< Previous Module - Home - Next Module >
One of the features of Microsoft Purview is the ability to show the lineage between datasets created by data processes. Data lineage shows how data moves over time and enables you to see how data is used and what changes to data have been made. This visibility helps you to understand, trace back and correct data at the source of origin. Lineage, thus also results into better data quality.
Lineage is typically captured from tools that extract, transform and load data. These ETL tools are, for example, Data Factory, Data Share, and Power BI. They capture the lineage of data as it moves. By scanning these ETL tools you can capture and visualize the lineage in Microsoft Purview.
Microsoft Purview also supports the ability to upload custom lineage. Custom lineage is lineage that you created yourself, for example by uploading metadata using the Microsoft Purview's Atlas REST APIs. Lineage in Purview includes relationships between datasets and processes.
💡 Did you know?
Dataset: A dataset (structured or unstructured) provided as an input to a process. For example, a SQL Table, Azure blob, and files (such as .csv and .xml), are all considered datasets. In the lineage section of Purview, datasets are represented by rectangular boxes.
Process: An activity or transformation performed on a dataset is called a process. For example, ADF Copy activity, Data Share snapshot and so on. In the lineage section of Purview, processes are represented by round-edged boxes.
- An Azure account with an active subscription.
- An Azure Data Lake Storage Gen2 Account (see module 00).
- An Azure Data Factory Account (see module 00).
- A Microsoft Purview account (see module 01).
This module steps through what is required for connecting an Azure Data Factory account with a Microsoft Purview account to track data lineage.
- Connect an Azure Data Factory account with a Microsoft Purview account.
- Trigger a Data Factory pipeline to run so that the lineage metadata can be pushed into Purview.
- Create an Azure Data Factory Connection in Microsoft Purview
- Copy Data using Azure Data Factory
- View Lineage in Microsoft Purview
-
Open the Microsoft Purview Governance Portal, navigate to Management > Data Factory (under Lineage connections) and click New.
⚠️ To view/add/remove Data Factory connections, you need to be assigned the Collection admin role on the root collection.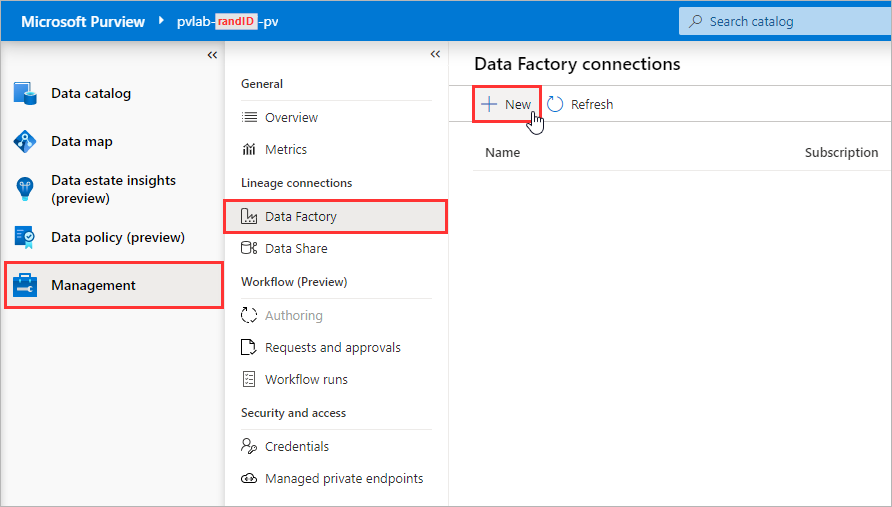
-
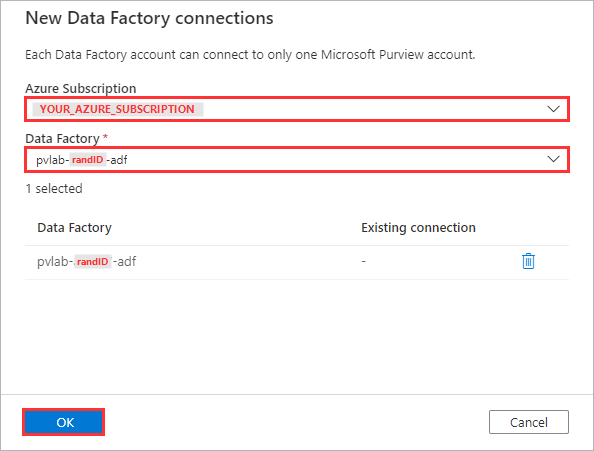
Select your Azure Data Factory account instance from the drop-down menu (e.g.
pvlab-{randomId}-adf) and click OK.💡 Did you know?
Microsoft Purview can connect to multiple Azure Data Factories but each Azure Data Factory account can only connect to one Microsoft Purview account.
