Visual-language assistant with Pixtral and OpenVINO
Pixtral-12b is multimodal model that consists of 12B parameter multimodal decoder based on Mistral Nemo and 400M parameter vision encoder trained from scratch. It is trained to understand both natural images and documents. The model shows strong abilities in tasks such as chart and figure understanding, document question answering, multimodal reasoning and instruction following. Pixtral is able to ingest images at their natural resolution and aspect ratio, giving the user flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Unlike previous open-source models, Pixtral does not compromise on text benchmark performance to excel in multimodal tasks.
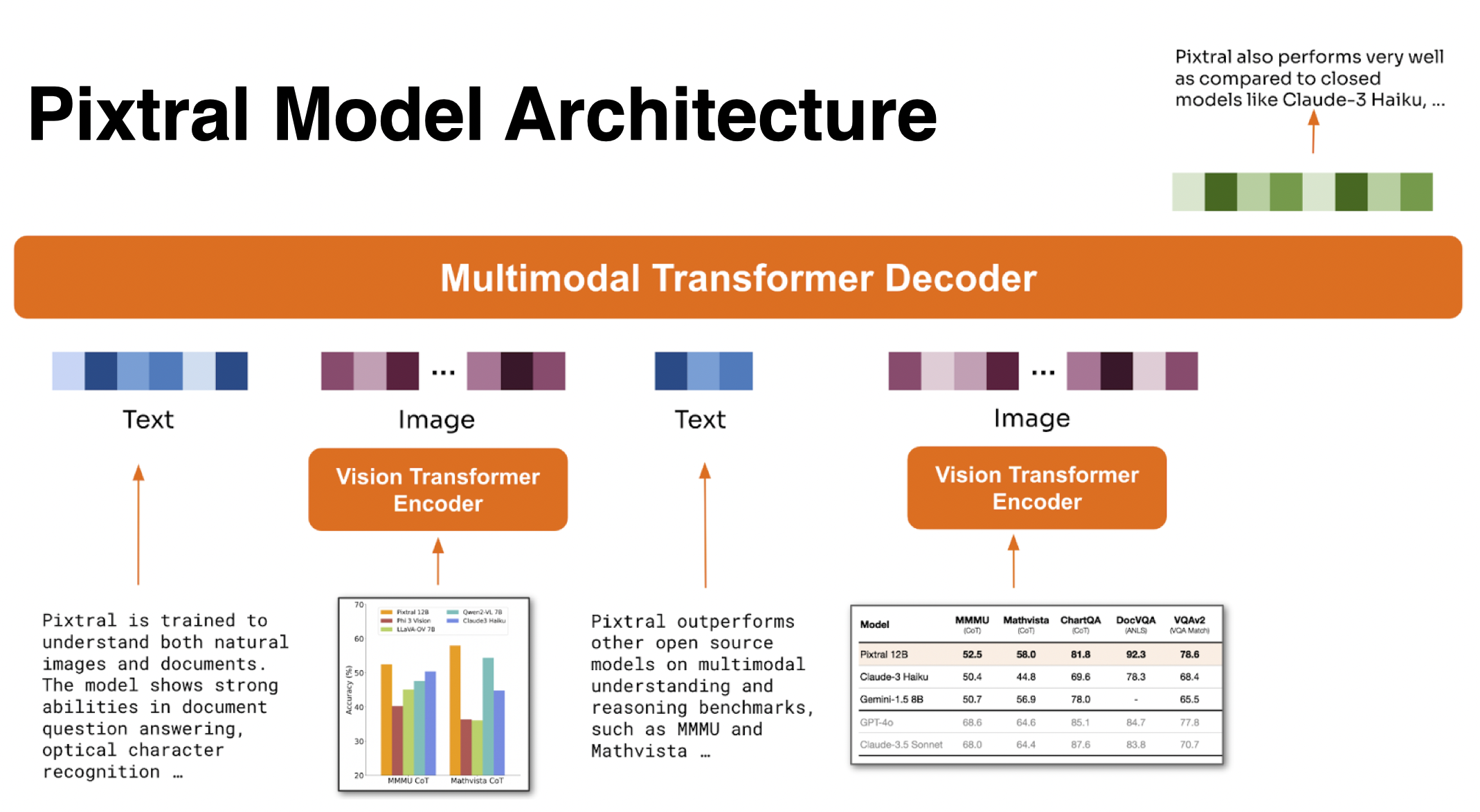
More details about model are available in blog post and model card
In this tutorial we consider how to convert, optimize and run this model using OpenVINO.
The tutorial consists from following steps:
- Install requirements
- Convert and Optimize model
- Run OpenVINO model inference
- Launch Interactive demo
In this demonstration, you'll create interactive chatbot that can answer questions about provided image's content.
The image bellow illustrates example of input prompt and model answer.

This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
For details, please refer to Installation Guide.
