{kind=link}
{kind=link}
{kind=link}
{kind=link}
Procyon is the brightest star in the constellation of Canis Minor
Procyon is a dynamically scheduling, scalar, speculative RISCV processor supporting the RV32I ISA. here are some of the key features for this processor:
- Highly parameterizable
- Synthesizes for FPGAs
- Out-of-order execution
- L1 instruction cache
- Non-blocking L1 data cache with configurable number of outstanding misses
- Speculative execution across branches and speculative load execution with memory disambiguation
- Configurable number of integer issue pipelines
- Wishbone bus interface
The hardware is implemented in SystemVerilog and simulated in SystemC using Verilator. There is also a bitstream target for the CycloneIVe FPGA on the Terasic DE2-115 board.
In the tb directory there are some tests:
arch: RISCV CPU architectural testslsu: Tests that stress the LSU in various ways
Running make in each directory will build and run the simulation. Verilator is used to convert the SystemVerilog code to SystemC code and SystemC is used to run the simulation. For arch this will run a suite of rv32ui architectural tests across multiple models of the Procyon core. Each model will have it's top level parameters randomized. The architectural tests' source code can be found at riscv-tests which is a submodule in this repo. The riscv-tests repo is a fork of the official riscv-tests repo with some special tweaks to get the tests running on procyon. It's also possible to run an arbitrary free-standing bare-metal binary. From the arch directory:
make build-only
obj_dir/Vdut <binary>
The above will also work from any of the other directories in the tb directory.
The number of models with randomized parameters to simulate can be specified with a make variable, like so: make NUM_MODELS=50. The simulations will produce a VCD file which can be viewed by any waveform viewer. One such open source waveform viewer is gtkwave.
Currently, only the CycloneIVe FPGA on the Terasic DE2-115 board is supported. To build run make. To program the FPGA run make program. SW[17] (Switch 17) on the DE2-115 board is flipped to the up position to bring the design out of reset. The core is automatically halted after the first instruction of the loaded program has retired. KEY0 on the DE2-115 board is used to step through the code one instruction at a time. KEY1 is used to un-halt the core and let it run full-speed. If the program is one of the architectural or LSU tests the core will automatically halt once the test has completed. The hex displays on the board will show the retired data written into the register file; in the case the test passes, it will show 4A33 otherwise it will show FAE1. The red LEDs show the retiring PC or branch address and the green LEDs show the register number the retiring instruction is writing too.
The Procyon core and system is functional on the FPGA with the following blocks:
procyon: The actual RISCV coreprocyon_rom: Thebootrom. It will hold the bare-metal program instructions that the core will execute.boot_ctrl: Copies the binary loaded into thebootromto the SRAM before de-asserting reset to the Procyon core and switching the Wishbone bus mux to pass through the signals from the Procyon core.sram_top: SRAM controller module used to interface with the IS61WV102416BLL SRAM chip on the DE2-115 board. It includes a Wishbone responder interface to the Wishbone bus.
A python script, hexify-bin.py, is provided to convert an elf or binary file to hex format: hexify-bin.py <binary/ELF> <out_dir>. This is done by the Makefile automatically.
To build the FPGA bitstream with a custom binary loaded into the bootrom: make PROGRAM=<riscv program ELF/binary>.