-
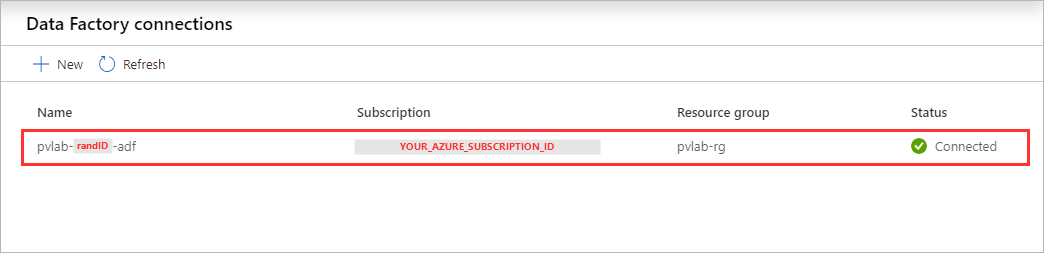
Once finished, you should see the Data Factory in a connected state.
-
To confirm that Azure Data Factory has been provided the necessary access, navigate to Data map > Collections >
YOUR_ROOT_COLLECTION> Role assignments, within Data curators you should be able to see the Azure Data Factory managed identity.💡 Did you know?
When a user creates an Azure Data Factory connection, behind the scenes the Data Factory managed identity is added to the
Data Curatorrole. This provides Azure Data Factory the necessary access to push lineage to Microsoft Purview during a pipeline execution. See supported Azure Data Factory activities for more information.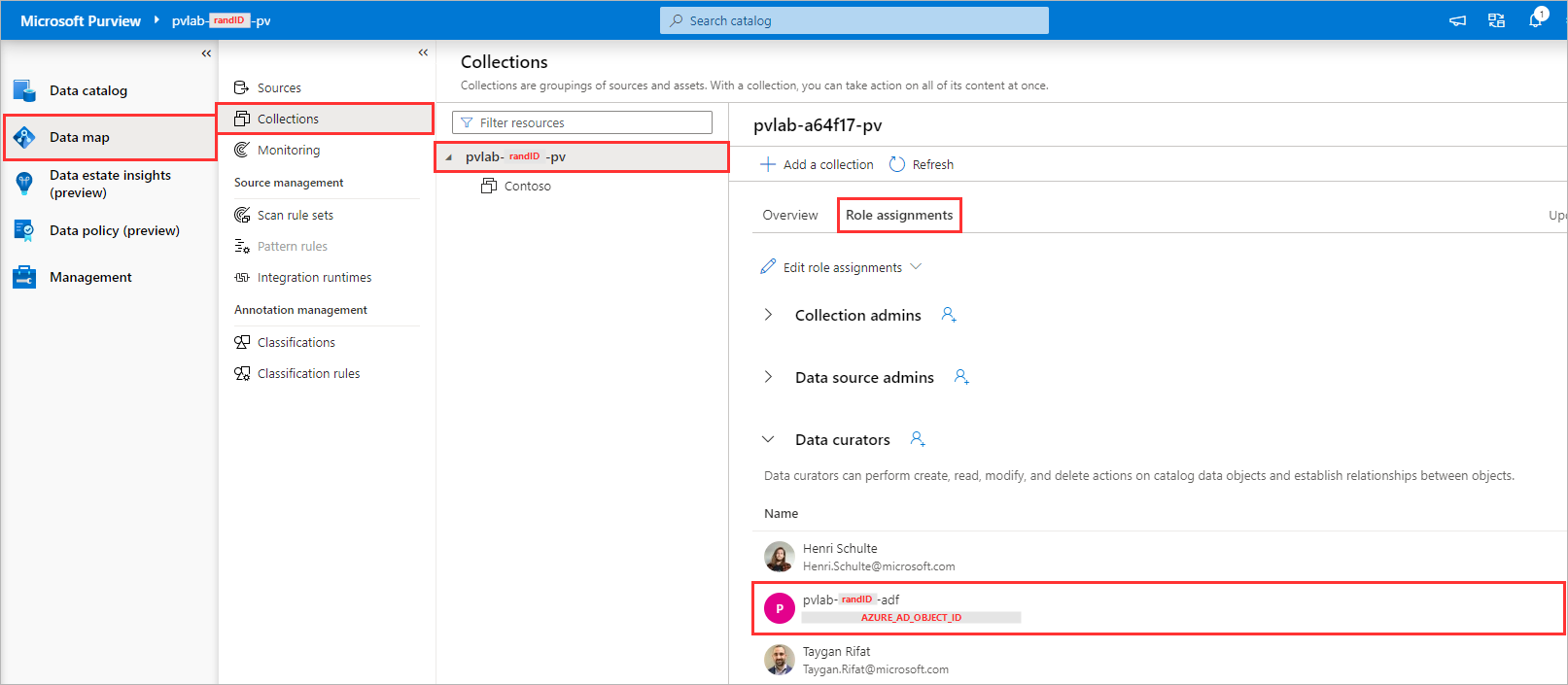




-
Within the Azure Portal, navigate to your Azure Data Factory resource and click Open Azure Data Factory Studio.
