- Table of Contents
- Contributing to tt-metal
- Machine setup
- Developing tt-metal
- Tests in tt-metal
- Debugging guide
- Contribution standards
- Hardware troubleshooting
Thank you for your interest in this project.
If you are interested in making a contribution, then please familiarize yourself with our technical contribution standards as set forth in this guide.
Next, please request appropriate write permissions by opening an issue for GitHub permissions.
All contributions require:
- an issue
- Your issue should be filed under an appropriate project. Please file a feature support request or bug report under Issues to get help with finding an appropriate project to get a maintainer's attention.
- a pull request (PR).
- Your PR must be approved by appropriate reviewers.
Furthermore, all PRs must follow the contribution standards.
Hugepages is required to both run and develop on the Metalium project.
If you ever need to re-enable Hugepages, you can try the script we homemade for this:
sudo python3 infra/machine_setup/scripts/setup_hugepages.py enable
Then to check if Hugepages is enabled:
python3 infra/machine_setup/scripts/setup_hugepages.py check
Currently, the most convenient way to develop is to do so on our cloud machines. They have prerequisite dependencies, model files, and other settings set up for users.
Please refer to the README for source installation and environment setup instructions, then please read the Getting Started page.
In order to get debug level log messages, set the environment variable
TT_METAL_LOGGER_LEVEL=Debug.
For example,
TT_METAL_LOGGER_LEVEL=Debug ./build/test/tt_metal/test_add_two_ints
-
First, ensure that you have built the project and activated the Python environment, along with any required
PYTHONPATHvariables. -
Build the HTML documentation.
cd docs
make clean
make html
You can optionally build and view the ttnn sweeps results with:
make ttnn_sweeps/check_directory
make ttnn_sweeps
then turn on the server to view.
make server
You can customize the port by using the PORT=<port> environment variable. If
you're using a customer-facing cloud machine, please disregard this point.
- Navigate to the docs page.
Navigate your web browser to http://<ip address>:<port>, where <ip address>
is the IP address of the machine on which you launched the web server. For
example: http://10.250.37.37:4242, for port 4242.
If you forwarded your port, navigate to http://localhost:8888.
- If you make changes, you may need to check spelling errors.
We use the spell-checker, Aspell, to ensure we don't sneak in some typos in our documentation. This is enforced by static-checks on github workflows as well.
To check if your updated docs pass this check you can run,
$ cd ${TT_METAL_HOME} && ./docs/spellcheck.shIf there are errors in this check you will see an exit code non-zero.
To update the documentation for spelling errors or any out-of-dictionary words you can run,
$ cd ${TT_METAL_HOME} && ./docs/spellcheck.sh updateCommit your changes and the personal dictionary, at docs/aspell-dictionary.pws, that is changed.
Ensure you're in a developer Python environment with necessary environment variables set as documented in the developing section.
This includes the environment variables, Python dev environment etc.
All developers are responsible for ensuring that post-commit regressions pass upon any submission to the project. We will cover how to run these regressions both locally and on CI. Failure to ensure these tests pass will constitute a major regression and will likely mean reverting your commits.
You must run post-commit regressions before you commit something.
These regressions will also run after every pushed commit to the GitHub repo.
cmake --build build --target install
cmake --build build --target tests
./tests/scripts/run_tests.sh --tt-arch $ARCH_NAME --pipeline-type post_commit
If changes affect tensor or tt_dnn libraries, run this suite of pytests
which tests tensor APIs and tt_dnn ops. These are also tested in post
commit.
pytest tests/python_api_testing/unit_testing/ -vvv
pytest tests/python_api_testing/sweep_tests/pytests/ -vvv
If you would like to run the post-commit tests on GitHub Actions, please refer to using CI for development.
Make sure to add post-commit tests in the at the lowest two levels of the tests directory to make sure tests are executed on the workflows.
New shell scripts added above the lowest two levels may not be executed on the post-commit workflows!
After building the repo and activating the dev environment with the appropriate environment variables, you have two options for running performance regressions on model tests.
If you are using a machine with virtual machine specs, please use
./tests/scripts/run_tests.sh --tt-arch $ARCH_NAME --pipeline-type models_performance_virtual_machine
If you are using a machine with bare metal machine specs, please use
./tests/scripts/run_tests.sh --tt-arch $ARCH_NAME --pipeline-type models_performance_bare_metal
We have a legacy suite of C++ integration tests that are built like standalone executables. This section goes over how to generally run such tests if there's a specific one you'd like to run.
