> inputs) {
* For example:
*
* # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j]
- * tf.angle(input) ==> [2.0132, 1.056]
+ * tf.math.angle(input) ==> [2.0132, 1.056]
*
* {@literal @}compatibility(numpy)
* Equivalent to np.angle.
@@ -277,7 +277,7 @@ public Angle angle(Operand input) {
* For example:
*
* # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j]
- * tf.angle(input) ==> [2.0132, 1.056]
+ * tf.math.angle(input) ==> [2.0132, 1.056]
*
* {@literal @}compatibility(numpy)
* Equivalent to np.angle.
@@ -994,9 +994,10 @@ public FloorDiv floorDiv(Operand x, Operand y) {
}
/**
- * Returns element-wise remainder of division. When {@code x < 0} xor {@code y < 0} is
- * true, this follows Python semantics in that the result here is consistent
- * with a flooring divide. E.g. {@code floor(x / y) * y + mod(x, y) = x}.
+ * Returns element-wise remainder of division.
+ * This follows Python semantics in that the
+ * result here is consistent with a flooring divide. E.g.
+ * {@code floor(x / y) * y + floormod(x, y) = x}, regardless of the signs of x and y.
* NOTE: {@code math.FloorMod} supports broadcasting. More about broadcasting
* here
*
@@ -2128,7 +2129,7 @@ public Tanh tanh(Operand x) {
}
/**
- * Returns x / y element-wise for integer types.
+ * Returns x / y element-wise, rounded towards zero.
* Truncation designates that negative numbers will round fractional quantities
* toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different
* than Python semantics. See {@code FloorDiv} for a division function that matches
diff --git a/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/NnOps.java b/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/NnOps.java
index 4b0902ac98f..1592c64f74d 100644
--- a/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/NnOps.java
+++ b/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/NnOps.java
@@ -2070,18 +2070,47 @@ public SparseSoftmaxCrossEntropyWithLogits sparseSoftmaxC
* If two elements are equal, the lower-index element appears first.
*
* @param data type for {@code values} output
+ * @param data type for {@code indices} output
* @param input 1-D or higher with last dimension at least {@code k}.
* @param k 0-D. Number of top elements to look for along the last dimension (along each
* row for matrices).
* @param options carries optional attribute values
* @param data type for {@code TopKV2} output and operands
- * @return a new instance of TopK
+ * @return a new instance of TopK, with default output types
*/
- public TopK topK(Operand input, Operand k,
- TopK.Options... options) {
+ public TopK topK(Operand input, Operand k,
+ TopK.Options[] options) {
return TopK.create(scope, input, k, options);
}
+ /**
+ * Finds values and indices of the {@code k} largest elements for the last dimension.
+ * If the input is a vector (rank-1), finds the {@code k} largest entries in the vector
+ * and outputs their values and indices as vectors. Thus {@code values[j]} is the
+ * {@code j}-th largest entry in {@code input}, and its index is {@code indices[j]}.
+ * For matrices (resp. higher rank input), computes the top {@code k} entries in each
+ * row (resp. vector along the last dimension). Thus,
+ *
+ * values.shape = indices.shape = input.shape[:-1] + [k]
+ *
+ * If two elements are equal, the lower-index element appears first.
+ *
+ * @param data type for {@code values} output
+ * @param data type for {@code indices} output
+ * @param input 1-D or higher with last dimension at least {@code k}.
+ * @param k 0-D. Number of top elements to look for along the last dimension (along each
+ * row for matrices).
+ * @param indexType The value of the indexType attribute
+ * @param options carries optional attribute values
+ * @param data type for {@code TopKV2} output and operands
+ * @param data type for {@code TopKV2} output and operands
+ * @return a new instance of TopK
+ */
+ public TopK topK(Operand input,
+ Operand k, Class indexType, TopK.Options... options) {
+ return TopK.create(scope, input, k, indexType, options);
+ }
+
/**
* Get the parent {@link Ops} object.
