In today's fast-paced development world, efficiently seeding a complex database is crucial for rapid application development. @snaplet/seed offers a seamless solution, and in this post, we'll explore its powerful capabilities using a Hasura slack clone as a case study.
To demonstrate the effectiveness of @snaplet/seed, we'll take a Hasura slack clone as our example. We'll deploy a local Hasura instance using the Hasura CLI and Docker, followed by employing @snaplet/seed to populate our app with data.
- Node.js and npm: Installation Guide
- Docker and docker-compose: Get Docker
Setting up a working local environment is our first step. Here's how to get started:
-
Clone the Snaplet examples repository and navigate to the Hasura slack clone example:
git clone [email protected]:snaplet/examples.git && cd examples/seed/hasura-slack-clone
-
Install the necessary Node packages:
npm install
-
Spin up Docker containers:
docker-compose up -d
-
Launch the Hasura console:
npx hasura console
-
In a separate terminal, apply Hasura metadata and migrations:
npx hasura metadata apply && npx hasura migrate apply && npx hasura metadata apply
Opening http://localhost:9695/console should now display the Hasura console. You'll notice that our database is currently empty, but we're all set to change that!
As you can see for now, there is no data in our database. But we now have a deployed schema who look like this:
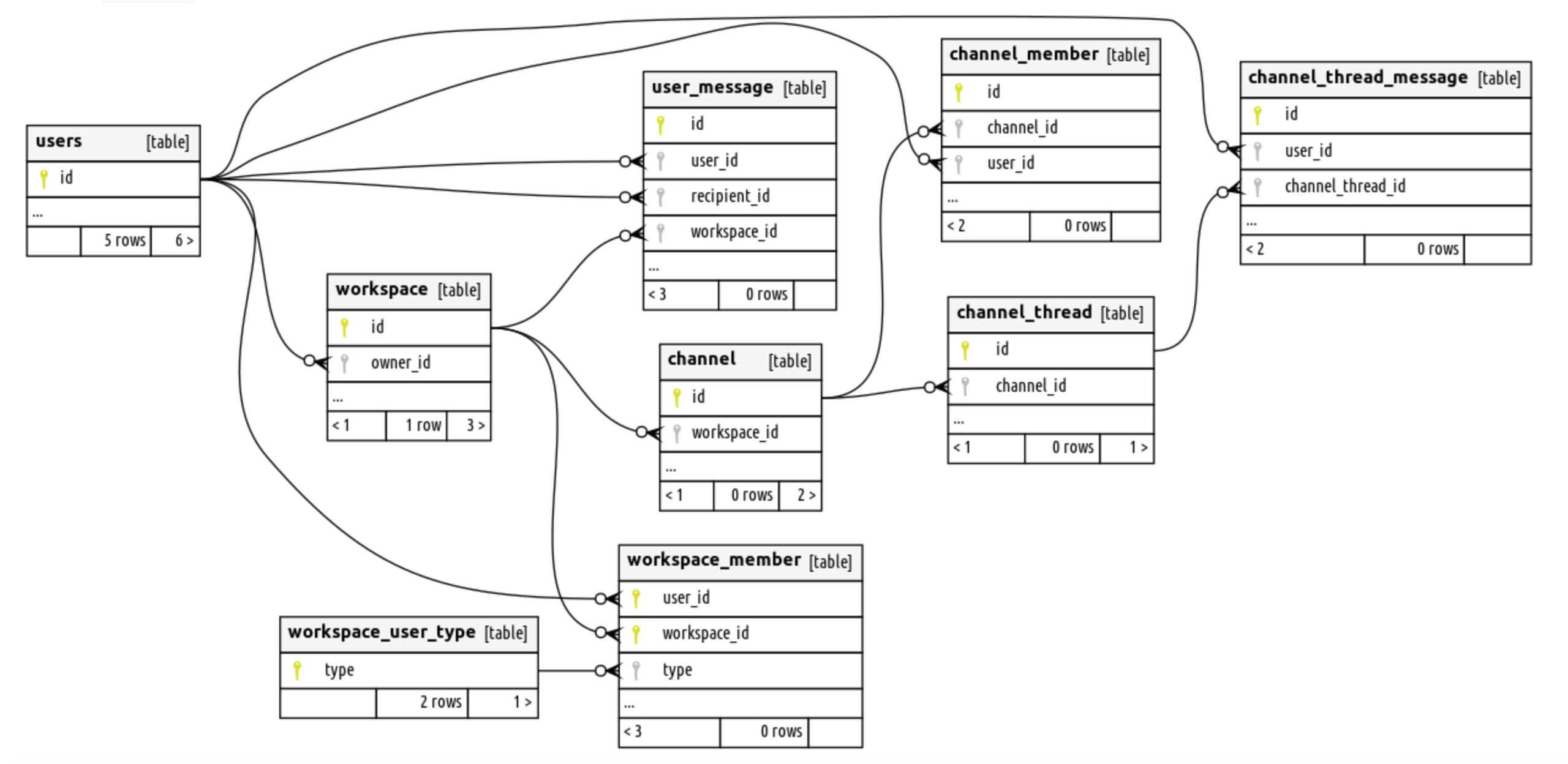
Let's setup snaplet to generate some data for us.
