forked from rbmonster/learning-note
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
125 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,125 @@ | ||
| <a name="index">**Index**</a> | ||
|
|
||
| * [Apache Flink](#Apache Flink) | ||
| * [1. 概念](#概念) | ||
| * [1.1. 处理无界和有界数据](#处理无界和有界数据) | ||
| * [1.2. 有状态与无状态](#有状态与无状态) | ||
| * [1.3. 流处理应用的基本组件](#流处理应用的基本组件) | ||
| * [1.3.1. 流](#流) | ||
| * [1.3.2. 应用状态](#应用状态) | ||
| * [1.3.3. 时间](#时间) | ||
| * [1.4. 应用场景](#应用场景) | ||
| * [1.4.1. 事件驱动型应用](#事件驱动型应用) | ||
| * [1.4.2. 数据分析应用](#数据分析应用) | ||
| * [1.4.3. 数据管道应用](#数据管道应用) | ||
| * [2. 参考资料](#参考资料) | ||
| # <a name="0">Apache Flink</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
|
|
||
| 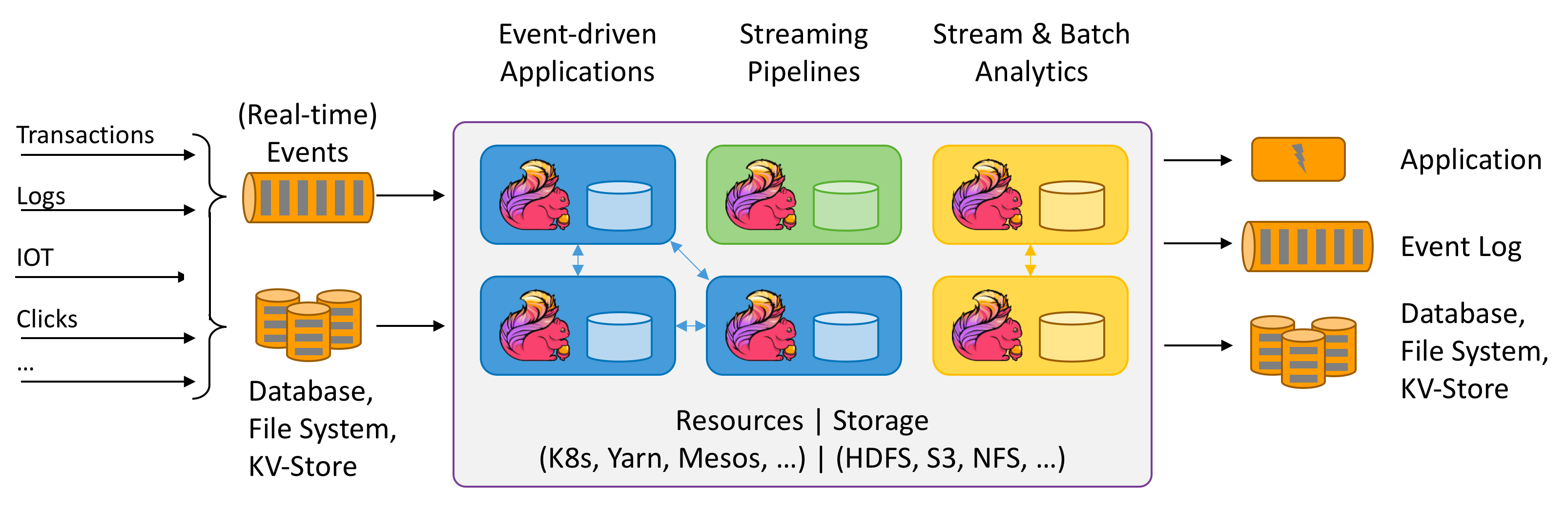 | ||
|
|
||
| ## <a name="1">概念</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| Apache Flink 是一个框架和分布式处理引擎,用于在**无边界和有边界数据流**上进行**有状态**的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 | ||
| - 分布式:「它的存储或者计算交由多台服务器上完成,最后汇总起来达到最终的效果」。 | ||
| - 实时:处理速度是毫秒级或者秒级的 | ||
| - 计算:可以简单理解为对数据进行处理,比如清洗数据(对数据进行规整,取出有用的数据) | ||
|
|
||
| ### <a name="2">处理无界和有界数据</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。 | ||
|
|
||
| 数据可以被作为**无界或者有界流**来处理。 | ||
| 1. **无界流**:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 | ||