*/
diff --git a/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/Ops.java b/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/Ops.java
index 37f7aa35358..4fc017acff7 100644
--- a/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/Ops.java
+++ b/tensorflow-core/tensorflow-core-api/src/gen/annotations/org/tensorflow/op/Ops.java
@@ -76,7 +76,11 @@
import org.tensorflow.op.core.Constant;
import org.tensorflow.op.core.ConsumeMutexLock;
import org.tensorflow.op.core.ControlTrigger;
+import org.tensorflow.op.core.Conv;
+import org.tensorflow.op.core.Conv2DBackpropFilterV2;
+import org.tensorflow.op.core.Conv2DBackpropInputV2;
import org.tensorflow.op.core.CopyToMesh;
+import org.tensorflow.op.core.CopyToMeshGrad;
import org.tensorflow.op.core.CountUpTo;
import org.tensorflow.op.core.DecodeProto;
import org.tensorflow.op.core.DeepCopy;
@@ -162,6 +166,8 @@
import org.tensorflow.op.core.Print;
import org.tensorflow.op.core.Prod;
import org.tensorflow.op.core.QuantizedReshape;
+import org.tensorflow.op.core.RaggedFillEmptyRows;
+import org.tensorflow.op.core.RaggedFillEmptyRowsGrad;
import org.tensorflow.op.core.RandomIndexShuffle;
import org.tensorflow.op.core.Range;
import org.tensorflow.op.core.Rank;
@@ -176,6 +182,7 @@
import org.tensorflow.op.core.RefSelect;
import org.tensorflow.op.core.RefSwitch;
import org.tensorflow.op.core.Relayout;
+import org.tensorflow.op.core.RelayoutLike;
import org.tensorflow.op.core.RemoteCall;
import org.tensorflow.op.core.Reshape;
import org.tensorflow.op.core.ResourceCountUpTo;
@@ -209,6 +216,10 @@
import org.tensorflow.op.core.ScatterNdUpdate;
import org.tensorflow.op.core.ScatterSub;
import org.tensorflow.op.core.ScatterUpdate;
+import org.tensorflow.op.core.SegmentMaxV2;
+import org.tensorflow.op.core.SegmentMinV2;
+import org.tensorflow.op.core.SegmentProdV2;
+import org.tensorflow.op.core.SegmentSumV2;
import org.tensorflow.op.core.Select;
import org.tensorflow.op.core.SetDiff1d;
import org.tensorflow.op.core.SetSize;
@@ -218,6 +229,9 @@
import org.tensorflow.op.core.Slice;
import org.tensorflow.op.core.Snapshot;
import org.tensorflow.op.core.SpaceToBatchNd;
+import org.tensorflow.op.core.SparseSegmentMeanGradV2;
+import org.tensorflow.op.core.SparseSegmentSqrtNGradV2;
+import org.tensorflow.op.core.SparseSegmentSumGradV2;
import org.tensorflow.op.core.Split;
import org.tensorflow.op.core.SplitV;
import org.tensorflow.op.core.Squeeze;
@@ -231,7 +245,6 @@
import org.tensorflow.op.core.StatefulPartitionedCall;
import org.tensorflow.op.core.StatefulWhile;
import org.tensorflow.op.core.StatelessIf;
-import org.tensorflow.op.core.StatelessPartitionedCall;
import org.tensorflow.op.core.StatelessWhile;
import org.tensorflow.op.core.StopGradient;
import org.tensorflow.op.core.StridedSlice;
@@ -240,6 +253,7 @@
import org.tensorflow.op.core.StridedSliceHelper;
import org.tensorflow.op.core.Sum;
import org.tensorflow.op.core.SwitchCond;
+import org.tensorflow.op.core.TPUPartitionedOutputV2;
import org.tensorflow.op.core.TemporaryVariable;
import org.tensorflow.op.core.TensorArray;
import org.tensorflow.op.core.TensorArrayClose;
@@ -381,10 +395,10 @@ public final class Ops {
public final SignalOps signal;
- public final QuantizationOps quantization;
-
public final TrainOps train;
+ public final QuantizationOps quantization;
+
private final Scope scope;
Ops(Scope scope) {
@@ -407,8 +421,8 @@ public final class Ops {
math = new MathOps(this);
audio = new AudioOps(this);
signal = new SignalOps(this);
- quantization = new QuantizationOps(this);
train = new TrainOps(this);
+ quantization = new QuantizationOps(this);
}
/**
@@ -1062,7 +1076,9 @@ public BatchToSpaceNd batchToSpaceNd(Operand input,
*
*
* NOTE: Bitcast is implemented as a low-level cast, so machines with different
- * endian orderings will give different results.
+ * endian orderings will give different results. A copy from input buffer to output
+ * buffer is made on BE machines when types are of different sizes in order to get
+ * the same casting results as on LE machines.
*
* @param data type for {@code output} output
* @param input The input value
@@ -2082,19 +2098,105 @@ public ControlTrigger controlTrigger() {
return ControlTrigger.create(scope);
}
+ /**
+ * Computes a N-D convolution given (N+1+batch_dims)-D {@code input} and (N+2)-D {@code filter} tensors.
+ * General function for computing a N-D convolution. It is required that
+ * {@code 1 <= N <= 3}.
+ *
+ * @param data type for {@code output} output
+ * @param input Tensor of type T and shape {@code batch_shape + spatial_shape + [in_channels]} in the
+ * case that {@code channels_last_format = true} or shape
+ * {@code batch_shape + [in_channels] + spatial_shape} if {@code channels_last_format = false}.
+ * spatial_shape is N-dimensional with {@code N=2} or {@code N=3}.
+ * Also note that {@code batch_shape} is dictated by the parameter {@code batch_dims}
+ * and defaults to 1.
+ * @param filter An {@code (N+2)-D} Tensor with the same type as {@code input} and shape
+ * {@code spatial_filter_shape + [in_channels, out_channels]}, where spatial_filter_shape
+ * is N-dimensional with {@code N=2} or {@code N=3}.
+ * @param strides 1-D tensor of length {@code N+2}. The stride of the sliding window for each
+ * dimension of {@code input}. Must have {@code strides[0] = strides[N+1] = 1}.
+ * @param padding The type of padding algorithm to use.
+ * @param options carries optional attribute values
+ * @param data type for {@code Conv} output and operands
+ * @return a new instance of Conv
+ */
+ public Conv conv(Operand input, Operand filter, List strides,
+ String padding, Conv.Options... options) {
+ return Conv.create(scope, input, filter, strides, padding, options);
+ }
+
+ /**
+ * Computes the gradients of convolution with respect to the filter.
+ *
+ * @param data type for {@code output} output
+ * @param input 4-D with shape {@code [batch, in_height, in_width, in_channels]}.
