
测试环境:
CPU: Intel Core i7-12700KF
GPU: NVIDIA RTX 3080TI
RAM: 32GB
注:Data文件并未上传。
布匹缺陷检测:https://github.com/Xande1r/Fabric-Defection-Detection
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR),主要面向自然场景,如下图中所示的牌匾等各种自然场景可见的文字。
文字识别的全流程包括:图像预处理,OCR识别,恢复版面,后处理。
OCR主要分为两部分:
- 文本检测, 即找出文本所在位置。
- 文本识别, 将文字区域进行识别。
在OCR技术中,有几种最常见的问题:透视变换、尺寸过小、文字扭曲、背景复杂、字体多样、语言混合、字体模糊、光照复杂。这些问题,在本次的轮胎OCR识别中都有着或多的体现。
在本次项目中,我个人使用的点云转换为图像的具体步骤如下:
-
原始数据提取高度数据
-
高度数据转化为高度图
-
裁切高度图
-
修复图像
-
展平图像
-
规格化
-
去噪
-
直方图均衡化
-
直方图裁切
原始数据是一个(X,Z,Y)格式的三维点云数据,但是根据扫描线的流程来看,可以只采用Z坐标,因为扫描线是逐行的。
图像中存在着本不该存在的点,因此需要去除这些点。采用滤波的方式填充、去除这些点。参考资料,可采用的方案有:
- 去零均值滤波:虽然会在一定程度上破坏图像的细节,但是有效的抑制噪声。而且实际检验,对于细节的丢失可以接受。
- 形态学运算:主要是腐蚀与膨胀。这一操作可以快速提取形态特征,但是效果并不如上面的滤波。
利用Open3D生成的点云观察可得,轮胎本省并不是平整的,而是一个曲面。这就需要展平图像。

本次采用的方法是:估计曲面的高度,然后用原本的点云减去估计的高度。估计高度的方法有:
-
扫描线均值估计:求出轮胎每一行的高度平均值,依次作为曲面的估计值。
-
均值估计:利用均值模糊的原理,消除高度差。
根据生成的高度图来看,扫描线均值估计的结果虽然更精确,但是因为轮胎本身不够平整,会产生块状伪影;而均值估计则是会出现条状伪影。因此决定将这两种方法结合使用。

对读入的数据进行样条插值网格化。这一步骤是可选的。经过测试,个人觉得对生成的图片质量影响不大,但是用了之后跑起来会比较慢。
直接读入数据,从原始数据提取高度数据也是可行的一种方法。
下一个问题是,如何克服轮胎弯曲的问题?
本次提出的想法是:展平图像,并且还需去除轮胎的弯曲。
获取图像的长宽。设置一些预设的参数。创建一个空的平面。
设置一个1*40,值全为0.25的滤波器。
接下来,通过对每一行循环,从图像的开头到结尾,取图像的一部分作为patch。
在这里,patch的大小是20。当然,patch的大小是要参考实际情况而定的。

然后,将所有为0的值重新设置为patch里最大的值。
接下来,将patch里所有行堆叠在一起,取其中的最小值,生成一个一行数组。这个数组里面的值就是该patch里的最小值。

在取最小值之后,利用上文提到的1*40滤波器对其滤波,让他变得平滑,这样是为了方便接下来的展平。
滤波器的大小不是固定的,可以根据效果调整。

在卷积完之后,可以看到曲线变得更加平滑。这样就意味着文字的部分被消去了。
取出该patch里的第一行,也就是该patch里要处理的行,与卷积完之后的图像叠放在一起,取最小值,可以凸显文字。

这里可以更加清楚的看到。

但是这样也会产生一个问题:卷积完之后,边缘的值会变得异常。因此需要再处理边缘值。

处理完之后,再将patch中的第一行与生成的值对比,将其相减,这样保留下来的就是文字了。

最后再将其加入上文生成的平面中。
如此循环就能生成图像。
但是生成的图像对比度不明显,原因是这样的:
在这其中存在着诸多小于0的元素,因此要把这些元素变成0。
除此之外,因为边缘过大,所以还需要去除0.5以上的部分。把这些地方的元素钳制到0.5即可。

得到的效果如上图所示。
观察生成的平面,发现生成的平面实际上还是有起伏的。之前所作的操作在转置之后相当于是对每一列滤波。

而现在要做的就是再对每一行滤波。同样的设置一个1*40的矩阵,值全部为0.025,对其卷积。
这是卷积之前的图像(部分)。

这是卷积之后的图像(部分)。


可以看到蓝色线(之前),橘红色(之后)。取两者之间的最大值,将其送回。
除此之外,轮胎上存在毛刺,这也是需要去除的部分。方法是:寻找图像中的峰值(代表着毛刺),将他们提取出来,通过形态学操作使其膨胀,然后对其取反,去掉这些洞。效果如图。