Snaplet operates in two main steps:
- Introspection: Snaplet analyzes your database, gathering schema, data, and relationship details.
- Configuration: Snaplet generates multiples transforms to generate data based on the introspection result (columns names, data types, relationships, etc).
- Script Generation: Snaplet generates a
seed.tsfile for data generation.
To set it up:
npx @snaplet/seed@latest initYou will be asked to choose an "adapter" to connect to your local database, in this example we'll use "postgres-js".
The cli will genrate a default seed.config.ts for you and prompt you at some point
to edit it to provide an "adapter" allowing us to connect to the database.
What we need to do here is two things:
- Configure the default adapter so it connect to our localhost database:
postgres://postgres:[email protected]:5433/postgres - Ensure our seed, won't be touching our hasura internal tables as we don't want to alter them. Those internal tables are located under the
hdb_catalogschema. We'll exclude them using theselectoption in the config.
So let's edit our seed.config.ts so it look like this:
import { defineConfig } from "@snaplet/seed/config";
import { SeedPostgres } from "@snaplet/seed/adapter-postgres";
import postgres from "postgres";
export default defineConfig({
// We use our postgres-js adapter to connect to our local database
adapter: () =>
new SeedPostgres(
postgres("postgres://postgres:[email protected]:5433/postgres")
),
alias: {
// We want inflections name on our fields see: https://docs.snaplet.dev/seed/core-concepts#inflection
inflection: true,
}
select: [
// We don't want to alter any tables under this schema
"!hdb_catalog*",
],
});When saving this configuration, our cli watcher will detect that it's now able to connect
and introspect our database, and will finish our client generation generating a seed.ts file:
import { createSeedClient } from "@snaplet/seed";
const seed = await createSeedClient();
// Clears all existing data in the database, but keep the structure
await seed.$resetDatabase();
// This will create 3 records in the workspaceUserTypes table
// it reads workspaceUserTypes times(x) 3
await seed.workspaceUserTypes((x) => x(3));
process.exit()Now that we have our seed.ts file, we can generate data with the following command:
npx tsx seed.tsWith our current configuration this will create 3 workspace user types. Not very useful.
To build a more realistic environment, we plan to add:
- Workspaces: We aim to create 2 distinct workspaces.
- Users: For each workspace, we'll create 2 users.
- Channels: Each workspace will have 2 channels.
- Messages: We plan to create 2 messages in each channel.
These additions will help us simulate a more authentic workspace environment, giving us a better platform to demonstrate the capabilities of @snaplet/seed.
We can update our seed.ts like this:
...
await seed.$resetDatabase();
await seed.workspaces((x) =>
// 1. We want to create 2 workspaces
x(2, () => ({
// 2. We want to 2 users per workspace
workspaceMembers: (x) => x(2),
channels: (x) =>
// 3. We want to create 2 channels per workspace
x(2, () => ({
// 4. We want two members per channel
channelMembers: (x) => x(2),
channelThreads: (x) =>
// 5. We want to create 2 thread per channel
x(2, () => ({
// 6. We want to create 2 messages per thread
channelThreadMessages: (x) => x(2),
})),
})),
}))
);Based on our configuration, here's what we expect:
2 workspaces 4 users 4 channels 8 channel members 8 channel threads 16 channel thread messages Let's generate the data and explore the result:
npx tsx seed.tsAs you can see, we have now a lot of data in our database. Let's explore it in the Hasura console.

Something is off, the actual generated data is not what we expected. We have:
- 2 workspaces (ok)
- 30 users (not ok)
- 4 channels (ok)
- 8 channel members (ok)
- 8 channel threads (ok)
- 16 channel thread messages (ok)
What happened here ?
By default, snaplet will generate data for all the tables in your database.
But it will also try to generate data for all the tables that are connected to the tables you want to generate data for.
And by default, it will either "create data" or "try to connect to existing data". By default he will try to create data.
This is the reason why we see 30 users created and also why we have 4 workspace_user_type created. Even if we didn't ask for it.
Because workspaceMembers require a valid user_id to be created, each workspace also require a valid user for owner_id and so on.
Right now, every time generate see this kind of relationships it'll create a new user for it.
This could be fine, but in our case we want to have more control over the data we generate. What we really want it to re-use a pool of defined users and assign them to differents workspaces and channels.
Let's rewrite our expectations:
- Create a pool of 8 users.