+ * @param filter 4-D with shape {@code [filter_height, filter_width, in_channels, out_channels]}.
+ * Only shape of tensor is used.
+ * @param outBackprop 4-D with shape {@code [batch, out_height, out_width, out_channels]}.
+ * Gradients w.r.t. the output of the convolution.
+ * @param strides The stride of the sliding window for each dimension of the input
+ * of the convolution. Must be in the same order as the dimension specified with
+ * format.
+ * @param padding The type of padding algorithm to use.
+ * @param options carries optional attribute values
+ * @param data type for {@code Conv2DBackpropFilterV2} output and operands
+ * @return a new instance of Conv2DBackpropFilterV2
+ */
+ public Conv2DBackpropFilterV2 conv2DBackpropFilterV2(Operand input,
+ Operand filter, Operand outBackprop, List strides, String padding,
+ Conv2DBackpropFilterV2.Options... options) {
+ return Conv2DBackpropFilterV2.create(scope, input, filter, outBackprop, strides, padding, options);
+ }
+
+ /**
+ * Computes the gradients of convolution with respect to the input.
+ *
+ * @param data type for {@code output} output
+ * @param input 4-D with shape {@code [batch, in_height, in_width, in_channels]}.
+ * Only shape of tensor is used.
+ * @param filter 4-D with shape
+ * {@code [filter_height, filter_width, in_channels, out_channels]}.
+ * @param outBackprop 4-D with shape {@code [batch, out_height, out_width, out_channels]}.
+ * Gradients w.r.t. the output of the convolution.
+ * @param strides The stride of the sliding window for each dimension of the input
+ * of the convolution. Must be in the same order as the dimension specified with
+ * format.
+ * @param padding The type of padding algorithm to use.
+ * @param options carries optional attribute values
+ * @param data type for {@code Conv2DBackpropInputV2} output and operands
+ * @return a new instance of Conv2DBackpropInputV2
+ */
+ public Conv2DBackpropInputV2 conv2DBackpropInputV2(Operand input,
+ Operand filter, Operand outBackprop, List strides, String padding,
+ Conv2DBackpropInputV2.Options... options) {
+ return Conv2DBackpropInputV2.create(scope, input, filter, outBackprop, strides, padding, options);
+ }
+
/**
* The CopyToMesh operation
*
* @param data type for {@code output} output
* @param input The input value
- * @param layout The value of the layout attribute
- * @param options carries optional attribute values
+ * @param mesh The value of the mesh attribute
* @param data type for {@code CopyToMesh} output and operands
* @return a new instance of CopyToMesh
*/
- public CopyToMesh copyToMesh(Operand input, String layout,
- CopyToMesh.Options... options) {
- return CopyToMesh.create(scope, input, layout, options);
+ public CopyToMesh copyToMesh(Operand input, String mesh) {
+ return CopyToMesh.create(scope, input, mesh);
+ }
+
+ /**
+ * The CopyToMeshGrad operation
+ *
+ * @param data type for {@code output} output
+ * @param input The input value
+ * @param forwardInput The forwardInput value
+ * @param data type for {@code CopyToMeshGrad} output and operands
+ * @return a new instance of CopyToMeshGrad
+ */
+ public CopyToMeshGrad copyToMeshGrad(Operand input,
+ Operand forwardInput) {
+ return CopyToMeshGrad.create(scope, input, forwardInput);
}
/**
@@ -2282,6 +2384,15 @@ public DestroyTemporaryVariable destroyTemporaryVariable(Op
*
*
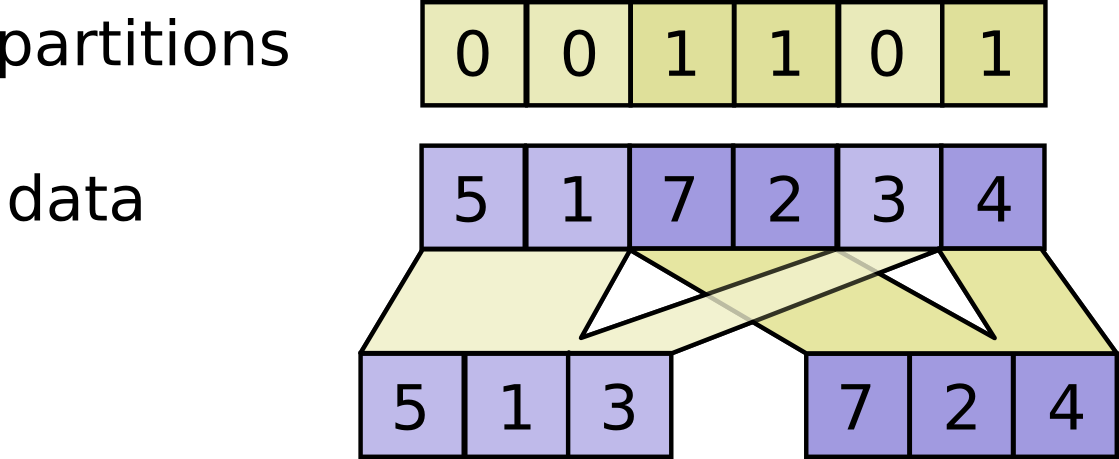
*
Raises:
+ *
+ * - {@code InvalidArgumentError} in following cases:
+ *
+ * - If partitions is not in range {@code [0, num_partiions)}
+ * - If {@code partitions.shape} does not match prefix of {@code data.shape} argument.
