
ModelScope Community
中文 | English | Docs

- Introduction
- News
- 🔥LLM Training and Inference
- 🔥SCEdit Tuner
- Installation
- Getting Started
- Learn More
- License
- Contact Us
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) is an extensible framwork designed to faciliate lightweight model fine-tuning and inference. It integrates implementations for various efficient fine-tuning methods, by embracing approaches that is parameter-efficient, memory-efficient, and time-efficient. SWIFT integrates seamlessly into ModelScope ecosystem and offers the capabilities to finetune various models, with a primary emphasis on LLMs and vision models. Additionally, SWIFT is fully compatible with PEFT, enabling users to leverage the familiar Peft interface to finetune ModelScope models.
Currently supported approches (and counting):
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 🔥SCEdit: SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing < arXiv | Project Page >
- NEFTune: Noisy Embeddings Improve Instruction Finetuning
- QA-LoRA:Quantization-Aware Low-Rank Adaptation of Large Language Models.
- LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
- ROME: Rank-One Editing of Encoder-Decoder Models
- Adapter: Parameter-Efficient Transfer Learning for NLP
- Prompt Tuning: Visual Prompt Tuning
- Side: Side-Tuning: A Baseline for Network Adaptation via Additive Side Networks
- Res-Tuning: Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone < arXiv | Project Page | Usage >
- All tuners offered on PEFT, like IA3, AdaLoRA
Key features:
- By integrating the ModelScope library, models can be readily obatined via a model-id.
- Tuners provided by SWIFT can be combined together to allow exploration of multiple tuners on a model for best result.
- Support calling
activate_adapterordeactivate_adapterorset_active_adaptersto activate/deactivate tuners. User can inference with one model and multiple tuners in different threads independently. - Support training and inference with scripts/CLI,meanwhile support inference with Web-UI.
- Support model deployment(vllm/chatglm.cpp/xinference),Check Official documentation for details.
Users can check the documentation of SWIFT to get detail tutorials.
- 🔥2024.02.05: Support Qwen1.5 series, To view all supported Qwen1.5 models please check Model List. The qwen1half-7b-chat, qwen1half-7b-chat-int8 fine-tuned scripts are provided.
- 2024.02.01: Support openbmb-minicpm series: openbmb-minicpm-2b-sft-chat, openbmb-minicpm-2b-chat.
- 🔥2024.02.01: Support dataset mixture to reduce Catastrophic Forgetting. Use
--train_dataset_mix_ratio 2.0to train! We also provide a common knowledge dataset ms-bench. - 🔥2024.02.01: Support Agent training! Agent training algorithm comes from this paper. We also introduce the ms-agent dataset. Use this script to begin an agent training!
- 🔥2024.02.01: Support SFT loss to DPO training to reduce the repeat generation problem caused by the KL-divergence loss.
- 2024.02.01: Support AdaLoRA and IA3 adapter in SFT.
- 2024.02.01: Support
--merge_lora_and_savein AnimateDiff training. - 2024.01.30: Support internlm-xcomposer2-7b-chat.
- 🔥2024.01.30: Support ZeRO-3, just need to specify
--deepspeed_config_path default-zero3. - 2024.01.29: Support internlm2-math series: internlm2-math-7b, internlm2-math-7b-chat, internlm2-math-20b, internlm2-math-20b-chat.
- 🔥2024.01.26: Support yi-vl-6b-chat, yi-vl-34b-chat.
- 2024.01.24: Support codefuse-codegeex2-6b-chat, codefuse-qwen-14b-chat.
- 2024.01.23: Support orion series: orion-14b, orion-14b-chat.
- 2024.01.20: Support xverse-13b-256k, xverse-65b-v2, xverse-65b-chat.
- 🔥2024.01.17: Support internlm2 series: internlm2-7b-base, internlm2-7b, internlm2-7b-sft-chat, internlm2-7b-chat, internlm2-20b-base, internlm2-20b, internlm2-20b-sft-chat, internlm2-20b-chat.
- 2024.1.15: Support yuan series: yuan2-2b-instruct, yuan2-2b-janus-instruct, yuan2-51b-instruct, yuan2-102b-instruct.
- 🔥2024.01.12: Support deepseek-moe series: deepseek-moe-16b, deepseek-moe-16b-chat.
- 🔥2024.01.04: Support for VLLM deployment, compatible with the OpenAI API style. For more details, please refer to VLLM Inference Acceleration and Deployment
- 2024.01.04: Update Benchmark to facilitate viewing the training speed and GPU memory required for different models.
