

"The regex-centric, fast and flexible lexical analyzer generator for C++"
Flex reimagined. Fast, flexible, adds Boost 💪
RE/flex is faster than Flex while providing a wealth of new features. RE/flex is also much faster than regex libraries such as Boost.Regex, C++11 std::regex, PCRE2 and RE2. For example, tokenizing a representative C source code file into 244 tokens takes only 13 microseconds:
| Command / Function | Software | Time (μs) |
|---|---|---|
| reflex --fast | RE/flex | 13 |
| flex -+ --full | Flex | 17 |
| reflex --full | RE/flex | 29 |
| boost::spirit::lex::lexertl::actor_lexer::iterator_type | Boost.Spirit.Lex | 40 |
| reflex -m=boost-perl | Boost.Regex | 230 |
| pcre2_match() | PCRE2 (pre-compiled) | 318 |
| reflex -m=boost | Boost.Regex POSIX mode | 450 |
| flex -+ | Flex | 3968 |
| RE2::Consume() | RE2 (pre-compiled) | 5088 |
| RE2::Consume() | RE2 POSIX mode (pre-compiled) | 5420 |
| std::cregex_iterator() | C++11 std::regex | 14784 |
Note: Best times of 10 tests with average time in microseconds over 100 runs (using clang 8.0.0 with -O2, 2.9 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3).
- Compatible with Flex to eliminate a learning curve, making a transition to RE/flex frustration-free.
- Includes many examples, such as a tokenizer for C/C++ code, a tokenizer for Python code, a tokenizer for Java code, and more.
- Works with Bison and supports reentrant, bison-bridge, bison-locations and
Bison 3.0 C++ interface
%skeleton "lalr1.cc". - Extensive documentation in the online User Guide.
- Adds Unicode support with Unicode property matching
\p{C}and C++11, Java, C#, and Python Unicode properties for identifier name matching. - Adds indent/nodent/dedent anchors to match text with indentation, including
\t(tab) adjustments. - Adds lazy quantifiers to the POSIX regular expression syntax, so hacks are no longer needed to work around greedy repetitions in Flex.
- Adds word boundary anchors to the POSIX regular expression syntax.
- Adds an extensible hierarchy of pattern matcher engines, with a choice of regex engines, including the RE/flex regex engine and Boost.Regex.
- Adds freespace mode option to improve readability of lexer specifications.
- Adds
%classand%initto customize the generated Lexer classes. - Adds
%includeto modularize lexer specifications. - Generates clean source code that defines an MT-safe (reentrant) C++ Lexer class derived from an abstract lexer class template, parameterized by matcher class type.
- Multiple lexer classes can be combined and used in one application.
- Configurable Lexer class generation to customize the interface for various parsers, including Yacc and Bison.
- Generates scanners for lexical analysis on files, C++ streams, and (wide) strings, with automatic fast conversion of UTF-16/32 to UTF-8 for matching Unicode on UTF-encoded input files.
- Generates lex.yy.cpp files while Flex generates lex.yy.cc files (in C++ mode with flex option -+), to distinguish the generated files.
- Generates Graphviz files to visualize FSMs with the Graphviz dot tool.
- Conversion of regex expressions, for regex engines that lack regex features.
- The RE/flex regex library makes C++11 std::regex and Boost.Regex much easier to use in plain C++ code for pattern matching on (wide) strings, files, and streams.
The RE/flex software is fully self-contained. No other libraries are required. Boost.Regex is optional to use as a regex engine.
The RE/flex repo includes tokenizers for Java, Python, and C/C++.
Use reflex/bin/reflex.exe from the command line or add a Custom Build
Step in MSVC++ as follows:
-
select the project name in Solution Explorer then Property Pages from the View menu (see also custom-build steps in Visual Studio);
-
add an extra path to the
reflex/includefolder in the Include Directories under VC++ Directories, which should look like$(VC_IncludePath);$(WindowsSDK_IncludePath);C:\Users\YourUserName\Documents\reflex\include(this assumes thereflexsource package is in your Documents folder). -
enter
"C:\Users\YourUserName\Documents\reflex\bin\reflex.exe" --header-file "C:\Users\YourUserName\Documents\mylexer.l"in the Command Line property under Custom Build Step (this assumesmylexer.lis in your Documents folder); -
enter
lex.yy.h lex.yy.cppin the Outputs property; -
specify Execute Before as
PreBuildEvent.
If you are using specific reflex options such as --flex then add these in step 3.