但问题就是,这样也会影响文字主体。不过就整体而言,这样的代价是可以接受的。下一步就是进行文字检测。

文本检测的任务是定位出输入图像中的文字区域。文字检测是文字识别过程中的一个重要环节。对于简单场景,可以采用:形态学操作、MSER+NMS等算法;对于复杂场景可以采用:CTPN、SegLink、EAST、DBnet等。
在初期尝试的时候,尝试使用MSER+NMS算法,但是存在着将杂讯区域识别成文字区域的问题。MSER(Maximally Stable Extremal Regions,最大稳定极值区域)是一个较为流行的文字检测传统方法。
同时,一般会采用 NMS 方法(Non Maximum Suppression,非极大值抑制)来辅助去除检测到的重合区域。这一方法抑制非极大值的元素,即抑制不是最大尺寸的框,相当于去除大框中包含的小框,达到去除重复区域,找到最佳检测位置的目的。
然而,尽管MSER+NMS 尽管检测速度非常快,且能满足一定的文字识别场景。但当在复杂的自然场景中,特别是有复杂背景的,其检测效果也不尽人意,会将一些无关的因素也检测出来。因此,尝试使用其他方法来进行文字检测。
EAST算法的中间过程只有:全卷积网络FCN、非极大值抑制NMS。而且支持文本行、单词的多角度检测。
EAST的检测过程如下图所示:

