The TSB-TAB model structure proposed in paper "Emotion recognition by fusing time synchronous and time asynchronous representations".
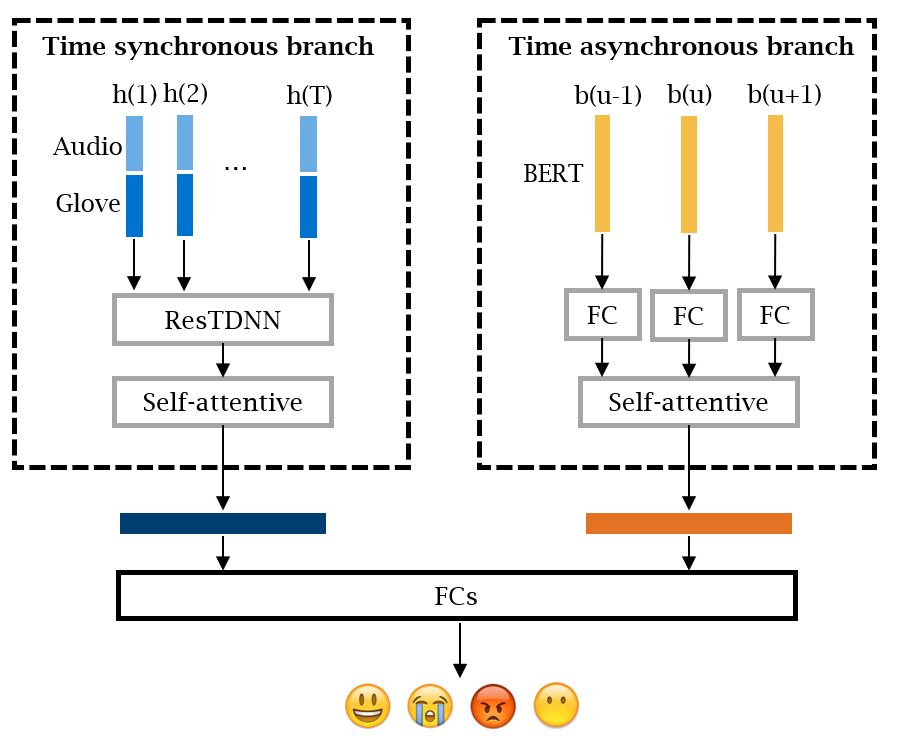
The system was implemented in HTK which causes difficulty in sharing the code. We’re working on releasing HTK-related work which might take some time due to complicated procedures.
Here we convert the HTK model structure to PyTorch along with the Newbob scheduler used in HTK. Users are encouranged to build their own dataloaders and training framework.
N.B. Layer-wise pretraining might be required to train the TSB.
For reference, we've reported the results evaluated with most of the commonly used speaker-independent test setups on IEMOCAP in the paper including leave-one-session-out 5-fold cross validation, leave-one-speaker-out 10-fold cross validation, and training on session 1-4 and testing on session 5.
If you find our work useful, please cite the corresponding paper:
@inproceedings{wu2021emotion,
title={Emotion recognition by fusing time synchronous and time asynchronous representations},
author={Wu, Wen and Zhang, Chao and Woodland, Philip C},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={6269--6273},
year={2021},
organization={IEEE}
}