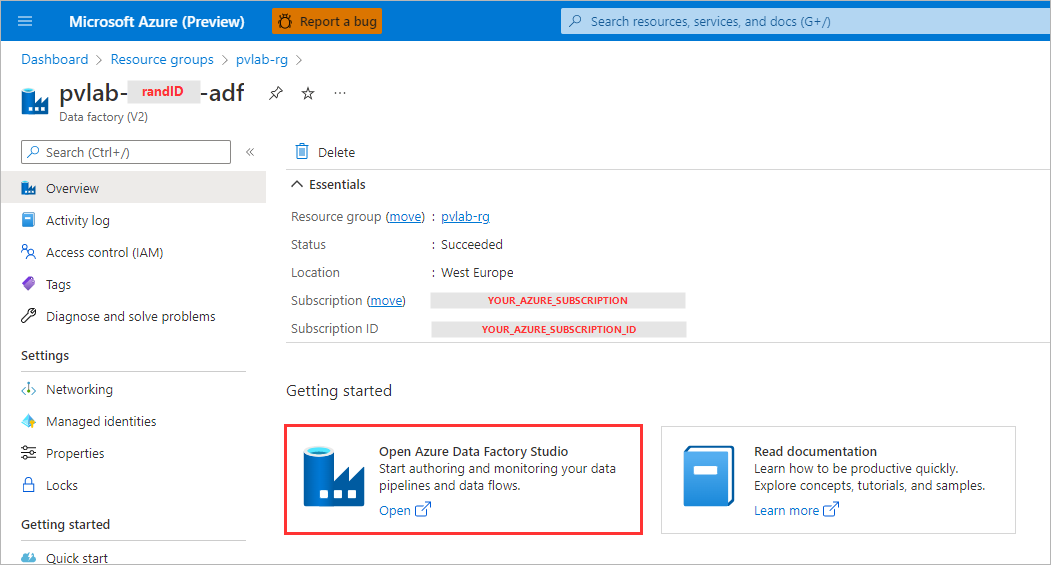
-
Click Ingest.
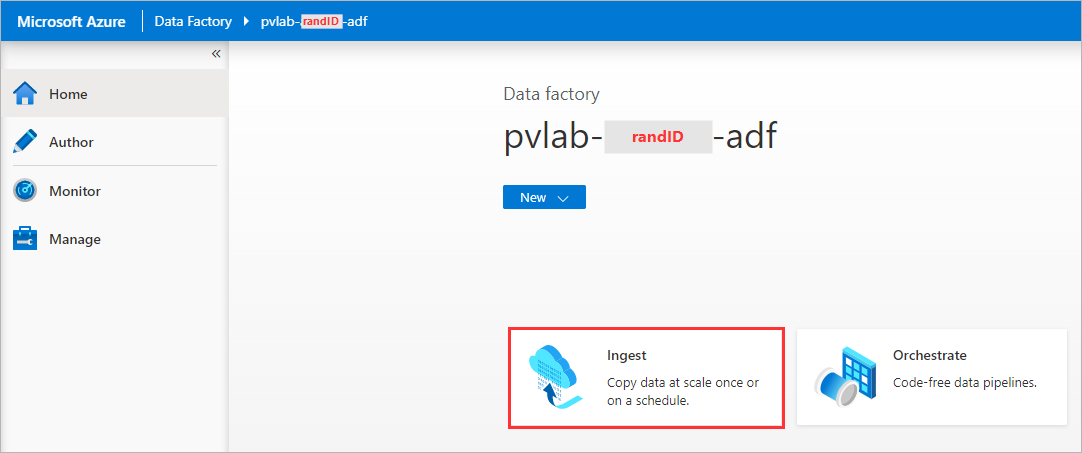
-
Select Built-in copy task and then click Next.
