_height = (old_height // size + 1) * size - old_height
+ pad_width = (old_width // size + 1) * size - old_width
+ return old_height + pad_height, old_width + pad_width
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(np.array(image_inputs[0]))
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(image_inputs[0])
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = self.feature_extract_tester.prepare_inputs(equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ expected_height, expected_width = self.calculate_expected_size(image_inputs[0])
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
diff --git a/tests/models/swin2sr/test_modeling_swin2sr.py b/tests/models/swin2sr/test_modeling_swin2sr.py
new file mode 100644
index 000000000000..5bd54d7a79f9
--- /dev/null
+++ b/tests/models/swin2sr/test_modeling_swin2sr.py
@@ -0,0 +1,321 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Swin2SR model. """
+import inspect
+import unittest
+
+from transformers import Swin2SRConfig
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import Swin2SRForImageSuperResolution, Swin2SRModel
+ from transformers.models.swin2sr.modeling_swin2sr import SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Swin2SRImageProcessor
+
+
+class Swin2SRModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ patch_size=1,
+ num_channels=3,
+ embed_dim=16,
+ depths=[1, 2, 1],
+ num_heads=[2, 2, 4],
+ window_size=2,
+ mlp_ratio=2.0,
+ qkv_bias=True,
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ drop_path_rate=0.1,
+ hidden_act="gelu",
+ use_absolute_embeddings=False,
+ patch_norm=True,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ is_training=True,
+ scope=None,
+ use_labels=False,
+ upscale=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.depths = depths
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+ self.qkv_bias = qkv_bias
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_absolute_embeddings = use_absolute_embeddings
+ self.patch_norm = patch_norm
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.is_training = is_training
+ self.scope = scope
+ self.use_labels = use_labels
+ self.upscale = upscale
+
+ # here we set some attributes to make tests pass
+ self.num_hidden_layers = len(depths)
+ self.hidden_size = embed_dim
+ self.seq_length = (image_size // patch_size) ** 2
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return Swin2SRConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ embed_dim=self.embed_dim,
+ depths=self.depths,
+ num_heads=self.num_heads,
+ window_size=self.window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=self.qkv_bias,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ drop_path_rate=self.drop_path_rate,
+ hidden_act=self.hidden_act,
+ use_absolute_embeddings=self.use_absolute_embeddings,
+ path_norm=self.patch_norm,
+ layer_norm_eps=self.layer_norm_eps,
+ initializer_range=self.initializer_range,
+ upscale=self.upscale,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = Swin2SRModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.embed_dim, self.image_size, self.image_size)
+ )
+
+ def create_and_check_for_image_super_resolution(self, config, pixel_values, labels):
+ model = Swin2SRForImageSuperResolution(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ expected_image_size = self.image_size * self.upscale
+ self.parent.assertEqual(
+ result.reconstruction.shape, (self.batch_size, self.num_channels, expected_image_size, expected_image_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class Swin2SRModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (Swin2SRModel, Swin2SRForImageSuperResolution) if is_torch_available() else ()
+
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Swin2SRModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Swin2SRConfig, embed_dim=37)
+
+ def test_config(self):
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_for_image_super_resolution(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_super_resolution(*config_and_inputs)
+
+ @unittest.skip(reason="Swin2SR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Swin2SR does not support training yet")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="Swin2SR does not support training yet")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = Swin2SRModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ # overwriting because of `logit_scale` parameter
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if "logit_scale" in name:
+ continue
+ if param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ expected_num_attentions = len(self.model_tester.depths)
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ window_size_squared = config.window_size**2
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_heads[0], window_size_squared, window_size_squared],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 1, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_heads[0], window_size_squared, window_size_squared],
+ )
+
+
+@require_vision
+@require_torch
+@slow
+class Swin2SRModelIntegrationTest(unittest.TestCase):
+ def test_inference_image_super_resolution_head(self):
+ processor = Swin2SRImageProcessor()
+ model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-classical-sr-x2-64").to(torch_device)
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size([1, 3, 976, 1296])
+ self.assertEqual(outputs.reconstruction.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[0.5458, 0.5546, 0.5638], [0.5526, 0.5565, 0.5651], [0.5396, 0.5426, 0.5621]]
+ ).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.reconstruction[0, 0, :3, :3], expected_slice, atol=1e-4))
diff --git a/utils/check_repo.py b/utils/check_repo.py
index da0d6df8b039..ec6f73134d13 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -146,6 +146,7 @@
# should **not** be the rule.
IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
# models to ignore for model xxx mapping
+ "Swin2SRForImageSuperResolution",
"CLIPSegForImageSegmentation",
"CLIPSegVisionModel",
"CLIPSegTextModel",