forked from SocialComplexityLab/socialgraphs2021
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
6e27d83
commit f1cd430
Showing
1 changed file
with
131 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,131 @@ | ||
| { | ||
| "cells": [ | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Formalia:\n", | ||
| "\n", | ||
| "Please read the [assignment overview page](https://github.com/SocialComplexityLab/socialgraphs2021/wiki/Assignments) carefully before proceeding. This page contains information about formatting (including formats etc.), group sizes, and many other aspects of handing in the assignment. \n", | ||
| "\n", | ||
| "_If you fail to follow these simple instructions, it will negatively impact your grade!_\n", | ||
| "\n", | ||
| "**Due date and time**: The assignment is due on Tuesday September 28th, 2021 at 23:59. Hand in your IPython notebook file (with extension `.ipynb`) via http://peergrade.io/\n", | ||
| "\n", | ||
| "(If you haven't set up an account on peergrade yet, go to www.peergrade.io/join and type in the class code: BUKAYJ.)" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Part 1: Binning degree distributions\n", | ||
| "\n", | ||
| "\n", | ||
| "* Binning real numbers\n", | ||
| " * Let's do a gentle start and use the `random` library to generate 5000 data points from a Gaussian distribution with $\\mu = 2$ and $\\sigma = 0.125$.\n", | ||
| " * Now, let's use `numpy.histogram` to bin those number into 10 bins. What does the `numpy.histogram` function return? Do the two arrays have the same length?\n", | ||
| " * Then we use `matplotlib.pyplot.plot` to plot the binned data. You will have to deal with the fact that the counts- and bin-arrays have different lengths. Explain how you deal with this problem and why.\n", | ||
| "* Binning integers\n", | ||
| " * But binning real numbers into a fixed number of bins is easy when `numpy.histogram` does all the work and finds the right bin boundaries for you. \n", | ||
| "Now we'll generate a bunch of integers and set the bin boundaries manually. This time, let's grab data from a Poisson distribution. As it turns out `numpy` also has some convenient random number generators. Use `numpy.random.poisson` to generate 5000 numbers drawn from a Poisson distribution characterized by $\\lambda = 10$. Find the maximum and minimum value of your 5000 random numbers. \n", | ||
| " * Instead of simplify specifying the number of bins for `numpy.histogram`, let's specify the bins we want using a vector. Create a vector $v$ that results in a binning that puts each integer value in its own bin and where the first bin contains the minimum number you found above, and the last bin contains the maximum number (you may want to think about how `numpy.histogram` deals with the smallest an largest value in particular; is it correct to set the first entry of $v$ to be equal to the smallest value you observe and the last entry of $v$ to be the highest value observed?). Use the vector by setting `numpy.histogram`'s `bin` parameter as `bin = ` $v$. What is the sum over bin counts? Explain how the binning-vectors first and last element relates to the min and max from the Poisson distribution.\n", | ||
| " * Now, use a bar chart (`matplotlib.pyplot.bar`) to plot the distribution \n", | ||
| "* Binning and plotting degree distributions. \n", | ||
| " * Let's generate the Erdös-Renyi (ER) network which has a degree distribution that matches the Poisson distribution above. \n", | ||
| "First we have to figure out which values the ER parameters (_N_ and _p_) should assume. It's easy to see that $N = 5000$, but how do you find $p$? \n", | ||
| "**Hint**: The parameter $\\lambda$ in the Poisson distribution corresponds to the average degree, so you have to find a $p$ that results in an average degree, $k = 10$. And you know that $\\langle k \\rangle = p (N-1)$, which will give you $p$.\n", | ||
| " * Now, use `networkx` to create the graph and extract the degree distribution.\n", | ||
| " * Finally, create a nice bar plot of the degree distribution, including axes labels and a plot title. Make sure that it looks like the Poisson distribution you plotted above." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Part 2: Random networks and plotting in `networkx`\n", | ||
| " \n", | ||
| "* In your notebook, work through NS exercise 3.1 ('Erdős-Rényi Networks'). The exercise can be found in Section 3.11: Homework.\n", | ||
| "* Paths. Plot a random network with 200 nodes and an average degree of 1.5\\. (I suggest using `networkx.draw` and reading [the documentation](https://networkx.github.io/documentation/stable/reference/drawing.html) carefully to get an overview of all the options and what they look like. For example, you may want to shrink the node size).\n", | ||