Before compiling your program with MSVC++, drag the folders reflex/lib and
reflex/unicode to the Source Files in the Solution Explorer panel of
your project. Next, run reflex.exe simply by compiling your project (which
may fail, but that is OK for now as long as we executed the custom build step
to run reflex.exe). Drag the generated lex.yy.h and lex.yy.cpp files to
the Source Files. Now you are all set!
In addition, the reflex/vs directory contains batch scripts to build projects
with MS Visual Studio C++.
On Mac OS X you can use homebrew to install RE/flex with
brew install re-flex. Otherwise:
You have two options: 1) quick install or 2) configure and make.
First clone the code:
$ git clone https://github.com/Genivia/RE-flex
Then simply do a quick clean build, assuming your environment is pretty much standard:
$ ./clean.sh
$ ./build.sh
This compiles the reflex tool and installs it locally in reflex/bin. For
local use of RE/flex in your project, you can add this location to your $PATH
variable to enable the new reflex command:
$ export PATH=$PATH:/your_path_to_reflex/reflex/bin
Note that the libreflex.a and libreflex.so libraries are saved locally in
reflex/lib. Link against the library when you use the RE/flex regex engine
in your code, such as:
$ c++ <options and .o/.cpp files> -L/your_path_to_reflex/reflex/lib -lreflex
or you could statically link libreflex.a with:
$ c++ <options and .o/.cpp files> /your_path_to_reflex/reflex/lib/libreflex.a
Also note that the RE/flex header files that you will need to include in your
project are locally located in include/reflex.
To install the man page, the header files in /usr/local/include/reflex, the
library in /usr/local/lib and the reflex command in /usr/local/bin:
$ sudo ./allinstall.sh
The configure script accepts configuration and installation options. To view these options, run:
$ ./configure --help
Run configure and make:
$ ./configure && make
To build the examples also:
$ ./configure --enable-examples && make
After this successfully completes, you can optionally run make install to
install the reflex command and libreflex library:
$ sudo make install
Unfortunately, cloning from Git does not preserve timestamps which means that you may run into "WARNING: 'aclocal-1.15' is missing on your system." To work around this problem, run:
$ autoreconf -fi
$ ./configure && make
-
To use Boost.Regex as a regex engine with the RE/flex library and scanner generator, install Boost and link your code against
libboost_regex.a -
To visualize the FSM graphs generated with reflex option
--graphs-file, install Graphviz dot.
There are two ways you can use this project:
- as a scanner generator for C++, similar to Flex;
- as an extensible regex matching library for C++.
For the first option, simply build the reflex tool and run it on the command line on a lexer specification:
$ reflex --flex --bison --graphs-file lexspec.l
This generates a scanner for Bison from the lexer specification lexspec.l and
saves the finite state machine (FSM) as a Graphviz .gv file that can be
visualized with the Graphviz dot tool:
$ dot -Tpdf reflex.INITIAL.gv > reflex.INITIAL.pdf
$ open reflex.INITIAL.pdf
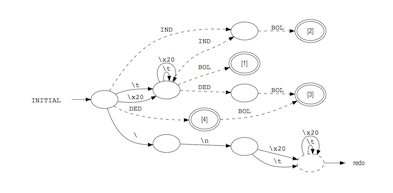
Several examples are included to get you started. See the manual for more details.
For the second option, simply use the new RE/flex matcher classes to start pattern matching on strings, wide strings, files, and streams.
You can select matchers that are based on different regex engines:
- RE/flex regex:
#include <reflex/matcher.h>and usereflex::Matcher; - Boost.Regex:
#include <reflex/boostmatcher.h>and usereflex::BoostMatcherorreflex::BoostPosixMatcher; - C++11 std::regex:
#include <reflex/stdmatcher.h>and usereflex::StdMatcherorreflex::StdPosixMatcher.
Each matcher may differ in regex syntax features (see the full documentation), but they have the same methods and iterators:
matches()returns nonzero if the input matches the specified pattern;find()search input and returns nonzero if a match was found;scan()scan input and returns nonzero if input at current position matches;split()returns nonzero for a split of the input at the next match;find.begin()...find.end()filter iterator;scan.begin()...scan.end()tokenizer iterator;split.begin()...split.end()splitter iterator.