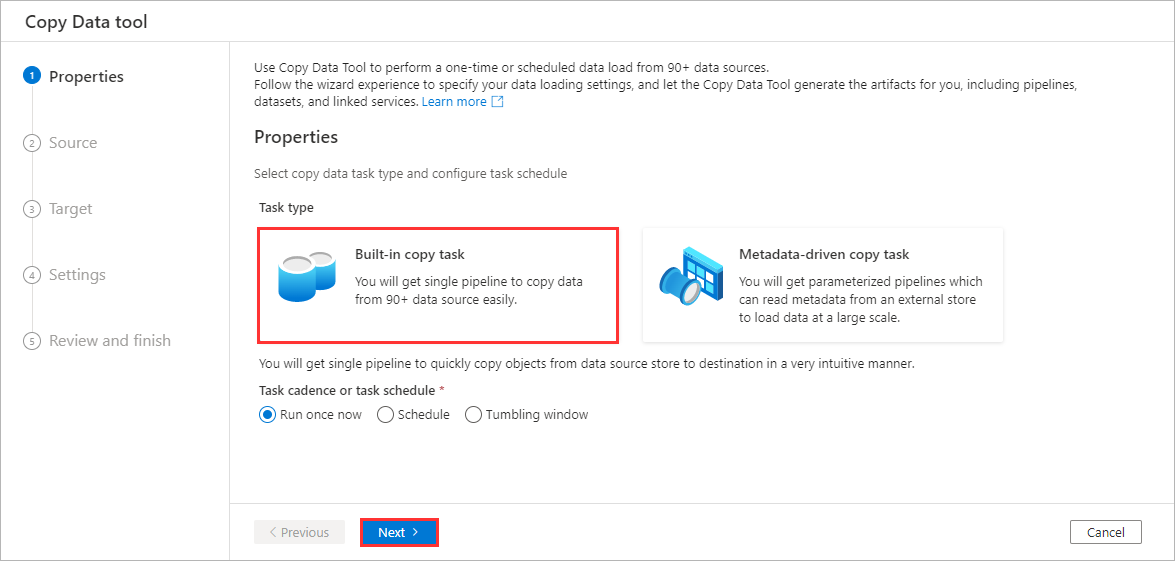
-
Change the Source type to
Azure Data Lake Storage Gen2and then click New connection.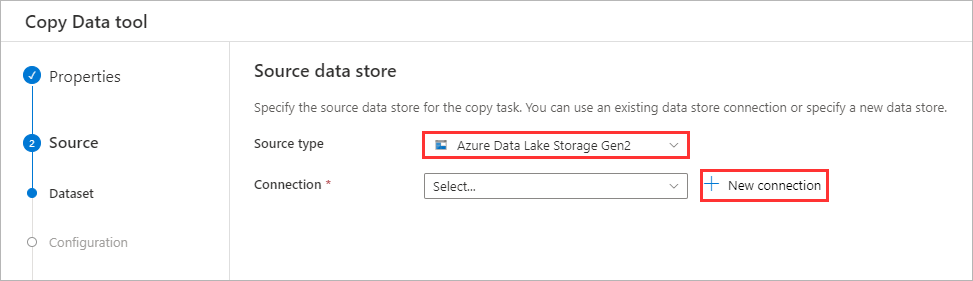
-
Select your Azure subscription and Storage account (e.g.
pvlab{randomId}adls), click Test connection and then click Create.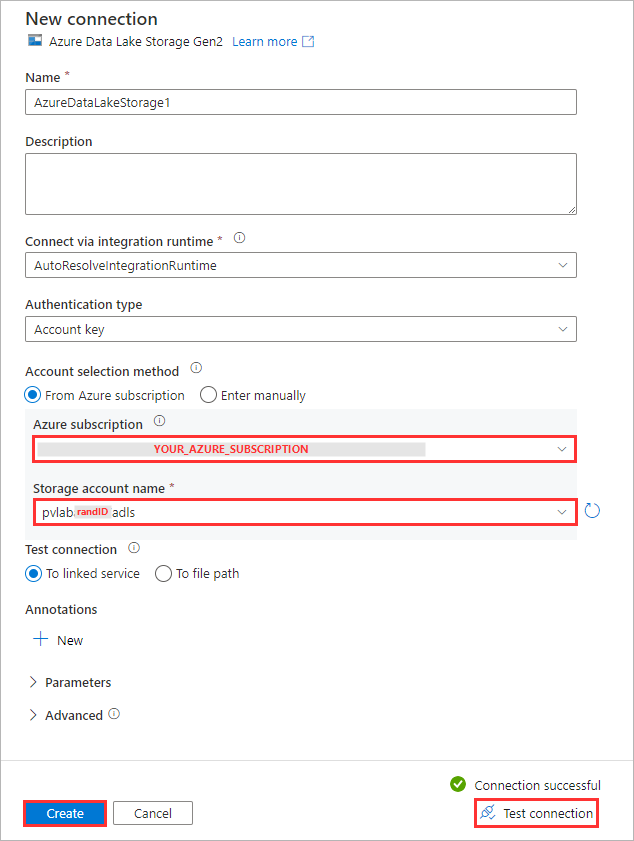
-
Click Browse.
-
Navigate to
raw/BingCoronavirusQuerySet/2020/and click OK.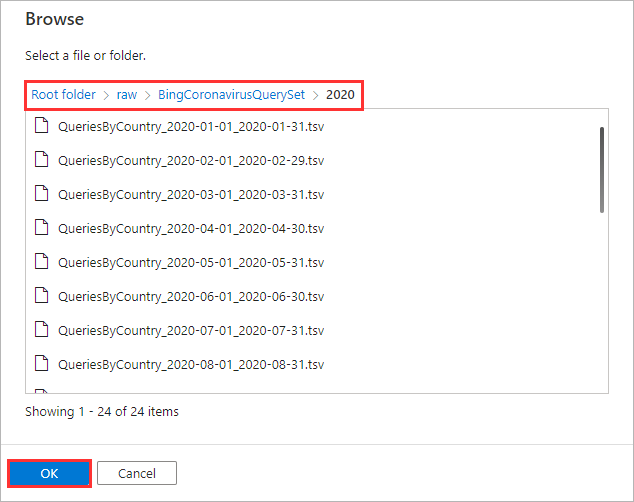
-
Confirm your folder path selection and click Next.