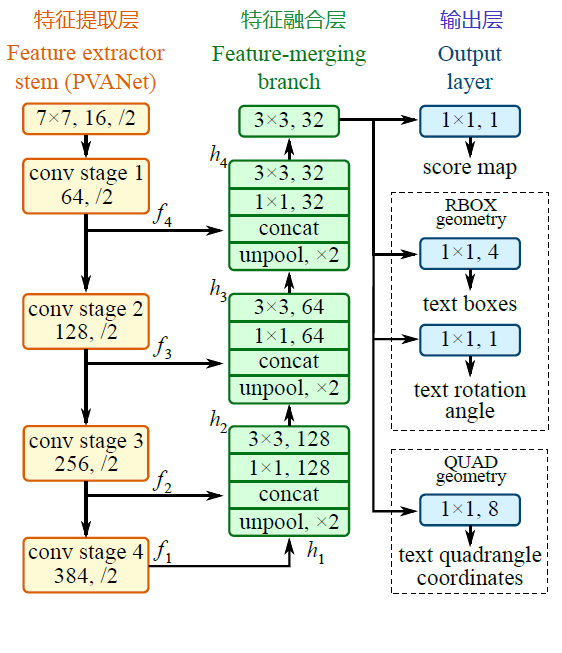
EAST 模型的网络结构分为特征提取层、特征融合层、输出层三大部分。
基于 PVANet(一种目标检测的模型)作为网络结构的骨干,分别从 stage1,stage2,stage3,stage4 的卷积层抽取出特征图,卷积层的尺寸依次减半,但卷积核的数量依次增倍,这是一种 “金字塔特征网络”(FPN,feature pyramid network)的思想。
通过这种方式,可抽取出不同尺度的特征图,以实现对不同尺度文本行的检测(大的 feature map 擅长检测小物体,小的 feature map 擅长检测大物体)。
将前面抽取的特征图按一定的规则进行合并,这里的合并规则采用了 U-net 方法,规则如下:
-
特征提取层中抽取的最后一层的特征图(f1)被最先送入 unpooling 层,将图像放大 1 倍
-
接着与前一层的特征图(f2)串起来(concatenate)
-
然后依次作卷积核大小为 1x1,3x3 的卷积
-
对 f3,f4 重复以上过程,而卷积核的个数逐层递减,依次为 128,64,32
-
最后经过 32 核,3x3 卷积后将结果输出到 “输出层”
最终输出以下 5 部分的信息,分别是:
-
score map:检测框的置信度,1 个参数;
-
text boxes:检测框的位置(x, y, w, h),4 个参数;
-
text rotation angle:检测框的旋转角度,1 个参数;
-
text quadrangle coordinates:任意四边形检测框的位置坐标,(x1, y1), (x2, y2), (x3, y3), (x4, y4),8 个参数。
其中,text boxes 的位置坐标与 text quadrangle coordinates 的位置坐标看起来似乎有点重复,其实不然,这是为了解决一些扭曲变形文本行,如下图:
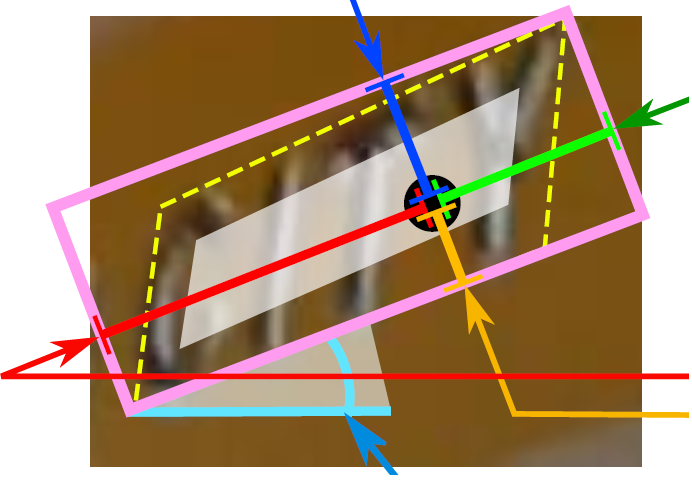
如果只输出 text boxes 的位置坐标和旋转角度(x, y, w, h,θ),那么预测出来的检测框就是上图的粉色框,与真实文本的位置存在误差。而输出层的最后再输出任意四边形的位置坐标,那么就可以更加准确地预测出检测框的位置(黄色框)。
Differentiable Binarization(DB),可以在分割网络中执行二值化的过程,可以自适应的设置二值化阈值,不仅可以简化后处理,并且提高了文本检测的性能。
在本项目所使用的框架PP中,集成了DB。也一并使用了这一算法来识别作为对照。
对于一个文本识别模型,需要有一下要素:
1、读取输入的图像,提取图像特征,因此,需要有个卷积层用于读取图像和提取特征。
2、由于文本序列是不定长的,因此在模型中需要引入 RNN(循环神经网络),一般是使用双向 LSTM 来处理不定长序列预测的问题。