- Build the API integration tests using the make command,
cmake --build build --target tests
- Run the test binaries from the path ${TT_METAL_HOME}/build/test/tt_metal
The new fangled way we run our tests is with Googletest. The way we generally structure our tests with this framework is to bundle it into a single executable.
You can use --gtest_filter to filter out the specific test you'd like.
For example, to build and run the DispatchFixture.TensixDRAMLoopbackSingleCore on
fast dispatch, you can
- Build the unit tests:
cmake --build build --target tests - Run the test:
./build/test/tt_metal/unit_tests_api --gtest_filter="DispatchFixture.TensixDRAMLoopbackSingleCore"
On slow dispatch, to run another specific test, the equivalent would be:
- Build the unit tests as you would above.
- Run with the slow dispatch mode:
export TT_METAL_SLOW_DISPATCH_MODE=1 ./build/test/tt_metal/unit_tests/unit_tests_api --gtest_filter="DeviceSingleCardBufferFixture.TestL1BuffersAllocatedTopDown"
We have split our tests into the two dispatch modes for less pollution of state between the two. We would like to eventually enable switching between the two modes easily.
We use pytest to run our Python-based tests. This is the general procedure for running such tests.
- Run the specific test point with pytest tool, e.g.
$ pytest tests/tt_eager/python_api_testing/sweep_tests/pytests/tt_dnn/test_composite.py - If you have any issues with import paths for python libraries include the following environment variable,
$ export PYTHONPATH=${PYTHONPATH}:${TT_METAL_HOME}
- GDB can be used to debug Metalium C++ host APIs and C++ Python binding files.
- Build with debug symbols:
CONFIG=Debug ./build_metal.sh - To debug Metalium C++ host APIs, run
gdb --args <generated binary> - To debug the C++ binding file itself:
- Ensure the python file you wish to debug is standalone and has a main function.
- Run
gdb --args python <python file>
- Breakpoints can be added for future loaded libraries. For example, to add a breakpoint to
Deviceobject constructor:
- Build with debug symbols:
(gdb) b device.cpp:Device::Device
No source file named device.cpp.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (device.cpp:Device::Device) pending.
(gdb) r
...
Breakpoint 1, tt::tt_metal::Device::Device (this=0x3c, device_id=21845, num_hw_cqs=24 '\030', l1_small_size=140737349447680, l1_bank_remap=<>, minimal=119) at tt-metal/tt_metal/impl/device/device.cpp
71 Device::Device(
- To log the compiler defines passed in with
-Dduring the kernel build phase:- Run with Watcher enabled,
export TT_METAL_WATCHER=1 - Files with the kernel configurations are generated as
<tt-metal dir>/built/<device id>/kernels/kernel_args.csv
- Run with Watcher enabled,
- To examine the compile time arguments of a kernel:
- Within your kernel, assign the arguments to constexpr like this:
constexpr uint32_t in1_mcast_sender_noc_y = get_compile_time_arg_val(0); - Run
dump-constexprs.pyscript on the generated ELF file. E.g.python tt_metal/tools/dump-consts.py built/0/kernels/command_queue_producer/1129845549852061924/brisc/brisc.elf --function kernel_main. Note: debug information (DWARF) must be present in ELF files (compiler option-g). To enable, add TT_METAL_RISCV_DEBUG_INFO=1 environment variable.
- Within your kernel, assign the arguments to constexpr like this:
- For developing device-side code, it is recommended to always run with Watcher enabled. Set the environment variable to 10 to have the watcher server update every 10 seconds:
export TT_METAL_WATCHER=10- Running with watcher enabled will include code that validates NoC transactions, as well as on-device assertions.
- Watcher will flag illegal NoC transactions that may seem to run ok without watcher, this is expected (e.g., 0 length transactions are not considered safe but appear safe in practice).
- If watcher detects an error, an appropriate message will be displayed, the problematic core will be stalled, and the program will exit. For more information on watcher debug features, see the Watcher documentation.
- Once the design has been "proven", disable watcher for performance testing.