+ *
+ *
+ *
*
* @param data type for {@code outputs} output
* @param data The data value
@@ -4009,8 +4120,9 @@ public ParallelDynamicStitch parallelDynamicStitch(
/**
* returns {@code f(inputs)}, where {@code f}'s body is placed and partitioned.
- *
- * Selects between {@link StatefulPartitionedCall} and {@link StatelessPartitionedCall} based on the statefulness of the function arguments.
+ * Asynchronously executes a function, potentially across multiple devices but
+ * within a single process. The kernel places and partitions a given function's
+ * underlying graph, and executes each of the partitioned subgraphs as a function.
*
* @param args A list of input tensors.
* @param Tout A list of output types.
@@ -4018,8 +4130,7 @@ public ParallelDynamicStitch parallelDynamicStitch(
* A function that takes 'args', a list of tensors, and returns 'output',
* another list of tensors. Input and output types are specified by 'Tin'
* and 'Tout'. The function body of f will be placed and partitioned across
- * devices, setting this op apart from the regular Call op. This op is
- * stateful.
+ * devices, setting this op apart from the regular Call op.
*
* @param options carries optional attribute values
* @return a new instance of PartitionedCall
@@ -4108,6 +4219,36 @@ public QuantizedReshape quantizedReshape(Operand tensor,
return QuantizedReshape.create(scope, tensor, shape, inputMin, inputMax);
}
+ /**
+ * The RaggedFillEmptyRows operation
+ *
+ * @param data type for {@code output_values} output
+ * @param valueRowids The valueRowids value
+ * @param values The values value
+ * @param nrows The nrows value
+ * @param defaultValue The defaultValue value
+ * @param data type for {@code RaggedFillEmptyRows} output and operands
+ * @return a new instance of RaggedFillEmptyRows
+ */
+ public RaggedFillEmptyRows raggedFillEmptyRows(Operand valueRowids,
+ Operand values, Operand nrows, Operand defaultValue) {
+ return RaggedFillEmptyRows.create(scope, valueRowids, values, nrows, defaultValue);
+ }
+
+ /**
+ * The RaggedFillEmptyRowsGrad operation
+ *
+ * @param data type for {@code d_values} output
+ * @param reverseIndexMap The reverseIndexMap value
+ * @param gradValues The gradValues value
+ * @param data type for {@code RaggedFillEmptyRowsGrad} output and operands
+ * @return a new instance of RaggedFillEmptyRowsGrad
+ */
+ public RaggedFillEmptyRowsGrad raggedFillEmptyRowsGrad(
+ Operand reverseIndexMap, Operand gradValues) {
+ return RaggedFillEmptyRowsGrad.create(scope, reverseIndexMap, gradValues);
+ }
+
/**
* Outputs the position of {@code value} in a permutation of [0, ..., max_index].
* Output values are a bijection of the {@code index} for any combination and {@code seed} and {@code max_index}.
@@ -4119,12 +4260,13 @@ public QuantizedReshape quantizedReshape(Operand tensor,
* @param index A scalar tensor or a vector of dtype {@code dtype}. The index (or indices) to be shuffled. Must be within [0, max_index].
* @param seed A tensor of dtype {@code Tseed} and shape [3] or [n, 3]. The random seed.
* @param maxIndex A scalar tensor or vector of dtype {@code dtype}. The upper bound(s) of the interval (inclusive).
+ * @param options carries optional attribute values
* @param data type for {@code RandomIndexShuffle} output and operands
* @return a new instance of RandomIndexShuffle
*/
public RandomIndexShuffle randomIndexShuffle(Operand index,
- Operand seed, Operand maxIndex) {
- return RandomIndexShuffle.create(scope, index, seed, maxIndex);
+ Operand seed, Operand maxIndex, RandomIndexShuffle.Options... options) {
+ return RandomIndexShuffle.create(scope, index, seed, maxIndex, options);
}
/**
@@ -4360,6 +4502,20 @@ public Relayout relayout(Operand input, String layout) {
return Relayout.create(scope, input, layout);
}
+ /**
+ * The RelayoutLike operation
+ *
+ * @param data type for {@code output} output
+ * @param input The input value
+ * @param layoutInput The layoutInput value
+ * @param data type for {@code RelayoutLike} output and operands
+ * @return a new instance of RelayoutLike
+ */
+ public RelayoutLike relayoutLike(Operand input,
+ Operand layoutInput) {
+ return RelayoutLike.create(scope, input, layoutInput);
+ }
+
/**
* Runs function {@code f} on a remote device indicated by {@code target}.
*
@@ -5275,7 +5431,7 @@ public ScatterMul scatterMul(Operand ref,
*
* In Python, this scatter operation would look like this:
*
- * indices = tf.constant([[0], [2]])
+ * indices = tf.constant([[1], [3]])
* updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
* [7, 7, 7, 7], [8, 8, 8, 8]],
* [[5, 5, 5, 5], [6, 6, 6, 6],
@@ -5286,10 +5442,10 @@ public ScatterMul scatterMul(Operand ref,
*
* The resulting tensor would look like this:
*
- * [[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
- * [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]],
+ * [[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]],
* [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
- * [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]
+ * [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]],
+ * [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]]]
*
* Note that on CPU, if an out of bound index is found, an error is returned.