For example:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
if (reflex::BoostMatcher("\\d{4}-\\d{2}-\\d{2}", birthdate).matches() != 0)
std::cout << "Valid date!" << std::endl;
With a group capture to fetch the year:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
reflex::BoostMatcher matcher("(\\d{4})-\\d{2}-\\d{2}", birthdate);
if (matcher.matches() != 0)
std::cout << std::string(matcher[1].first, matcher[1].second) << " was a good year!" << std::endl;
To search a string for words \w+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
while (matcher.find() != 0)
std::cout << "Found " << matcher.text() << std::endl;
The split method is roughly the inverse of the find method and returns text
located between matches. For example using non-word matching \W+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\W+", "How now brown cow.");
while (matcher.split())
std::cout << "Found " << matcher.text() << std::endl;
To pattern match the content of a file that may use UTF-8, 16, or 32 encodings:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a FILE
FILE *fd = fopen("somefile.txt", "r");
if (fd == NULL)
exit(EXIT_FAILURE);
reflex::BoostMatcher matcher("\\w+", fd);
while (matcher.find())
std::cout << "Found " << matcher.text() << std::endl;
fclose(fd);
Same again, but this time with a C++ input stream:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a stream
std::ifstream file("somefile.txt", std::ifstream::in);
reflex::BoostMatcher matcher("\\w+", file);
while (matcher.find())
std::cout << "Found " << matcher.text() << std::endl;
file.close();
Stuffing the search results into a container using RE/flex iterators:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
#include <vector> // std::vector
// use a BoostMatcher to convert words of a sentence into a string vector
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
std::vector<std::string> words(matcher.find.begin(), matcher.find.end());
Use C++11 range-based loops with RE/flex iterators:
#include <reflex/stdmatcher.h> // reflex::StdMatcher, reflex::Input, std::regex
// use a StdMatcher with std::regex to to search for words in a sentence
for (auto& match : reflex::StdMatcher("\\w+", "How now brown cow.").find)
std::cout << "Found " << match.text() << std::endl;
RE/flex also allows you to convert expressive regex syntax forms such as \p
Unicode classes, character class set operations such as [a-z--[aeiou]],
escapes such as \X, and (?x) mode modifiers, to a regex string that the
underlying regex library understands and will be able to use:
std::string reflex::Matcher::convert(const std::string& regex, reflex::convert_flag_type flags)std::string reflex::BoostMatcher::convert(const std::string& regex, reflex::convert_flag_type flags)std::string reflex::StdMatcher::convert(const std::string& regex, reflex::convert_flag_type flags)
For example:
#include <reflex/matcher.h> // reflex::Matcher, reflex::Input, reflex::Pattern
// use a Matcher to check if sentence is in Greek:
static const reflex::Pattern pattern(reflex::Matcher::convert("[\\p{Greek}\\p{Zs}\\pP]+", reflex::convert_flag::unicode));
if (reflex::Matcher(pattern, sentence).matches() != 0)
std::cout << "This is Greek" << std::endl;
We use convert with optional flag reflex::convert_flag::unicode to make .
(dot), \w, \s and so on match Unicode and to convert \p Unicode character
classes.
Conversion is fast (it runs in linear time in the size of the regex), but it is
not without some overhead. Making converted regex patterns static as shown
above saves the cost of conversion to just once to support many matchings.
Please see CONTRIBUTING.
Read more about RE/flex in the manual.
RE/flex by Robert van Engelen, Genivia Inc. Copyright (c) 2015-2019, All rights reserved.
RE/flex is distributed under the BSD-3 license LICENSE.txt. Use, modification, and distribution are subject to the BSD-3 license.