- To print within a kernel, use the Debug Print API:
- Define the environment variable to specify which cores to print from,
export TT_METAL_DPRINT_CORES=(0,0)-(4,4)to print from a 5x5 grid of cores. - In the kernel,
#include "debug/dprint.h", and to print a variablex,DPRINT << x << ENDL(); - For more information on kernel printing, see the Kernel Debug Print documentation.
- Define the environment variable to specify which cores to print from,
- Try to always develop with Watcher enabled. It can catch certain errors and asserts and report them, as well as providing useful debug information in the case of a hang.
- If watcher is enabled when your program hangs, make sure that
Watcher checking device <n>is being printed, then kill your program.- Make sure that the watcher didn't explicitly catch any errors and print them on
stdout. For example, the following is printed if the watcher catches a NoC transaction with bad alignment:
- Make sure that the watcher didn't explicitly catch any errors and print them on
TT_METAL_WATCHER=10 ./your_program
...
Always | WARNING | Watcher detected NOC error and stopped device: bad alignment in NOC transaction.
Always | WARNING | Device 0 worker core(x= 0,y= 0) virtual(x= 1,y= 1): brisc using noc0 tried to access DRAM core w/ physical coords (x=0,y=11) DRAM[addr=0x00003820,len=102400], misaligned with local L1[addr=0x00064010]
Always | INFO | Last waypoint: NARW, W, W, W, W
Always | INFO | While running kernels:
Always | INFO | brisc : tests/tt_metal/tt_metal/test_kernels/dataflow/dram_copy.cpp
Always | INFO | ncrisc: blank
Always | INFO | triscs: blank
Test | INFO | Reported error: Device 0 worker core(x= 0,y= 0) virtual(x= 1,y= 1): brisc using noc0 tried to access DRAM core w/ physical coords (x=0,y=11) DRAM[addr=0x00003820,len=102400], misaligned with local L1[addr=0x00064010]
Always | FATAL | Watcher detected NOC error and stopped device: bad alignment in NOC transaction.
- If no such error is reported, but the program is hanging, check the watcher log generated in
generated/watcher/watcher.log. There is a legend at the top of the log showing how to interpret it, and a sample portion of a log is shown below:
Legend:
Comma separated list specifies waypoint for BRISC,NCRISC,TRISC0,TRISC1,TRISC2
I=initialization sequence
W=wait (top of spin loop)
R=run (entering kernel)
D=done (finished spin loop)
X=host written value prior to fw launch
A single character status is in the FW, other characters clarify where, eg:
NRW is "noc read wait"
NWD is "noc write done"
noc<n>:<risc>{a, l}=an L1 address used by NOC<n> by <riscv> (eg, local src address)
noc<n>:<riscv>{(x,y), a, l}=NOC<n> unicast address used by <riscv>
noc<n>:<riscv>{(x1,y1)-(x2,y2), a, l}=NOC<n> multicast address used by <riscv>
rmsg:<c>=brisc host run message, D/H device/host dispatch; brisc NOC ID; I/G/D init/go/done; | separator; B/b enable/disable brisc; N/n enable/disable ncrisc; T/t enable/disable TRISC
smsg:<c>=slave run message, I/G/D for NCRISC, TRISC0, TRISC1, TRISC2
k_ids:<brisc id>|<ncrisc id>|<trisc id> (ID map to file at end of section)
...
