First of all, this project wouldn't had been possible without Maciek Dziubiński.
The repository works on building a model that takes in input the front camera image and generates the top-down view as well as simultaneous map generation (Can be thought of 2D SLAM).

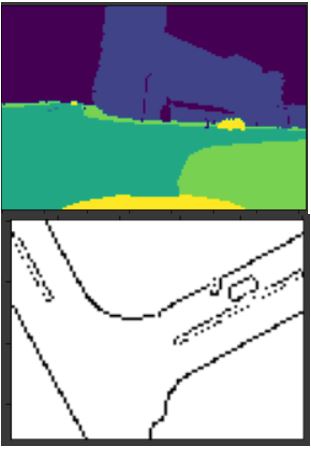
3 Models were trained:
- U-Net
- Autoencoder
- Deeper Autoencoder
Model was trained using following losses:
- SSIM
- Dice Loss
- Cross Entropy Loss
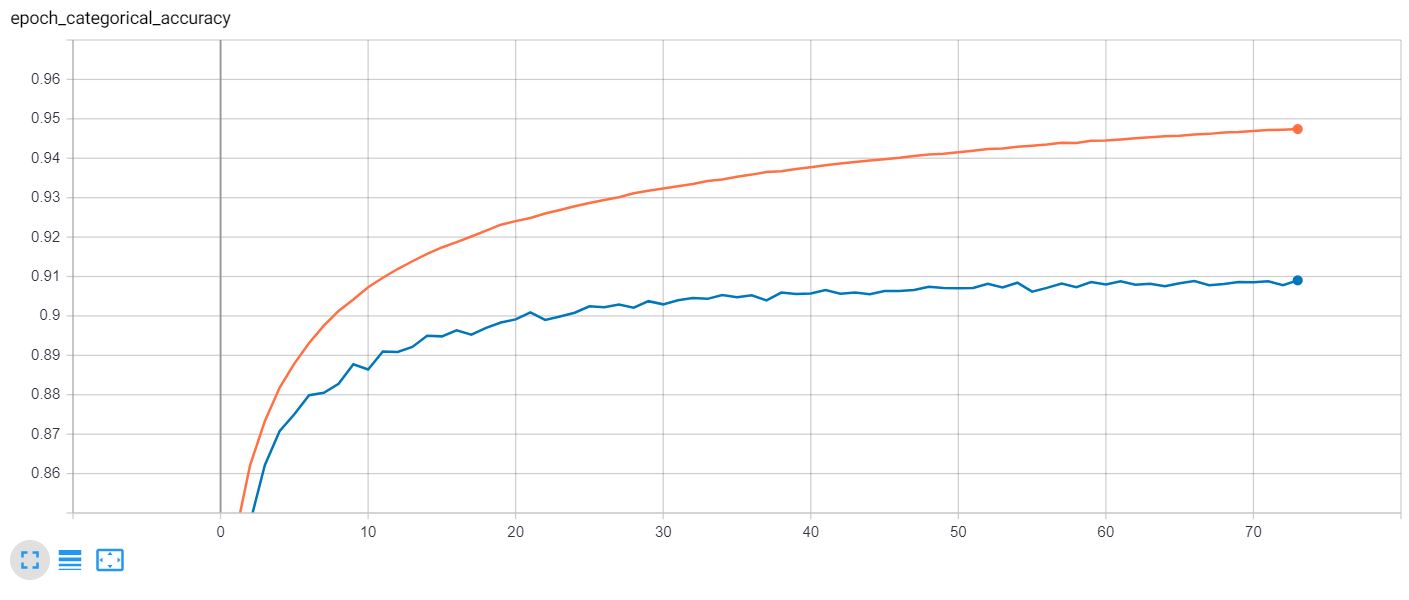
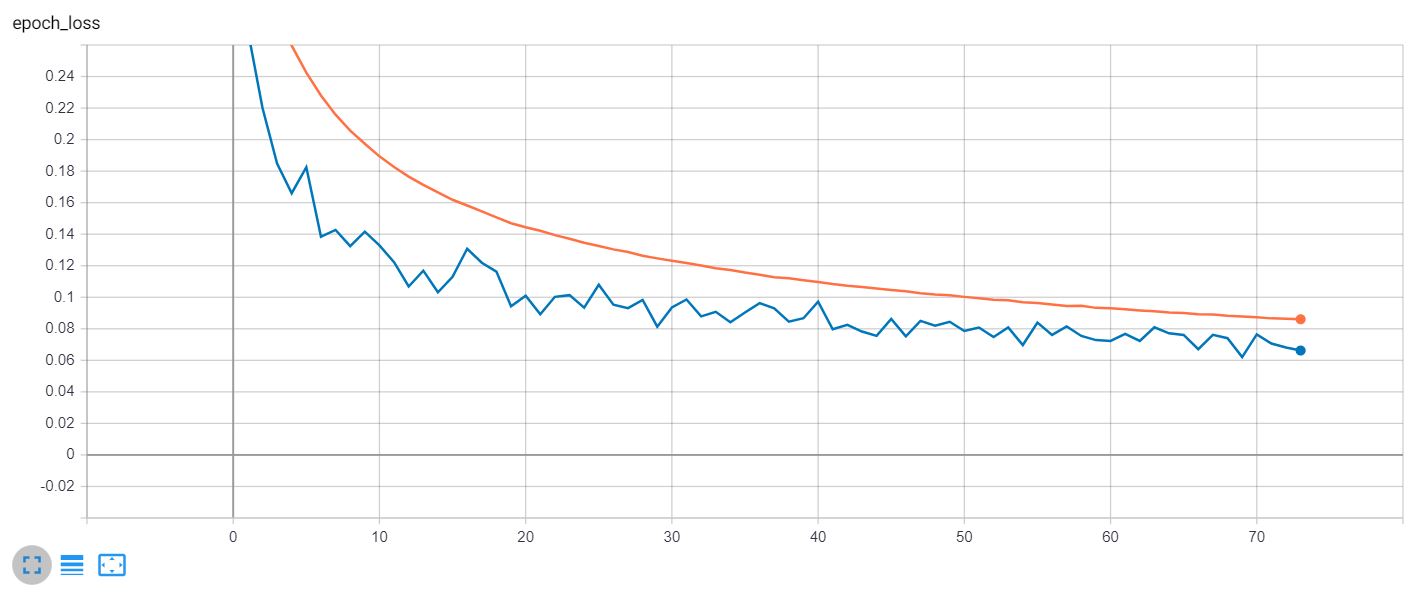

