| title | date | tags | |||
|---|---|---|---|---|---|
python处理word文档案例-列出修订点 |
2019-10-30 05:18:56 -0700 |
|
最近一个“大法师”朋友找到了我,问我能不能帮他做一个小程序,需要将word文档中的修订内容(如下图1)都统一做成如下形式,生成修订表(如图2)。
图1 原文件
图2 生成的修订表

因为本人是典型的java程序员,也会一点点python。在网上找到的资源,只有一个修订方式是批注的解决方法,不包含其他的修改类型(比如:新增,删除,移动,格式)。 目前网上找到的解决方案有如下几种: 1.通过VB或者宏程序处理; 2.通过解析word的xml去处理。 第一种方式是最简单的,但是因为对这方面不太熟悉,而朋友又急着要,因此这个方案先抛弃了。 下面着重讲解通过解析word的xml来实现这个效果的思路。
1.将原文docx文档,通过更改后缀为zip,将里面的xml文件拿出来。(主要用到的是document.xml,styles.xml)
2.准备好开发环境:python3,以及几个主要的依赖:BeautifulSoup,docx。
这里我们需要提取的修订内容主要是新增的内容,以及删除的内容。
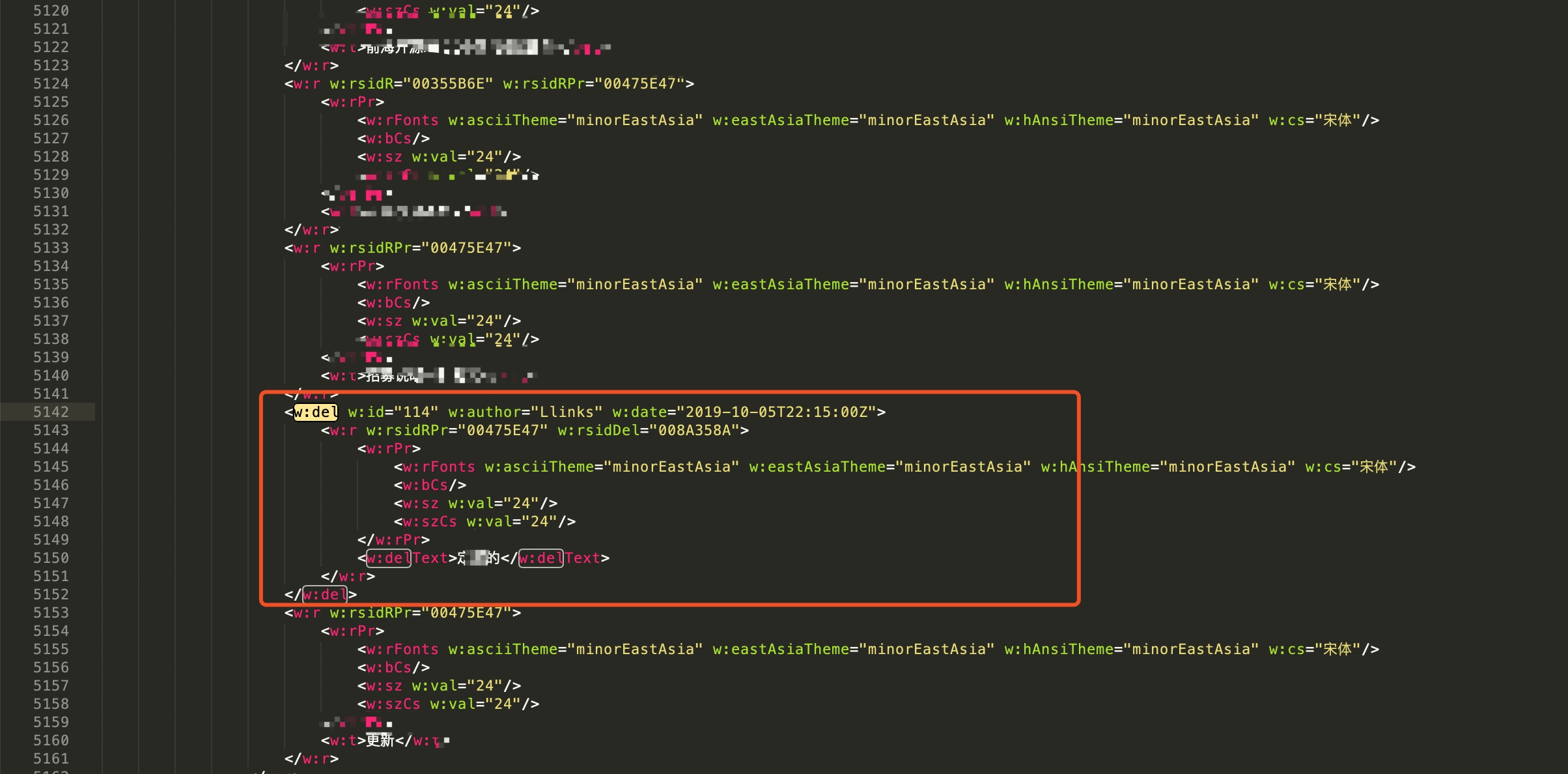
1.在原文中找到一个删除的内容,在xml里查找。可以看到在如下图所示位置可以找到,属于‘w:del’标签。
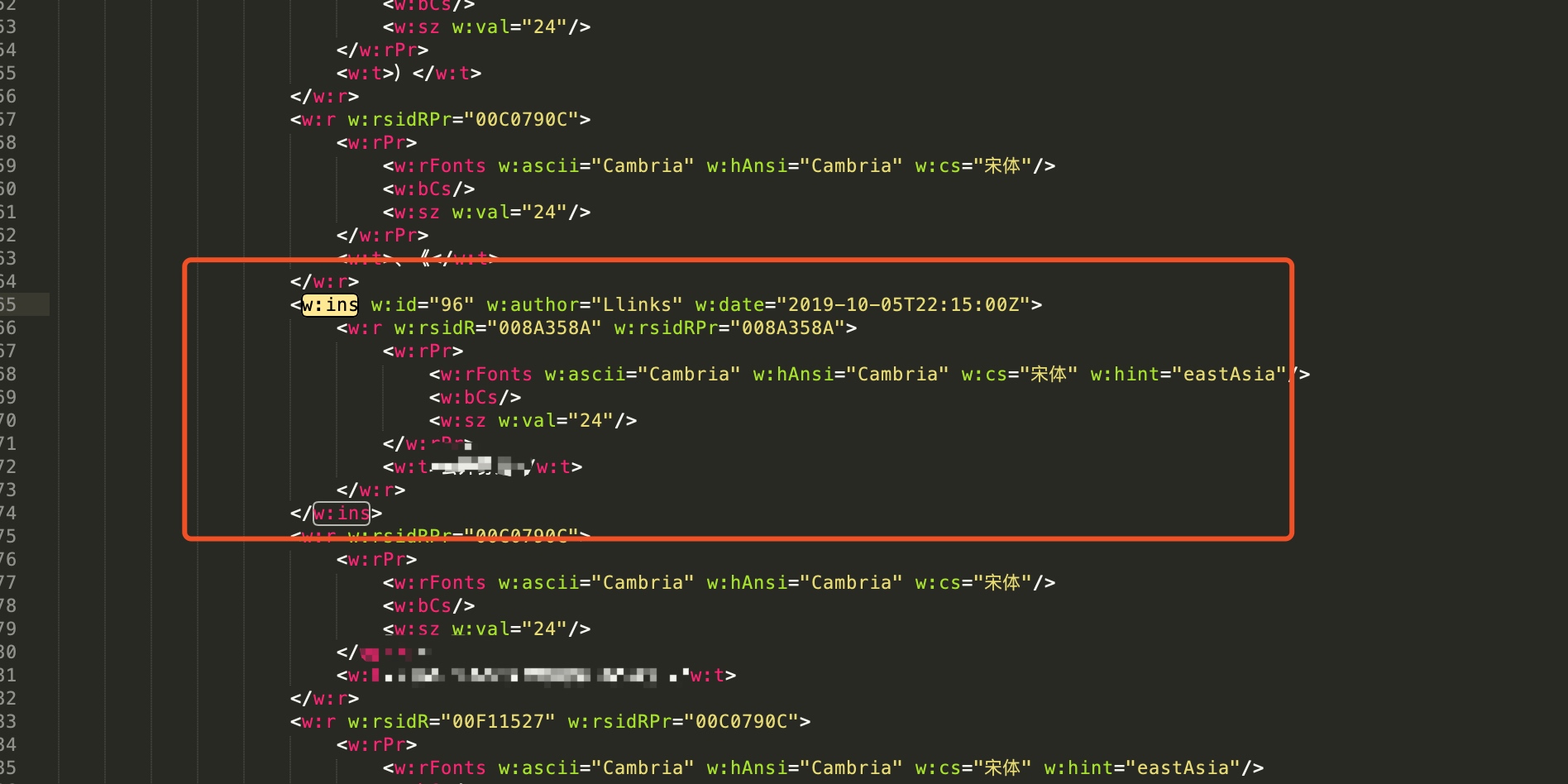
2.同理。新增内容也找到,属于‘w:ins’标签。
3.这样,在我们的代码中,只要查找这两个标签的内容就可以找到对应的修订记录里。但是这样还不够,我们最终的效果是要原文和修改后的内容进行对比。这里的解决思路是这样的:提取每一段文字,将文字中标记为新增的内容删掉,就是原文;将文字中标记为删掉的内容去掉,就是修订后的内容。源码如下。