-
Preview the sample data by clicking Preview data, and then click Next.
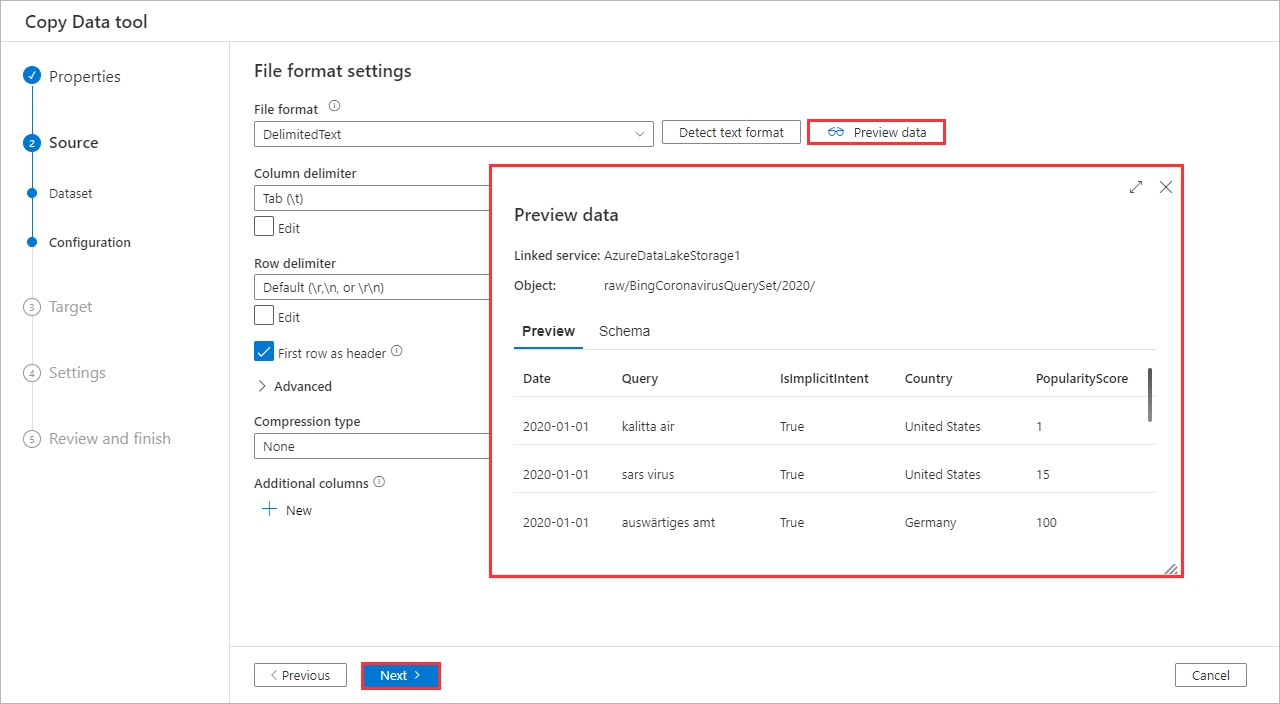
-
Change the Target type to
Azure Data Lake Storage Gen2, set the Connection to the existing connection (e.g.AzureDataLakeStorage1), and then click Browse.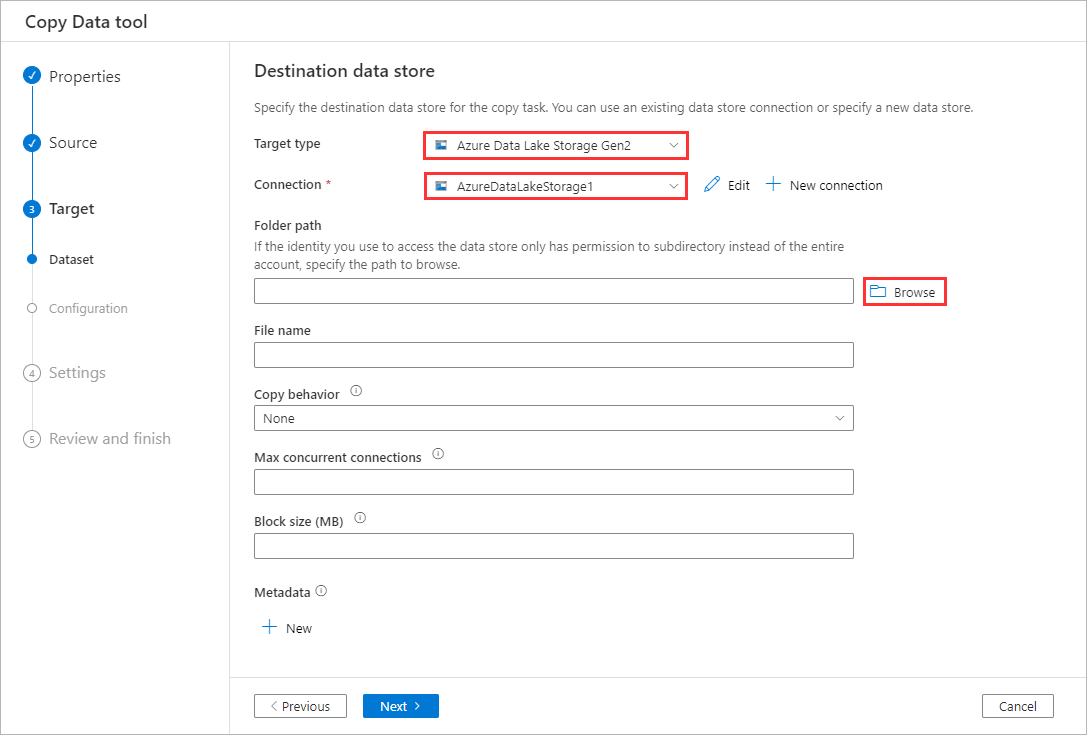
-
Navigate to
raw/and click OK.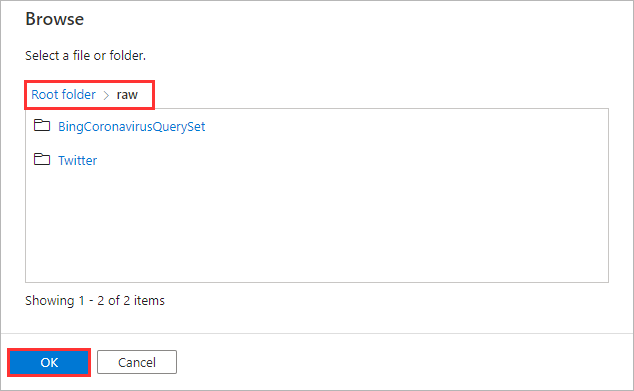
-
Confirm your folder path selection, set the file name to
