- post请求的四种提交方式
-
form-data
就是http请求中的multipart/form-data,它会将表单的数据处理为一条消息,以标签为单元,用分隔符分开。既可以上传键值对,也可以上传文件。当上传的字段是文件时,会有Content-Type来说明文件类型;content-disposition,用来说明字段的一些信息; 由于有boundary隔离,所以multipart/form-data既可以上传文件,也可以上传键值对,它采用了键值对的方式,所以可以上传多个文件。
-
x-www-form-urlencoded
就是application/x-www-from-urlencoded,会将表单内的数据转换为键值对,比如,name=Java&age = 23
-
raw
可以上传任意格式的文本,可以上传text、json、xml、html等
-
binary
相当于Content-Type:application/octet-stream,从字面意思得知,只可以上传二进制数据,通常用来上传文件,由于没有键值,所以,一次只能上传一个文件
-
multipart/form-data与x-www-form-urlencoded区别
multipart/form-data:既可以上传文件等二进制数据,也可以上传表单键值对,只是最后会转化为一条信息; x-www-form-urlencoded:只能上传键值对,并且键值对都是间隔分开的。
-
XSS和CSRF简介
XSS(Cross-site scripting)跨站脚本注入,不对服务器进行直接的攻击,转而攻击使用服务器的用户,最为常见的方法就是在用户的输入框内输入script表现包裹的javascript语句,下次其他用户访问网站的时候,就会被收到XSS攻击啦,比如在input输入框中输入如下语句
<script> while(true) { alert('233333'); } </script>这样其他用户打开该网站的时候,就会一直有23333的弹窗。
那么该如何预防XSS呢,如果我们不需要用户输入 HTML 而只想让他们输入纯文本,那么把所有用户输入进行 HTML 转义输出是个不错的做法。似乎很多 Web 开发框架、模版引擎的开发者也发现了这一点,Django 内置模版和 Jinja2 模版总是默认转义输出变量的。如果没有使用它们,我们自己也可以这么做。PHP 可以用 htmlspecialchars 函数,Python 可以导入 cgi 模块用其中的 cgi.escape 函数。如果使用了某款模版引擎,那么其必自带了方便快捷的转义方式
那如果某些地方需要用户输入HTML呢,这个时候,就需要非常小心了,仅仅对script标签做过滤是没有办法完全杜绝XSS的,随便在一个DOM节点上绑定一个onclick的事件处理函数或者使用display的iframe进行用户不知道的请求,都能实现XSS,有个比较方便的解决方法,增加白名单,我们不对用户的输入做直接存储,而是根据HTML的结构进行解析(HTML比XML的容错率高),然后将解析完毕的结果存入数据库,读取拼接数据的时候,将节点name和白名单中进行比较,大大降低XSS的可能性
CSRF(Cross-site request forgery)跨站请求伪造
XSS是CSRF的一种,把通过XSS实现的CSRF称为XSRF,CSRF和XSS的攻击方式有一些相似,都不是直接对服务器进行攻击,而是攻击使用服务器的用户,预防CSRF的基本方法是使用POST请求代替GET请求进行写入的操作,然而黑客还是可以通过不可见的表单进行攻击,这时候就需要行之有效的请求令牌来预防CSRF了,举个栗子,django中的{% csrf_token %},服务器会在session中写入csrftoken,请求的时候,需要在请求头部写入X-CSRFTOKEN,值为cookie中的csrftoken, 也可以使用加密的cookie,但是如果网站没有预防XSS的话,执行了外站的脚本,就可能造成cookie泄露,还是不如token
-
HTTP缓存机制
-
TCP的三次握手和四次挥手
-
三次握手
- 客户端发送带有SYN标志的数据包
- 服务端收到了数据包之后,发送带有SYN/ACK的数据包
- 客户端收到ACK之后,向服务端发送ACK,开始通信
-
四次挥手
- 客户端发送一个FINISH给服务端
- 服务端收到之后,返回一个ACK给客户端
- 服务端发送一个FINISH给客户端,服务端断开连接
- 客户端收到之后,发送ACK给服务端,客户端断开连接
-
-
header中Content-Disposition的作用
在get请求的response header中设置 Content-Disposition 可以用于文件下载,给出一个栗子
res.setHeader('Content-Disposition', `attachment; filename=${filename}`);
-
http和https
https的SSL加密是在传输层实现的。
-
http和https的基本概念
http: 超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
https: 是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
https协议的主要作用是:建立一个信息安全通道,来确保数组的传输,确保网站的真实性。
-
http和https的区别?