More
- 🔥 2023.12.29: Support web-ui for training and inference, use
swift web-uiafter the installation of ms-swift. - 🔥 2023.12.29: Support DPO RLHF(Reinforcement Learning from Human Feedback) and two datasets: AI-ModelScope/stack-exchange-paired and AI-ModelScope/hh-rlhf for this task. Check this documentation to start training!
- 🔥 2023.12.28: Support SCEdit! This framework can easily reduce memory usage in training and inference, and replace ControlNet for controllable image generating scenarios, view the following chapter for details.
- 2023.12.23: Support codegeex2-6b.
- 2023.12.19: Support phi2-3b.
- 2023.12.18: Support for VLLM for inference acceleration.
- 2023.12.15: Support deepseek, deepseek-coder series: deepseek-7b, deepseek-7b-chat, deepseek-67b, deepseek-67b-chat, openbuddy-deepseek-67b-chat, deepseek-coder-1_3b, deepseek-coder-1_3b-instruct, deepseek-coder-6_7b, deepseek-coder-6_7b-instruct, deepseek-coder-33b, deepseek-coder-33b-instruct.
- 2023.12.13: Support mistral-7b-instruct-v2, mixtral-moe-7b, mixtral-moe-7b-instruct.
- 2023.12.09: Support the
freeze_parametersparameter as a compromise between LoRA and full parameter. Corresponding shell scripts can be found at full_freeze_ddp. Supportdisable_tqdm,lazy_tokenize,preprocess_num_procparameters, for details please refer to Command-Line parameters. - 2023.12.08: Support sus-34b-chat, support yi-6b-200k, yi-34b-200k.
- 2023.12.07: Support Multi-Node DDP training.
- 2023.12.04: Supported models: zephyr-7b-beta-chat, openbuddy-zephyr-7b-chat. Supported datasets: hc3-zh, hc3-en.
- 🔥 2023.12.02: Best Practices for Self-cognition Fine-tuning, 10 minutes for self-cognition fine-tuning for LLM, creating a LLM that is specific to oneself.
- 🔥 2023.11.30: Support for training and inference of the qwen-1_8b, qwen-72b, and qwen-audio model series. The corresponding shell scripts can be viewed at qwen_1_8b_chat, qwen_72b_chat, qwen_audio_chat.
- 🔥 2023.11.29: Support the training and inference for AnimateDiff
- 🔥 2023.11.24: Support for yi-34b-chat, codefuse-codellama-34b-chat: The corresponding shell script can be found in yi_34b_chat, codefuse_codellama_34b_chat.
- 🔥 2023.11.18: Support for tongyi-finance-14b series models: tongyi-finance-14b, tongyi-finance-14b-chat, tongyi-finance-14b-chat-int4. The corresponding shell script can be found in tongyi_finance_14b_chat_int4.
- 2023.11.16: Added support for more models in flash attn: qwen series, qwen-vl series, llama series, openbuddy series, mistral series, yi series, ziya series. Please use the
use_flash_attnparameter. - 🔥 2023.11.11: NEFTune Supported, Use is with
Swift.prepare_model(model, NEFTuneConfig()) - 🔥 2023.11.11: Support training and inference with CLI, and inference with Web-UI. Check the Run using Swift CLI chapter for details.
- 🔥 2023.11.11: Support model deployment(vllm/chatglm.cpp/xinference),Check Official documentation for details.
- 🔥 2023.11.10: Support for bluelm series models: bluelm-7b, bluelm-7b-chat, bluelm-7b-32k, bluelm-7b-chat-32k. The corresponding shell script can be found in bluelm_7b_chat.
- 🔥 2023.11.08: Support the finetuning of xverse-65b model, scripts can be found at: xverse_65b.
- 🔥 2023.11.07: Support the finetuning of yi-6b, yi-34b model, scripts can be found at: yi_6b, yi_34b.
- 🔥 2023.10.30: Support QA-LoRA and LongLoRA to decrease memory usage in training.
- 🔥 2023.10.30: Support ROME(Rank One Model Editing) to add/modify knowledges, training is not needed!
- 2023.10.30: Support for skywork-13b series models: skywork-13b, skywork-13b-chat. The corresponding shell script can be found in skywork_13b.
