12306 铁路购票服务是与大家生活和出行相关的关键系统,包括会员、购票、订单、支付和网关等服务。
这个项目旨在让学习者可以快速掌握分布式系统设计的技巧,尤其适合对高并发、分布式感兴趣的同学学习。如果想深入理解和应用分布式系统的设计原则,这个项目将会是一个很好的学习资源。
12306 项目中包含了缓存、消息队列、分库分表、设计模式等代码,通过这些代码可以全面了解分布式系统的核心知识点。
为了方便大家学习,该系统提供了两种独立版本:
-
SpringBoot 聚合服务版本:适合测试和部署,可以直接启动
aggregation-service聚合服务和网关服务。 -
SpringCloud 微服务版本:适合学习微服务设计,可以分别启动支付、订单、用户、购票和网关服务。
根据自己的学习和使用需求,选择合适的版本启动即可。微服务版本侧重学习设计,聚合服务版本侧重测试和部署。请根据场景需要,选择正确的版本进行学习和使用。

在系统设计中,采用最新 JDK17 + SpringBoot3&SpringCloud 微服务架构,构建高并发、大数据量下仍然能提供高效可靠的 12306 购票服务。
通过学习 12306 项目,不仅能了解其运作机制,还能接触最新技术体系带来的新特性,从而拓展技术视野并提升自身技术水平。
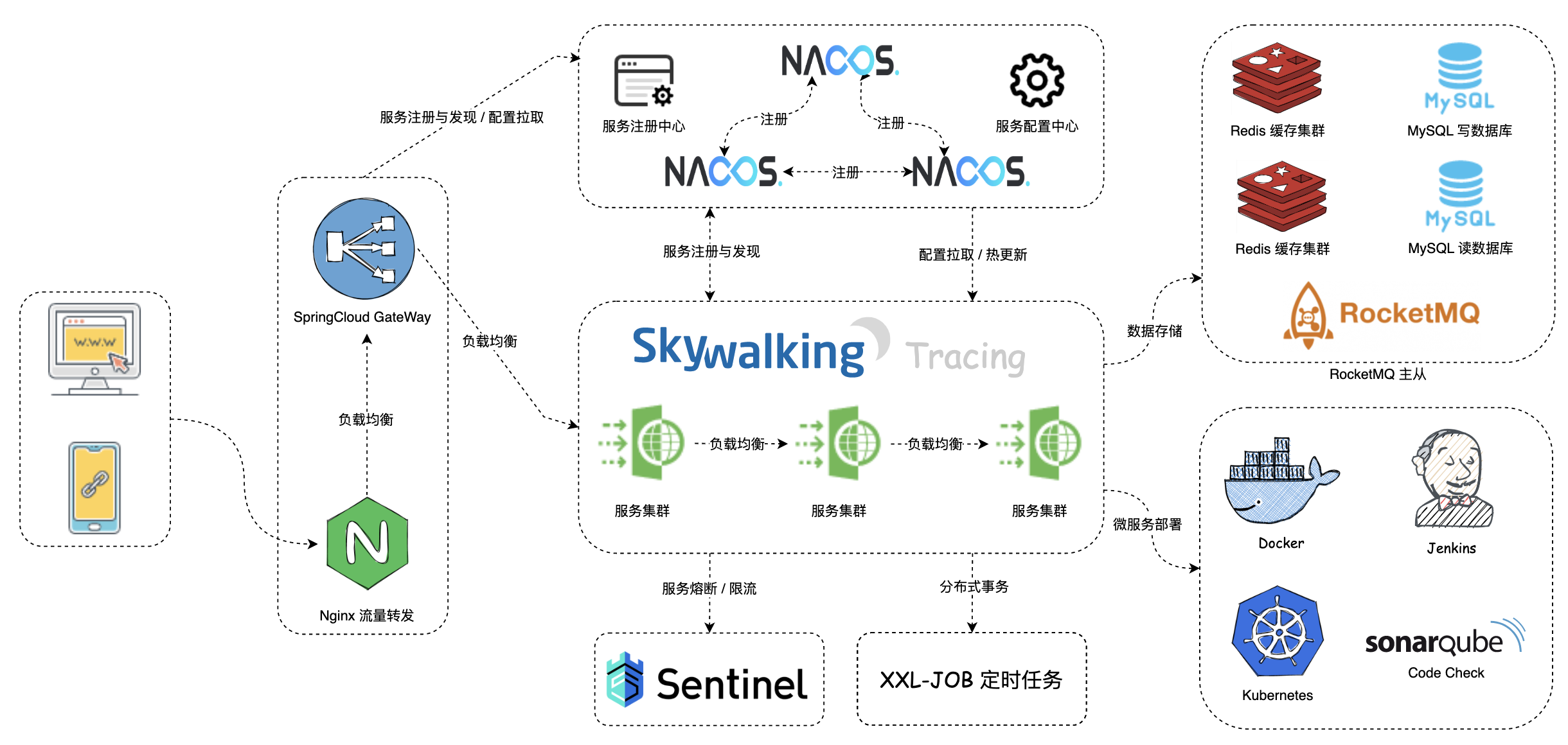
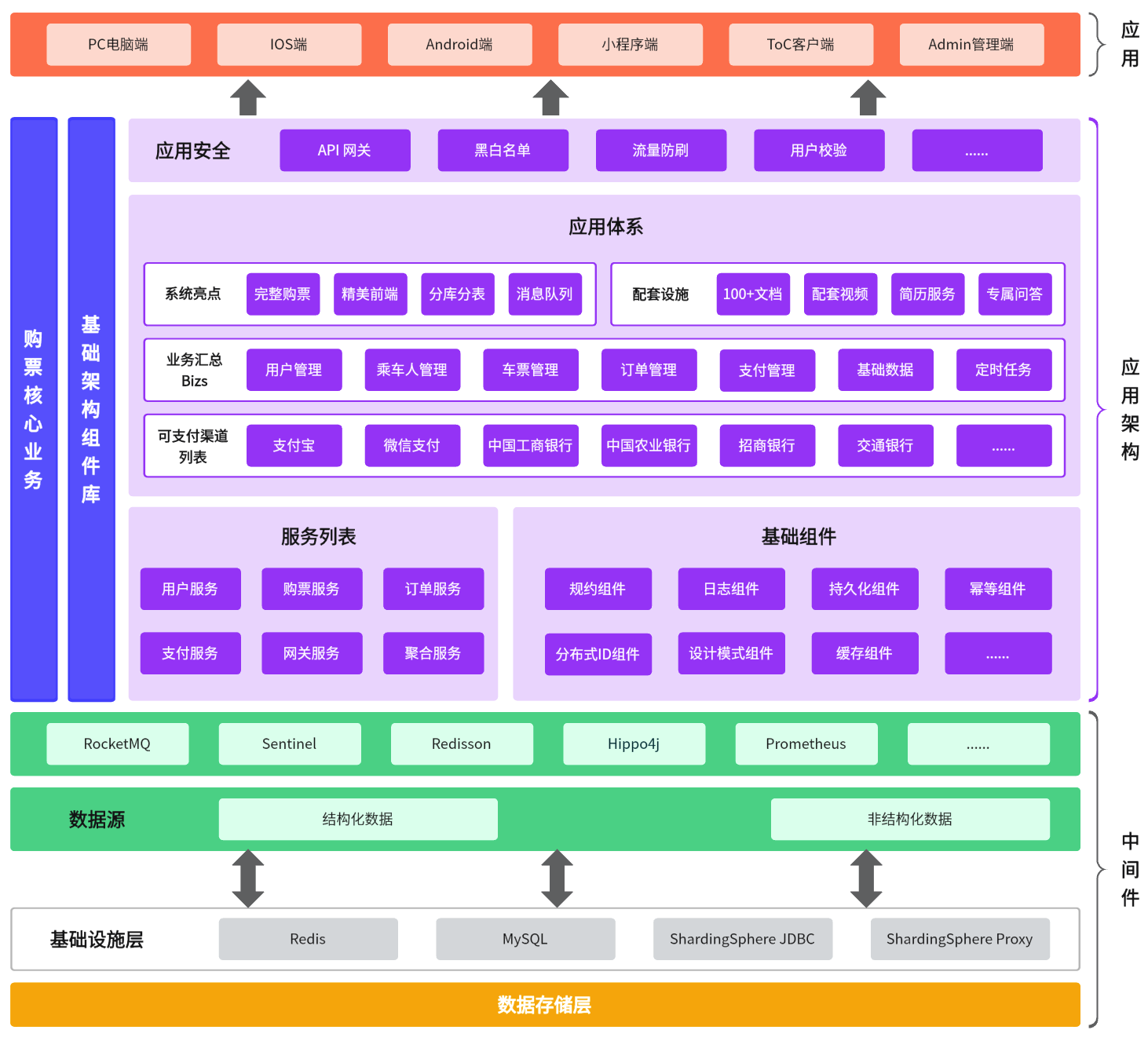