# 原文内容:删掉添加的
oldcontents = oldpar.find_all("w:ins")
# 修订版内容:去掉删除的
newcontents = newpar.find_all("w:del")
for oldcontent in oldcontents:
oldcontent.extract()
for newcontent in newcontents:
newcontent.extract()
章节内容需要放在表格的第一列,并且同一章节的修订内容应该归纳在同一个章节里。
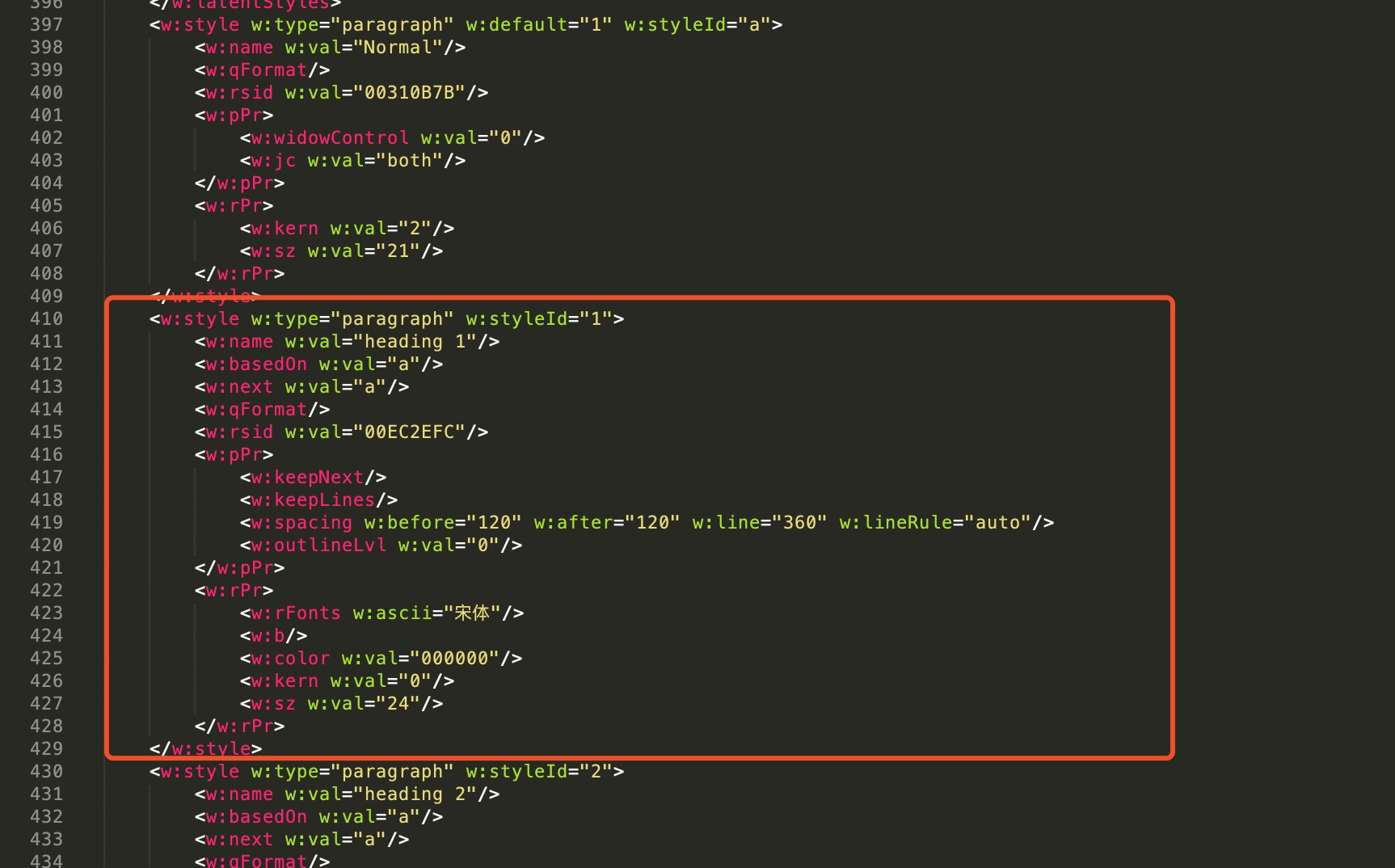
1.在我们这里,文档中的章节内容一般都是标题1文字,这里找到styles.xml,里面有标题1的定义样式。如下图所示,我们找到‘heading 1’的定义,styleid是1.