* On GPU, if an out of bound index is found, the index is ignored.
@@ -5555,6 +5711,197 @@ public ScatterUpdate scatterUpdate(Operand ref,
return ScatterUpdate.create(scope, ref, indices, updates, options);
}
+ /**
+ * Computes the maximum along segments of a tensor.
+ * Read
+ * the section on segmentation
+ * for an explanation of segments.
+ * Computes a tensor such that
+ * \(output_i = \max_j(data_j)\) where {@code max} is over {@code j} such
+ * that {@code segment_ids[j] == i}.
+ *
If the maximum is empty for a given segment ID {@code i}, it outputs the smallest
+ * possible value for the specific numeric type,
+ * {@code output[i] = numeric_limits::lowest()}.
+ * Note: That this op is currently only supported with jit_compile=True.
+ *
Caution: On CPU, values in {@code segment_ids} are always validated to be sorted,
+ * and an error is thrown for indices that are not increasing. On GPU, this
+ * does not throw an error for unsorted indices. On GPU, out-of-order indices
+ * result in safe but unspecified behavior, which may include treating
+ * out-of-order indices as the same as a smaller following index.
+ *
The only difference with SegmentMax is the additional input {@code num_segments}.
+ * This helps in evaluating the output shape in compile time.
+ * {@code num_segments} should be consistent with segment_ids.
+ * e.g. Max(segment_ids) should be equal to {@code num_segments} - 1 for a 1-d segment_ids
+ * With inconsistent num_segments, the op still runs. only difference is,
+ * the output takes the size of num_segments irrespective of size of segment_ids and data.
+ * for num_segments less than expected output size, the last elements are ignored
+ * for num_segments more than the expected output size, last elements are assigned
+ * smallest possible value for the specific numeric type.
+ *
For example:
+ *
+ *
+ *
+ * {@literal @}tf.function(jit_compile=True)
+ * ... def test(c):
+ * ... return tf.raw_ops.SegmentMaxV2(data=c, segment_ids=tf.constant([0, 0, 1]), num_segments=2)
+ * c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]])
+ * test(c).numpy()
+ * array([[4, 3, 3, 4],
+ * [5, 6, 7, 8]], dtype=int32)
+ *
+ *
+ *
+ *
+ * @param data type for {@code output} output
+ * @param data The data value
+ * @param segmentIds A 1-D tensor whose size is equal to the size of {@code data}'s
+ * first dimension. Values should be sorted and can be repeated.
+ * The values must be less than {@code num_segments}.
+ * Caution: The values are always validated to be sorted on CPU, never validated
+ * on GPU.
+ * @param numSegments The numSegments value
+ * @param data type for {@code SegmentMaxV2} output and operands
+ * @return a new instance of SegmentMaxV2
+ */
+ public SegmentMaxV2 segmentMaxV2(Operand data,
+ Operand segmentIds, Operand numSegments) {
+ return SegmentMaxV2.create(scope, data, segmentIds, numSegments);
+ }
+
+ /**
+ * Computes the minimum along segments of a tensor.
+ * Read
+ * the section on segmentation
+ * for an explanation of segments.
+ * Computes a tensor such that
+ * \(output_i = \min_j(data_j)\) where {@code min} is over {@code j} such
+ * that {@code segment_ids[j] == i}.
+ *
If the minimum is empty for a given segment ID {@code i}, it outputs the largest
+ * possible value for the specific numeric type,
+ * {@code output[i] = numeric_limits::max()}.
+ * Note: That this op is currently only supported with jit_compile=True.
+ *
Caution: On CPU, values in {@code segment_ids} are always validated to be sorted,
+ * and an error is thrown for indices that are not increasing. On GPU, this
+ * does not throw an error for unsorted indices. On GPU, out-of-order indices
+ * result in safe but unspecified behavior, which may include treating
+ * out-of-order indices as the same as a smaller following index.
+ *
The only difference with SegmentMin is the additional input {@code num_segments}.
+ * This helps in evaluating the output shape in compile time.
+ * {@code num_segments} should be consistent with segment_ids.
+ * e.g. Max(segment_ids) should be equal to {@code num_segments} - 1 for a 1-d segment_ids
+ * With inconsistent num_segments, the op still runs. only difference is,
+ * the output takes the size of num_segments irrespective of size of segment_ids and data.
+ * for num_segments less than expected output size, the last elements are ignored
+ * for num_segments more than the expected output size, last elements are assigned
+ * the largest possible value for the specific numeric type.
+ *
For example:
+ *
+ *
+ *
+ * {@literal @}tf.function(jit_compile=True)
+ * ... def test(c):
+ * ... return tf.raw_ops.SegmentMinV2(data=c, segment_ids=tf.constant([0, 0, 1]), num_segments=2)
+ * c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]])
+ * test(c).numpy()
+ * array([[1, 2, 2, 1],
+ * [5, 6, 7, 8]], dtype=int32)
+ *
+ *
+ *
+ *
+ * @param data type for {@code output} output
+ * @param data The data value
+ * @param segmentIds A 1-D tensor whose size is equal to the size of {@code data}'s
+ * first dimension. Values should be sorted and can be repeated.
+ * The values must be less than {@code num_segments}.
+ * Caution: The values are always validated to be sorted on CPU, never validated
+ * on GPU.
