FATE-Flow是用于联邦学习的端到端Pipeline系统,它由一系列高度灵活的组件构成,专为高性能的联邦学习任务而设计。其中包括数据处理、建模、训练、验证、发布和在线推理等功能.

- 使用DAG定义Pipeline;
- 使用 JSON 格式的 FATE-DSL 描述DAG;
- FATE具有大量默认的联邦学习组件, 例如Hetero LR/Homo LR/Secure Boosting Tree等;
- 开发人员可以使用最基本的API轻松实现自定义组件, 并通过DSL构建自己的Pipeline;
- 联邦建模任务生命周期管理器, 启动/停止, 状态同步等;
- 强大的联邦调度管理, 支持DAG任务和组件任务的多种调度策略;
- 运行期间实时跟踪数据, 参数, 模型和指标;
- 联邦模型管理器, 模型绑定, 版本控制和部署工具;
- 提供HTTP API和命令行界面;
- 提供可视化支持, 可在 FATE-Board 上进行可视化建模。

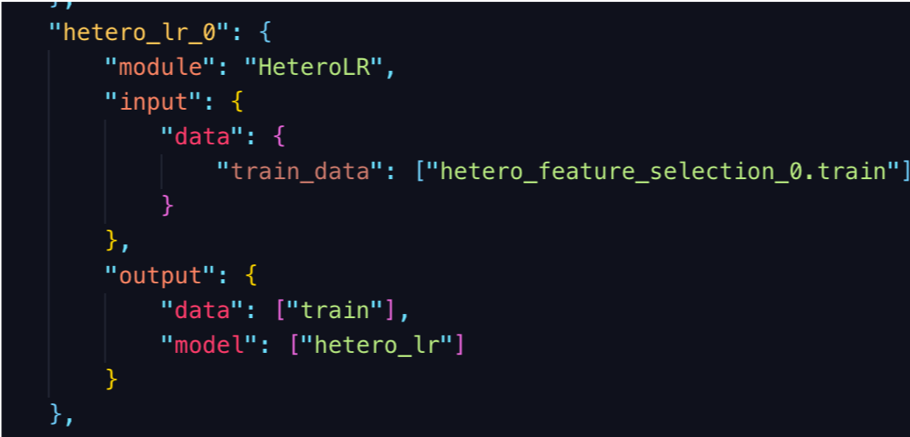
仅需一步就可以为Pipeline配置组件
- 定义此组件的模块
- 定义输入, 包括数据, 模型或isometric_model(仅用于FeatureSelection)
- 定义输出, 包括数据和模型