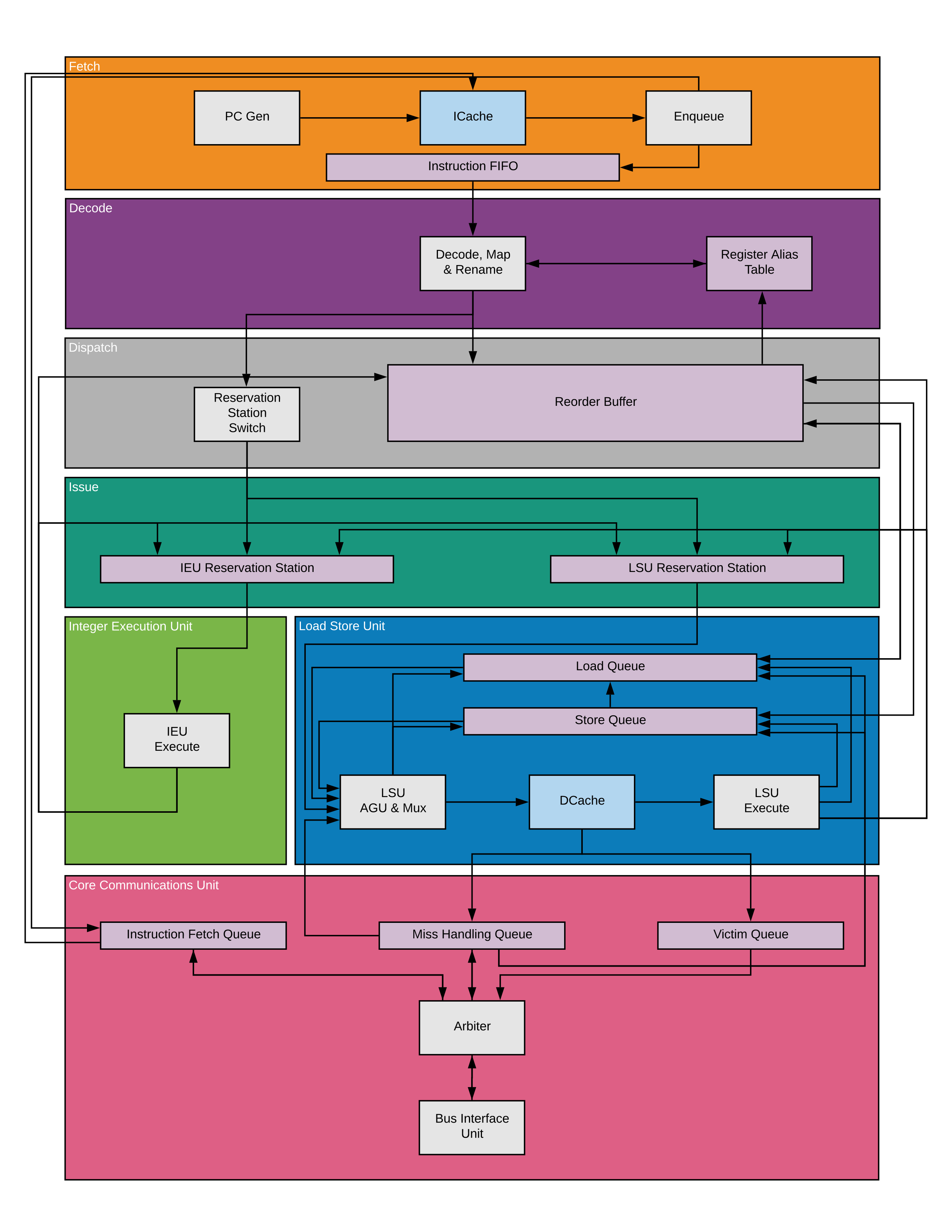
The Procyon core is an out-of-order, speculative processor. At a high-level an instruction goes through the following stages in the processor:
| Stage | Description |
|---|---|
| Fetch | Retrieve an instruction from the instruction cache and place it into the Instruction FIFO. If there was a cache miss, it will allocate an entry in the Instruction Fetch Queue and stall until the cache fill arrives. It will stall if the Instruction FIFO or Instruction Fetch Queue is full. |
| Decode | Decodes an instruction from the Instruction FIFO every cycle and reserve entries in the Reorder Buffer and the appropriate Reservation Station depending on the instruction type. Gets values or producer of source registers and renames destination registers in the Register Alias Table. |
| Dispatch | Updates entries in the Reorder Buffer and Reservation Station for the new instruction and allows it to be scheduled when it's ready. |
| Issue | When all operands are available an instruction can be issued into the appropriate functional unit every cycle. The reservation station will capture register values from producer ops and schedule ready instructions to it's functional unit when available. |
| Execute | Execute the instruction, this may take one or more cycles. The functional units are pipelined so they can be executing multiple instructions in different pipeline cycles simultaneously. Loads will speculatively load from the data cache regardless of outstanding stores. Stores will just generate the effective address and wait in the store queue until it can be retired. |
