| layout | title |
|---|---|
post |
第30期 |
从reddit/hackernews/lobsters/meetingcpp摘抄一些c++动态。
每周更新
周刊项目地址 github,在线地址 |知乎专栏 |腾讯云+社区
欢迎投稿,推荐或自荐文章/软件/资源等,请提交 issue
这篇文章还是很精彩的,抓内存,从陌生的代码上找问题。值得一读
之前介绍过英文原文,这个作者简单翻译整理了一下,对于异常实现有兴趣的可以点开看看
简单了介绍了malloc的原理,值得一看
一个llvm教程
这里总结了llvm2021大会上的一些演讲,值得一看
整理了一些google miracleptr的一些文档。不过大部分都是google内部可见的
介绍一个c++match方案
void f(auto const& x) {
inspect (x) {
i as int => std::cout << "int " << i;
[_,y] is [0,even] => std::cout << "point on y-axis and even y " << y;
[a,b] is [int,int] => std::cout << "2-int tuple " << a << " " << b;
s as std::string => std::cout << "string \"" + s + "\"";
is _ => std::cout << "((no matching value))";
}
}
int main() {
f(42);
f(std::pair{0, 2});
f(std::tuple{1, 2});
f("str");
struct {} foo;
f(foo);
}这里用is来表达不同类型的match
提案中。看个乐
之前也讨论过哈,就是enum封装
using BucketIndex_t = int;
enum class BucketIndex : int { None = -1, First = 0 };
static constexpr inline BucketIndex operator+ (BucketIndex b, int i) {return BucketIndex(BucketIndex_t(b) + i);}
static constexpr inline BucketIndex operator- (BucketIndex b, int i) {return BucketIndex(BucketIndex_t(b) - i);}
static constexpr inline BucketIndex& operator++ (BucketIndex &b) {b = b + 1; return b;}
static constexpr inline BucketIndex& operator-- (BucketIndex &b) {b = b - 1; return b;}
还是介绍LLVM的。这个我不懂就不多说了
其实就是介绍p1064这个提案
#include <iostream>
#include <map>
#include <memory>
#include <vector>
#include <ranges>
struct SectionHandler {
virtual ~SectionHandler() = default;
constexpr virtual std::vector<int> getSupportedTags() const = 0;
};
struct GeneralHandler : public SectionHandler {
constexpr virtual std::vector<int> getSupportedTags() const override {
return { 1, 2, 3, 4, 5, 6 };
}
};
struct ShapesHandler : public SectionHandler {
constexpr virtual std::vector<int> getSupportedTags() const override {
return { 7, 10 };
}
};
constexpr size_t calcMemoryToAllocate() {
std::vector<SectionHandler*> handlers;
handlers.push_back(new GeneralHandler());
handlers.push_back(new ShapesHandler());
size_t maxTag = 0;
for (const auto& h : handlers) {
for (const auto& t : h->getSupportedTags())
if (t > maxTag)
maxTag = t;
}
std::vector<int> uniqueTags;
uniqueTags.resize(maxTag+1);
for (const auto& h : handlers) {
for (const auto& t : h->getSupportedTags())
uniqueTags[t]++;
}
for (auto& h : handlers)
delete h;
auto ret = std::ranges::find_if(uniqueTags, [](int i) { return i >= 2;});
return ret == uniqueTags.end();
}
int main() {
static_assert(calcMemoryToAllocate());
}可以在这里@Compiler Explorer试验一下
只有msvc支持,gcc clang我试了都不行
其实是让virtual的动态在编译期固定住的技巧
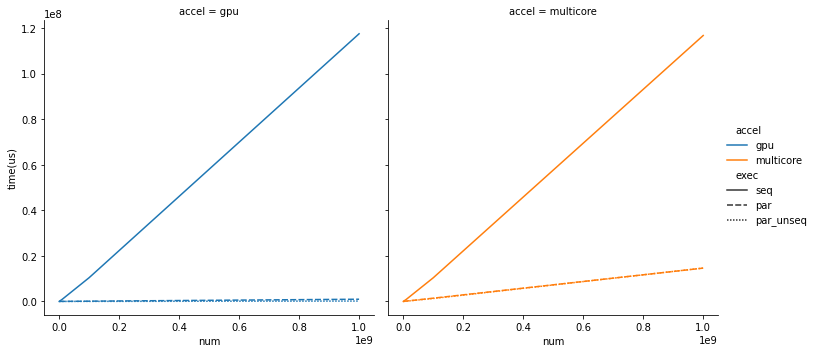
测试了一波nvc++ 在stl算法上的并发效果 (有GPU和多核加速两种对比)
代码
auto time_diff = [](auto& s, auto& e, auto conf, int n) {
float duration = std::chrono::duration_cast<std::chrono::microseconds>
(e - s).count();
std::cout << n << "," << duration << "," << conf << "," << "multicore/gpu??" << std::endl;
};
auto tic = std::chrono::steady_clock::now();
std::sort(std::execution::seq, vals.begin(), vals.end());
auto toc = std::chrono::steady_clock::now();
time_diff(tic, toc, "seq", n_);
auto tic = std::chrono::steady_clock::now();
std::sort(std::execution::par, vals.begin(), vals.end());
auto toc = std::chrono::steady_clock::now();
time_diff(tic, toc, "par", n_);
auto tic = std::chrono::steady_clock::now();