2020_merged.parquet, set the copy behavior to Merge files, and click Next.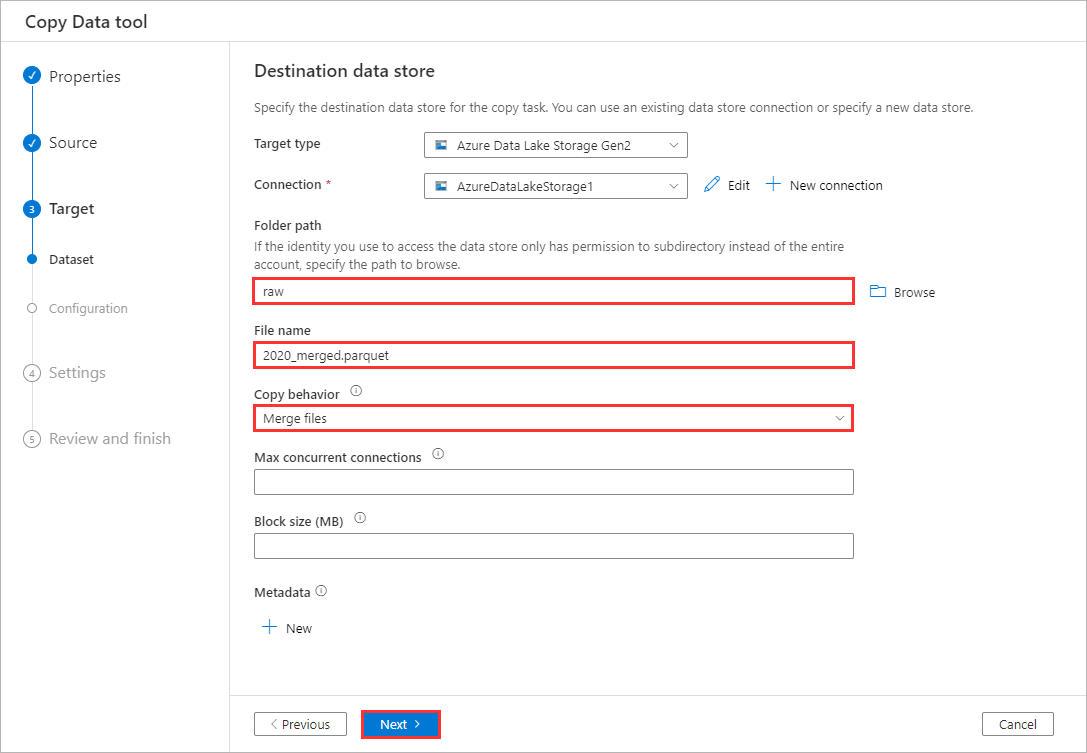
-
Set the file format to Parquet format and click Next.
-
Leave the default settings and click Next.
-
Review the summary and proceed by clicking Next.
-
Once the deployment is complete, click Finish.
-
Navigate to the Monitoring screen to confirm the pipeline has run successfully.