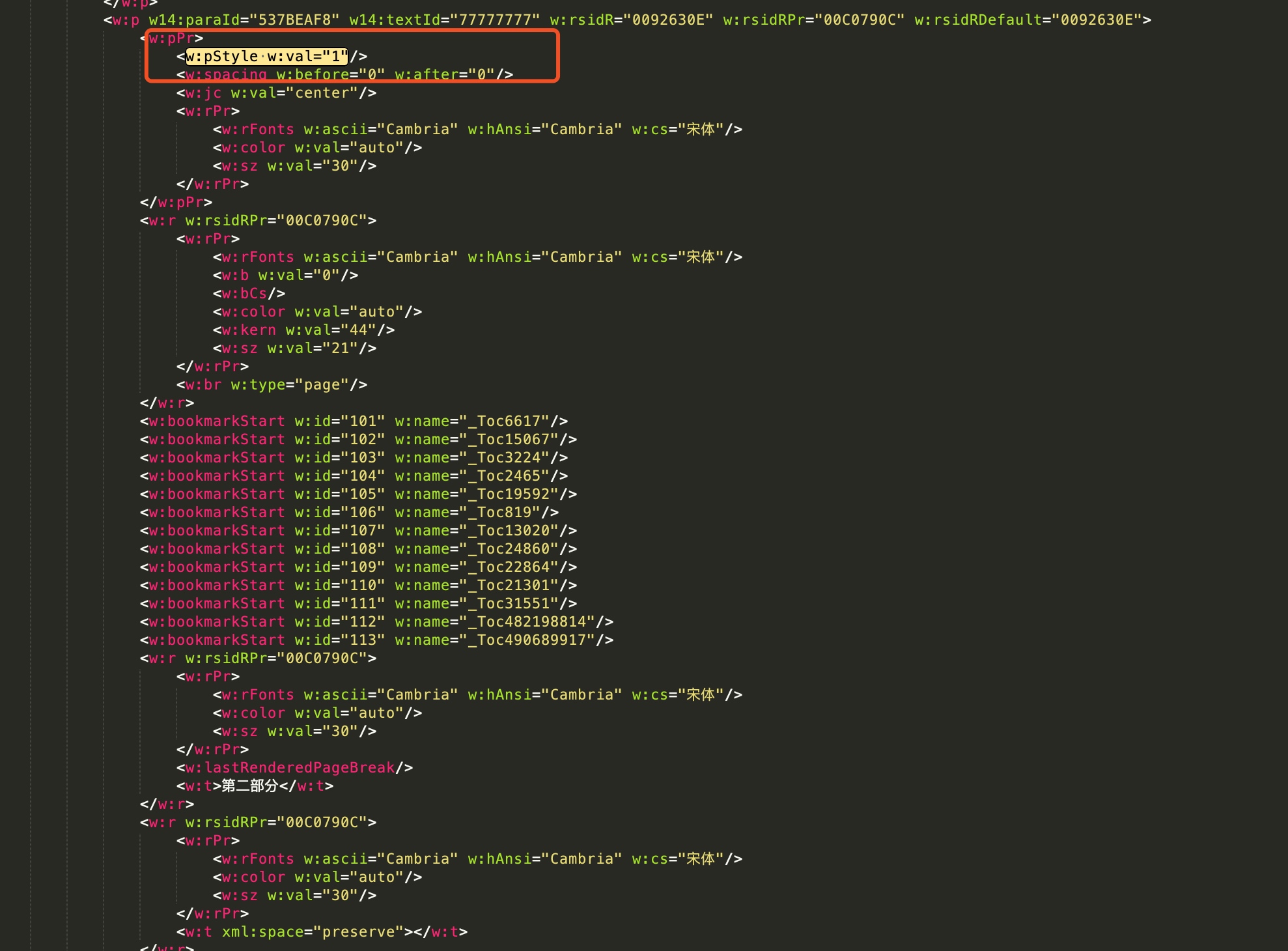
2.在document.xml里找到对应的‘w:pStyle’标签,并且 ‘w:val’属性为1。
3.具体解析方式,如下源码。
# 查找前面第一个标题
wpparas = para.find_all_previous('w:p');
if len(wpparas)>0:
haschapter = False
for index in range(len(wpparas)):
wppara = wpparas[index]
p = wppara.find('w:pstyle',attrs={'w:val' : headingstyleid})
if p is not None :
if wppara.get_text() is not None and charpter !='' and charpter != wppara.get_text():
# 合并单元格
table.cell(charpterstartindex, 0).merge(table.cell(len(table.rows)-1, 0)).text = charpter
charpterstartindex = len(table.rows)
charpter = wppara.get_text();
haschapter = True
break
if index == (len(wpparas)-1) and not haschapter:
charpterstartindex += 1
其他更详细的源码参见:我的github