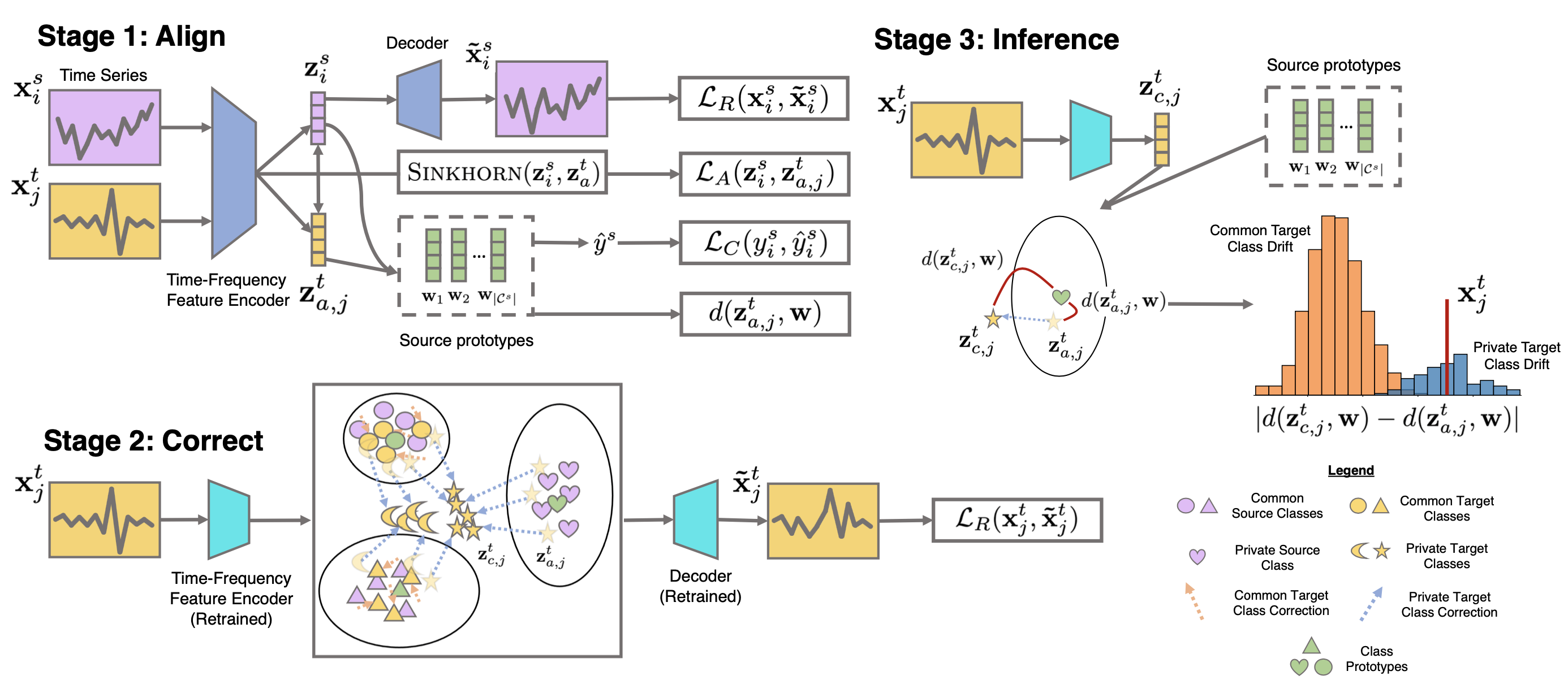
The transfer of models trained on labeled datasets from a source domain to unlabeled target domains is facilitated by unsupervised domain adaptation (UDA). However, when dealing with complex time series models, transferability becomes challenging due to differences in dynamic temporal structures between domains, which can result in feature shifts and gaps in time and frequency representations. Additionally, the label distributions in the source and target domains can be vastly different, making it difficult for UDA to address label shifts and recognize labels unique to the target domain. Raincoat is a domain adaptation method for time series that can handle both feature and label shifts.
Create a folder and download the pre-processed versions of the datasets WISDM, HAR, HHAR, Boiler, and Sleep-EDF.
To add new dataset (e.g., NewData), it should be placed in a folder named: NewData in the datasets directory.
Since "NewData" has several domains, each domain should be split into train/test splits with naming style as "train_x.pt" and "test_x.pt".
The structure of data files should in dictionary form as follows:
train.pt = {"samples": data, "labels: labels}, and similarly for test.pt.
- Python3
- Pytorch==1.7
- Numpy==1.20.1
- scikit-learn==0.24.1
- Pandas==1.2.4
- skorch==0.10.0
- openpyxl==3.0.7
Next, you have to add a class with the name NewData in the configs/data_model_configs.py file.
You can find similar classes for existing datasets as guidelines.
Also, you have to specify the cross-domain scenarios in self.scenarios variable.
Last, you have to add another class with the name NewData in the configs/hparams.py file to specify
the training parameters.
Our main model architecture can be found here.
Our training algorithm can be found here. The implementation is build upon a published benchmark work Adatime.
The experiments are organised in a hierarchical way such that:
- Several experiments are collected under one directory assigned by
--experiment_description. - Each experiment could have different trials, each is specified by
--run_description. - For example, if we want to experiment different UDA methods with CNN backbone, we can assign
--experiment_description CNN_backnones --run_description DANNand--experiment_description CNN_backnones --run_description DDCand so on.
To train a model:
python main.py --experiment_description exp1 \
--run_description run_1 \
--da_method DANN \
--dataset HHAR \
--backbone CNN \
--num_runs 5 \
@inproceedings{he2023domain,
title = {Domain Adaptation for Time Series Under Feature and Label Shifts},
author = {He, Huan and Queen, Owen and Koker, Teddy and Cuevas, Consuelo and Tsiligkaridis, Theodoros and Zitnik, Marinka},
booktitle = {https://arxiv.org/abs/2302.03133},
year = {2023}
}