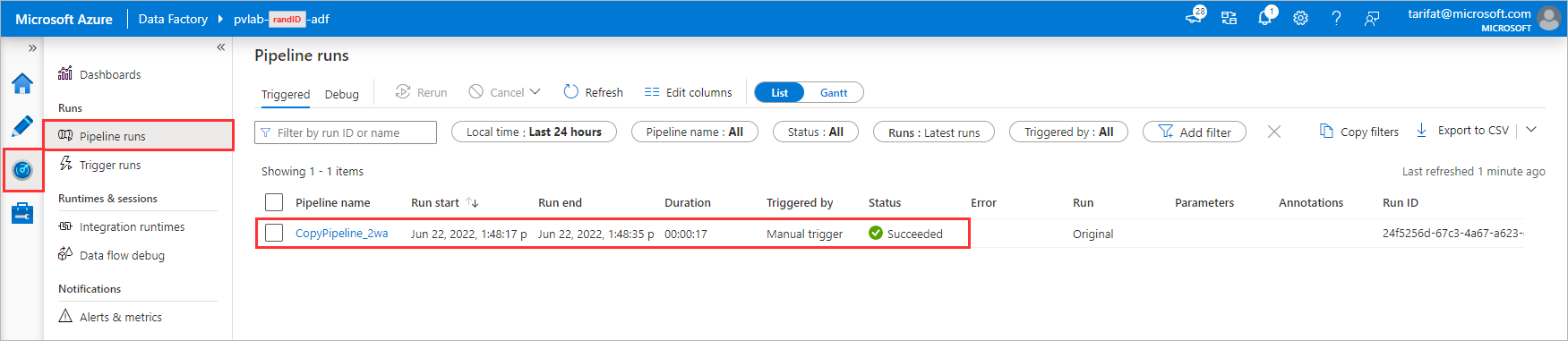

















-
Open the Microsoft Purview Governance Portal, from the Data catalog screen click Browse.
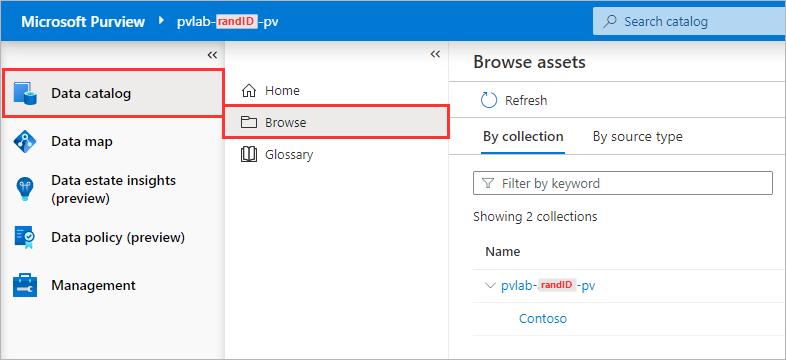
-
Switch to the By source type tab and then select Azure Data Factory.
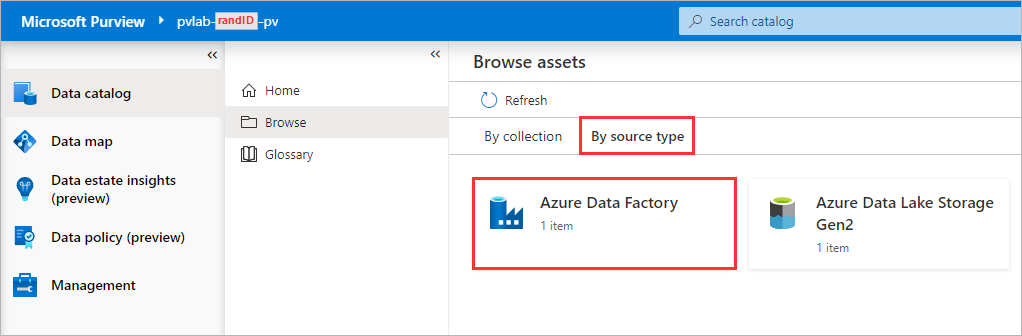
-
Select the Azure Data Factory account instance (e.g.
pvlab-{randomId}-adf).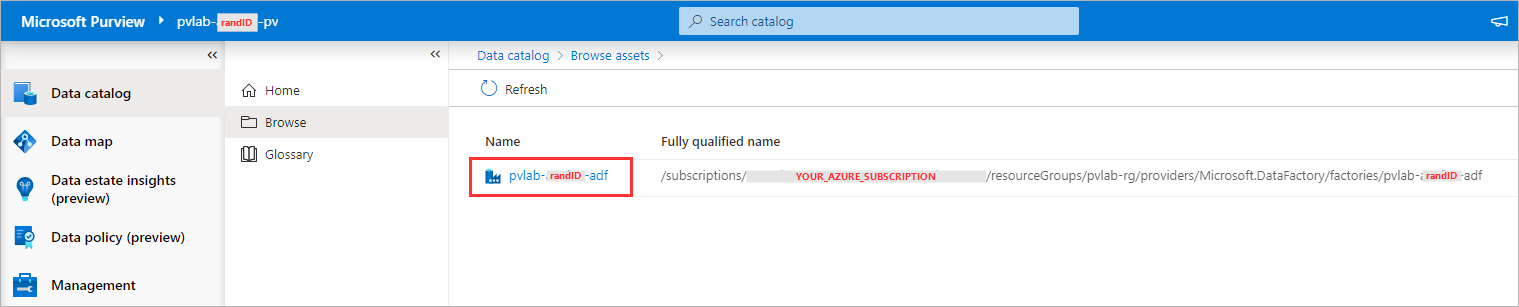
-
Select the Copy Pipeline and click to open the Copy Activity.