http传输的数据都是未加密的,也就是明文的,网景公司设置了SSL协议来对http协议传输的数据进行加密处理,简单来说https协议是由http和ssl协议构建的可进行加密传输和身份认证的网络协议,比http协议的安全性更高。 主要的区别如下:
Https协议需要ca证书,费用较高。
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
使用不同的链接方式,端口也不同,一般而言,http协议的端口为80,https的端口为443
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
-
https协议的工作原理
客户使用https url访问服务器,则要求web 服务器建立ssl链接。
web服务器接收到客户端的请求之后,会将网站的证书(证书中包含了公钥),返回或者说传输给客户端。
客户端和web服务器端开始协商SSL链接的安全等级,也就是加密等级。
客户端浏览器通过双方协商一致的安全等级,建立会话密钥,然后通过网站的公钥来加密会话密钥,并传送给网站。 web服务器通过自己的私钥解密出会话密钥。
web服务器通过会话密钥加密与客户端之间的通信。
-
https协议的优点
使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
谷歌曾在2014年8月份调整搜索引擎算法,并称“比起同等HTTP网站,采用HTTPS加密的网站在搜索结果中的排名将会更高”。
-
https协议的缺点
https握手阶段比较费时,会使页面加载时间延长50%,增加10%~20%的耗电。
https缓存不如http高效,会增加数据开销。
SSL证书也需要钱,功能越强大的证书费用越高。
SSL证书需要绑定IP,不能再同一个ip上绑定多个域名,ipv4资源支持不了这种消耗。
-
https为什么比http更安全
具体的见http权威指南/图解http,下面给出基本解释
- http的通信是使用明文不加密的,很可能会被窃听,而https是由http + ssl加密实现的,对通信进行加密
- http并不知道实际与其通信的对方是谁,很可能gg,而https使用一种证书的方法,证书由第三方权威机构发布,很难伪造,https通过验证证书,判断对方身份,是否是我们需要通信的目标
- http消息传输途中,很可能信息遭到篡改(增加或者删除),而https能够保证http通信消息的完整性
-
-
web服务的工作模式流程图
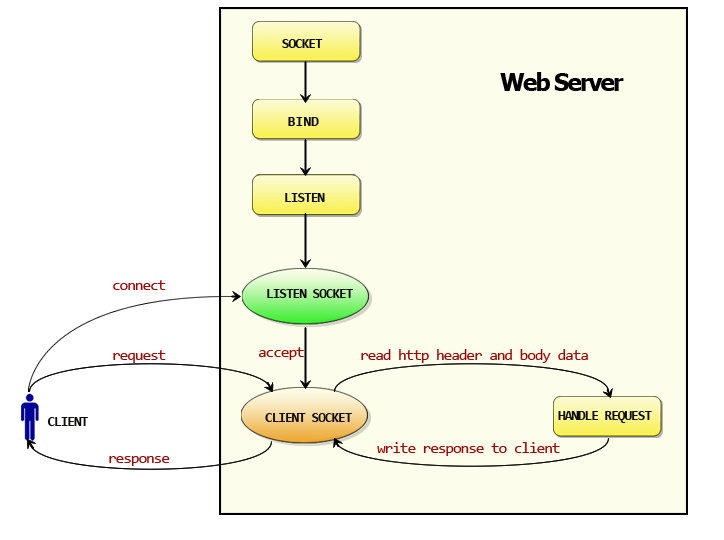
- 创建Listen Socket, 监听指定的端口, 等待客户端请求到来
- Listen Socket接受客户端的请求, 得到Client Socket, 接下来通过Client Socket与客户端通信
- 处理客户端的请求, 首先从Client Socket读取HTTP请求的协议头, 如果是POST方法, 还可能要读取客户端提交的数据, 然后交给相应的handler处理请求, handler处理完毕准备好客户端需要的数据, 通过Client Socket写给客户端
-
form-data 上传
const fd = new FormData(); fd.append('file', this.fileInput.files[0]); fd.append('ad_id', this.adId); fd.append('app_id', this.appId); fd.append('start_date', start_date); fd.append('end_date', end_date); fd.append('event_type', this.eventType); 然后 POST 请求的 body = fd 即可
-
GET、POST 请求文件下载
服务端设置一些参数,以 python 为例
result = make_response(list_to_csv(conversion_kv_dict, event_list)) # 生成一个 csv 文件 result.headers["Content-Type"] = "text/csv" result.headers["Content-Disposition"] = "attachment; filename=%s" % \ urllib.quote(filename) def list_to_csv(header_dict, data_list): """ 将list转为csv格式返回 :param header_dict: csv表头 :param data_list: 代转换的数据列表 :return: 转换后的csv格式内容 """ output = cStringIO.StringIO() csv_writer = csv.writer(output, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL) for i, each in enumerate(data_list): if i == 0: csv_writer.writerow(header_dict.values()) csv_writer.writerow([each.get(x, "") for x in header_dict.keys()]) result = output.getvalue() output.close() return result
如果是 GET 请求下载的话,直接 window.open()打开下载连接即可
如果是 POST 请求,使用 Blob 来进行下载
fetch(url, { method: 'POST'}) .then(res => { return res.blob(); }) .then(blob => { const reader = new FileReader(); reader.readAsDataURL(blob); reader.onload = (e) => { const a = document.createElement('a'); a.download = filename; a.href = e.target.result; document.body.appendChild(a); a.click(); document.body.removeChild(a); }) .catch(err => { console.log(err); }) -
http 状态码
- 200: OK
- 204: 请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用
- 301: 永久重定向
- 302: 临时重定向
- 303: 和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源
- 304: 资源未修改
- 307: 临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法
- 400: 请求报文中存在语法错误
- 401: 权限不足
- 403: 请求被拒绝
- 404: not found
- 413: 报文太长
- 500: 服务器正在执行请求时发生错误
- 503: 服务器暂时处于超负载或正在进行停机维护,现在无法处理请求
-
http 首部字段 cache-control
HTTP/1.1 通过 Cache-Control 首部字段来控制缓存
-
禁止进行缓存:no-store 指令规定不能对请求或响应的任何一部分进行缓
Cache-Control: no-store -
强制确认缓存:no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效才将能使用该缓存对客户端的请求进行响应
Cache-Control: no-cache -
private 指令规定了将资源作为私有缓存,只能被单独用户所使用,一般存储在用户浏览器中
Cache-Control: private -
public 指令规定了将资源作为公共缓存,可以被多个用户所使用,一般存储在代理服务器中
Cache-Control: public
-