| 2. **有界流**:有定义流的开始,也有定义流的结束。**有界流可以在摄取所有数据后再进行计算**。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为**批处理**。 | ||
|
|
||
| **Apache Flink 擅长处理无界和有界数据集**,精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。 | ||
|
|
||
| 无边界: 来一条处理一条。\ | ||
| 有边界: 如做数据统计:每个小时的pv(page view)是多少,那我就设置1小时的边界,攒着一小时的数据来处理一次。\ | ||
| 在Flink上,设置“边界”这种操作叫做开窗口(Windows),窗口可简单分为两种类型: | ||
| 1. 时间窗口(TimeWindows):按照时间窗口进行聚合,比如上面所讲得攥着一个小时的数据处理一次。 | ||
| 2. 计数窗口(CountWindows):按照指定的条数来进行聚合,比如每来了10条数据处理一次。 | ||
|
|
||
| ### <a name="3">有状态与无状态</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 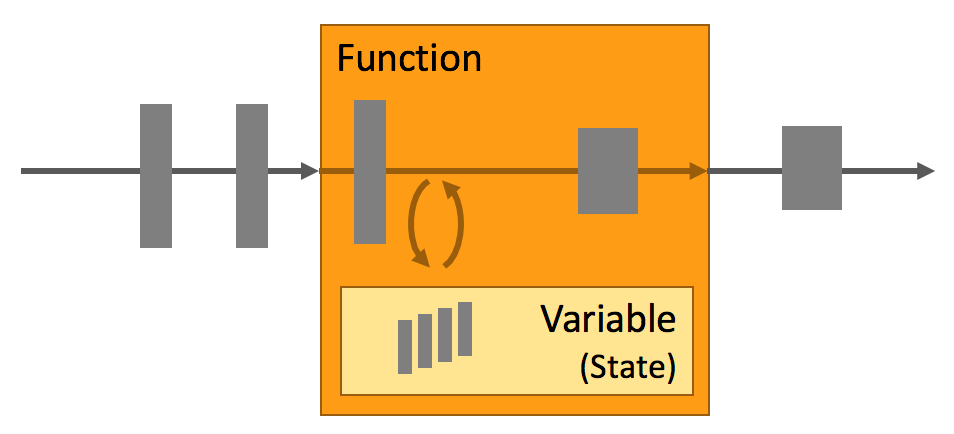 | ||
|
|
||
| 状态:只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的。任何运行基本业务逻辑的流处理应用都需要在**一定时间内存储所接收的事件或中间结果**,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理。 | ||
| > 无状态:每次的执行都**不依赖**上一次或上N次的执行结果,每次的执行都是**独立**的。 | ||
| > 有状态:执行**需要依赖**上一次或上N次的执行结果,某次的执行需要依赖前面事件的处理结果。 | ||
|
|
||
| ### <a name="4">流处理应用的基本组件</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
|
|
||
| #### <a name="5">流</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| - **有界** 和 **无界** 的数据流:流可以是无界的;也可以是有界的,例如固定大小的数据集。Flink 在无界的数据流处理上拥有诸多功能强大的特性,同时也针对有界的数据流开发了专用的高效算子。 | ||
| - **实时** 和 **历史记录** 的数据流:所有的数据都是以流的方式产生。 | ||
| > 用户通常会使用两种截然不同的方法处理数据。第一种是在数据生成时进行实时的处理;第二种是先将数据流持久化到存储系统中——例如文件系统或对象存储,然后再进行批处理。Flink 的应用能够同时支持处理实时以及历史记录数据流。 | ||