+ * @param numSegments The numSegments value
+ * @param data type for {@code SegmentMinV2} output and operands
+ * @return a new instance of SegmentMinV2
+ */
+ public SegmentMinV2 segmentMinV2(Operand data,
+ Operand segmentIds, Operand numSegments) {
+ return SegmentMinV2.create(scope, data, segmentIds, numSegments);
+ }
+
+ /**
+ * Computes the product along segments of a tensor.
+ * Read
+ * the section on segmentation
+ * for an explanation of segments.
+ * Computes a tensor such that
+ * \(output_i = \prod_j data_j\) where the product is over {@code j} such
+ * that {@code segment_ids[j] == i}.
+ *
If the product is empty for a given segment ID {@code i}, {@code output[i] = 1}.
+ *
Note: That this op is currently only supported with jit_compile=True.
+ *
The only difference with SegmentProd is the additional input {@code num_segments}.
+ * This helps in evaluating the output shape in compile time.
+ * {@code num_segments} should be consistent with segment_ids.
+ * e.g. Max(segment_ids) - 1 should be equal to {@code num_segments} for a 1-d segment_ids
+ * With inconsistent num_segments, the op still runs. only difference is,
+ * the output takes the size of num_segments irrespective of size of segment_ids and data.
+ * for num_segments less than expected output size, the last elements are ignored
+ * for num_segments more than the expected output size, last elements are assigned 1.
+ *
For example:
+ *
+ *
+ *
+ * {@literal @}tf.function(jit_compile=True)
+ * ... def test(c):
+ * ... return tf.raw_ops.SegmentProdV2(data=c, segment_ids=tf.constant([0, 0, 1]), num_segments=2)
+ * c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]])
+ * test(c).numpy()
+ * array([[4, 6, 6, 4],
+ * [5, 6, 7, 8]], dtype=int32)
+ *
+ *
+ *
+ *
+ * @param data type for {@code output} output
+ * @param data The data value
+ * @param segmentIds A 1-D tensor whose size is equal to the size of {@code data}'s
+ * first dimension. Values should be sorted and can be repeated.
+ * The values must be less than {@code num_segments}.
+ * Caution: The values are always validated to be sorted on CPU, never validated
+ * on GPU.
+ * @param numSegments The numSegments value
+ * @param data type for {@code SegmentProdV2} output and operands
+ * @return a new instance of SegmentProdV2
+ */
+ public SegmentProdV2 segmentProdV2(Operand data,
+ Operand segmentIds, Operand numSegments) {
+ return SegmentProdV2.create(scope, data, segmentIds, numSegments);
+ }
+
+ /**
+ * Computes the sum along segments of a tensor.
+ * Read
+ * the section on segmentation
+ * for an explanation of segments.
+ * Computes a tensor such that
+ * \(output_i = \sum_j data_j\) where sum is over {@code j} such
+ * that {@code segment_ids[j] == i}.
+ *
If the sum is empty for a given segment ID {@code i}, {@code output[i] = 0}.
+ *
Note that this op is currently only supported with jit_compile=True.
+ *
+ *
+ * @param data type for {@code output} output
+ * @param data The data value
+ * @param segmentIds A 1-D tensor whose size is equal to the size of {@code data}'s
+ * first dimension. Values should be sorted and can be repeated.
+ * The values must be less than {@code num_segments}.
+ * Caution: The values are always validated to be sorted on CPU, never validated
+ * on GPU.
+ * @param numSegments The numSegments value
+ * @param data type for {@code SegmentSumV2} output and operands
+ * @return a new instance of SegmentSumV2
+ */
+ public SegmentSumV2 segmentSumV2(Operand data,
+ Operand segmentIds, Operand numSegments) {
+ return SegmentSumV2.create(scope, data, segmentIds, numSegments);
+ }
+
/**
* The SelectV2 operation
*
@@ -5638,7 +5985,8 @@ public SetDiff1d setDiff1d(Operand
* and {@code set_shape}. The last dimension contains values in a set, duplicates are
* allowed but ignored.
* If {@code validate_indices} is {@code True}, this op validates the order and range of {@code set}
- * indices.
+ * indices. Setting is to {@code False} while passing invalid arguments results in
+ * undefined behavior.
*
* @param setIndices 2D {@code Tensor}, indices of a {@code SparseTensor}.
* @param setValues 1D {@code Tensor}, values of a {@code SparseTensor}.
@@ -5917,6 +6265,72 @@ public SpaceToBatchNd spaceToBatchNd(Operand input,
return SpaceToBatchNd.create(scope, input, blockShape, paddings);
}
+ /**
+ * Computes gradients for SparseSegmentMean.
+ * Returns tensor "output" with same shape as grad, except for dimension 0 whose
+ * value is the number of unique indexes in "indices". Also returns vector
+ * "sorted_unique_indices" containing the corresponding indexes from "indices".
+ *
+ * @param data type for {@code output} output
+ * @param data type for {@code sorted_unique_indices} output
+ * @param grad gradient propagated to the SparseSegmentMean op.
+ * @param indices indices passed to the corresponding SparseSegmentMean op.
+ * @param segmentIds segment_ids passed to the corresponding SparseSegmentMean op.
+ * @param denseOutputDim0 dimension 0 of "data" passed to SparseSegmentMean op.
