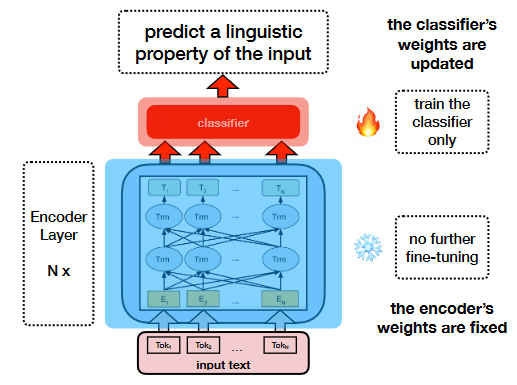
Given an encoder model (e.g., BERT) pre-trained on a certain task, we use the representations it produces to trian a classifier (without further fine-tuning the model) to predict a linguistic property of the input text.
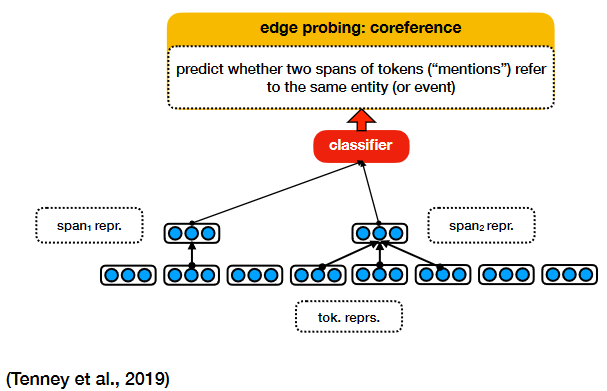
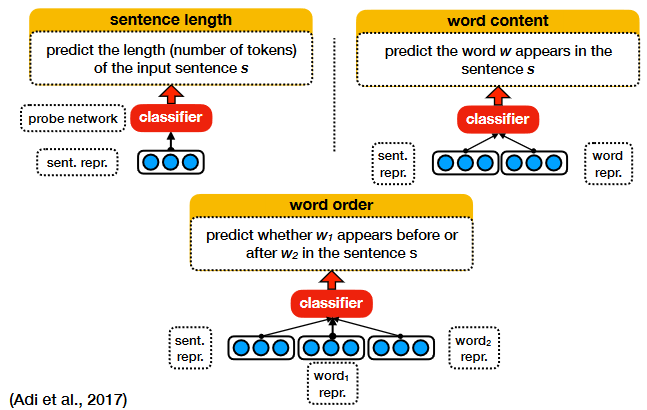
- if we can train a classifier to predict a property of the input text based on its representation, it means the property is encoded somewhere in the representation;
- if we cannot train a classifier to predict a property of the input text based on its representation, it means the property is not encoded in the representation or not encoded in a useful way, considering how the representation is likely to be used;
Literally, evaluation-based probing, it basically pulls out the output from the “module to probe”, attaches a prediction head (can be classification, regression, sequence labeling, and generation heads) on top of it. At the time of probing, we randomly initialize the prediction head and train the prediction head with the weights in the “module to probe” frozen. In real scenes, we compare the probing results between models or modules to assess the amount of task-relevant information stored in the models or modules.
- python3.9
Reference to download and install: https://www.python.org/downloads/release/python-3916/ - install requirements
> pip install -r requirements.txt
- Modify the config info in dataset/config.py, including the data_path, logging_path, checkpoints, and corpus you needed.
- Modify the parameters in run.sh
Noted that we offer two probing config: layer-wise and head-wise, pls specify the running mode based on your requirement.parser.add_argument("--task", default="ner", type=str, help="Please specify the task name {NER or Chunk}") parser.add_argument("--model_name_or_path", default="bert-base-uncased", type=str, help="Path to save the pretrained model") parser.add_argument("--embed_size", default="large", type=str) parser.add_argument("--label_size", default=2, type=int, help="classification task: the number of the label classes") parser.add_argument("--corpus",default="//home/weicheng/data_interns/yuan/", type=str) # Options parameters parser.add_argument("--config_name", default="", type=str,help="Pretrained config name or path if not the same as model_name_or_path", ) parser.add_argument("--tokenizer_name", default="", type=str,help="Pretrained tokenizer name or path if not the same as model_name_or_path", ) parser.add_argument("--cache_dir", default=None, type=str, help="Where do you want to store the pre-trained models downloaded from s3", ) parser.add_argument("--batch_size", default=64, type=int, help="Batch size.") parser.add_argument("--no_shuffle", action="store_true", help="Whether not to shuffle the dataloader") parser.add_argument("--seed", type=int, default=42) parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available") parser.add_argument("--epochs", default=3, type=int) parser.add_argument("--max_length", default=50, type=int, help="Max length of the tokenization") parser.add_argument("--num_workers", default=0, type=int) parser.add_argument("--lr", default=0.0001, type=float) parser.add_argument("--profile", action="store_true", help="whether to generate the heatmap") parser.add_argument("--mode", choices=["layer-wise", "head-wise"], type=str, help="choose training mode", default="layer-wise")
- Run the script
> bash run.sh
- Follow the scripts in paper-revision/run_exp.sh:
> bash run_exp.sh
- Follow the scripts in paper-revision/probing_exp_{}.sh
> bash probing_exp_{}.sh
- Follow the scripts in paper-revision/plot_head_magnitude.sh
> bash plot_head_magnitude.sh
Find more info in paper-revision/.