| #### <a name="6">应用状态</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 应用状态是 Flink 中的一等公民,Flink 提供了许多状态管理相关的特性 | ||
| - **多种状态基础类型**:Flink 为多种不同的数据结构提供了相对应的状态基础类型,例如原子值(value),列表(list)以及映射(map)。 | ||
| - **插件化的State Backend**:State Backend 负责管理应用程序状态,并在需要的时候进行 checkpoint。Flink 支持多种 state backend,可以将状态存在内存或者 RocksDB。 | ||
| - **精确一次语义**:Flink 的 checkpoint 和故障恢复算法保证了故障发生后应用状态的一致性。因此,Flink 能够在应用程序发生故障时,对应用程序透明,不造成正确性的影响。 | ||
| - **超大数据量状态**:Flink 能够利用其异步以及增量式的 checkpoint 算法,存储数 TB 级别的应用状态。 | ||
| - **可弹性伸缩的应用**:Flink 能够通过在更多或更少的工作节点上对状态进行重新分布,支持有状态应用的分布式的横向伸缩。 | ||
|
|
||
| 流的语义性有三种: | ||
| - 精确一次性(exactly once):有且只有一条,不多不少 | ||
| - 至少一次(at least once):最少会有一条,只多不少 | ||
| - 最多一次(at most once):最多只有一条,可能会没有 | ||
|
|
||
| **Flink的精确一次性**指的是:状态只持久化一次到最终的存储介质中(本地数据库/HDFS等等) | ||
| > `Source`数据流有以下数字`21,13,8,5,3,2,1,1` -> 从右往左进行消费,当消费了`2,1,1`后state为4,在进行`5,3`消费时,若未持久化系统宕机,那么`5,3`会再次进行计算消费。 | ||
| 状态只持久化一次到最终的存储介质中(本地数据库/HDFS),在Flink下就叫做`exactly once`(计算的数据可能会重复(无法避免),但状态在存储介质上只会存储一次)。 | ||
| > 持久化时间设置,配置中设置checkpointInterval。而`CheckPoint`其实就是Flink会在指定的时间段上保存状态的信息,如果系统宕机则从`checkpoint`重放还没保存的数据进行计算。 | ||
| #### <a name="7">时间</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 许多常见的流计算都基于时间语义,例如窗口聚合、会话计算、模式检测和基于时间的 join。流处理的一个重要方面是应用程序如何衡量时间,即区分事件时间(`event-time`)和处理时间(`processing-time`)。 | ||
|
|
||
| **时间窗口的参数**: | ||