下方的架构图全面描述了项目的服务集合、组件库列表和基础设置层等要素,有助于用户快速了解 12306 平台的顶层设计和业务细节,从零到一进行构建。
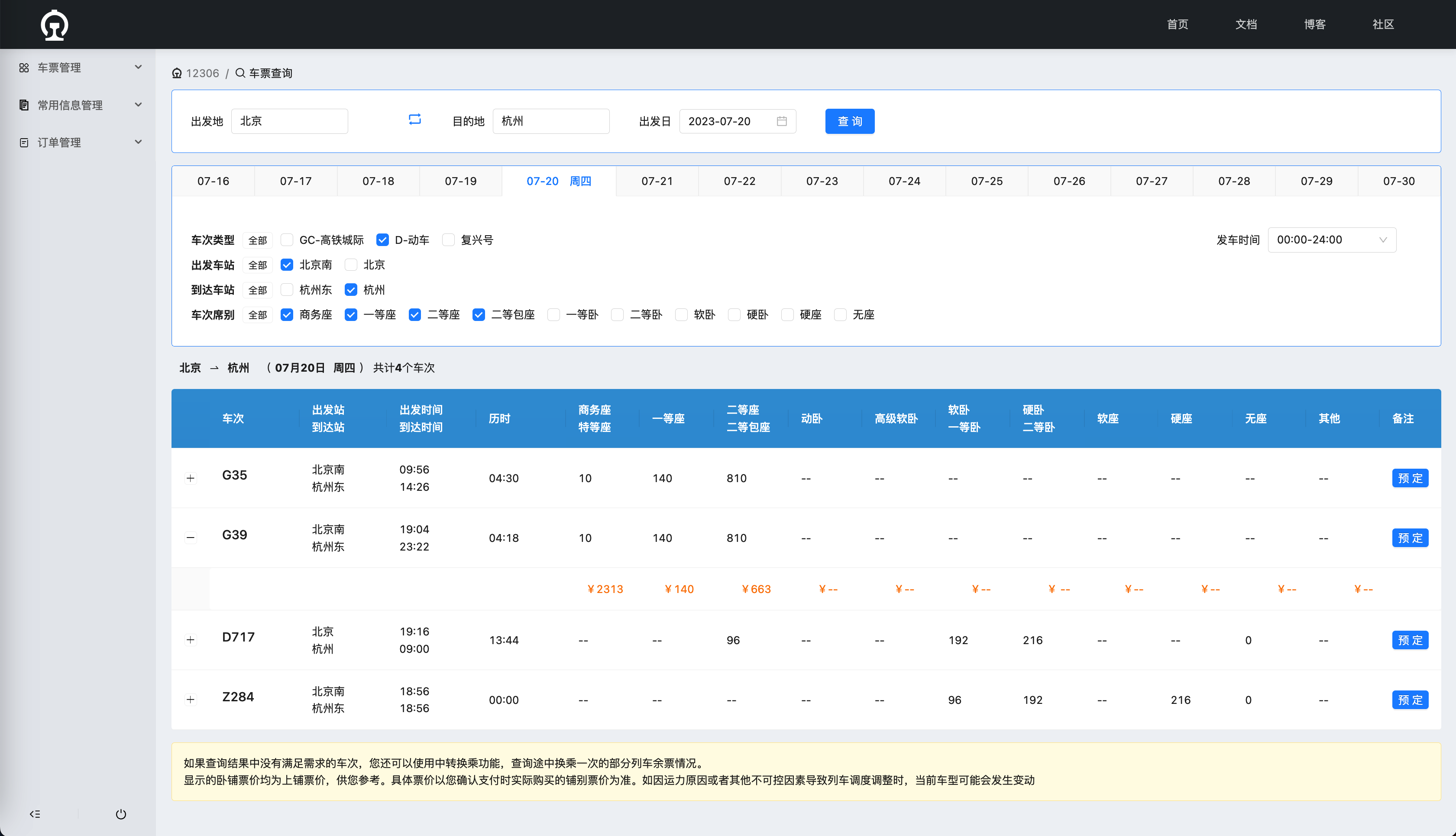
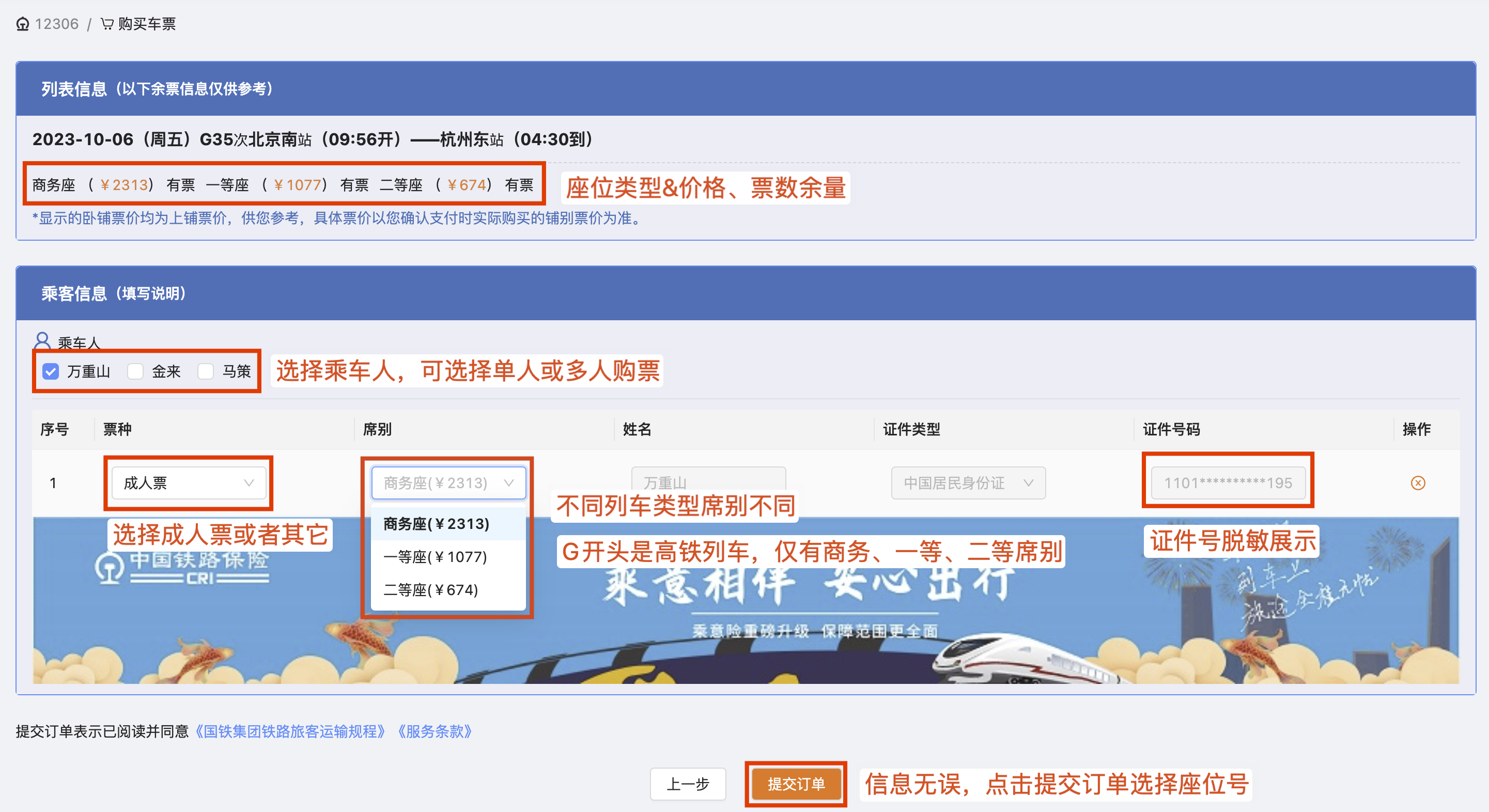
12306 前端系统实现了与官网极为接近的业务逻辑和 UI 展示。