| Complete | Broadcast the result on the Common Data Bus (CDB) which will feed into each Reservation Station to provide dependent instructions with the operands that they may be waiting for and mark the instruction as completed in the Reorder Buffer. Loads that miss in the data cache will wait in the load queue until the data is available at which point the load will be retried. Stores will let the Reorder Buffer know that it's ready to be retired but will not update the cache. |
| Retire | Once the instruction reaches the head of the Reorder Buffer and the instruction has been completed it will be retired which means it will be removed from the Reorder Buffer and the result value (if any) written into the Register File. For stores, the Reorder Buffer will signal the store queue to retire the store. The store queue will, as soon as the next cycle, tell the LSU to write the store data to the cache. If the store misses in the cache it will wait in the store queue until the cache-line is available. At this point the stores will also CAM the load queue and mark any load to the same address bytes as "mis-speculated". |
At a finer level, the processor's pipeline is organized as described below for the various execution paths.
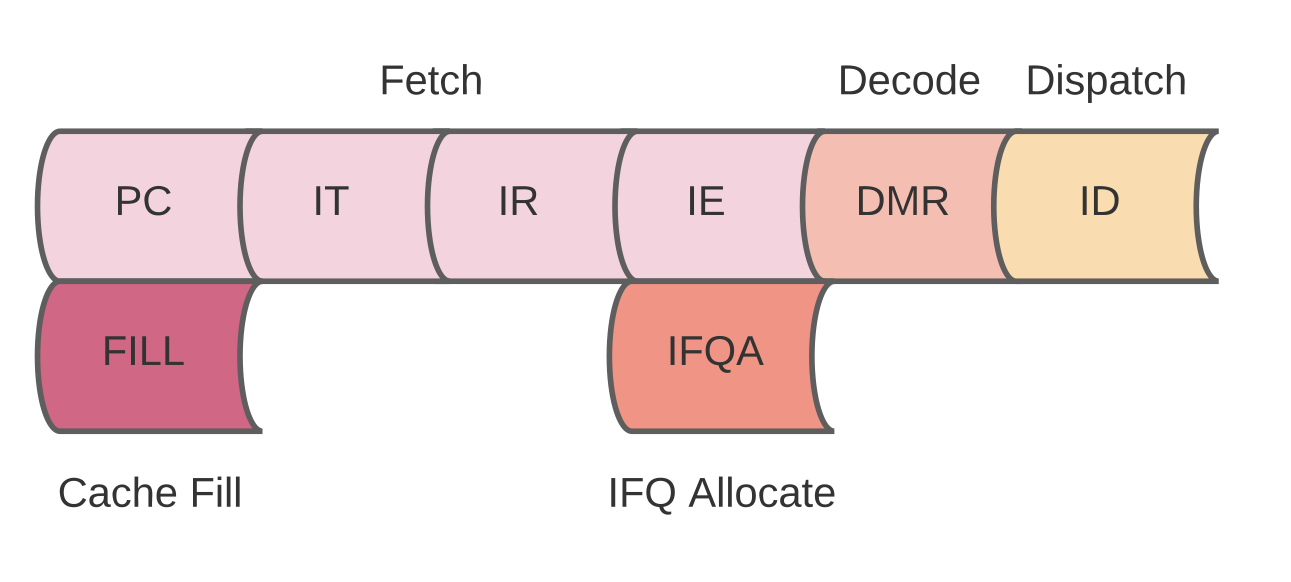
This part of the pipeline is the same for all ALU, branch and load/store instructions. It's composed of the Fetch, Decode and Dispatch stages.