3、为了提升模型的适用性,最好不要要求对输入字符进行分割,直接可进行端到端的训练,这样可减少大量的分割标注工作,这时就要引入 CTC 模型(Connectionist temporal classification, 联接时间分类),来解决样本的分割对齐的问题。
4、最后根据一定的规则,对模型输出结果进行纠正处理,输出正确结果。
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络),是华中科技大学在发表的论文《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition》提出的一个识别文本的方法,该模型主要用于解决基于图像的序列识别问题,特别是场景文字识别问题。
CRNN 的主要特点是:
(1)可以进行端到端的训练;
(2)不需要对样本数据进行字符分割,可识别任意长度的文本序列
(3)模型速度快、性能好,并且模型很小(参数少)
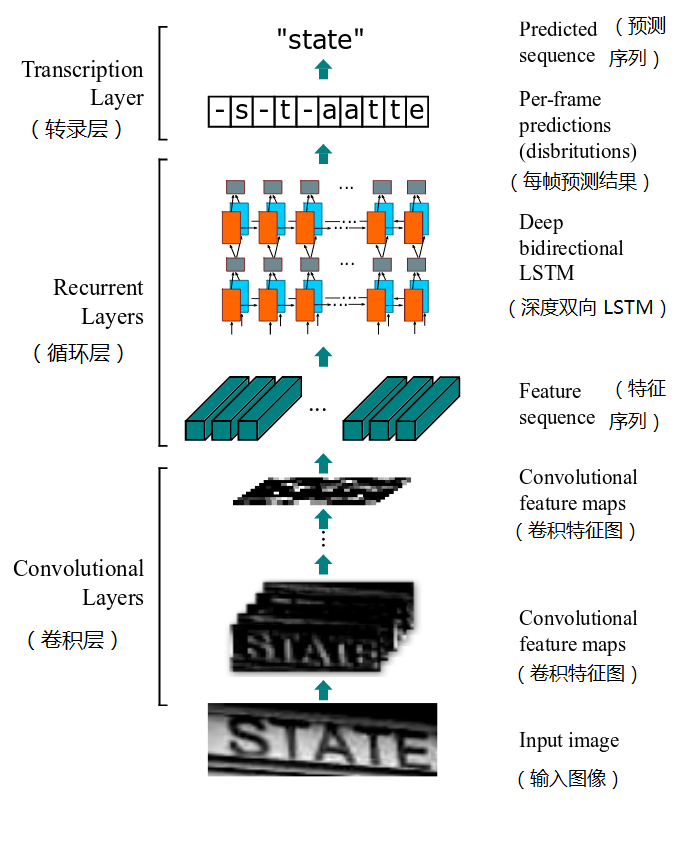
CRNN 模型主要由以下三部分组成:
(1)卷积层:从输入图像中提取出特征序列;
(2)循环层:预测从卷积层获取的特征序列的标签分布;
(3)转录层:把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果。
下面将展开对这三个层进行介绍:
CRNN 对输入图像先做了缩放处理,把所有输入图像缩放到相同高度,默认是 32,宽度可任意长。
由标准的 CNN 模型中的卷积层和最大池化层组成,结构类似于 VGG,如下图:
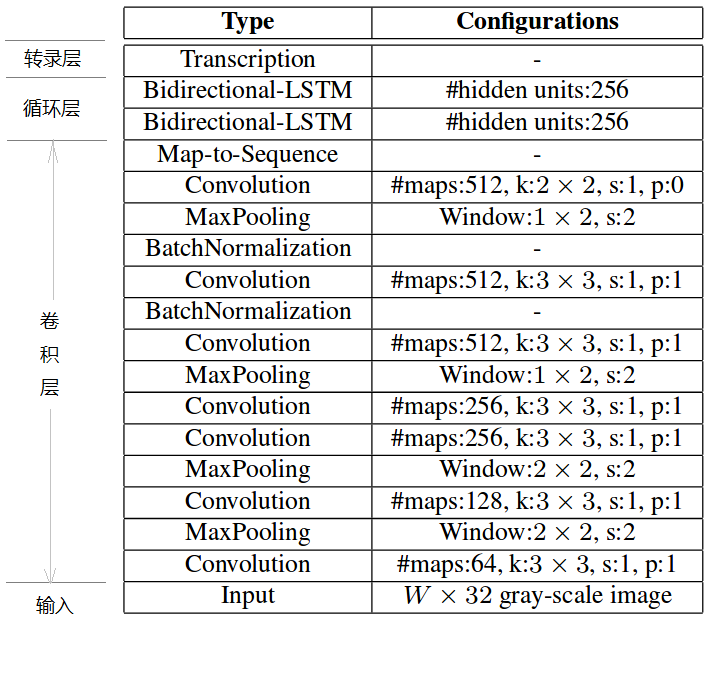
卷积层是由一系列的卷积、最大池化、批量归一化等操作组成的。
提取的特征序列中的向量是在特征图上从左到右按照顺序生成的,用于作为循环层的输入,每个特征向量表示了图像上一定宽度上的特征,默认的宽度是 1,也就是单个像素。由于 CRNN 已将输入图像缩放到同样高度了,因此只需按照一定的宽度提取特征即可。如下图所示:
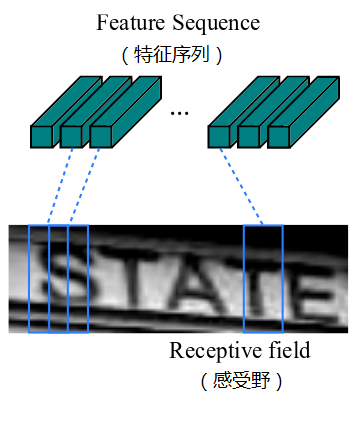
循环层由一个双向 LSTM 循环神经网络构成,预测特征序列中的每一个特征向量的标签分布。
由于 LSTM 需要有个时间维度,在本模型中把序列的 width 当作 LSTM 的时间 time steps。
其中,“Map-to-Sequence” 自定义网络层主要是做循环层误差反馈,与特征序列的转换,作为卷积层和循环层之间连接的桥梁,从而将误差从循环层反馈到卷积层。
转录层是将 LSTM 网络预测的特征序列的结果进行整合,转换为最终输出的结果。