在学习过程中,通过类似官网的前端系统直接调试后端服务,可以避免纯通过接口测试的繁琐。这种真实场景的模拟,使得学习过程更加流畅高效。
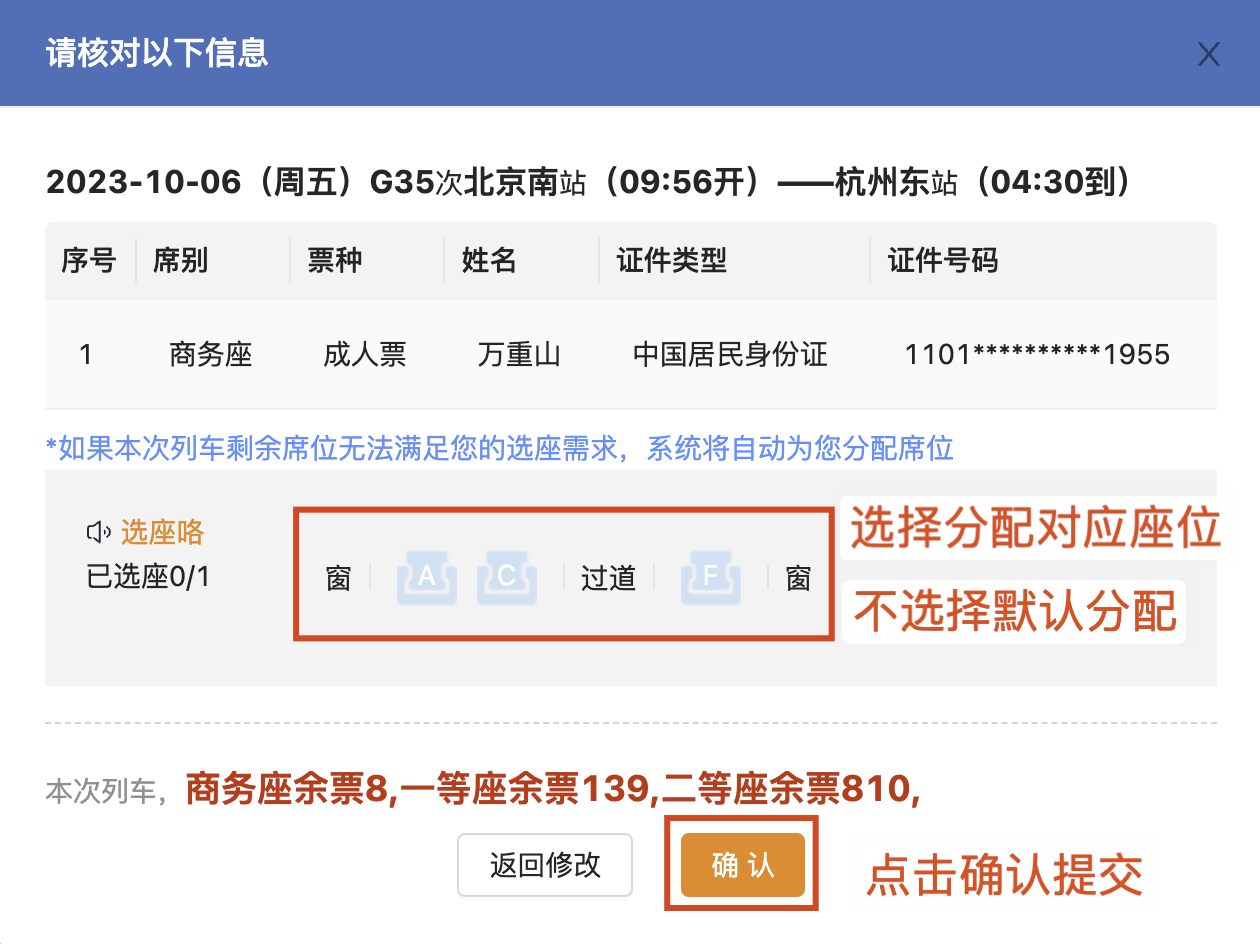
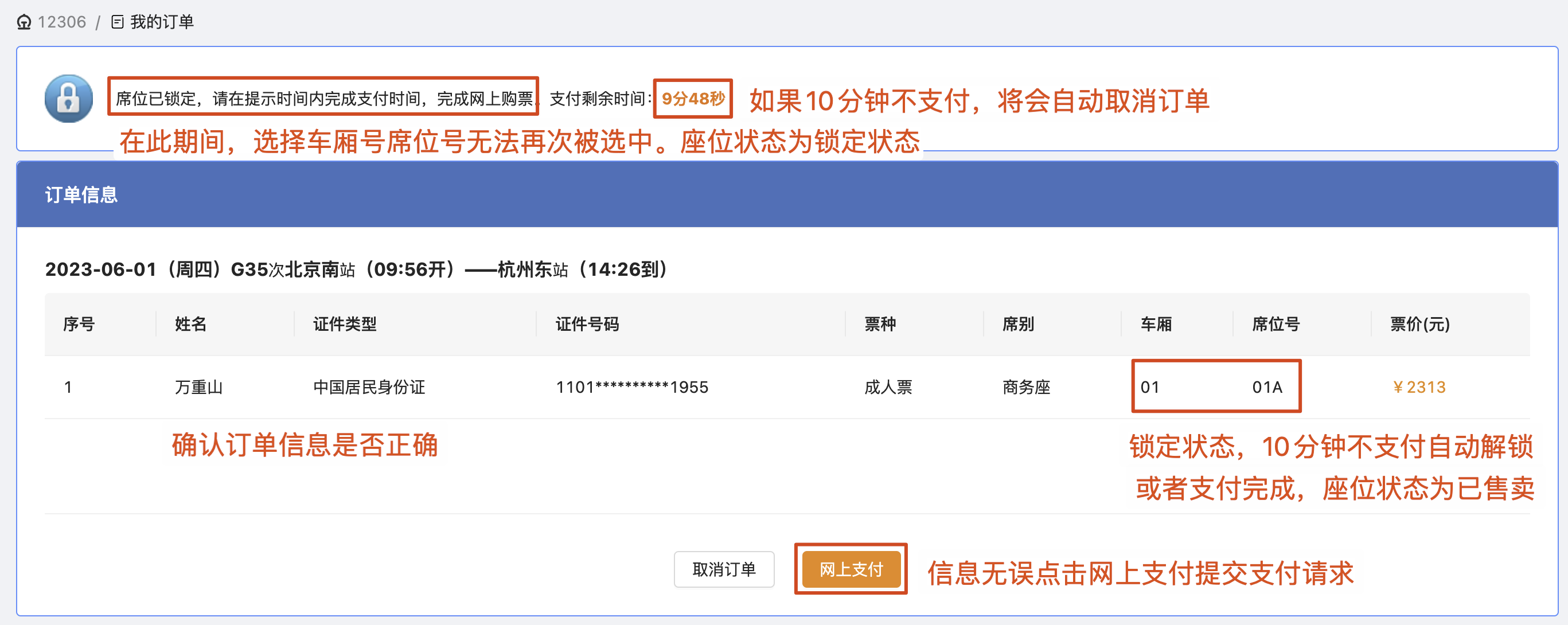
说些大家对于 12306 购票时没有考虑到的一些业务点,或者存在误区的地方。
背景:假设,有一站列车,途径北京南、济南西、南京南、杭州东、宁波。