The fetch stage is very simple at the moment. It simply takes the current PC and sends it to the iCache to read out and enqueuing it into the Instruction FIFO. It handles cache misses by allocating the PC in the Instruction Fetch Queue.
The PC Generator (PC) either increments the PC by 4 or maintains the current PC in case of structural hazards (Instruction FIFO full or Instruction Fetch Queue full) or sets it to the redirect address in case of a flush.
The Instruction Cache is queried for tag and the data (it will return the full cache-line) in this cycle (IT). The cache supports bypassing data from incoming fills.
Cache-line tags and validity are checked in this cycle (IR) and if a cache hit is indicated, the instruction data will be marked valid.
If there is a cache miss, the fetch unit will signal the Instruction Fetch Queue to retrieve the cache-line and stall. Once the cache-line is filled, the fetch unit will resume at the missed PC. If a valid instruction is found in the iCache, the fetch unit will enqueue it into the Instruction FIFO in this cycle (IE). It will stall if the instruction FIFO is full.
The Instruction Fetch Queue is very simple. It will simply request the CCU to retrieve the cache-line and then signal a fill request to the iCache when the cache-line is available.
Whenever the Fetch unit misses in the iCache it will send an allocate request to the Instruction Fetch Queue with the PC that missed.
In the DMR (Decode, Map & Rename) cycle the instruction will be decoded to produce a set of control signals indicating what this instruction does and what source operands it requires and various other bits. In addition, the source registers will be looked up in the Register Alias Table for either the value of the register or the producer of the register value if a previous instruction is in the process of writing to it. This lookup resolves RAW hazards.
The destination register for the instruction (if needed) will be renamed in the Register Alias Table as well thus avoiding WAR and WAW hazards. An entry will be reserved in both the Reorder Buffer and Reservation Station in this cycle and will be filled with the instruction details in the next cycle. If either the Reorder Buffer or the Reservation Station are full, then the pipeline will stall here.
The Reorder Buffer and the Reservation Station will be updated in this cycle simply enqueuing the new op. Data for source operands will be bypassed from the CDB before enqueuing in the Reservation Station in case the CDB is valid in the same cycle.
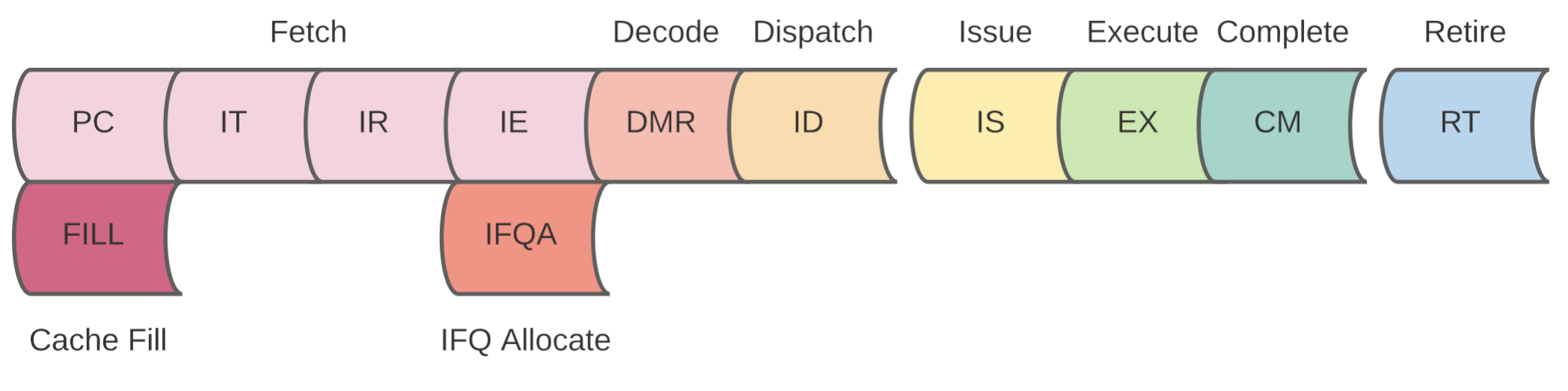
The IEU (Integer Execution Unit) executes all ALU and branch instructions in the execution stage of the pipeline.