+ * @param data type for {@code SparseSegmentMeanGradV2} output and operands
+ * @param data type for {@code SparseSegmentMeanGradV2} output and operands
+ * @return a new instance of SparseSegmentMeanGradV2
+ */
+ public SparseSegmentMeanGradV2 sparseSegmentMeanGradV2(
+ Operand grad, Operand indices, Operand segmentIds,
+ Operand denseOutputDim0) {
+ return SparseSegmentMeanGradV2.create(scope, grad, indices, segmentIds, denseOutputDim0);
+ }
+
+ /**
+ * Computes gradients for SparseSegmentSqrtN.
+ * Returns tensor "output" with same shape as grad, except for dimension 0 whose
+ * value is the number of unique indexes in "indices". Also returns vector
+ * "sorted_unique_indices" containing the corresponding indexes from "indices".
+ *
+ * @param data type for {@code output} output
+ * @param data type for {@code sorted_unique_indices} output
+ * @param grad gradient propagated to the SparseSegmentSqrtN op.
+ * @param indices indices passed to the corresponding SparseSegmentSqrtN op.
+ * @param segmentIds segment_ids passed to the corresponding SparseSegmentSqrtN op.
+ * @param denseOutputDim0 dimension 0 of "data" passed to SparseSegmentSqrtN op.
+ * @param data type for {@code SparseSegmentSqrtNGradV2} output and operands
+ * @param data type for {@code SparseSegmentSqrtNGradV2} output and operands
+ * @return a new instance of SparseSegmentSqrtNGradV2
+ */
+ public SparseSegmentSqrtNGradV2 sparseSegmentSqrtNGradV2(
+ Operand grad, Operand indices, Operand segmentIds,
+ Operand denseOutputDim0) {
+ return SparseSegmentSqrtNGradV2.create(scope, grad, indices, segmentIds, denseOutputDim0);
+ }
+
+ /**
+ * Computes gradients for SparseSegmentSum.
+ * Returns tensor "output" with same shape as grad, except for dimension 0 whose
+ * value is the number of unique indexes in "indices". Also returns vector
+ * "sorted_unique_indices" containing the corresponding indexes from "indices".
+ *
+ * @param data type for {@code output} output
+ * @param data type for {@code sorted_unique_indices} output
+ * @param grad gradient propagated to the SparseSegmentSum op.
+ * @param indices indices passed to the corresponding SparseSegmentSum op.
+ * @param segmentIds segment_ids passed to the corresponding SparseSegmentSum op.
+ * @param denseOutputDim0 dimension 0 of "data" passed to SparseSegmentSum op.
+ * @param data type for {@code SparseSegmentSumGradV2} output and operands
+ * @param data type for {@code SparseSegmentSumGradV2} output and operands
+ * @return a new instance of SparseSegmentSumGradV2
+ */
+ public SparseSegmentSumGradV2 sparseSegmentSumGradV2(
+ Operand grad, Operand indices, Operand segmentIds,
+ Operand denseOutputDim0) {
+ return SparseSegmentSumGradV2.create(scope, grad, indices, segmentIds, denseOutputDim0);
+ }
+
/**
* Splits a tensor into {@code num_split} tensors along one dimension.
*
@@ -6141,7 +6555,8 @@ public StatefulIf statefulIf(Operand cond, Iterable>
* @return a new instance of StatefulPartitionedCall
*/
public StatefulPartitionedCall statefulPartitionedCall(Iterable> args,
- List> Tout, ConcreteFunction f, PartitionedCall.Options... options) {
+ List> Tout, ConcreteFunction f,
+ StatefulPartitionedCall.Options... options) {
return StatefulPartitionedCall.create(scope, args, Tout, f, options);
}
@@ -6204,28 +6619,6 @@ public StatelessIf statelessIf(Operand cond, Iterable
- * A function that takes 'args', a list of tensors, and returns 'output',
- * another list of tensors. Input and output types are specified by 'Tin'
- * and 'Tout'. The function body of f will be placed and partitioned across
- * devices, setting this op apart from the regular Call op.
- *
- * @param options carries optional attribute values
- * @return a new instance of StatelessPartitionedCall
- */
- public StatelessPartitionedCall statelessPartitionedCall(Iterable> args,
- List> Tout, ConcreteFunction f, PartitionedCall.Options... options) {
- return StatelessPartitionedCall.create(scope, args, Tout, f, options);
- }
-
/**
* output = input; While (Cond(output)) { output = Body(output) }
*
@@ -6605,6 +6998,23 @@ public SwitchCond switchCond(Operand data, Operand data type for {@code output} output
+ * @param inputs A tensor which represents the full shape of partitioned tensors.
+ * @param numSplits The value of the numSplits attribute
+ * @param partitionDims A list of integers describing how each dimension is partitioned. Emptiness
+ * indicates the inputs are replicated.
+ * @param data type for {@code TPUPartitionedOutputV2} output and operands
+ * @return a new instance of TPUPartitionedOutputV2
+ */
+ public TPUPartitionedOutputV2 tPUPartitionedOutputV2(Operand inputs,
+ Long numSplits, List partitionDims) {
+ return TPUPartitionedOutputV2.create(scope, inputs, numSplits, partitionDims);
+ }
+
/**
* Returns a tensor that may be mutated, but only persists within a single step.
* This is an experimental op for internal use only and it is possible to use this
@@ -6665,7 +7075,9 @@ public TensorArrayClose tensorArrayClose(Operand handle) {
* (n0 x d0 x d1 x ...), (n1 x d0 x d1 x ...), ..., (n(T-1) x d0 x d1 x ...)