在 CRNN 模型中双向 LSTM 网络层的最后连接上一个 CTC 模型,从而做到了端对端的识别。所谓 CTC 模型(Connectionist Temporal Classification,联接时间分类),主要用于解决输入数据与给定标签的对齐问题,可用于执行端到端的训练,输出不定长的序列结果。
由于输入的自然场景的文字图像,由于字符间隔、图像变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个词,如下图:
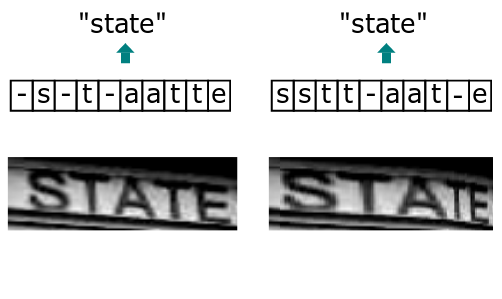
而引入 CTC 就是主要解决这个问题,通过 CTC 模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有 1 个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示:
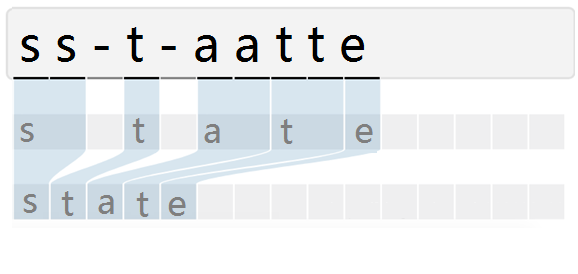
CRNN这种架构虽然准确,但复杂且LSTM的效率较低,很多移动设备对LSTM的加速效果并不好,所以在实际的应用场景中也存在诸多限制。随着swin transformer在计算机视觉领域大放光彩,swin的这种金字塔结构(像CNN里面的下采样一样)也被引入到文字识别。
而SVTR是一种文本定制的识别模型。它引入局部和全局混合块,分别提取笔划特征和字符间相关性,并结合多尺度backbone,形成多粒度特征描述。SVTR-L在识别英汉场景文本方面都取得了先进的性能。
SVTR的网络如下图所示。
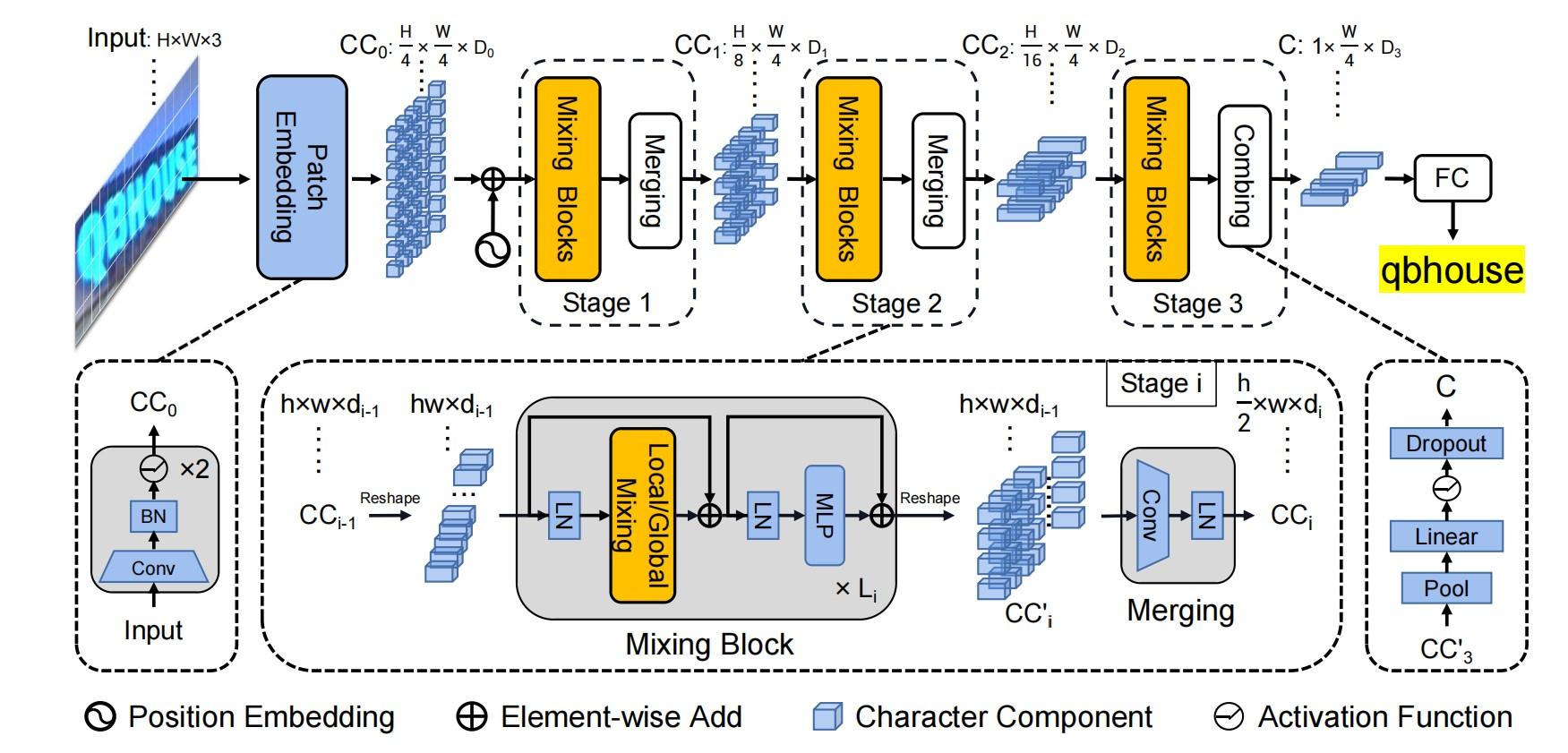
SVTR使用两个卷积进行1/4下采样得到token。
不同的是,swin是直接使用一个步长为4的4×4卷积进行无重叠的patch embedding。
但是,SVTR则是使用两个步长为2的3×3卷积进行有重叠的patch embedding。这是延续的CNN的作风,感受野更大,提取局部信息的表达能力也会比swin的patch embedding要好。
SVTR延续了paddleocr里面的CRNN下采样结构,3个下采样模块都只对特征图的高度进行下采样,即:
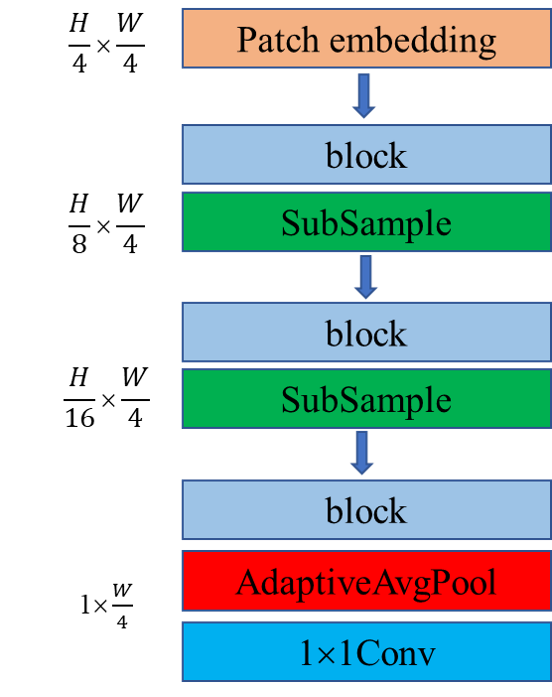
SVTR使用SubSample模块是一个步长为(2,1)核大小为3×3的普通卷积,之所以对高度进行下采样而不对宽度进行下采样,有两个原因:
(1)宽维度所包含的文字信息笔记丰富,下采样会造成较多信息的丢失
(2)CTC解码前的Argmax序列输出长度越大,结果越稀疏(包含的空字符越多,CTC解码时连续相同的文字就很大程度上不会被误判掉)
由于两个字符可能略有不同,文本识别严重依赖于字符组件级别的特征。