查询站点对应的列车车次信息。
- 你以为:通过搜索引擎技术 ElasticSearch 技术解决,因为涉及大量的查询条件。比如:车次、车组、出发车站、到达车站、出发时间等。
- 实际上 :当海量并发查询时,ElasticSearch 的并发能力以及资源占用情况来说,并不适用。而且,大家如果仔细思考,发现这些查询条件都是可以通过类似于 Redis 的缓存技术存储,并在内存中进行组装。
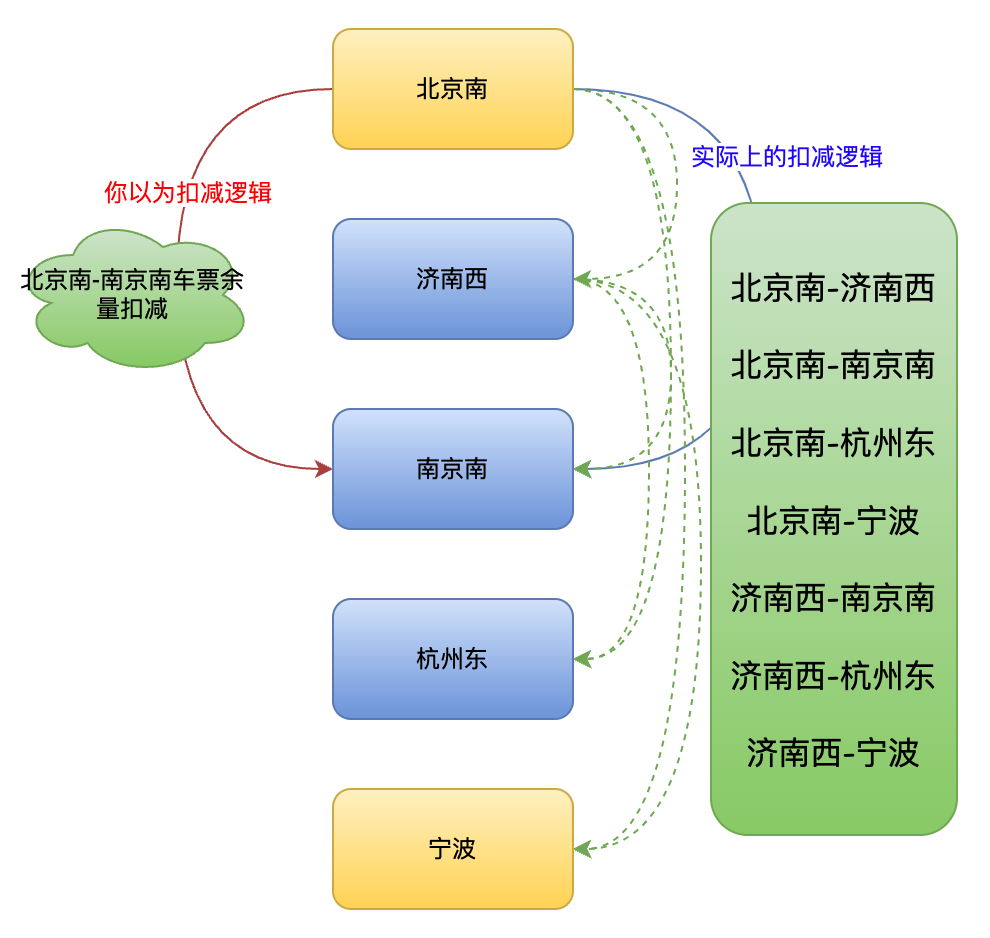
买一张北京南到南京南的车票。
- 你以为:只扣减北京南到南京南单趟的票。
- 实际上:会扣减北京南-济南西,北京南-南京南,济南西-南京南的三趟车票。如果其中有任意条件不满足都不会购买成功。
买一张济南西到南京南的车票。
- 你以为:按照上述逻辑,如果通过软件恶意刷票,只买济南西-南京南的票,北京南-杭州东是否就买不到了?