- 🔥 2023.10.27: Support for chatglm3 series models: chatglm3-6b-base, chatglm3-6b, chatglm3-6b-32k. The corresponding shell script can be found in chatglm3_6b.
- 🔥 2023.10.17: Supported int4, int8 models: qwen-7b-chat-int4, qwen-14b-chat-int4, qwen-vl-chat-int4, baichuan2-7b-chat-int4, baichuan2-13b-chat-int4, qwen-7b-chat-int8, qwen-14b-chat-int8.
- 2023.10.15: Supported ziya2-13b model series: ziya2-13b, ziya2-13b-chat.
- 2023.10.12: Supported mistral-7b model series: openbuddy-mistral-7b-chat, mistral-7b, mistral-7b-instruct.
- 🔥 2023.10.07: Supported DeepSpeed ZeRO-2, enabling LoRA (not just QLoRA) to run DDP on 2*A10.
- 2023.10.04: Supported datasets in the fields of mathematics, law, SQL, and coding: blossom-math-zh, school-math-zh, text2sql-en, sql-create-context-en, lawyer-llama-zh, tigerbot-law-zh, leetcode-python-en.
- 🔥 2023.09.25: Supported qwen-14b model series: qwen-14b, qwen-14b-chat.
- 2023.09.18: Supported internlm-20b model series: internlm-20b, internlm-20b-chat.
- 2023.09.12: Supported training with MP+DDP to accelerate full-parameter fine-tuning speed.
- 2023.09.05: Supported openbuddy-llama2-70b-chat model.
- 2023.09.03: Supported baichuan2 model series: baichuan2-7b, baichuan2-7b-chat, baichuan2-13b, baichuan2-13b-chat.
After installation, you can use web-ui training/inference like:
SWIFT_UI_LANG=en swift web-uiSupported environment variables:
WEBUI_SHARE=1 Share the gradio or not SWIFT_UI_LANG=en/zh The language of radio WEBUI_SERVER server_name, web-ui host ip,0.0.0.0 means all routes are allowed,127.0.0.1 means only localhost can visit the web WEBUI_PORT The port of web-ui
Here is a simple introduction of web-ui:
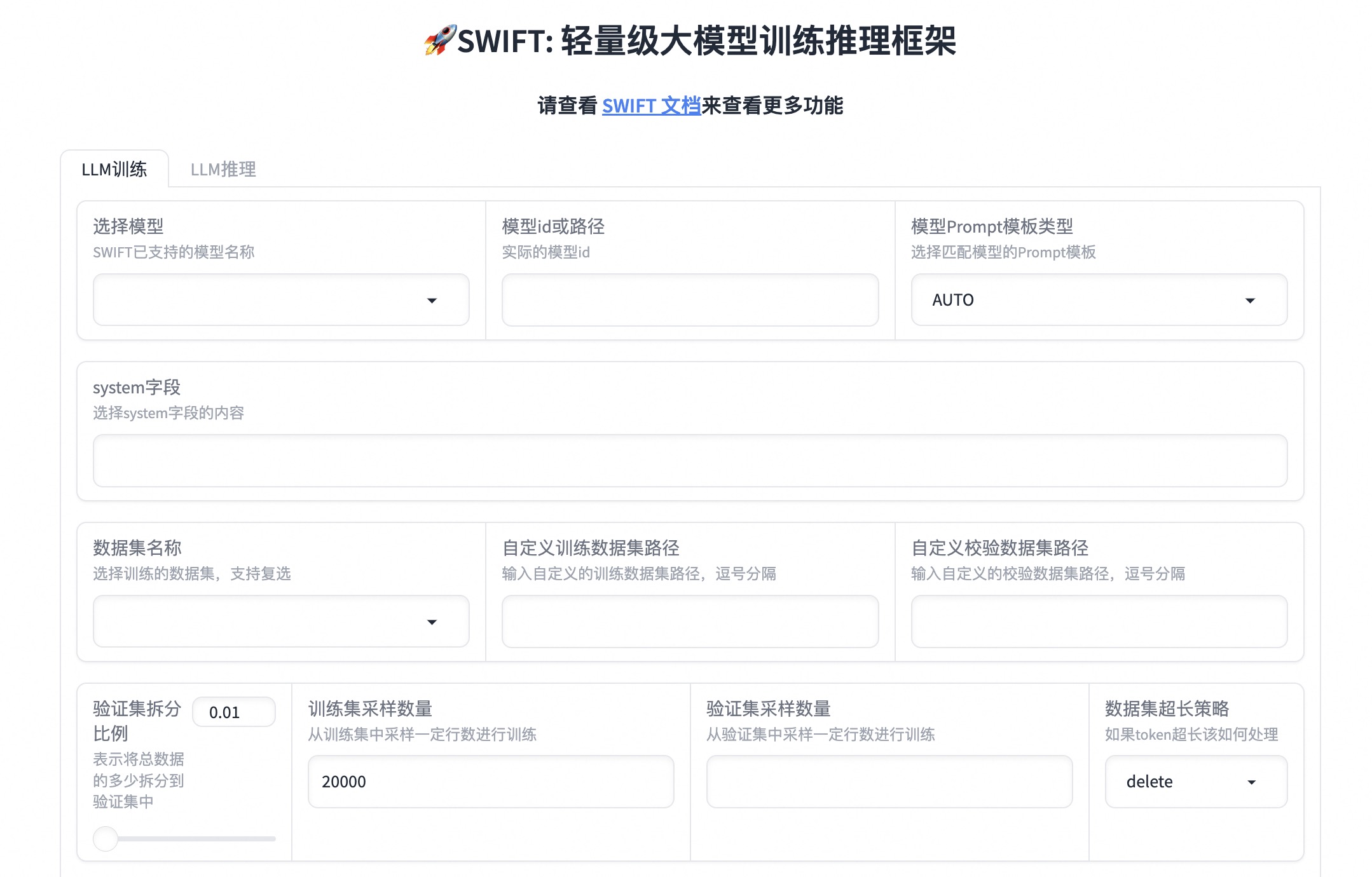
- Self-cognition fine-tuning for large models in 10 minutes, creating a personalized large model, please refer to Best Practices for Self-cognition Fine-tuning.
- Quickly perform inference on LLM and build a Web-UI, see the LLM Inference Documentation.
- Rapidly fine-tune and perform inference on LLM, and build a Web-UI, see the LLM Fine-tuning Documentation.
- Using interface to fine-tuning and perform inference, see the WEB-UI Documentation.