The operation is performed in this cycle. Conditional branches are resolved but no redirection of the Front-End will happen in this cycle. The result data and Reorder Buffer entry number (i.e. this number is basically the renaming of the destination register) is prepared to be broad-casted over the Common Data Bus (CDB) in the next cycle (i.e. the "Complete" cycle). Each IEU is connected to it's own CDB so there is no hazard when driving the bus.
The instruction is marked as completed in the Reorder Buffer and it will wait there until it gets to the head of the Reorder Buffer.
Retiring instructions is straightforward for integer ALU instructions; they will simply update the destination register in the Register Alias Table with the calculated value and mark it as "not busy" if it's Reorder Buffer entry number was the last Reorder Buffer entry to update the register value. Branches will redirect the Front-End since it is now known that the branch is no longer speculative.
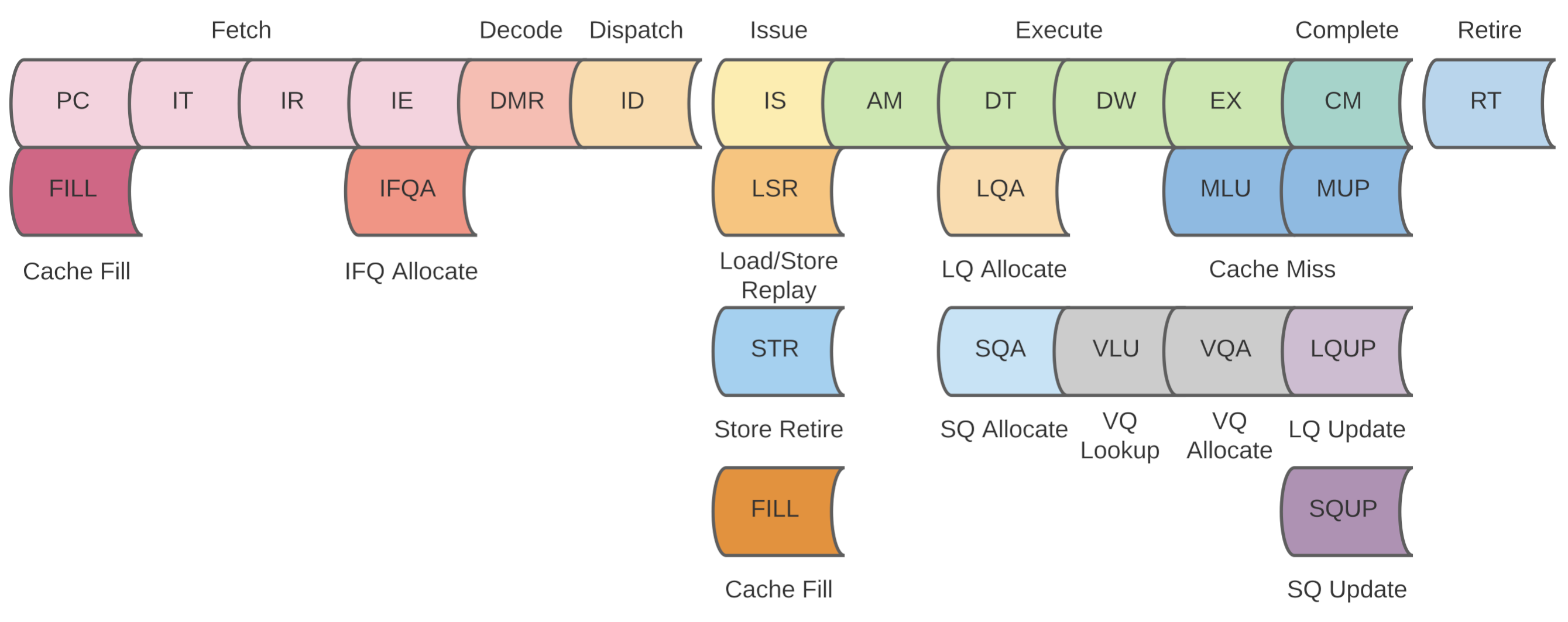
The load/store unit performs loads and stores in the execution stage. The main pipeline is split into four cycles but is complicated by data cache misses and structural hazards due to cache fills, older loads/stores replaying or stores retiring.