然而,现有的研究大多采用特征序列来表示图像文本。每个特征对应于一个切片图像区域,这通常是有噪声的,特别是对于不规则的文本。它不是描述这个角色的最佳方法。而vision transformer引入了二维特征表示,但如何在文本识别的背景下利用这种表示仍然值得研究。
更具体地说,对于embedded组件,作者认为文本识别需要两种特征:
(1)第一个是局部组件模式,如类似笔画的特征。它编码了形态特征和特征不同部分之间的相关性
(2)第二种是字符间的依赖性,如不同字符之间或文本和非文本组件之间的相关性。
因此,作者设计了两个混合块(全局Mix和局部Mix),通过使用不同接收场的self-attention来感知上下文的相关性。
1、Global Mixing
Global Mixing评估所有字符组件之间的依赖性。由于文本和非文本是图像中的两个主要元素,这种通用的Mixing可以建立来自不同字符的组件之间的长期依赖关系。
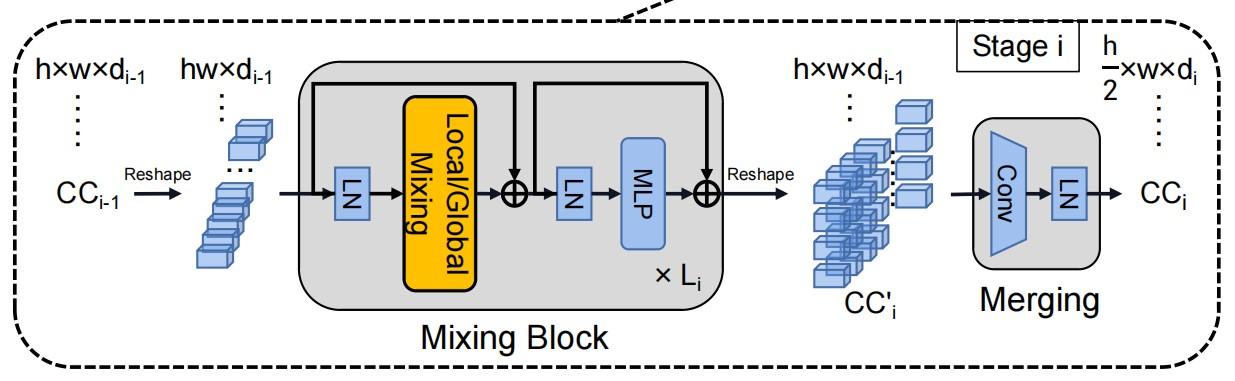
此外,它还能削弱非文本成分的影响,同时提高文本成分的重要性。
在数学上,对于上一阶段的字符组件CCi−1,它首先被reshape为一个特征序列。当进入Mixing block时,应用layer norm进行标准化,然后进行多头自注意获取其依赖关系。然后,依次应用LN和MLP进行特征融合。同时引入跳跃连接,形成全局混合块。
2、Local Mixing
而Local mixing评估了预定义窗口内组件之间的相关性。其目的是对形态特征进行编码,并建立特征内成分之间的关联,从而模拟对特征识别至关重要的笔画样例特征。
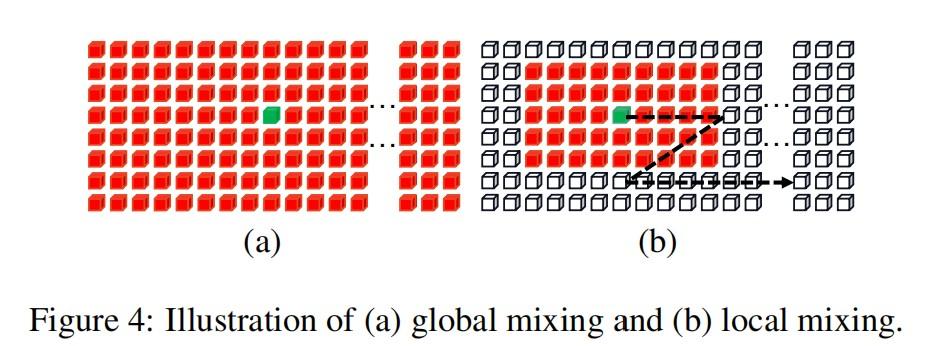
与Global Mixing不同,Local mixing考虑的是每个分量都有一个邻域。与卷积类似,混合是以滑动窗口的方式进行。窗口大小根据经验设置为7×11。
与Global Mixing相比,它实现了自我注意机制来捕获局部模式。其实就是Swin transformer里面的那一套,将全局的self-attention转换为局部的self-attention来计算,只不过swin是为了减少计算量,而SVTR是为了获取更多的局部信息。
而且swin是通过reshape这种类似的方式来进行滑窗,并将不同的窗口累加到通道维度上,而SVTR则是直接使用值为0的mask操作。SVTR这种做法和swin相比,计算复杂度还是比较高。
Merging其实就是下采样操作,和卷积的下采样一样。
因为self-attention的计算量和特征图的宽高有关,宽高太大的话,计算复杂度暴涨,所以SVTR对其进行了下采样操作,在低分辨率的特征图上计算可以减少矩阵乘法的计算复杂度。
在最后一个阶段,使用一个Combining进行维度的压缩。
首先将高度维度全局池化为1,然后是经过全连接层处理。在这里字符被进一步压缩为一个特征序列。与CRNN中的合并操作相比,SVTR的合并操作可以避免对一维尺寸非常小的token进行卷积,例如对高度为2的token进行卷积。