|
|
||
| Flink 提供了丰富的时间语义支持: | ||
| - **事件时间模式**:使用事件时间语义的流处理应用根据事件本身自带的时间戳进行结果的计算。即以事件处理时间为准。 | ||
| - **Watermark 支持**:Flink 引入了 watermark 的概念,用以衡量事件时间进展。Watermark 也是一种平衡处理延时和完整性的灵活机制。 | ||
| - **迟到数据处理**:当以带有 watermark 的事件时间模式处理数据流时,在计算完成之后仍会有相关数据到达。这样的事件被称为迟到事件。Flink 提供了多种处理迟到数据的选项,例如将这些数据重定向到旁路输出(side output)或者更新之前完成计算的结果。 | ||
| - **处理时间模式**:除了事件时间模式,Flink 还支持处理时间语义。处理时间模式根据处理引擎的机器时钟触发计算,一般适用于有着**严格的低延迟需求**,并且能够容忍近似结果的流处理应用。 | ||
|
|
||
| Flink的**时间语义**: 不指定默认是数据到Flink的时间`Processing Time`来进行聚合处理,flink可以给我们指定聚合的时间以事件发生的时间`Event Time`来进行处理。 | ||
| > 解释:在11:06分产生了5条数据,在11:07分产生了4条数据,按每分钟的维度来进行聚合计算。可能由于网络的延迟性等原因,导致06分的3条数据在07分时Flink才接收到。如果不做任何处理,那07分有可能处理了7条条数据。对于需要准确结果的场景来说不准确。 | ||
| Flink的水位线`waterMarks`:存在网络延迟等情况导致数据接收不是有序,根据场景的需求可以设置一个**延迟时间**,等延迟的时间到了,flink再聚合统一聚合。 | ||
| > 解读:因为设置了「事件发生的时间」Event Time,所以Flink可以检测到每一条记录发生的时间,而设置了水位线waterMarks设置延迟一分钟,等到Flink发现07分:59秒的数据来到了Flink,那就确信06分的数据都来了(因为设置了1分钟延迟),此时才聚合06分的窗口数据。 | ||
|
|
||
| ### <a name="8">应用场景</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| #### <a name="9">事件驱动型应用</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。 | ||
|
|
||
| 在传统架构中,应用需要读写远程事务型数据库。 相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。 | ||
| 优点: | ||
| 1. 事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟。 | ||