- Nov 14, 2016: 0.9.0 beta released
- Nov 15, 2016: 0.9.1 improved portability
- Nov 17, 2016: 0.9.2 improvements and fixes for minor issues
- Nov 19, 2016: 0.9.3 replaces
%importwith%include, adds freespace option-x, fixes minor issues - Nov 20, 2016: 0.9.4 fixes minor issues, added new examples/json.l
- Nov 25, 2016: 0.9.5 bug fixes and improvements
- Dec 1, 2016: 0.9.6 portability improvements
- Dec 6, 2016: 0.9.7 bug fixes, added option
--regexp-file, Python tokenizer - Dec 9, 2016: 0.9.8 fixes minor issues, improved reflex tool options
--fulland--fast, generates scanner with FSM table or a fast scanner with FSM code, respectively - Jan 8, 2017: 0.9.9 bug fixes and improved Flex compatibility
- Jan 15, 2017: 0.9.10 improved compatibility with Flex options, fixed critical issue with range unions
- Jan 25, 2017: 0.9.11 added C++11 std::regex matching engine support, moved .h files to include/reflex, requires
#include <reflex/xyz.h>from now on, fixederrno_tportability issue - Mar 3, 2017: 0.9.12 refactored and improved, includes new regex converters for regex engines that lack regex features such as Unicode character classes
- Mar 4, 2017: 0.9.13 improved warning and error messages
- Mar 6, 2017: 0.9.14 reflex option -v shows stats with execution timings, bug fixes
- Mar 8, 2017: 0.9.15 added
wtext(),wpair(),winput()methods, other improvements - Mar 22, 2017: 0.9.16 bug fixes, speed improvements, improved option
--unicoderegex conversion, also with(?u:), changedwtext()towstr()and added astr()method - Mar 24, 2017: 0.9.17 improvements
- Mar 26, 2017: 0.9.18 added reflex option
-p(--perf-report) for performance debugging, added doc/man/reflex.1 man page, added interactive readline example - Mar 31, 2017: 0.9.19 fixed reflex option
-m,lexer.in(i)now resets the lexer, fixed reassigning the same input to the lexer that caused UTF BOM to be read twice - Apr 5, 2017: 0.9.20 EBCDIC file translation, other improvements
- Apr 10, 2017: 0.9.21 fixed option
-Pto support multiple lexer classes in one application, addedconfigureinstallation script, optional quick install withallinstall.sh(renamed frominstall.sh) - Apr 12, 2017: 0.9.22 improved explanations of
matches(),find(),scan(),split()that return nonzero for a match, other minor improvements - May 24, 2017: 0.9.23 improved portability, added file encoding conversions for CP-1250 to CP-1258, CP 437, and CP 850/858
- Jun 24, 2017: 0.9.24 added an option for users to define their own custom code pages to translate input, fixed
#in free space mode - Jun 28, 2017: 0.9.25 fixed
--fastFSM not always halting on EOF after a mismatch; fixed buffer realloc, added new examples/csv.l - Jul 5, 2017: 0.9.26 fixed
wstr()always returning UTF-16 strings (should be UTF-16 only whenstd::wstringrequires it) - Sep 26, 2017: 0.9.27 the Flex-compatible
yy_scan_string(),yy_scan_bytes()andyy_scan_buffer()functions now create a new buffer as in Flex, delete this buffer withyy_delete_buffer(); fixed examples to work with newer Bison versions (Bison 3.0.4) - Dec 12, 2017: 0.9.28 added
yy_scan_wstringandyy_scan_wbufferfor wide string scanning with Flex-like functions - Jan 28, 2018: 1.0.0 removed dynamic exception specifications to comply with C++17, upgraded to stable release 1.0
- Feb 24, 2018: 1.0.1 added Unicode IsBlockName categories
- Mar 6, 2018: 1.0.2 added namespace nesting with
%option namespace=NAME1.NAME2.NAME3 ... - Mar 7, 2018: 1.0.3 fixed
--namespaceand%option namespace - Apr 22, 2018: 1.0.4 updated to Unicode 10, cleaned up code to remove tool warnings
- Jun 29, 2018: 1.0.5 updated
--namespacefor options--fastand--fullto support the generation of multiple optimized lexers placed in namespaces. - Jul 9, 2018: 1.0.6 added
--bison-ccoption to generate scanners for Bison 3.0%skeleton "lalr1.cc"C++ parsers, included two examplesflexexample9xxandreflexexample9xxto demo this feature. - Jul 12, 2018: 1.0.7 added
--bison-cc-namespaceand--bison-cc-parseroptions to customize Bison 3.0%skeleton "lalr1.cc"C++ parsers. - Jul 30, 2018: 1.0.8 updated to Unicode 11.
- Aug 21, 2018: 1.0.9 fixed reflex regex library matching with range quantifiers by correcting coding typo.
- Dec 8, 2018: 1.0.10 fixed
columno()to take tab spacing into account. - Jan 18, 2019: 1.0.11 fixed GCC 8.2 warnings, additional enhancements.
- Jan 21, 2019: 1.0.12 the reflex tool now reads files using
reflex::Input. - Feb 20, 2019: 1.1.0 code quality updates.
- Mar 6, 2019: 1.1.1 fixed
configureandmake installheader files, updated--bison-locationsoption. - Mar 7, 2019: 1.1.2 fixed reflex tool handling of backslashes in file paths.
- Mar 11, 2019: 1.1.3 updated to Unicode 12, examples can now be built with
./configure --enable-examples. - Mar 27, 2019: 1.1.4 fixed reflex tool common top code block insertion for all inclusive states.