Christoph Feichtenhofer*, Haoqi Fan*, Yanghao Li, Kaiming He
Technical report, arXiv, May 2022. [Paper]
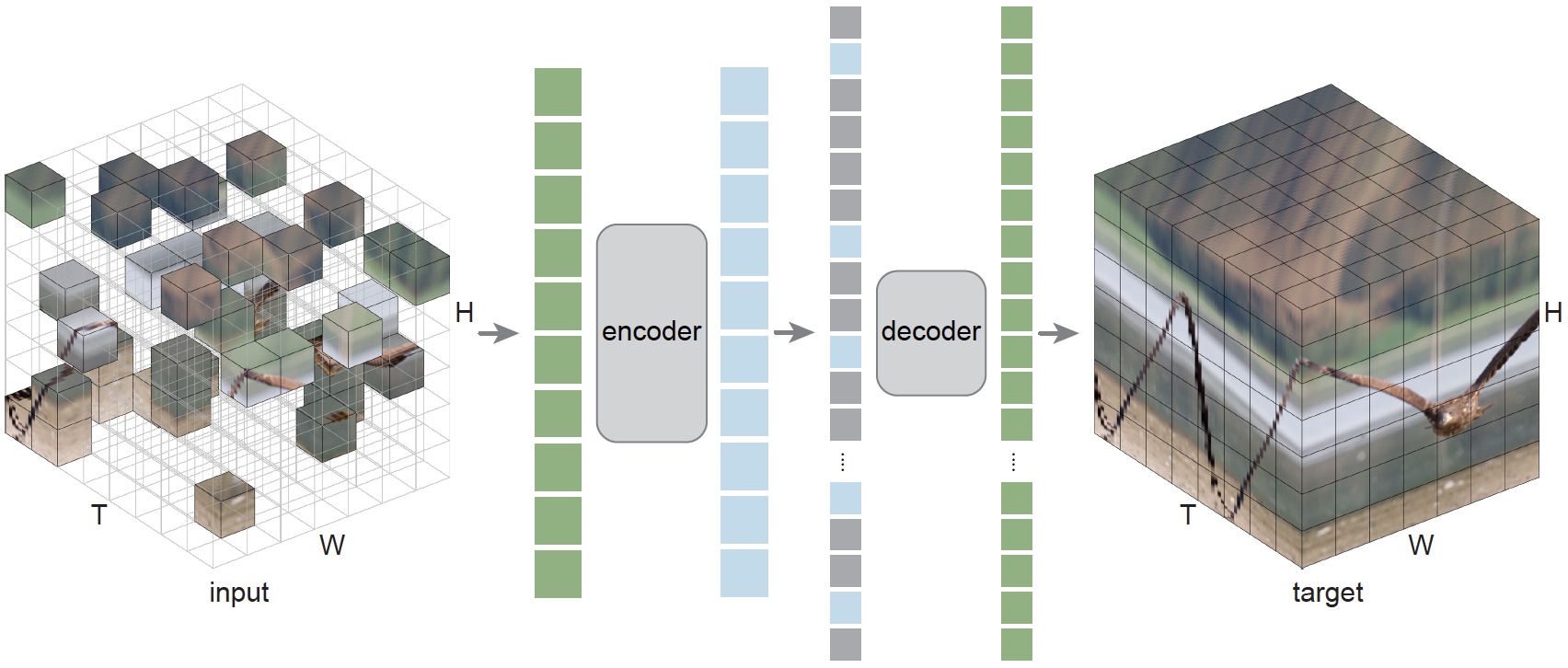
| name | frame length x sample rate | top1 | Flops (G) x views | #params (M) | config pre-train (PT) | config fine-tune | model PT |
|---|---|---|---|---|---|---|---|
| ViT-B | 16 x 4 | 81.3 | 180 x 3 x 7 | 87 | k400_VIT_B_16x4_MAE_PT | k400_VIT_B_16x4_FT | link |
| ViT-L | 16 x 4 | 84.8 | 598 x 3 x 7 | 304 | k400_VIT_L_16x4_MAE_PT | k400_VIT_L_16x4_FT | link |
| ViT-H | 16 x 4 | 85.1 | 1193 x 3 x 7 | 632 | k400_VIT_H_16x4_MAE_PT | k400_VIT_H_16x4_FT | link |
To use self-supervised learning techniques please refer to the configs under configs/masked_ssl. For example, the command
python tools/run_net.py \
--cfg configs/masked_ssl/k400_VIT_L_16x4_MAE_PT.yaml \
DATA.PATH_TO_DATA_DIR path_to_your_Kinetics_dataset
should train an MAE ViT-L model on the Kinetics-400 dataset, and the command
python tools/run_net.py \
--cfg configs/masked_ssl/k400_VIT_L_16x4_FT.yaml \
DATA.PATH_TO_DATA_DIR path_to_your_Kinetics_dataset \
TRAIN.CHECKPOINT_FILE_PATH path_to_your_pretrain_checkpoint
will fine-tune the resulting model, after passing the checkpoint path to the config.
If you find this useful for your research, please consider citing the paper using the following BibTeX entry.
@article{feichtenhofer2022masked,
title={Masked Autoencoders As Spatiotemporal Learners},
author={Feichtenhofer, Christoph and Fan, Haoqi and Li, Yanghao and He, Kaiming},
journal={arXiv preprint arXiv:2205.09113},
year={2022}
}