This is an official implementation of the Sophia-G optimizer in the paper https://arxiv.org/abs/2305.14342 and GPT-2 training scripts. The code is based on nanoGPT. Please cite the paper and star this repo if you find Sophia useful. Thanks!
@article{liu2023sophia,
title={Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training},
author={Liu, Hong and Li, Zhiyuan and Hall, David and Liang, Percy and Ma, Tengyu},
journal={arXiv preprint arXiv:2305.14342},
year={2023}
}-
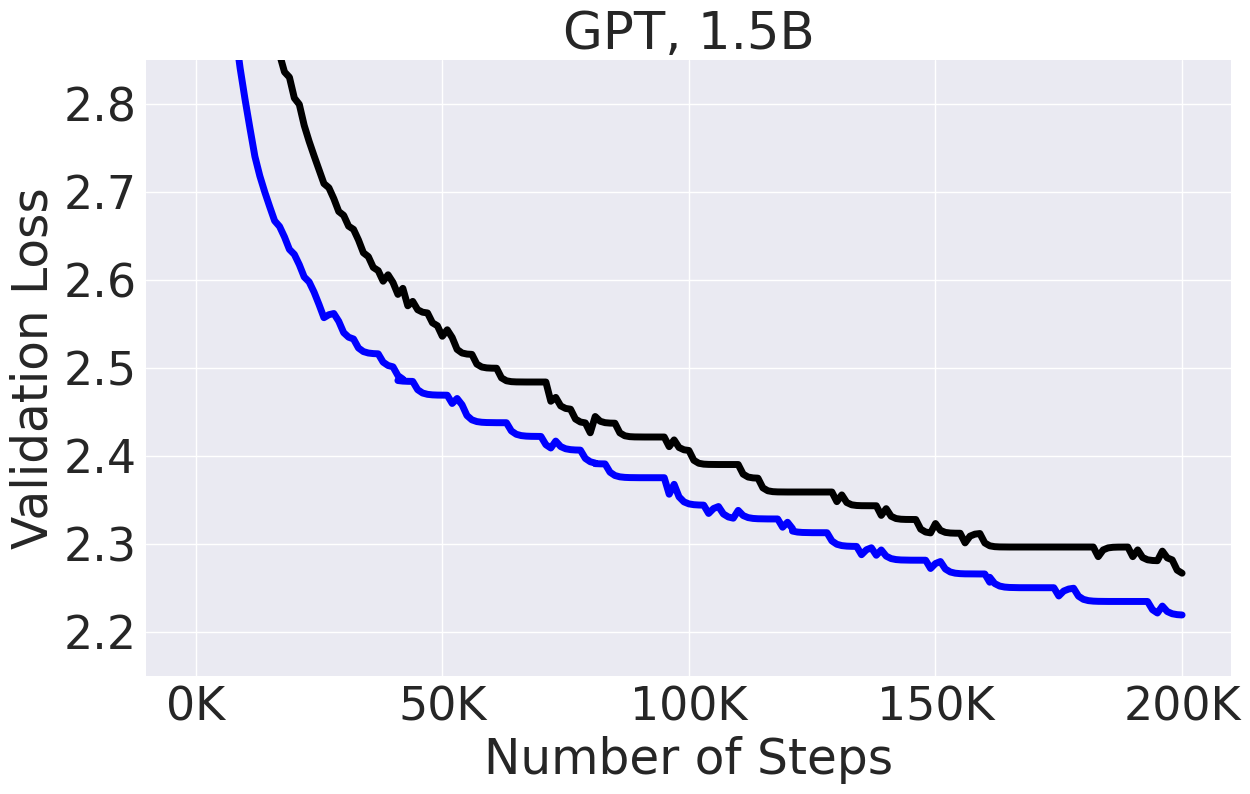
🔥 🔥 Training script and results released for GPT2 1.5B.
-
🔥 Watch Sophia running on GPT2 Medium(355M) in the wandb report.
-
We will spend more resources on scaling up to larger models. Please feel free to let us know if you have any feedback or interesting findings from using Sophia.
-
For Large (770M), please see the hyperparameters we used to produce the results in the paper below in the hyperparameter tuning. The scripts will be released soon (potentially with an improved choice of hyperparameters that we are currently experimenting with.)