The Load/Store Unit is split into four main cycles assuming a cache hit; AM, DT, DW, and EX. There are several structures in the LSU and around it that are key to successful operation. These are the Load Queue, Store Queue, Victim Queue and Miss Handling Queue.
For new loads or stores the effective address is calculated. An entry is allocated in either the Load Queue or Store Queue (depending on the instruction) and the address, instruction type and destination Reorder Buffer entry number is stored but if the Load or Store Queue is full, the LSU pipeline will stall here. There is an extra wrinkle in this pipeline cycle; previous loads may be replayed, stores may be retired and cache-lines will be filled and these operations all are muxed into the LSU pipeline. Cache fills have priority followed by retiring stores and then replaying loads and then finally new instructions.
The Data Cache is queried for tag and the data (it will return the full cache-line) in this cycle. Write data from the next cycle is bypassed here to avoid RAW memory hazards.
In the same cycle as DT (Data Cache Data/Tag Read), an entry will be allocated in either the Load Queue or Store Queue depending on whether the instruction is a Load or Store with the relevant details stored in the entry.
Cache-line tags and validity are checked here and if a cache hit is indicated, the load data will be marked valid and retiring store data will be written into the cache.
The Victim Queue will be queried for load operations only. Valid data can be bypassed from the Victim Queue with a hit signal indicating the lookup was successful.
The execute stage is straightforward. The actual bytes needed by the load instruction is extracted from the cache-line and prepared to be driven on the CDB alongside the Reorder Buffer entry number. If a cache fill operation occurred and there is a victimized cache-line, that cache-line will be allocated in the Victim Queue in this cycle. The victimized cache-line will eventually be written out to memory but is available for lookups by load operations while waiting in the Victim Queue.
The data on the CDB will be used to forward any load data to dependent instructions in any of the Reservation Stations. The Reorder Buffer entry for the instruction will be marked as completed and it'll wait there until it is ready to be retired. Stores will not write to the Data Cache until they are retired to prevent mis-speculated updates to the cache and maintain precise interrupts. Both loads and stores will be kept in the respective queues until they are retired. For loads this allows retiring stores to look up younger loads and mark them as mis-speculated if the address ranges overlap. There is no store data bypassing in the LSU so this is necessary.
During the same cycle as CM (complete), the Load Queue and Store Queue will be updated with the Miss Handling Queue tag or told to "sleep" until the next Miss Handling Queue fill request comes through in the case the load or store missed in the cache and the Miss Handling Queue is full. Load & stores will be immediately be marked replayable if the cache-line they need is ready in the Miss Handling Queue and the Miss Handling Queue is ready to launch a cache fill request to the LSU.
Loads will be deallocated from the Load Queue if a mis-speculation did not occur. If the load was speculatively executed and an older Store wrote to the same bytes as the load, it'll be marked as mis-speculated in the Reorder Buffer and the Reorder Buffer will flush the entire pipeline and restart execution at the mis-speculated load. Stores will be removed from the Reorder Buffer but not from the Store Queue. Instead they will be marked as non-speculative or retired in the Store Queue. This mechanism is described further below.
