This project is a Flask web application that utilizes a combination of language models and document embeddings for text-based conversation and document retrieval. It integrates Google's GenerativeAI models and Pinecone Vector Database to provide conversational AI capabilities and efficient document search.
- Clone the repository:
git clone <repository_url>
cd <repository_name>- Install dependencies:
pip install -r requirements.txt-
Set up environment variables:
Create a
.envfile in the root directory and add the following:PINECONE_API_KEY=<your_pinecone_api_key> PINECONE_INDEX_NAME=<your_pinecone_index_name> -
Run the Flask application:
python app.pySure, let's add that information to the Usage section:
-
Set up environment variables:
Create a
.envfile in the root directory and add the following:PINECONE_API_KEY=<your_pinecone_api_key> PINECONE_INDEX_NAME=<your_pinecone_index_name> -
Run the Flask application:
python app.py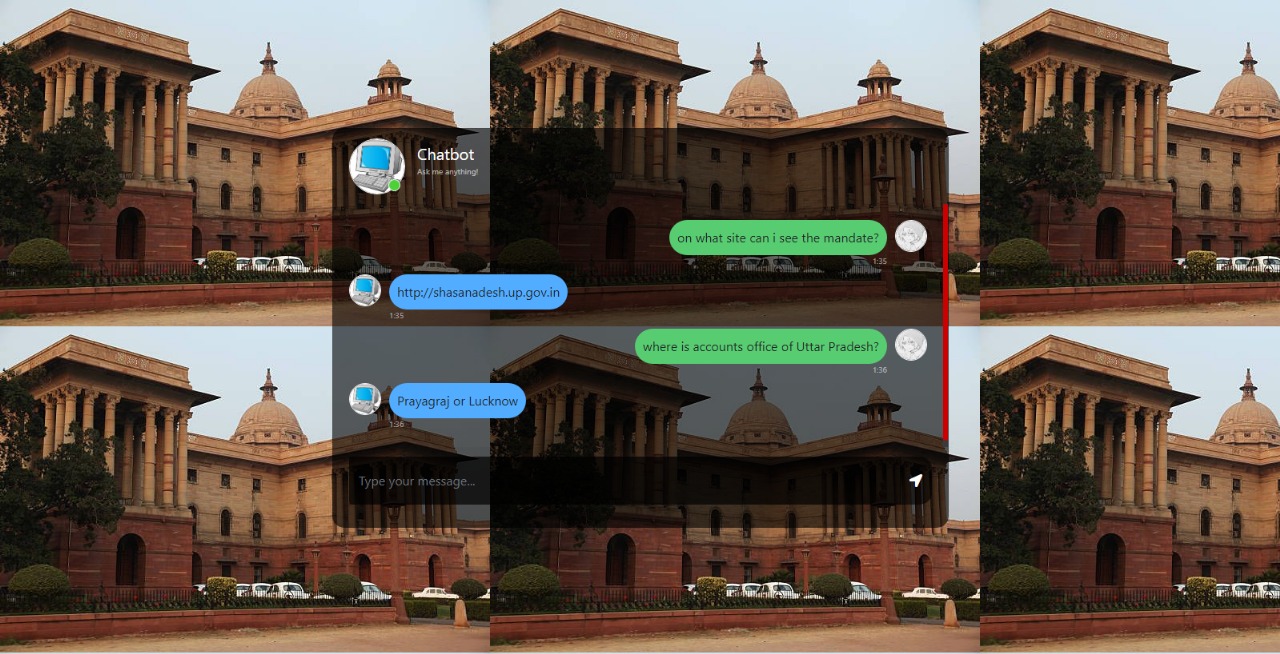
- Run the script to store document indexes:
python store_indexes.py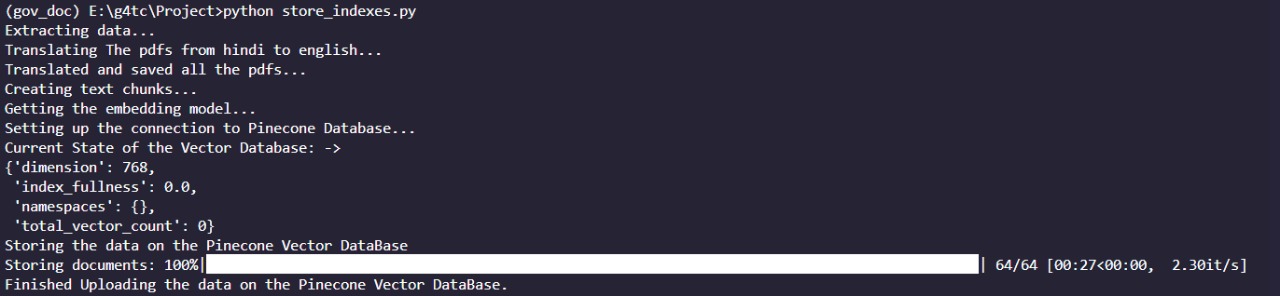 This step is necessary to ensure that the document indexes are properly stored in the Pinecone Vector Database for efficient retrieval.