- pytorch 2.0
- transformers
- datasets
- tiktoken
- wandb
Prepare the OpenWebText data following nanoGPT:
$ python data/openwebtext/prepare.py
Start pre-training GPT2 Small (125M):
If you have a machine with 10 A5000 (24GB) GPUs,
$ torchrun --standalone --nproc_per_node=10 train_sophiag.py config/train_gpt2_small_sophiag.py --batch_size=8 --gradient_accumulation_steps=6
If you have a machine with 8 A100 (40GB) GPUs,
$ torchrun --standalone --nproc_per_node=8 train_sophiag.py config/train_gpt2_small_sophiag.py --batch_size=12 --gradient_accumulation_steps=5
To reproduce the AdamW baseline following nanoGPT:
$ torchrun --standalone --nproc_per_node=10 train_adam.py config/train_gpt2_small_adam.py --batch_size=8 --gradient_accumulation_steps=6
This will lead to results in the figure below:

Start pre-training GPT2 Medium (355M):
If you have a machine with 8 A100 (40GB) GPUs,
$ torchrun --standalone --nproc_per_node=8 train_sophiag.py config/train_gpt2_medium_sophiag.py --batch_size=6 --gradient_accumulation_steps=10
To reproduce the AdamW baseline:
$ torchrun --standalone --nproc_per_node=8 train_adam.py config/train_gpt2_medium_adam.py --batch_size=6 --gradient_accumulation_steps=10
Please adjust nproc_per_node, batch_size, and gradient_accumulation_steps accordingly if you use other hardware setup. Make sure their product equals 480.
This will lead to results in the figure below:

Start pre-training GPT2 1.5B:
We use the Pile and GPT NeoX tokenizer. First set up TPU instances and environment following levanter. Then change GAMMA_SOPHIA_G to 200 in optim.py. The training script for 1.5B model is
gcloud compute tpus tpu-vm ssh <instance_name> --zone <zone_name> --worker=all --command 'WANDB_API_KEY=<wandb_api_key> levanter/infra/launch.sh python levanter/examples/gpt2_example.py --config_path levanter/config/gpt2_1536_pile.yaml --trainer.beta1 0.965 --trainer.beta2 0.99 --trainer.min_lr_ratio 0.020 --trainer.weight_decay 0.15 --trainer.learning_rate 2.5e-4 --trainer.warmup_ratio 0.01'
Suggested Improvement: The following code snippet provides an improved version for updating the Hessian in the "General Usage" section. This code has been tested and verified to work correctly, offering a more reliable experience for users testing the SophiaG model.
# Proposed improved code for updating Hessian
import torch
import torch.nn.functional as F
from sophia import SophiaG
# init model loss function and input data
model = Model()
data_loader = ...
# init the optimizer
optimizer = SophiaG(model.parameters(), lr=2e-4, betas=(0.965, 0.99), rho=0.01, weight_decay=1e-1)
total_bs = len(data_loader)
bs = total_bs * block_size
k = 10
iter_num = -1
# training loop
for epoch in range(epochs):
for X, Y in data_loader:
# standard training code
logits, loss = model(X, Y)
loss.backward()
optimizer.step(bs=bs)
optimizer.zero_grad(set_to_none=True)
iter_num += 1
if iter_num % k != k - 1:
continue
else:
# update hessian EMA
logits, _ = model(X, None)
samp_dist = torch.distributions.Categorical(logits=logits)
y_sample = samp_dist.sample()
loss_sampled = F.cross_entropy(logits.view(-1, logits.size(-1)), y_sample.view(-1), ignore_index=-1)
loss_sampled.backward()
optimizer.update_hessian()
optimizer.zero_grad(set_to_none=True)
model.zero_grad()Steps to Reproduce:
- Download the "sophia.py" file from the SophiaG repository.
- Place the downloaded "sophia.py" file in the same folder as your code.
- Import the SophiaG class from "sophia.py" and utilize it as a template, as provided in the suggested code snippet.
Expected Behavior: Upon updating the Hessian using the suggested improved code, the SophiaG model should function as expected for general use cases, and users should be able to utilize the sophia.py file to test the model seamlessly.
Additional Information: Updating the "General Usage" code with the proposed improvement will enhance the usability of the SophiaG repository for the PyTorch community. This will ensure a smooth experience for users who want to explore and experiment with the SophiaG optimizer.
Please let me know if you require any further information or assistance in resolving this issue.
Note: Before merging the changes, it is advisable to have other developers review the code and conduct additional testing to validate its correctness and efficacy.
Definition of learning rate
- The update in the code is written as
$\theta_{t+1} = \theta_t - lr*\textup{clip}(m_t / (\rho * h_t + \epsilon), 1)$ , which is equivalent to the update in the paper up to a re-parameterization. (the$lr$ here corresponds to$\rho \cdot \eta_t$ in the paper).
Some tips for tuning hyperparameters (based on our limited tuning):
-
Choose lr to be about the same as the learning rate that you would use for AdamW. Some partial ongoing results indicate that lr can be made even larger, possibly leading to a faster convergence.
-
Consider choosing
$\rho$ in$[0.01, 0.1]$ .$\rho$ seems transferable across different model sizes. We choose rho = 0.03 in 125M Sophia-G. The (lr, rho) for 355M, Sophia-G is chosen to be (5e-4,0.05) (more aggressive and therefore, even faster! 🚀 🚀). Slightly increasing weight decay to 0.2 seems also helpful. -
Please feel free to let us know what you find out during hyper-parameters tuning. We appreciate your valuable feedback and comments!
The GPT-2 training code is based on nanoGPT, which is elegant and super efficient.