Retiring stores will be marked as such in the Store Queue. When the Store Queue detects any stores that are ready to be actually written into the Data Cache, it will select one store and send it to the beginning of the LSU pipeline where it'll contend for access to the pipeline with Cache Fills. Once it is in the pipeline it'll go through the same cycles as described above except the data will be written in the Data Cache in the DW cycle. In the case that the store misses in the cache, it'll attempt to allocate into the Miss Handling Queue (MHQ). If the Miss Handling Queue is full, the EX cycle will signal the Store Queue to put the store to "sleep" and wait for the Miss Handling Queue to indicate that an entry is free at which point it will be "replayed". If the Miss Handling Queue is not full, the store will write it's data into the Miss Handling Queue registers and the Store Queue entry will be deallocated at the end of the EX cycle.
Loads that miss in the Data Cache will have to be "replayed" later. Loads will attempt to allocate in the Miss Handling Queue on a cache miss. If the Miss Handling Queue is full, the EX cycle will signal the Load Queue to put the instruction to "sleep" and wait for the Miss Handling Queue to indicate that an entry is free. If the Miss Handling Queue is not full, the Load Queue will be updated to indicate that it is waiting for the cache-line and which Miss Handling Queue entry will provide the cache-line. When the Miss Handling Queue indicates that it is no longer full, the loads waiting for a Miss Handling Queue entry will be sent to the beginning of the LSU pipeline and compete for access with retiring stores and cache fills and basically go through the same flow as described above. When the Miss Handling Queue is finished retrieving the cache-line for a specific entry it will signal the Load Queue with that Miss Handling Queue entry number. The Load Queue will perform a CAM search on the Miss Handling Queue entry number and "wake up" any loads that were waiting on that data. One of those loads will be selected by the Load Queue and sent to the beginning of the LSU pipeline to be replayed.
The Miss Handling Queue takes care of any cache misses. It interfaces with the BIU and provides storage for a cache-line of data for each entry.
The Miss Handling Queue is looked up in the same cycle as the LSU EX cycle. This is to find a matching entry or a new entry for the given load/store address if any exists so that, for loads, the Load Queue can be updated in the next cycle in case of a cache miss and for stores, the store data can be written to the Miss Handling Queue entry in case of a cache miss.
A new entry is allocated in this cycle in case of a cache miss. If an entry already exists for the given load/store address the load/store will be simply be merged with this entry. For stores, this means the store data will be written into the cache-line buffer for the entry (in both the new or existing entry cases). The Miss Handling Queue will interface with the BIU to request data and write received data into the entry merging the received data with the store data. There is a bypass network to select store data to be written into the buffer over received data from the BIU in case they occur on the same cycle.
When a full cache-line is received from the BIU, the Miss Handling Queue will signal the LSU pipeline to perform the Cache Fill. This goes through the same LSU pipeline flow as described above. Cache Fills take priority over any other LSU pipeline operation.
The Victim Queue holds victimized cache-lines due to cache fill operations. The Victim Queue allows lookups and bypasses valid data for load operations only.
After the DT stage, the Victim Queue is queried for data for the load operation. If it is available, the data will be sent to the LSU with a hit signal in the next cycle.
After a cache fill operation writes into the Data Cache, the victimized cache-line will be allocated into the Victim Queue in the LSU EX stage. The victim cache-line is available for lookups by load operations. Since writes may update the victimized cache-line by enqueuing into the MHQ, the Victim Queue may hold stale data that can be used by subsequent loads. This scenario is handled by the store operation marking all younger loads as mis-speculated causing those loads to flush the core and restart from the mis-speculated load. In the case that the VQ is full, the MHQ will not issue any cache fill operations even if it can until the VQ is no longer full. The VQ gets priority over the MHQ and IFQ by the CCU arbiter.