- DPO training supported, start by using this script.
- Utilize VLLM for inference acceleration and deployment(OpenAI API). Please refer to VLLM Inference Acceleration and Deployment for more information.
- View the models and datasets supported by Swift. You can check supported models and datasets.
- Expand and customize models, datasets, and dialogue templates in Swift, see Customization and Expansion.
- Check command-line parameters for fine-tuning and inference, see Command-Line parameters.
- View the training time and training GPU memory comparison under different parameters, you can check Benchmark.
# pip install ms-swift -U
# Experimental environment: A10, 3090, V100, ...
# 12GB GPU memory
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
from swift.llm import (
DatasetName, InferArguments, ModelType, SftArguments,
infer_main, sft_main, app_ui_main, merge_lora_main
)
model_type = ModelType.qwen_1_8b
sft_args = SftArguments(
model_type=model_type,
train_dataset_sample=2000,
dataset=[DatasetName.jd_sentiment_zh],
output_dir='output')
result = sft_main(sft_args)
best_model_checkpoint = result['best_model_checkpoint']
print(f'best_model_checkpoint: {best_model_checkpoint}')
torch.cuda.empty_cache()
infer_args = InferArguments(
ckpt_dir=best_model_checkpoint,
load_dataset_config=True,
val_dataset_sample=10)
# merge_lora_main(infer_args)
result = infer_main(infer_args)
torch.cuda.empty_cache()
app_ui_main(infer_args)- Supported SFT Methods: lora, qlora, longlora, qalora, full parameter fine-tuning, partial parameter fine-tuning.
- Supported Features: quantization, DDP, model parallelism, gradient checkpointing, pushing to modelscope hub, custom datasets, multimodal and agent SFT, mutli-round chat, DPO, self-cognition fine-tuning, ...
- Supported Models: [Detailed Info]
- Multi-Modal:
- qwen-vl series: qwen-vl, qwen-vl-chat, qwen-vl-chat-int4.
- qwen-audio series: qwen-audio, qwen-audio-chat.
- yi-vl series: yi-vl-6b-chat, yi-vl-34b-chat.
- cogagent series: cogagent-18b-chat, cogagent-18b-instruct.
- internlm-xcomposer2 series: internlm-xcomposer2-7b-chat.