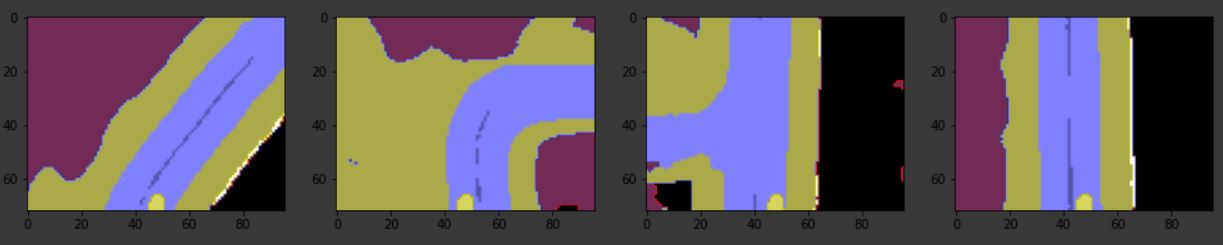
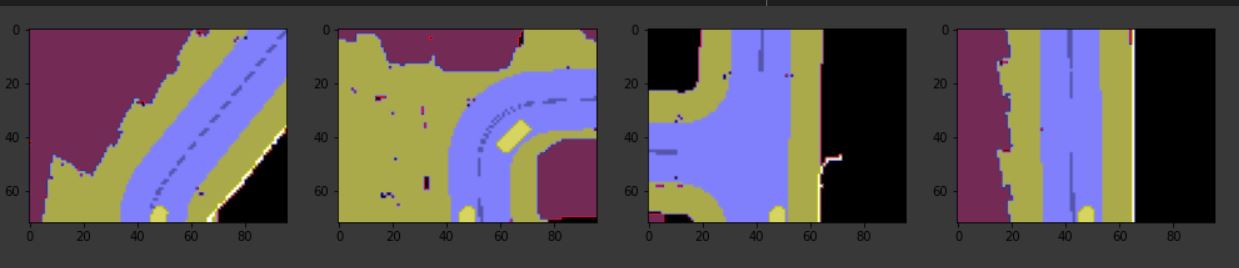
The model was trained on a simulator, but I was able to obtain good results after finetuning the model and some further image processing. See how the car is correctly localized to the right and th road curve is correctly detected.

This is based on image stitching using map coordinate metadata. I noticed that SIFT/SURF, etc based image feature extractors and matchers do not work in this case since the images produced are very symmetrical and sparse in colors, therefore, no good/unique features can be extracted from these images to perform stitching based on pixels.
Hence, we use location coordintes based stitching. Images are simply overlapped along with correct rotation.
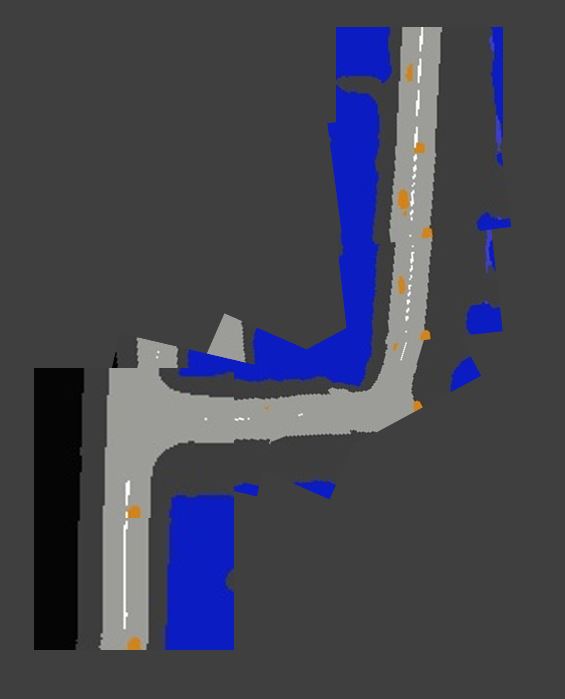
Dataset can be found here.

Although, the dataset contains images from five camera:
- Front
- Top
- Left
- Right
- Rear
Note: For training the model, only front images were used to predict the half top-down image.