This step is necessary to ensure that the document indexes are properly stored in the Pinecone Vector Database for efficient retrieval.
- Access the application in your web browser at
http://localhost:8000.
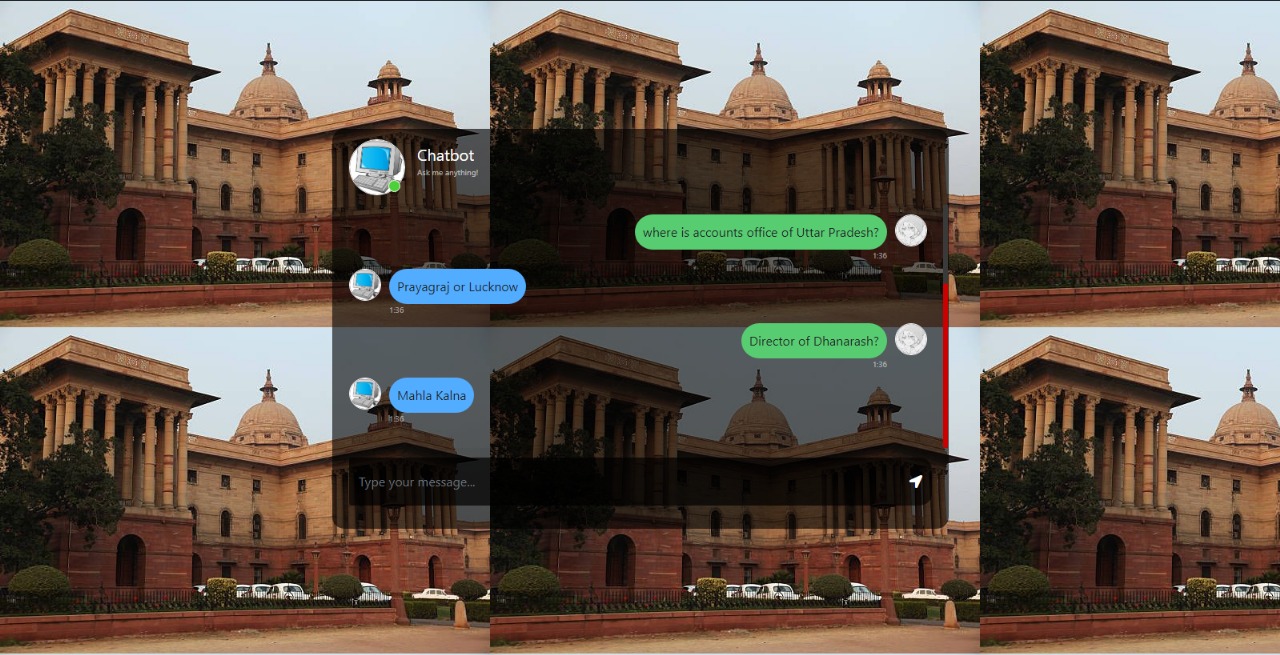
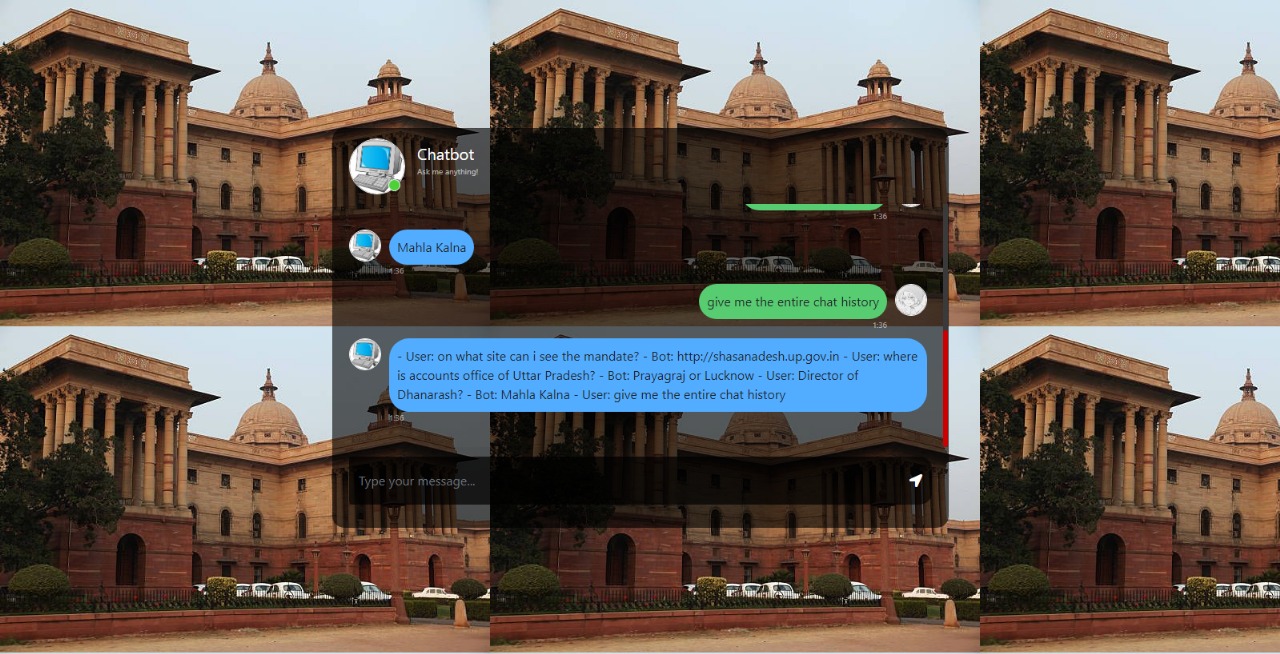
- Chat Interface: Engage in conversation with the integrated generative AI model.
- Document Search: Retrieve relevant documents based on user queries.
- PDF Processing: Extract text from PDF documents, translate from Hindi to English, and split into manageable chunks.
- Pinecone Integration: Store document embeddings for efficient retrieval and search.
This function handles the chat interaction between the user and the AI model. It processes user input, retrieves relevant documents, and generates a response using the generative AI model.
@app.route("/get", methods=["GET", "POST"])
def chat():
# Process user input
msg = request.form["msg"]
chat_history.append(("User", msg))
# Retrieve relevant documents
info = retriever.get_relevant_documents(msg)
# Generate response
formatted_prompt = prompt_template.format(question=msg, context=info, history=chat_history)
response = chatting.send_message(formatted_prompt)
chat_history.append(("Bot", response.text))
return str(response.text)This function extracts text from PDF documents, translates from Hindi to English, splits into chunks, retrieves embeddings, and stores them in the Pinecone Vector Database.
def store_vectors():
chunks = helper.get_chunks_from_pdf(path="test_documents")
embeddings = helper.get_embeddings()
index = helper.pinecone_init()
done = helper.store_data(text_chunks=chunks, embeddings=embeddings, index=index)
if done == False:
exit()- PDF Extraction: PDF documents are loaded and their text content is extracted.
# Load PDFs and extract text
chunks = helper.get_chunks_from_pdf(path="test_documents")- Translation: Hindi text, if present, is translated to English.
# Translate Hindi text to English
translations, data = helper.trans(data=extracted_data)- Text Chunking: Text is divided into manageable chunks for efficient processing.
# Split text into chunks
text_chunks = helper.text_split(extracted_data=data)- Embedding Generation: Text chunks are converted into embeddings using Hugging Face models.
# Retrieve embeddings
embeddings = helper.get_embeddings()- Pinecone Storage: Embeddings are stored in the Pinecone Vector Database for fast retrieval.
# Store vectors in Pinecone
done = helper.store_data(text_chunks=chunks, embeddings=embeddings, index=index)# Import necessary modules
import src.helper as helper
# Extract text from PDFs, translate, and store vectors
helper.store_vectors()Contributions are welcome! Please open an issue or submit a pull request with any improvements or bug fixes.