接着利用组合特征,通过一个简单的并行线性预测来实现识别。具体地说,使用全连接层生成转录序列。理想情况下,相同字符被转录成重复的字符,非文本的组件被转录成一个空白符号。就是一个CTC解码模块。
在本次项目里使用的PaddlePaddle框架还提供了基于SVTR算法优化的SVTR。这一算法不再采用RNN,而是使用transformer结构。这样可以更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。
直接将识别模型替换成SVTR_Tiny,识别准确率从74.8%提升到80.1%,但是预测速度慢了将近11倍。
总的来看,整个结构其实就是通过self-attention和线性层完成视觉信息和序列信息的编码一步到位。也就是省掉了CRNN里面那个LSTM模块。但是,在PaddleOCR V3里面只使用了两层的self-attention,还是通过mobilenet提取视觉信息,self-attention进行序列信息转换,没有全部使用transformer模块,大概是为了减少计算复杂度。
SVTR_LCNet是针对文本识别任务,将基于Transformer的SVTR网络和轻量级CNN网络PP-LCNet融合的一种轻量级文本识别网络。
使用该网络,预测速度优于PP-OCRv2的识别模型20%,但是由于没有采用蒸馏策略,该识别模型效果略差。此外,进一步将输入图片规范化高度从32提升到48,预测速度稍微变慢,但是模型效果大幅提升,识别准确率达到73.98%(+2.08%),接近PP-OCRv2采用蒸馏策略的识别模型效果。
SVTR_Tiny 网络结构如下所示:
由于 MKLDNN 加速库支持的模型结构有限,SVTR 在 CPU+MKLDNN 上相比 PP-OCRv2 慢了10倍。PP-OCRv3 期望在提升模型精度的同时,不带来额外的推理耗时。SVTR_Tiny 结构的主要耗时模块为 Mixing Block,因此PPOCR团队对 SVTR_Tiny 的结构进行了一系列优化。
1、将 SVTR 网络前半部分替换为 PP-LCNet 的前三个stage,保留4个 Global Mixing Block ,精度为76%,加速69%,网络结构如下所示:
2、将4个 Global Mixing Block 减小到2个,精度为72.9%,加速69%,网络结构如下所示:
3、Global Mixing Block 的预测速度与输入其特征的shape有关,因此后移 Global Mixing Block 的位置到池化层之后,精度下降为71.9%,速度超越基于CNN结构的PP-OCRv2-baseline 22%,网络结构如下所示:
利用PaddleOCR Label标注数据。由于轮胎中存在着多样字体等问题,标注数据采取手工方式进行。