std::sort(std::execution::par_unseq, vals.begin(), vals.end());
auto toc = std::chrono::steady_clock::now();
time_diff(tic, toc, "par_unseq", n_);能看出使用 针对nvc++,par的加速效果还是很显著的
我跑了gcc版本,基本没有提升
还是concepts教程。上代码吧
template <typename T>
concept has_x = requires (T v) {
v.x;
};
template <typename T>
concept coord = has_x<T> && requires (T v) {
v.y;
};
void function(has_x auto x) {}
void function(coord auto x) {}struct X {
int x;
};
struct Y {
int x;
int y;
};
int main() {
function(X{}); // OK, only one viable candidate
function(Y{}); // OK, coord is more specific
}这两种require还是很有意思的
对coroutine执行结构不了解的,可以看这篇博客写的不错,这里就不直接引用了
对于原文中的代码
#include <coroutine>
#include <optional>
#include <iostream>
#include <cassert>
#include <exception>
class Future;
struct Promise
{
using value_type = const char*;
const char* value{};
Promise() = default;
std::suspend_always initial_suspend() { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void unhandled_exception() { std::rethrow_exception(std::current_exception()); }
std::suspend_always yield_value(const char* value) {
this->value = std::move(value);
return {};
}
void return_void() {
this->value = nullptr;
}
Future get_return_object();
};
class Future
{
public:
using promise_type = Promise;
explicit Future(std::coroutine_handle<Promise> handle)
: handle (handle)
{}
~Future() {
if (handle) { handle.destroy(); }
}
Promise::value_type next() {
if (handle) {
handle.resume();
return handle.promise().value;
}
else {
return {};
}
}
private:
std::coroutine_handle<Promise> handle{};
};
Future Promise::get_return_object()
{
return Future{ std::coroutine_handle<Promise>::from_promise(*this) };
}
// co-routine
Future Generator()
{
co_yield "Hello ";
co_yield "world";
co_yield "!";
}
int main()
{
auto generator = Generator();
while (const char* item = generator.next()) {
std::cout << item;
}
std::cout << std::endl;
return 0;
}co_yield expr转换成co_await promise.yield_value(expr), 直接执行yield_value,然后value就有值了,执行的是简单的move赋值,由于返回suspend_always,这里直接挂起等待resume,next中会手动执行resume,resume执行完协程才会继续,然后next就拿到的co_yield的值
整体来说这个协程的组件太精细。精准控制。对于实际使用来说不是那么方便。主要是得定制自己的 future promise awaitable,以前也说过,还是用现成的比较方便,比如cppcoro
delete也可以用在一般函数上。看代码
#include <iostream>
#include <ios>
using namespace std;
void any_type(void* p) { cout << "any_type(void* p = " << hex << p << ")\n"; }
void void_only(std::nullptr_t) { cout << "void_only(std::nullptr_t)\n"; }
void void_only(void* p) { cout << "void_only(void* p = "<< hex << p << ")\n"; }
#if __cplusplus >= 202002L
void void_only(auto*) = delete; // C++20 and newer...
#else
template<typename T> void void_only(T*) = delete; // prior to C++20...
#endif
// ALL other overloads, not just 1 pointer parameter signatures...
template<typename ...Ts> void void_only(Ts&&...) = delete;
int main()
{
any_type(new char);
any_type(new short);
any_type(new int);
void_only(nullptr); // 1st overload
void_only((void*)0xABC); // 2nd overload, type must be void*
// void_only(0); // ERROR, ambiguous
// void_only(NULL); // ERROR, ambiguous
// void_only((long*)0); // ERROR, explicitly deleted
// void_only((int*)1, (int*)2); // ERROR, also explicitly deleted
}- pre-commit-hooks 一个git commit hook库,给c++项目用的,内置clang-format之类的lint插件
- DataFrame 正在找人帮忙维护项目,这个库有点类似arrow
- efsw 一个file watcher库,全平台支持
- idle 一个服务框架,支持插件化 hot-reload