| 2. 传统分层架构下,通常多个应用会共享同一个数据库,因而任何对数据库自身的更改都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此在更改数据表示或服务扩容时所需的协调工作将大大减少。 | ||
|
|
||
| 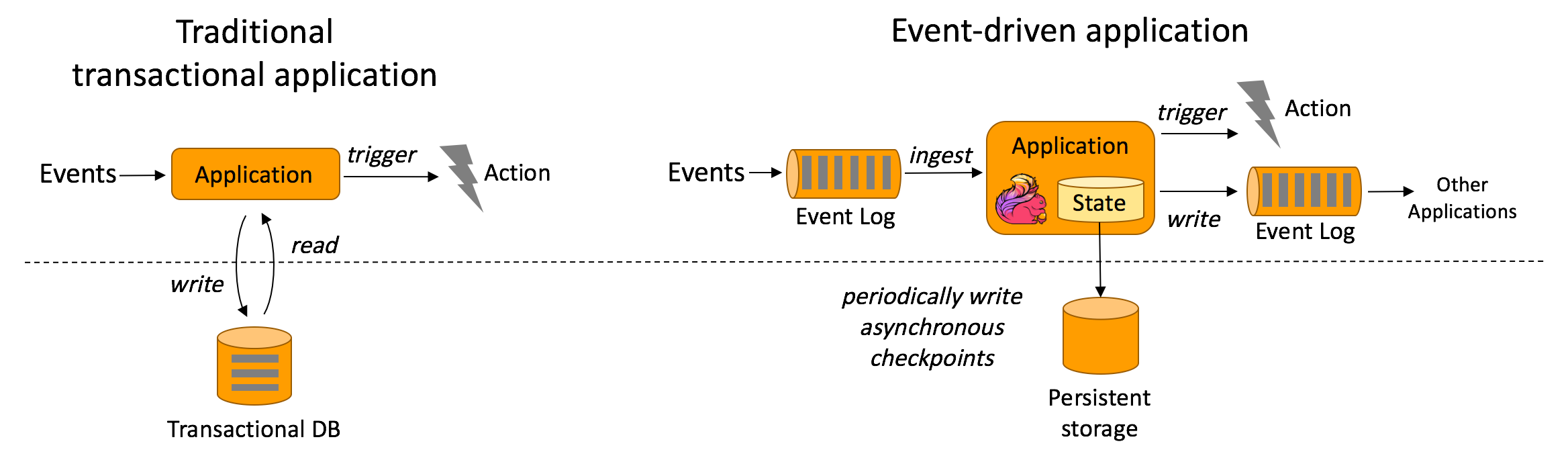 | ||
|
|
||
| #### <a name="10">数据分析应用</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 数据分析任务需要从原始数据中提取有价值的信息和指标。 | ||
|
|
||
| 传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。 | ||
| 和传统模式下读取有限数据集不同,流式查询或应用会接入实时事件流,并随着事件消费持续产生和更新结果。这些结果数据可能会写入外部数据库系统或以内部状态的形式维护。仪表展示应用可以相应地从外部数据库读取数据或直接查询应用的内部状态。 | ||
|
|
||
| 优点: | ||
| 1. 流式分析省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低 | ||
| 2. 导入数据的处理。批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界,而流式查询则无须考虑该问题。 | ||
| 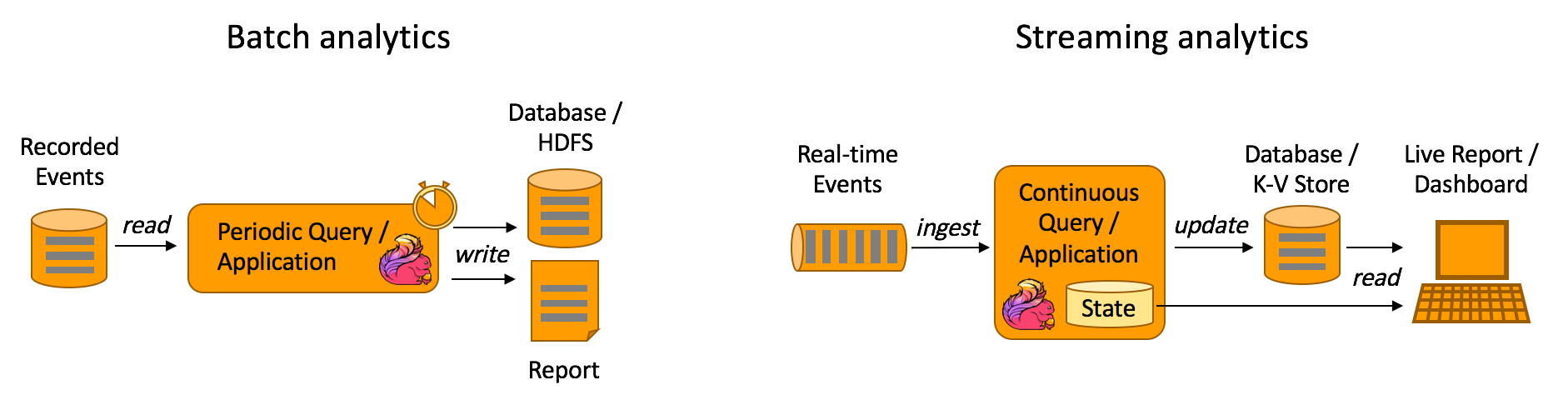 | ||
|
|
||
| #### <a name="11">数据管道应用</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| 提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。 | ||
| 数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个**不断生成数据的源头**读取记录,并将它们以低延迟移动到终点。 | ||
|
|
||
| 优点:和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。 | ||
| 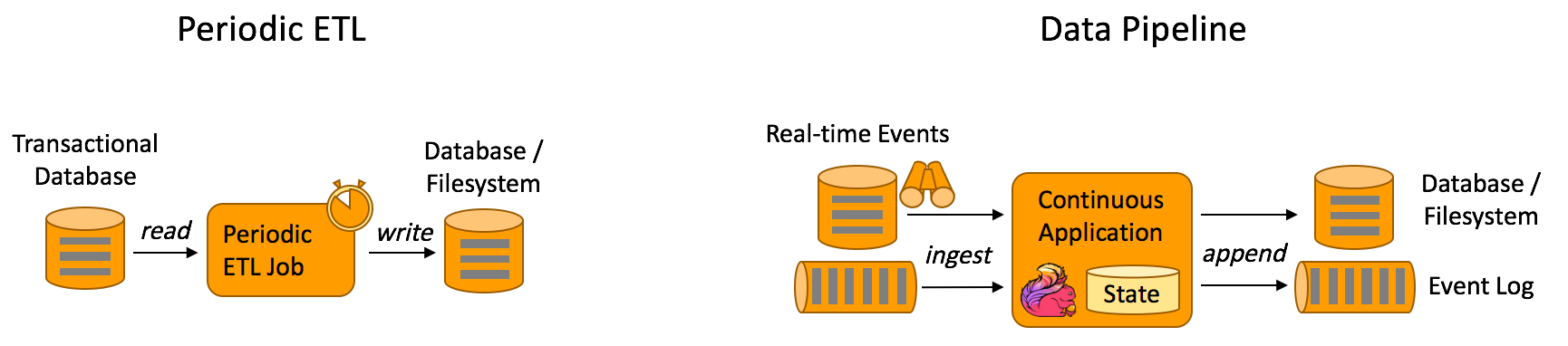 | ||
|
|
||
| 相关组件:Flink-CDC | ||
| ## <a name="12">参考资料</a><a style="float:right;text-decoration:none;" href="#index">[Top]</a> | ||
| - [Apache Flink 官网](https://flink.apache.org/zh/flink-architecture.html) | ||
| - [Flink入门教程](https://mp.weixin.qq.com/s/Ey-oWpGO_QDo4DixiccVGg) |