Paddle提供了对于图像的增强方式,包括Resize, CenterCrop, ColorJitter, RandomHorizontalFlip, RandomRotation, Transpose, Normalize等。除此之外,我们还定义了Random Cutout。利用这些方法,我们生成了训练集。
训练使用的是PaddleOCR已经预训练的模型。经过测试,可以顺利在3080TI GPU上训练的只有ch_PP-OCRv3_det_distill_train的student模型。因为只有英文出现,所以使用的是英文字典。训练参数如下:
epoch_num: 5000
输出层: 96
优化器:Adam,默认参数
学习率: 0.0001
防过拟合:L2正则化进行5次随机挑选图片进行测试,得到的结果如下:
| 评价指标 | 平均值 | 最大值 | 最小值 |
|---|---|---|---|
| 识别率 | 86.7% | 95.5% | 81.8% |
| 准确率 | 70.12% | 91.0% | 43.3% |
| 召回率 | 75.3% | 96.0% | 33.3% |

在测试中发现,对于超长句的识别存在困难。一方面是因为字体本身就存在歪曲的情况,另一方面是标注的时候,存在漏标注的情况。

在测试中发现,对于 7与/,O与0,1与I的区分存在困难。即使是更换了自己训练的模型之后仍然存在这个问题。
由于部分字体本身在处理之后就存在低对比度的情况,导致无法认出这部分字体。而且字体和背景环境的融合也导致了无法识别。
目前的效果总体还不错。可以基本上提取出字符用来识别。但是只考虑了高度,得到的结果还是不够精确。
通过EAST、DB算法,可以自动化的标识出绝大部分的句子了。但是轮胎上都或多或少带有花样字体,而无论是哪种算法都无法准确检测出这部分字体。
CRNN对于大部分的文字有着良好的识别能力。但是面对部分字体会认错字,比如7与/这种。除此之外,对于长句的识别效果也不好。另外,即使依靠LSTM,有的句子还是不能很好的识别。
在绝大部分的情况下,对于轮胎上信息的提取都能有一个相对不错的效果,但是如果轮胎本身在处理完之后还是存在弯曲,或者使用了大量花样字体,那么字符检测的准确率就会大幅度下降。