This project providers users the ability to generate paraphrases for sentences through a clean and simple API. A demo can be seen here: pair-a-phrase
The paraphraser was developed for Praxis SW under the Insight Data Science Artificial Intelligence program. Praxis SW goals are to generate paraphrases for applications. Their immediate goal is to generate data to improve interaction between consumers and their voice activated devices. Assume a user issued a command to their user by saying "Book me a flight to Hawaii.", it should be able to understand all the myriad number of ways that you could convey the same meaning using different words. For example, "Schedule a flight to Hawaii" or "Purchase a planet ticket to Hawaii". Alexa needs to be able to recognize these different paraphrases in order to recognize your task.
- Python 3.5
- Tensorflow
Run the following command from within your virtual environment:
pip install git+git://github.com/vsuthichai/paraphraser.git
from paraphraser import paraphrase
print(paraphrase("hello world"))The underlying model is a bidirectional LSTM encoder and LSTM decoder with attention trained using Tensorflow.
The dataset used to train this model is an aggregation of many different public datasets. To name a few:
- para-nmt-5m
- Quora question pair
- SNLI
- Semeval
- And more!
I have not included the aggregated dataset as part of this repo. If you're curious and would like to know more, contact me. Pretrained embeddings come from John Wieting's para-nmt-50m project.
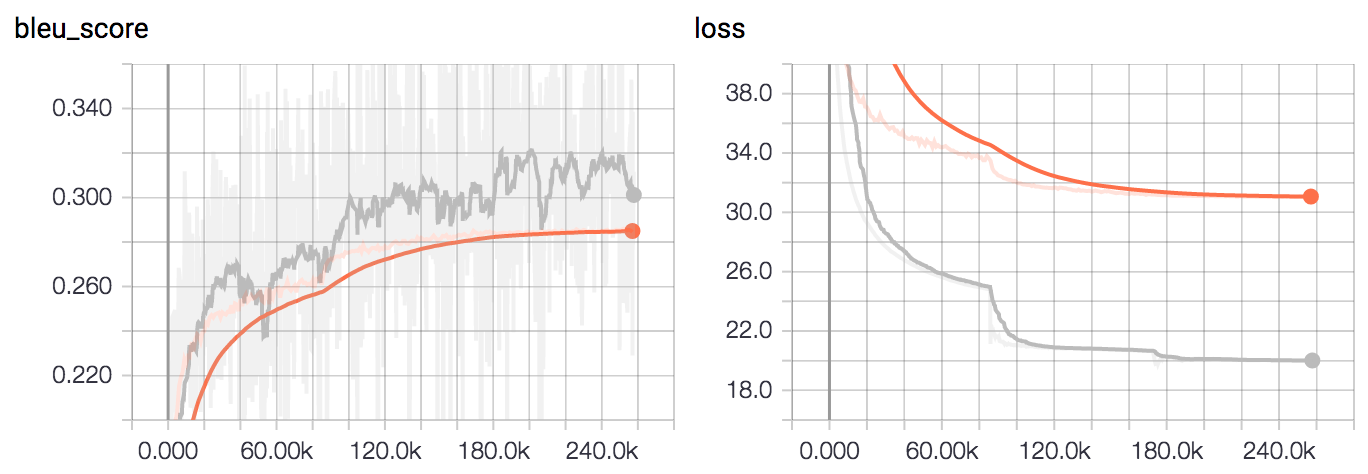
Training was done for 2 epochs on a Nvidia GTX 1080 and evaluted on the BLEU score. The Tensorboard training curves can be seen below. The grey curve is train and the orange curve is dev.
- Explore deeper number of layers
- Recurrent layer dropout
- Greater dataset augmentation
@inproceedings { wieting-17-millions,
author = {John Wieting and Kevin Gimpel},
title = {Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations},
booktitle = {arXiv preprint arXiv:1711.05732}, year = {2017}
}
@inproceedings { wieting-17-backtrans,
author = {John Wieting, Jonathan Mallinson, and Kevin Gimpel},
title = {Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext},
booktitle = {Proceedings of Empirical Methods in Natural Language Processing},
year = {2017}
}