Dump #7 at 8.992s
Device 0 worker core(x= 0,y= 0) virtual(x= 1,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 1,y= 0) virtual(x= 2,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 2,y= 0) virtual(x= 3,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 3,y= 0) virtual(x= 4,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 4,y= 0) virtual(x= 6,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 5,y= 0) virtual(x= 7,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 6,y= 0) virtual(x= 8,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 7,y= 0) virtual(x= 9,y= 1): GW, W, W, W, W rmsg:D0D|BNT smsg:DDDD k_ids:14|13|15
Device 0 worker core(x= 0,y= 7) virtual(x= 1,y=10): NTW,UAPW, W, W, W rmsg:H1G|bNt smsg:GDDD k_ids:0|2|0
Device 0 worker core(x= 1,y= 7) virtual(x= 2,y=10): NTW, HQW, W, W, W rmsg:H1G|bNt smsg:GDDD k_ids:0|1|0
Device 0 worker core(x= 2,y= 7) virtual(x= 3,y=10): NTW, HQW, W, W, W rmsg:H1G|bNt smsg:GDDD k_ids:0|3|0
Device 0 worker core(x= 3,y= 7) virtual(x= 4,y=10): NTW,UAPW, W, W, W rmsg:H1G|bNt smsg:GDDD k_ids:0|7|0
Device 0 worker core(x= 4,y= 7) virtual(x= 6,y=10): NABD, W, W, W, W rmsg:H0G|Bnt smsg:DDDD k_ids:4|0|0
Device 0 worker core(x= 5,y= 7) virtual(x= 7,y=10): NABD, W, W, W, W rmsg:H0G|Bnt smsg:DDDD k_ids:6|0|0
Device 0 worker core(x= 6,y= 7) virtual(x= 8,y=10): GW, W, W, W, W rmsg:H0D|bnt smsg:DDDD k_ids:0|0|0
Device 0 worker core(x= 7,y= 7) virtual(x= 9,y=10): GW, W, W, W, W rmsg:H0D|bnt smsg:DDDD k_ids:0|0|0
k_id[0]: blank
k_id[1]: tt_metal/impl/dispatch/kernels/cq_prefetch.cpp
k_id[2]: tt_metal/impl/dispatch/kernels/cq_dispatch.cpp
k_id[3]: tt_metal/impl/dispatch/kernels/cq_prefetch.cpp
k_id[4]: tt_metal/impl/dispatch/kernels/packet_mux.cpp
k_id[5]: tt_metal/impl/dispatch/kernels/eth_tunneler.cpp
k_id[6]: tt_metal/impl/dispatch/kernels/packet_demux.cpp
k_id[7]: tt_metal/impl/dispatch/kernels/cq_dispatch.cpp
k_id[13]: tests/tt_metal/tt_metal/test_kernels/dataflow/reader_matmul_tile_layout.cpp
k_id[14]: tests/tt_metal/tt_metal/test_kernels/dataflow/writer_matmul_tile_layout.cpp
k_id[15]: tests/tt_metal/tt_metal/test_kernels/compute/matmul_large_block_zm.cpp
- In the log above, relevant debug information is displayed for each code. Of particular note is the
k_idsfield, and the waypoint status.- The
k_idsfield reports the kernel currently running on the core, using the mapping at the end of the dump. Checking which kernels are running at the time of the hang (the latest dump in the log) shows which files to debug further, and should be included in any filed issues. - The waypoint field show the latest waypoint that each kernel has run past. The typical application of these is to put a waypoint before and after any kernel code that could hang, which can be used to pinpoint a hang from the log.
- Further debug features are available, such as a debug ring buffer on each core. For more information, see the Watcher documentation.
- The
- If you're able to deterministically reproduce the hang, the relevant kernel code can be instrumented with more debug features and iterated on to find the source of the hang.
- For multicast operations, you should check that the parameters are correct and you are calling the right variant of the method. Some examples of what to watch out for are the following:
- The number of destinations has to be non-zero.
- If the source node is in the destination set, you need to use the
loopback_srcvariant of the method. - The
loopback_srcvariant will not do anything if the set of destination nodes consists entirely of the source node.
- For multicast operations, you should check that the parameters are correct and you are calling the right variant of the method. Some examples of what to watch out for are the following:
- If a hang happens only when watcher is disabled, it is likely that the extra code added by watcher is affecting a timing-related issue. In this case you can try disabling certain watcher features to attempt to bring the timing closer.
- The most invasive watcher features is the NoC sanitization, try disabling it with:
TT_METAL_WATCHER=10 TT_METAL_WATCHER_DISABLE_NOC_SANITIZE=1 ./your_program
- If you still cannot reproduce the hang, try disabling the waypoint and assert features. This will reduce visibility into the hang, but is better than nothing:
TT_METAL_WATCHER=10 TT_METAL_WATCHER_DISABLE_NOC_SANITIZE=1 TT_METAL_WATCHER_DISABLE_WAYPOINT=1 ./your_program
TT_METAL_WATCHER=10 TT_METAL_WATCHER_DISABLE_NOC_SANITIZE=1 TT_METAL_WATCHER_DISABLE_WAYPOINT=1 TT_METAL_WATCHER_DISABLE_ASSERT=1 ./your_program
- If the hang is not reproducible with watcher enabled, or for whatever reason watcher cannot be enabled for the run that hangs, then you can use the
watcher_dumptool to poll watcher data after the fact. Even if the initial program is not run with watcher features, this can at least show the kernels that were running on each core at the time of the hang.