- 实际上:每个站数之间的数量都有规则。虽然放票时间都是一致的,但是优先大站之间的票量,避免因为大量用户购买了中间站的车票导致始发站和终点站的购票困难。该问题通过动态放票解决,比如刚开始放票时对小站之间仅开放少量票,大站之间放出来多数票。如果后续接近发车时间,再开放小站间的车票。
当然,业务以及技术上的难点和亮点并不止于这些,更多的信息可以通过代码以及 12306 的使用上进行发掘。
https://zzzyss.top/project/12306/service/%E7%94%A8%E6%88%B7%E6%9C%8D%E5%8A%A1.html

DO,DTO,PO 事务管理 ACID
根据给定的用户名获取与之关联的乘客列表,首先尝试从缓存中检索数据,如果没有缓存则从数据库中获取。 我们需要通过缓存来防止请求直接打到数据库。封装的缓存组件 safeGet 的作用就是,如果缓存中有,那么就从缓存中返回。如果缓存中没有,就查询数据库,并将查询数据库的结果,同步到缓存。
步骤同上
- 开启事务:为了保证操作的完整性和一致性。
- 获取当前用户:从 ThreadLocal 获取执行操作的用户名称。
- 数据转换和设置:将请求参数转换为数据库对象,并设置相关信息(如用户名、创建日期、审核状态)。
- 插入数据到数据库:将乘客信息插入数据库,并在失败时抛出异常。
- 异常处理和事务管理:如果操作过程中出现异常,则记录错误并回滚事务;否则,提交事务以保存更改。
- 删除用户缓存:操作成功后,删除相关用户的乘客信息缓存,确保数据一致性。
和新增乘车人方法相同。
和新增乘车人方法相同。
queryUserByUsername 方法通过用户名查询用户信息,并将结果转换为 UserQueryRespDTO 类型,如果用户不存在则抛出异常。
- 布隆过滤器检查:首先使用布隆过滤器判断用户名是否可能已存在。布隆过滤器是一个高效的数据结构,能快速检查元素是否存在于一个集合中,但它有一定的误判率。
- Redis验证:如果布隆过滤器指示用户名可能存在,方法进一步使用Redis进行确切的检查。这是因为布隆过滤器可能产生误判,而Redis可以提供准确的结果。 这种结合布隆过滤器和Redis的方法提高了效率同时确保了准确性。
- 使用责任链模式处理注册请求。
- 使用Redisson获取分布式锁,防止并发注册同一用户名。
- 尝试将用户信息插入数据库,处理可能的用户名、手机号、邮箱重复异常。
- 在成功注册后,从相关数据结构(Redis和布隆过滤器)中更新信息。
- 使用try-finally结构确保在操作结束后释放分布式锁。
- 返回用户注册的响应DTO。 此方法通过分布式锁和异常处理机制确保了用户注册过程的一致性和原子性,同时使用了布隆过滤器和Redis来管理用户名的唯一性和复用情况。
- 身份验证:login 方法首先判断用户是使用邮箱、手机号还是用户名登录,然后在相应的数据库表中查询以验证用户身份。
- 生成JWT令牌:身份验证通过后,方法生成一个JWT(JSON Web Token)令牌,用于后续的身份校验和访问控制。
- 存储用户信息和令牌:用户的基本信息和生成的JWT令牌存储到分布式缓存中,以便快速访问和维护用户会话。
- 返回登录响应:方法最后返回包含用户信息和JWT令牌的响应对象。
checkLogin 方法通过检查分布式缓存中与提供的JWT访问令牌相对应的数据来验证用户的登录状态。
logout 方法在访问令牌非空时,删除分布式缓存中对应的条目以实现用户登出。
- 验证用户名匹配:检查请求中提供的用户名是否与当前登录的用户名一致。
- 使用分布式锁:通过获取一个分布式锁来确保对用户数据的操作是原子性的,防止并发问题。
- 查询用户信息:根据用户名查询用户的详细信息。
- 插入用户删除记录:在用户删除记录表中插入一条新记录,记录用户的删除操作。
- 更新用户信息表:更新用户表中的相关信息,如设置用户的删除时间。
- 清除登录缓存:从分布式缓存中删除用户的登录状态信息,实现用户的登出。
- 处理用户名复用:将已删除的用户名标记为可复用,以便将来可能重新使用。
- 释放分布式锁:操作完成后释放之前获取的分布式锁。
- 事务管理:整个操作过程在一个事务中进行,以确保数据的一致性和完整性。