| " * Extract the Giant Connected Component, GCC. (Hint. You can use `networkx.connected_component_subgraphs`)\n", | ||
| " * Choose a node at random from the GCC. (Hint: You may want to try `random.choice`.)\n", | ||
| " * Find all nodes that are precisely 2 steps away from that node. (Hint. I suggest `networkx.single_source_shortest_path_length`)\n", | ||
| " * Plot the GCC with the following choice of colors. Starting node _black_ (`\"#000000\"`). The nodes 2 steps away _red_ (`\"#ff0000\"`). All other nodes _blue_ (`\"#A0CBE2\"`). Again, I suggest using `networkx.draw()` and reading [the documentation](https://networkx.github.io/documentation/stable/reference/drawing.html) carefully find out how to color individual nodes.\n", | ||
| "\n", | ||
| "By the way, the default plot coming out of `networkx` doesn't look like the one below. But by tweaking parameters, you should be able to create something that looks like it.\n", | ||
| "\n", | ||
| "" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Part 3: Watts-Strogatz Networks\n", | ||
| "\n", | ||
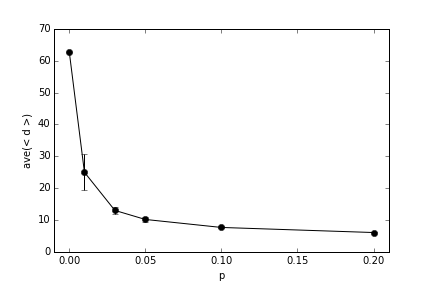
| "* Use `nx.watts_strogatz_graph` to generate 3 graphs with 500 nodes each, average degree = 4, and rewiring probablity $p = 0, 0.1, \\textrm{and} 1$. Calculate the average shortest path length $\\langle d \\rangle$ for each one. Describe what happens to the network when $p = 1$.\n", | ||
| "* Let's understand the behavior of the WS model as we increase _p_ in more detail. Generate 50 networks with $N = 500$, $\\langle k \\rangle = 4$, for each of $p = \\{0, 0.01, 0.03, 0.05, 0.1, 0.2\\}$. Calculate the average of $\\langle d \\rangle$ as well as the standard deviation over the 50 networks, to create a plot that shows how the path length decreases very quickly with only a little fraction of re-wiring. Use the standard deviation to add errorbars to the plot. My version of the plot is below (since a picture's worth 1000 words).\n", | ||
| "\n", | ||
| "\n", | ||
| "" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Part 4. The Barabasi-Albert Model\n", | ||
| "\n", | ||
| "We're going to create our own Barabasi-Albert model (a special case) in a `notebook`. Follow the recipe below for success\n", | ||
| "\n", | ||
| "* Create a 100 node BA network using a BA model that you've coded on your own (so don't use the built-in NetworkX function, but the one you created during week 3). And plot it using NetworkX.\n", | ||
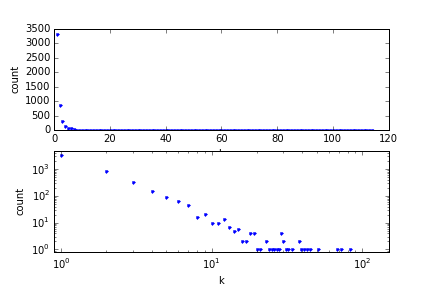
| "* Now create a 5000 node network.\n", | ||
| " * What's the maximum and minimum degree?\n", | ||
| " * Now, bin the degree distribution, for example using `numpy.histogram`.\n", | ||
| " * Plot the distribution. Plot it with both linear and log-log axes.\n", | ||
| "\n", | ||
| "" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Part 5 Power-laws and the friendship paradox\n", | ||
| "\n", | ||
| "Next step is to explore the [Friendship paradox](https://en.wikipedia.org/wiki/Friendship_paradox). This paradox states that _almost everyone_ have fewer friends than their friends have, on average. This sounds crazy, but is actually an almost trivial consequence of living in a social network with a power-law degree distribution. The explanation is that almost everyone is friends with a hub, that drives up the average degree of the friends. Let's explore that in the 5000 node BA network we've just generated. Do the following:\n", | ||
| "\n", | ||
| "* Pick a node _i_ at random (e.g. use `random.choice`). [Find its degree](http://networkx.lanl.gov/reference/generated/networkx.Graph.degree.html).\n", | ||
| "* Find _i_'s [neighbors](http://networkx.lanl.gov/reference/generated/networkx.Graph.neighbors.html). And calculate their average degree.\n", | ||
| "* Compare the two numbers to check if it's true that _i_'s friends (on average) have more friends than _i_.\n", | ||
| "* Do this 1000 times. How many out of those 1000 times is the friendship paradox true?\n", | ||
| "\n", | ||
| "Finally, we'll build a network of same size and degree, using the growth mechanism without the preferential attachment. \n", | ||
| "\n", | ||
| "* Compare to the ER network of same size and same $p$. What are the differences? Explain in your own words. *Hint*: To get started, take a look at the degree distribution, and study the number of connected components." | ||
| ] | ||
| } | ||
| ], | ||
| "metadata": { | ||
| "anaconda-cloud": {}, | ||
| "kernelspec": { | ||
| "display_name": "Python 3", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
| "language_info": { | ||
| "codemirror_mode": { | ||
| "name": "ipython", | ||
| "version": 3 | ||
| }, | ||
| "file_extension": ".py", | ||
| "mimetype": "text/x-python", | ||
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.7.7" | ||
| } | ||
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 1 | ||
| } |