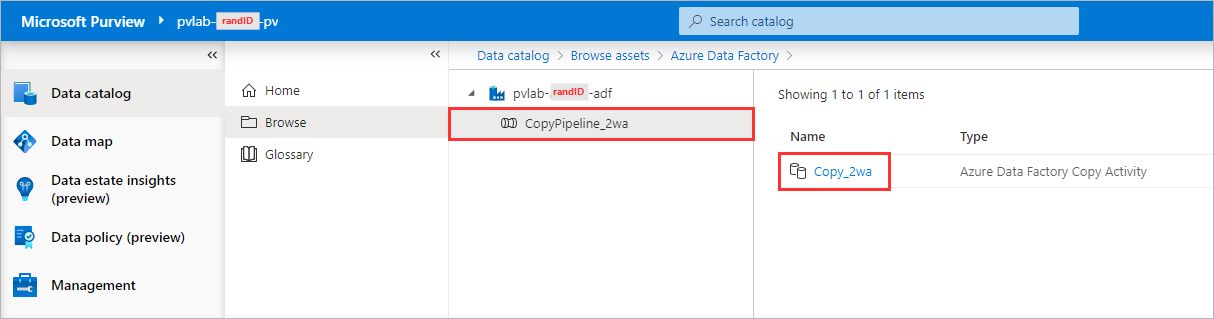
-
Navigate to the Lineage tab.
-
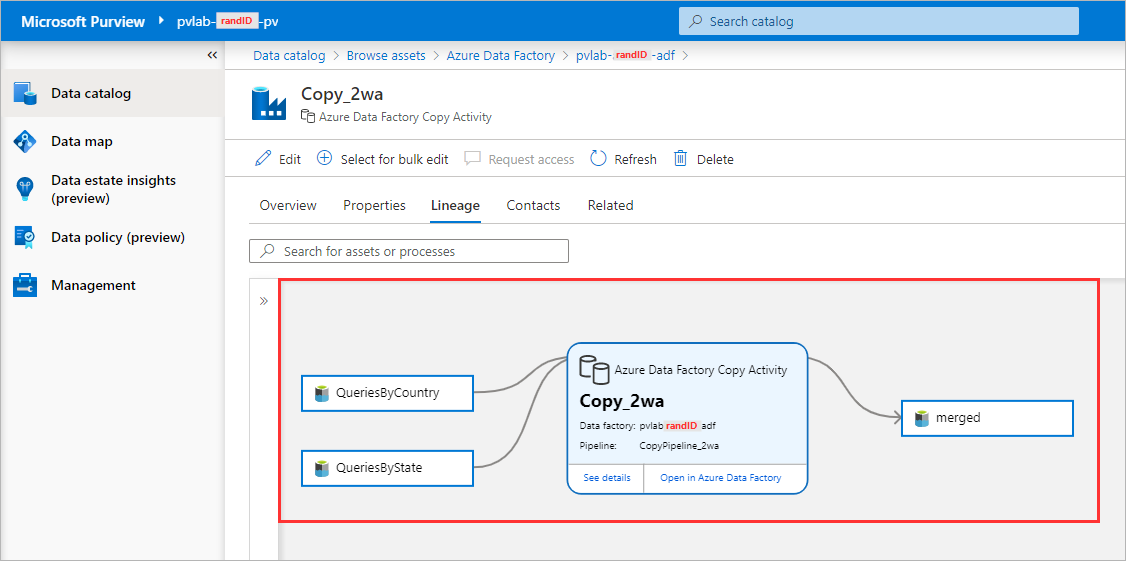
You can see the lineage information has been automatically pushed from Azure Data Factory to Purview. On the left are the two sets of files that share a common schema in the source folder, the copy activity sits in the center, and the output file sits on the right.






-
A Microsoft Purview account can connect to multiple Azure Data Factories?
A ) True
B ) False -
An Azure Data Factory can connect to multiple Microsoft Purview accounts?
A ) True
B ) False -
ETL processes are rendered on the lineage graph with what type of edges?
A ) Squared edges
B ) Rounded edges
This module provided an overview of how to integrate Microsoft Purview with Azure Data Factory and how relationships between assets and ETL activities can be automatically created at run time, allowing us to visually represent data lineage and trace upstream and downstream dependencies.