由于业界很多公司的大数据平台,都是基于Yarn搭建,所以Angel目前的分布式运行是基于Yarn,方便用户复用现网环境,而无需任何修改。
-
运行环境准备
Angel的分布式Yarn运行模式需要的环境,其实也非常简单:
-
一个可以正常运行Hadoop集群,包括Yarn和HDFS
- Hadoop >= 2.2.0
-
一个用于提交Angel任务的客户端Gateway
- Java >= 1.8
- 可以提交MR作业
- Angel发布包:angel-1.0.0-bin.zip
-
这里我们以最简单的LogisticRegression为例:
-
上传数据(如果用户有自己的数据可以略过本步,但是要确认数据格式一致)
-
找到发布包的data目录下的LogisticRegression测试数据
-
在hdfs上新建lr训练数据目录
hadoop fs -mkdir hdfs://my-nn:54310/test/lr_data -
将数据文件上传到指定目录下
hadoop fs -put data/exampledata/LRLocalExampleData/a9a.train hdfs://my-nn:54310/test/lr_data
-
-
提交任务
-
在发布包的bin目录下有Angel的提交脚本angel-submit,使用它将任务提交到Hadoop集群
./angel-submit \ --angel.app.submit.class "com.tencent.angel.ml.classification.lr.LRRunner"\ --angel.train.data.path "hdfs://my-nn:54310/test/lr_data" \ --angel.log.path "hdfs://my-nn:54310/test/log" \ --angel.save.model.path "hdfs://my-nn:54310/test/model" \ --action.type train \ --ml.data.type libsvm \ --ml.feature.num 1024 \ --angel.job.name LR_test
参数含义如下
名称 含义 action.type 计算类型,目前支持"train"和"predict"两种,分别表示模型训练和预测 angel.app.submit.class 算法运行类,每个算法都对应一个运行类 angel.train.data.path 训练数据路径 angel.log.path 算法指标日志输出路径 angel.save.model.path 模型保存路径 ml.data.type 训练数据格式,默认支持两种格式libsvm和dummy ml.feature.num 模型维度 angel.job.name 任务名 为了方便用户,Ange设置有许多参数可供调整,可以参考
- 系统参数: 主要系统配置
- 算法参数: Logistic Regression
-
-
观察进度
任务提交之后,会在控制台打印出任务运行信息,如URL和迭代进度等,如下图所示:

打开URL信息就可以看到Angel任务每一个组件的详细运行信息和算法相关日志:
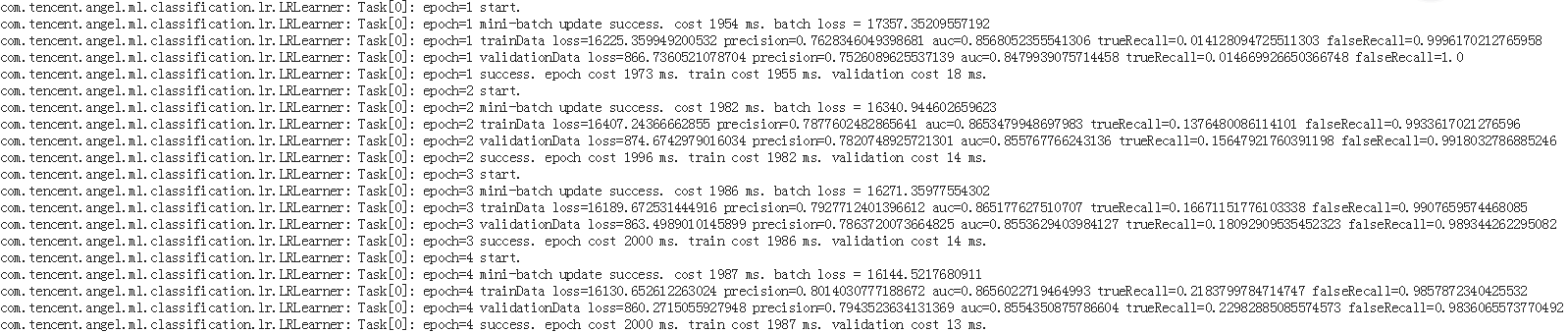
目前的监控页面有点简陋,后续会进一步优化,围绕PS的本质,提高美观程度和用户可用度