# Note that if the PCIe or ethernet connection to a chip goes down then this tool won't be able to access on-device data.
./build/tools/watcher_dump --devices=<ids of devices to dump>
cat generated/watcher/watcher.log # See k_ids field for each core in the last dump in the log
- In the future, this tool will be expanded to show more debug information available from the host side.
This project has adopted C++ formatting and style as defined in .clang-format.
There are additional requirements such as license headers.
As part of maintaining consistent code formatting across the project, we have integrated the pre-commit framework into our workflow. The pre-commit hooks will help automatically check and format code before commits are made, ensuring that we adhere to the project's coding standards.
Pre-commit is a framework for managing and maintaining multi-language pre-commit hooks. It helps catch common issues early by running a set of hooks before code is committed, automating tasks like:
- Formatting code (e.g., fixing trailing whitespace, enforcing end-of-file newlines)
- Running linters (e.g.,
clang-format,black,flake8) - Checking for merge conflicts or other common issues.
For more details on pre-commit, you can visit the official documentation.
To set up pre-commit on your local machine, follow these steps:
- Install Pre-commit:
Ensure you have Python installed, then run:
Note: pre-commit is already installed if you are using the python virtual environment.
pip install pre-commit
- Install the Git Hook Scripts:
In your local repository, run the following command to install the pre-commit hooks:
This command will configure your local Git to run the defined hooks automatically before each commit.
pre-commit install
- Run Pre-commit Hooks Manually:
You can also run the hooks manually against all files at any time with:
pre-commit run --all-files
-
Every source file must have the appropriate SPDX header at the top following the Linux conventions for C++ source files, RST files, ASM files, and scripts. For Python files, we are to use this convention:
# SPDX-FileCopyrightText: © 2023 Tenstorrent Inc. # SPDX-License-Identifier: Apache-2.0For C++ header files, we will treat them as C++ source files and use this convention:
// SPDX-FileCopyrightText: © 2023 Tenstorrent Inc. // // SPDX-License-Identifier: Apache-2.0
- Revert commits on main which fail post-commit tests immediately.
- There shall be a periodic discussion among the technical leads of this
project concerning:
- Certain codeowners and project-specific members review current tests in post-commit.
- Certain codeowners and project-specific members decide whether to remove/add any current tests in post-commit as project priorities change on an ongoing basis.
- Certain codeowners and project-specific members decide if we need to change owners or add more as project priorities change on an ongoing basis.
- Communication channels for these decisions and meetings shall be kept internal to Tenstorrent with the intent of having such discussions in the open later.
- Non-post-commit pipelines will not necessarily mean we have to revert the breaking commit, however any broken pipelines will be considered a priority bug fix.
- The responsibility of identifying, announcing status-tracking, and escalating
broken non-post-commit pipelines will be the responsibility of codeowners
whose tests are in the said non-post-commit pipeline.
- In the case of the model performance test pipeline, there are codeowners for such tests. However, it is the collective responsibility of all developers to ensure that we do not regress this pipeline.
-
There are some automated checks upon opening a PR. These checks are part, but not all, of the post-commit test suite. They must pass, but are not enough to ensure your PR will not be reverted.
-
To run any CI pipeline on GitHub Actions, please navigate to the actions page.
Next, you can navigate to any pipeline on the left side of the view. For example, you can run the entire post-commit CI suite by clicking on on the link to all post-commit workflows, clicking "Run workflow", selecting your branch, and pressing "Run workflow".