Fate-Flow部署在$PYTHONPATH/fate_flow/中,它依赖两个配置文件:$PYTHONPATH/arch/conf/server.conf, $PYTHONPATH/fate_flow/settings.py
在 server.conf配置所有FATE服务的地址,不同部署模式的FATE-Flow需要不同的Fate服务。有关详细信息, 请参考以下特定的部署模式。
关键配置项说明:
| 配置项 | 配置项含义 | 配置项值 |
|---|---|---|
| IP | FATE-Flow 的监听地址 | 默认0.0.0.0 |
| GRPC_PORT | 监听 FATE-Flow grpc 服务的端口 | 默认9360 |
| HTTP_PORT | FATE-Flow的http服务器的侦听端口 | 默认9380 |
| WORK_MODE | FATE-Flow的工作模式 | 0(单机模式), 1(群集模式) |
| USE_LOCAL_DATA | 是否使用FATE-Flow客户端机器上的数据 | True代表使用,False代表不使用 |
| USE_LOCAL_DATABASE | 是否使用本地数据库(sqlite) | False表示否, True表示是 |
| USE_AUTHENTICATION | 是否启用身份验证 | False表示否, True表示是 |
| USE_CONFIGURATION_CENTER | 是否使用Zookeeper | False表示否, True表示是 |
| MAX_CONCURRENT_JOB_RUN | 同时并行执行的Pipeline作业(job) 数量 | 默认5 |
| MAX_CONCURRENT_JOB_RUN_HOST | 最大运行作业(job) 数量 | 默认值10 |
| 数据库 | mysql数据库的配置 | 定制配置 |
| REDIS | Redis的配置 | 定制配置 |
| REDIS_QUEUE_DB_INDEX | Redis队列的Redis数据库索引 | 默认值0 |
服务器启动/停止/重启脚本
| 配置项 | 配置项含义 | 配置项值 |
|---|---|---|
| PYTHONPATH | python路径 | FATE-Flow父目录的绝对路径 |
| venv | python虚拟环境 | 自定义配置, 例如/data/projects/fate/venv, 而不是/data/projects/fate/venv/bin/activate |
您只需要启动FATE-Flow服务即可运行联邦学习建模实验。
| 配置项 | 配置项值 |
|---|---|
| WORK_MODE | 0 |
| USE_LOCAL_DATABASE | True |
- 使用 Sqlite 作为数据库, db文件是 FATE-Flow 根目录上的fate_flow_sqlite.db;
- 使用List作为任务队列;
- 多方通讯回环。
您需要部署三个服务:
- MySQL
- Fate-Flow
- FATE-Board
我们提供了FATE单机版的Docker版本以方便大家体验FATE. 请参阅docker-deploy上的docker版本部署指南.
| 配置项 | 配置项值 |
|---|---|
| WORK_MODE | 0 |
| USE_LOCAL_DATABASE | False |
| 数据库 | mysql数据库的配置 |
- 使用 MySQL 作为数据库;
- 使用List作为任务队列;
- 多方通讯回环;
- 可通过FATE-Board实现可视化。
FATE还为大数据场景提供了分布式框架从单机迁移到集群仅需要更改配置,无需更改算法。 要在集群上部署FATE,请参阅集群部署指南cluster-deploy.
| 配置项 | 配置项值 |
|---|---|
| WORK_MODE | 1 |
| 数据库 | mysql数据库的配置定制配置 |
| REDIS | Redis的配置 |
- 使用MySQL作为数据库;
- 使用redis队列作为任务队列;
- 多方通信使用代理;
- 可通过FATE-Board实现可视化。
FATE-Flow提供 REST API和命令行界面. 让我们开始使用client端来运行一个联邦学习Pipeline任务 (单机版本).
python fate_flow_client.py -f upload -c examples/upload_guest.json
python fate_flow_client.py -f upload -c examples/upload_host.jsonFATE-Flow Server中的配置项USE_LOCAL_DATA代表上传数据时是否使用FATE-Flow客户端机器上的数据,默认使用(True)。 如果FATE-Flow Server的配置USE_LOCAL_DATA设为True,并且还是想要使用FATE-Flow Server所在机器上的数据,可在上传配置中添加“use_local_data”参数,参数值为0(默认为1)。
集群部署使用同一个表上传数据时,需携带drop参数(0代表覆盖上传,1代表删除之前的数据并重新上传)
python fate_flow_client.py -f upload -c examples/upload_guest.json -drop 0python fate_flow_client.py -f submit_job -d examples/test_hetero_lr_job_dsl.json -c examples/test_hetero_lr_job_conf.json命令响应示例:
{
"data": {
"board_url": "http://localhost:8080/index.html#/dashboard?job_id=2019121910313566330118&role=guest&party_id=9999",
"job_dsl_path": "xxx/jobs/2019121910313566330118/job_dsl.json",
"job_runtime_conf_path": "xxx/jobs/2019121910313566330118/job_runtime_conf.json",
"logs_directory": "xxx/logs/2019121910313566330118",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "2019121910313566330118"
}
},
"jobId": "2019121910313566330118",
"retcode": 0,
"retmsg": "success"
}
以下某些操作将用到上面这些响应信息。
python fate_flow_client.py -f query_job -r guest -p 10000 -j $job_id您可以在CLI 中找到更多有用的命令。
有关更多联邦学习Pipeline作业(job) 示例, 请参考federatedml-1.x-examples 和 README
将模型发布到FATE-Serving, 然后使用Serving的GRPC API进行在线推理。
修改arch/conf/server_conf.json里FATE-Serving的ip和端口(需要注意多方都需要修改成各自FATE-Serving的实际部署地址),内容为"servings":["ip:port"],修改完后重启FATE-Flow. server_conf.json格式如下:
{
"servers": {
"servings": [
"127.0.0.1:8000"
]
}
}python fate_flow_client.py -f load -c examples/publish_load_model.json请使用您的任务配置替换 publish_online_model.json 中的相应配置。
之后, 您可以通过指定所使用的模型ID和模型版本来向FATE-Serving提出在线推理请求。
python fate_flow_client.py -f bind -c examples/bind_model_service.json请使用您的任务配置替换publish_online_model.json中的相应配置。之后, FATE-Serving会使用您提供的配置来设置参与方的默认模型ID和涉及该模型ID的默认模型版本。 然后, 您可以通过指定party_id或模型ID来向FATE-Serving提出在线推理请求。
$PYTHONPATH/logs/fate_flow/
$PYTHONPATH/logs/$job_id/
- FATE Flow是调度系统,根据用户提交的作业DSL,调度算法组件执行
- 将PYTHONPATH设置为fate_flow目录的父目录。
- 命令"submit_job"只是提交任务,"success"代表的是任务提交成功,任务失败后可以通过日志来查看。
- arbiter是用来辅助多方完成联合建模的,它的主要作用是聚合梯度或者模型。比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等。
- guest代表数据应用方。
- host是数据提供方。
- local是指本地任务, 该角色仅用于upload和download阶段中。
- Fate_flow目前仅支持在任务发起方进行kill,其它方kill会显示“cannot find xxxx”。
- Upload data是上传到eggroll里面,变成后续算法可执行的DTable格式。
- 您可以使用
python fate_flow_client.py -f component_output_model -j $job_id -r $role -g $guest -cpn $component_name -o $output_path
- 如果同一表的键相同, 它的值将被覆盖。
- 这些日志不会显示在board上展示:
$job_id/fate_flow_schedule.log,logs/error.log,logs/fate_flow/ERROR.log.
- load可以理解为发送模型到模型服务上, 而bind是绑定一个模型到模型服务。