- Establish 2 different workspace_user_type categories: "admin" and "user".
Using this initial data pool, we then aim to:
- Create 2 workspaces.
- Assign 2 users to each workspace.
- Create 2 channels for each workspace.
- Assign 2 users to each channel.
- Generate 2 threads per channel.
- Create 2 messages per thread.
- Generate 20 private messages between users across the workspaces.
To implement this, we'll utilize the @snaplet/seed ability to connect existing
data togethers.
Let's see what it look like:
// We setup a pool of 8 users
const { users } = await seed.users((x) => x(8));
// We setup a pool of 2 workspace user types
const { workspaceUserTypes } = await seed.workspaceUserTypes([
{ type: "admin" },
{ type: "user" },
]);
// We create our workspaces and data, providing our pool for snaplet to
// use rather than creating new data
await seed.workspaces(
(x) =>
x(2, () => ({
workspaceMembers: (x) => x(4),
channels: (x) =>
x(2, () => ({
channelMembers: (x) => x(2),
channelThreads: (x) =>
x(2, () => ({
channelThreadMessages: (x) => x(2),
})),
})),
// We create private messages between users of this workspace
userMessages: (x) => x(10),
})),
{
connect: { users, workspaceUserTypes },
}
);After adjusting our data generation strategy, let's run the command again to see the results:
npx tsx seed.ts
Hiro Nakamura voice: "Yatta !"
We've successfully generated a more controlled and realistic dataset.
Having a large dataset is great, but realism in data is key. For example, our users' "name" fields currently lack authenticity. To rectify this, we can refine our users definition the file:
// We use copycat to generate fake data deterministically
// that's like a deterministic faker
import { copycat } from '@snaplet/copycat'
snaplet.users((x) => x(8, () => ({
// We can customize each field to generate more realistic data
// Utilizing the `seed` and the copycat library for deterministic results
name: ({seed}) => copycat.fullName(seed),
displayName: ({seed}) => copycat.username(seed),
}))),This is all good and nice, but if we examine our data more closely, we'll notice some inconsistencies. Mainly due to the fact that some "logic" in our data cannot be expressed by our database and is more related to our application logic.
For example here a few things that we can think of:
- Some of our users are in two workspace, some in none, but we half of them in the first workspace, and the other half in the second workspace.
- Channel members should be workspace members.
- Channel thread messages should be exchanged only among members of the same channel.
Here we can see that our app requirement became more complex and we can already see that we would need a bit of custom logic to handle all that and ensure that our data is consistent with our app expectations.
Let's see how we could achieve that with snaplet:
const { users } = await seed.users((x) => x(8));
const { workspaceUserTypes } = await seed.workspaceUserTypes([
{ type: "admin" },
{ type: "user" },
]);
for (let i = 0; i < 2; i++) {
// We get the first or second half of our users array to assign to the workspace
const workspaceUsers = users.slice(i * 4, i * 4 + 4);
// We create workspaces and workspaceMembers for the users
const { workspaces, workspaceMembers } = await seed.workspaces(
[{ workspaceMembers: (x) => x(workspaceUsers.length) }],
{ connect: { users: workspaceUsers, workspaceUserTypes } }
);
// We create channels and channelMembers for the users within the workspace
const { channels, channelMembers } = await seed.channels(
(x) =>
x(2, () => ({
channelMembers: x(2),
})),
// Created channels are connected to the workspace and the members will be picked between the workspace members
{ connect: { workspaces, users: workspaceUsers } }
);
// We create 10 direct messages between users in the workspace
await seed.userMessages((x) => x(10), {
connect: { users: workspaceUsers, workspaces, workspaceMembers },
});
// For each channel, we create thread and messages between the members of the channel
for (const channel of channels) {
const members = channelMembers.filter((m) => m.channelId === channel.id);
// We filter the workspace users to get only the member of the channel
const membersUsers = workspaceUsers.filter((u) =>
members.some((m) => m.userId === u.id)
);
await seed.channelThreads(
(x) =>
x(2, () => ({
channelThreadMessages: (x) => x(2),
})),
{
connect: {
users: membersUsers,
workspaces,
workspaceMembers,
channelMembers: members,
channels: [channel],
},
}
);
}
}In this example we can see that we leverage the imperative style to easily insert our app data relationship logic into our seed script. Leveraging snaplet to automate all the things that doesn't need specifications.
Through this journey, we've showcased the flexibility and power of @snaplet/seed in creating a realistic and intricate database for a Hasura Slack clone. From addressing unexpected data generation results to refining relationships for authenticity, Snaplet proves to be an indispensable tool for developers looking to efficiently model complex data scenarios.
Whether you're a seasoned developer or just starting out, we hope this guide inspires you to explore the possibilities of Snaplet in your own projects. Dive in, experiment, and see how Snaplet can revolutionize your development workflow!