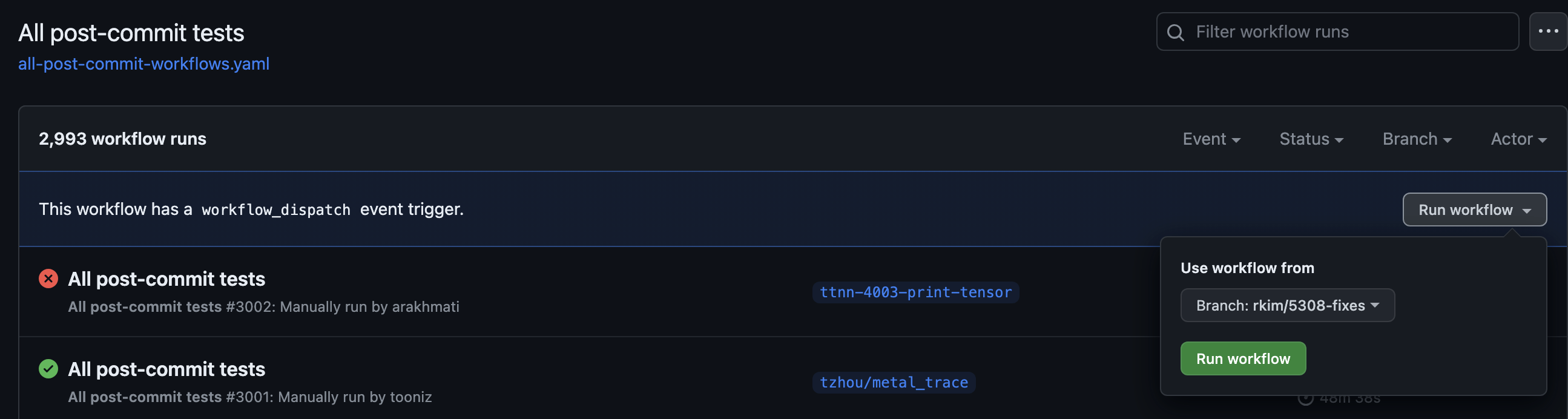
You can see the status of your CI run by clicking on the specific run you dispatched.
We have a sizeable number of workflows, so don't forget to press "Show more workflows...".
-
Unfortunately, we currently do not do automatic checks of all required workflows upon opening a PR. There are various reasons for this, such as limited machine resources. This means that developer and reviewer discretion is still the most important factor in ensuring PRs are merged successfully and without CI failure.

- CI/CD can be skipped for documentation only updates that incur no functional change.
- Upon submitting a PR and getting the necessary approvals:
- Click Squash and Merge
- Before confirming, edit the top level commit message by prepending the token
[skip ci]- Example:
[skip ci] #9999: Update CONTRIBUTING.md
- Example:
- Any API changes must be accompanied with appropriate documentation changes.
-
Filing an issue is encouraged for any item that needs alignment or long term tracking.
-
Link your issue under the
Ticketheadline in your PR description. -
Use descriptive commit messages
-
Merge commits are not allowed in our main branch. We enforce a linear history.
-
You can use either of the following methods to merge your branch on the GitHub UI:
- Squash and merge
- Rebase and merge
Include the user, the issue number, and optionally a description of the change. / and - are used as separators between user and issue number. And - and _ between issue number and description. E.g.
git checkout -b user-123
git checkout -b user/123
git checkout -b user-123_rename_method_x
git checkout -b user/123-add-x-unit-test
Edit the files that you want, making sure relevant unit tests pass. Then add them in. E.g.
git add abc.py
git add "*.py"
Please avoid using git add -A, which is fairly error prone.
You can restore files if you need to get the original. E.g.
git restore abc.py
git restore '*'
git restore --staged abc.py # if the file was already added
git commit -m "Rename method x"
Note: each commit on the main branch and any feature branch where multiple engineers collaborate should work. That is, everything compiles properly on the architecture used by your machine, you can run relevant code on the card, and relevant unit tests pass. Furthermore, for the main branch, you should run CI pipelines and make sure that the commit doesn't break anything important.
You can use git log to see the sequence of commits in the branch. That allows you to see where your branch is relative to main, and can help you figure out how the commits are structured, before and after commits and rebases.
You will need to push the change to origin. The command will provide a url that you should use to create pull request. This should be done the first time you push a change. After that you may need to set upstream to be able to push changes in the future. E.g.
git push origin user-123:user-123
git branch --set-upstream-to=origin/user-123 user-123
or
git push -u branch_name
Note: you may be able to push and set the upstream at the same time, but that assumes that you haven't rebased, which is probably not the case. The command would be something like
git push origin --set-upstream origin user-123
If that doesn't work, you should use branch --set-upstream-to.
Once you have a pull request, in the UI you can run actions against the branch. Go to Actions (https://github.com/tenstorrent/tt-metal/actions) and run the workflows that you want against your branch. At the very least, you should run All post-commit tests.
You can make more changes, commit them, and then if everything is set up and you don't need to rebase, then you can just do
git push
Occasionally, and for the final set of tests before the final commit, you should rebase your branch.