*
* and concatenates them into a Tensor of shape:
- *
{@code (n0 + n1 + ... + n(T-1) x d0 x d1 x ...)}
+ *
+ * (n0 + n1 + ... + n(T-1) x d0 x d1 x ...)
+ *
* All elements must have the same shape (excepting the first dimension).
*
* @param data type for {@code value} output
@@ -6825,14 +7237,22 @@ public TensorArraySize tensorArraySize(Operand handle,
/**
* Split the data from the input value into TensorArray elements.
* Assuming that {@code lengths} takes on values
- * {@code (n0, n1, ..., n(T-1))}
+ *
+ * (n0, n1, ..., n(T-1))
+ *
* and that {@code value} has shape
- *
{@code (n0 + n1 + ... + n(T-1) x d0 x d1 x ...)},
+ *
+ * (n0 + n1 + ... + n(T-1) x d0 x d1 x ...),
+ *
* this splits values into a TensorArray with T tensors.
*
TensorArray index t will be the subtensor of values with starting position
- *
{@code (n0 + n1 + ... + n(t-1), 0, 0, ...)}
+ *
+ * (n0 + n1 + ... + n(t-1), 0, 0, ...)
+ *
* and having size
- *
{@code nt x d0 x d1 x ...}
+ *
+ * nt x d0 x d1 x ...
+ *
*
* @param handle The handle to a TensorArray.
* @param value The concatenated tensor to write to the TensorArray.
@@ -6968,7 +7388,10 @@ public TensorListGather tensorListGather(
}
/**
- * The TensorListGetItem operation
+ * Returns the item in the list with the given index.
+ * input_handle: the list
+ * index: the position in the list from which an element will be retrieved
+ * item: the element at that position
*
* @param data type for {@code item} output
* @param inputHandle The inputHandle value
@@ -7123,16 +7546,21 @@ public TensorListScatterIntoExistingList tensorListScatterIntoExistingList(
}
/**
- * The TensorListSetItem operation
+ * Sets the index-th position of the list to contain the given tensor.
+ * input_handle: the list
+ * index: the position in the list to which the tensor will be assigned
+ * item: the element to be assigned to that position
+ * output_handle: the new list, with the element in the proper position
*
* @param inputHandle The inputHandle value
* @param index The index value
* @param item The item value
+ * @param options carries optional attribute values
* @return a new instance of TensorListSetItem
*/
public TensorListSetItem tensorListSetItem(Operand inputHandle,
- Operand index, Operand item) {
- return TensorListSetItem.create(scope, inputHandle, index, item);
+ Operand index, Operand item, TensorListSetItem.Options... options) {
+ return TensorListSetItem.create(scope, inputHandle, index, item, options);
}
/**
@@ -7574,8 +8002,16 @@ public Tile tile(Operand input, OperandNote: the timestamp is computed when the op is executed, not when it is added
- * to the graph.
+ * Common usages include:
+ *
+ * - Logging
+ * - Providing a random number seed
+ * - Debugging graph execution
+ * - Generating timing information, mainly through comparison of timestamps
+ *
+ * Note: In graph mode, the timestamp is computed when the op is executed,
+ * not when it is added to the graph. In eager mode, the timestamp is computed
+ * when the op is eagerly executed.
*
* @return a new instance of Timestamp
*/
@@ -7806,7 +8242,7 @@ public Unique unique(Operand x,
* For example:
*
* x = tf.constant([1, 1, 2, 4, 4, 4, 7, 8, 8])
- * y, idx, count = UniqueWithCountsV2(x, axis = [0])
+ * y, idx, count = tf.raw_ops.UniqueWithCountsV2(x=x, axis = [0])
* y ==> [1, 2, 4, 7, 8]
* idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]
* count ==> [2, 1, 3, 1, 2]
@@ -7816,7 +8252,7 @@ public Unique unique(Operand x,
* x = tf.constant([[1, 0, 0],
* [1, 0, 0],
* [2, 0, 0]])
- * y, idx, count = UniqueWithCountsV2(x, axis=[0])
+ * y, idx, count = tf.raw_ops.UniqueWithCountsV2(x=x, axis=[0])
* y ==> [[1, 0, 0],
* [2, 0, 0]]
* idx ==> [0, 0, 1]
@@ -7827,7 +8263,7 @@ public Unique unique(Operand x,
* x = tf.constant([[1, 0, 0],
* [1, 0, 0],
* [2, 0, 0]])
- * y, idx, count = UniqueWithCountsV2(x, axis=[1])
+ * y, idx, count = tf.raw_ops.UniqueWithCountsV2(x=x, axis=[1])
* y ==> [[1, 0],
* [1, 0],
* [2, 0]]
@@ -7862,7 +8298,7 @@ public UniqueWithCounts uniqueWithCounts(Operand
* For example:
*
* x = tf.constant([1, 1, 2, 4, 4, 4, 7, 8, 8])
- * y, idx, count = UniqueWithCountsV2(x, axis = [0])
+ * y, idx, count = tf.raw_ops.UniqueWithCountsV2(x=x, axis = [0])
* y ==> [1, 2, 4, 7, 8]
* idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]
* count ==> [2, 1, 3, 1, 2]
@@ -7872,7 +8308,7 @@ public UniqueWithCounts