Your branch needs to be kept up to date with main via rebase. You should rebase your local branch, and then once everything looks good, push the change. You should not rebase your origin branch. That way, if anything goes wrong, you can use origin to restore your branch to a good state.
Note: Before rebasing, remember to change your default comment character, which is mentioned earlier in Setting up Git.
Note: for very small changes where you don't expect to create a second commit it might be okay to use the UI to rebase origin. However, in general, it's better to avoid that.
You should first make sure main is up to date:
git checkout main
git fetch origin
git pull --rebase --prune
Then you can
git checkout user-123
git rebase main
This will apply one commit at a time. Each commit is in order. If your branch has two commits, then the first one is applied, then the second one is applied.
If there are no conflicts, everything will complete successfully. Then you can push the changes to origin. This is done through a forced push to save the rebase information:
git push -f
If there is any conflict with the commits being processed, you will need to edit the files to fix the problem. Information should be printed about what to do. It's probably a good idea not to skip commits.
Don't be surprised if changes from a subsequent commit are not there in the first commit. For example, if you are editing the files to fix up the first of two commits, the files will not have the edits of the second commit. When editing files, only fix up the conflicts listed. Do not change anything else.
If you do change anything else, then git rebase --continue will complain and
you will probably have to restart.
Look for HEAD. The conflict will look something like:
<<<< HEAD
Some other edits
====
Your edits
>>>> Your branch
Update the file to have a single piece of working code and remove the commit info. Make sure everything compiles and all the tests pass. Then you can continue with the rebase.
git rebase --continue
If something is wrong enough that you want to abort the rebase and undo all the changes, then you can start over. Do
git rebase --abort # go to before the rebase
If your local is in a bad state, you may also want to start from scratch on your local by pulling from origin, reflogging, or checking out a specific commit via its hash:
git pull --rebase # will undo changes
git reflog
git checkout <hash>
If none of those work you can also try:
git reset --hard origin/<BRANCH>
Note: If you are getting errors you may need to update the origin info via
git branch --set-upstream-to.
If everything goes well with all the updates. Then you can update origin:
git push -f
Note: It's okay to have a few commits, as long as each one works on its own. If you do want to combine commits you would want to run something like:
git rebase -i HEAD~10 # the number indicates how many commits you want to look at - here 10 commits
The latest one is at the bottom. You can use fixup or squash. Usually you want to use fixup (indicated by f) since that discards the message. Then edit the messages appropriately.
However, new squash and merge functionality in the UI is much easier than doing this process manually. Therefore you should use the UI whenever possible.
You will probably need to iterate several times in terms of pushing changes and rebasing your branch.
Once you have all of your changes working locally, your pull request (PR) approved, and all the workflows that you want passing after a final rebase, It is time to merge in your branch into main. This should be done in the Github UI.
Go to your PR and press the Squash and merge button. That will automatically
squash all of your commits, which is very useful. The button has an alternate
option to merge without squashing. You should use Squash and merge unless you
have a good reason not to.
After that, the UI will usually delete your branch.
- A PR must be opened for any code change with the following criteria:
- Be approved, by a maintaining team member and any codeowners whose modules are relevant for the PR.
- Pass any required post-commit pipelines, updated to the latest main. These
pipelines will generally, but not always, be defined in
.github/workflows/all-post-commit-workflows.yaml. - Pass any acceptance criteria mandated in the original issue.
- Pass any testing criteria mandated by codeowners whose modules are relevant for the PR.
- Avoid opening/re-opening/push new commits to PRs before you're ready for review and start running pipelines. This is because we don't want to clog our pipelines with unnecessary runs that developers may know will fail anyways.
- New or changing features require the following accompanying documentation:
- An architectural change plan approved by maintaining team members.
- A design plan with associated GitHub project/large containing issue. with sub-issues for proper documentation of project slices.
- An appropriate test plan with issues.
- Any release must be externally-available artifacts generated by a workflow on a protected branch.
- Demo models and tags conform to the rules set forth in the models README.
- Use Loguru for Python logging.
- Use Tenstorrent logger for C++ logging.
If a Tenstorrent chip seems to hang and/or is producing unexpected behaviour, you may try a software reset of the board.
For single-card: tt-smi -r 0
For T3000 (QuietBox, LoudBox etc.): tt-smi -r 0,1,2,3
If the software reset does not work, unfortunately you will have to power cycle the board. This usually means rebooting the host of a board.