- General:
- qwen series: qwen-1_8b, qwen-1_8b-chat, qwen-1_8b-chat-int4, qwen-1_8b-chat-int8, qwen-7b, qwen-7b-chat, qwen-7b-chat-int4, qwen-7b-chat-int8, qwen-14b, qwen-14b-chat, qwen-14b-chat-int4, qwen-14b-chat-int8, qwen-72b, qwen-72b-chat, qwen-72b-chat-int4, qwen-72b-chat-int8.
- qwen1.5 series: qwen1half-0_5b, qwen1half-0_5b-chat, qwen1half-0_5b-chat-int4, qwen1half-0_5b-chat-int8, qwen1half-1_8b, qwen1half-1_8b-chat, qwen1half-1_8b-chat-int4, qwen1half-1_8b-chat-int8, qwen1half-4b, qwen1half-4b-chat, qwen1half-4b-chat-int4, qwen1half-4b-chat-int8, qwen1half-7b, qwen1half-7b-chat, qwen1half-7b-chat-int4, qwen1half-7b-chat-int8, qwen1half-14b, qwen1half-14b-chat, qwen1half-14b-chat-int4, qwen1half-14b-chat-int8, qwen1half-72b, qwen1half-72b-chat, qwen1half-72b-chat-int4, qwen1half-72b-chat-int8.
- chatglm series: chatglm2-6b, chatglm2-6b-32k, chatglm3-6b-base, chatglm3-6b, chatglm3-6b-32k.
- llama series: llama2-7b, llama2-7b-chat, llama2-13b, llama2-13b-chat, llama2-70b, llama2-70b-chat.
- yi series: yi-6b, yi-6b-200k, yi-6b-chat, yi-34b, yi-34b-200k, yi-34b-chat.
- internlm series: internlm-7b, internlm-7b-chat, internlm-7b-chat-8k, internlm-20b, internlm-20b-chat, internlm2-7b-base, internlm2-7b, internlm2-7b-sft-chat, internlm2-7b-chat, internlm2-20b-base, internlm2-20b, internlm2-20b-sft-chat, internlm2-20b-chat.
- deepseek series: deepseek-7b, deepseek-7b-chat, deepseek-67b, deepseek-67b-chat, deepseek-moe-16b, deepseek-moe-16b-chat.
- openbuddy series: openbuddy-llama2-13b-chat, openbuddy-llama-65b-chat, openbuddy-llama2-70b-chat, openbuddy-mistral-7b-chat, openbuddy-zephyr-7b-chat, openbuddy-deepseek-67b-chat.
- mistral series: mistral-7b, mistral-7b-instruct, mistral-7b-instruct-v2.
- mixtral series: mixtral-moe-7b, mixtral-moe-7b-instruct.
- baichuan series: baichuan-7b, baichuan-13b, baichuan-13b-chat, baichuan2-7b, baichuan2-7b-chat, baichuan2-13b, baichuan2-13b-chat, baichuan2-7b-chat-int4, baichuan2-13b-chat-int4.
- yuan series: yuan2-2b-instruct, yuan2-2b-janus-instruct, yuan2-51b-instruct, yuan2-102b-instruct.
- xverse series: xverse-7b, xverse-7b-chat, xverse-13b, xverse-13b-chat, xverse-65b, xverse-65b-v2, xverse-65b-chat, xverse-13b-256k.
- orion series: orion-14b, orion-14b-chat.
- openbmb-minicpm 系列: openbmb-minicpm-2b-sft-chat, openbmb-minicpm-2b-chat.
- bluelm series: bluelm-7b, bluelm-7b-chat, bluelm-7b-32k, bluelm-7b-chat-32k.
- zephyr series: zephyr-7b-beta-chat.
- ziya series: ziya2-13b, ziya2-13b-chat.
- skywork series: skywork-13b, skywork-13b-chat.
- other: polylm-13b, seqgpt-560m, sus-34b-chat.
- Financial:
- tongyi-finance series: tongyi-finance-14b, tongyi-finance-14b-chat, tongyi-finance-14b-chat-int4.
- Coding:
- codefuse series: codefuse-codellama-34b-chat, codefuse-codegeex2-6b-chat, codefuse-qwen-14b-chat.
- deepseek-coder series: deepseek-coder-1_3b, deepseek-coder-1_3b-instruct, deepseek-coder-6_7b, deepseek-coder-6_7b-instruct, deepseek-coder-33b, deepseek-coder-33b-instruct.
- codegeex2 series: codegeex2-6b.
- phi series: phi2-3b.
- Math:
- internlm2-math series: internlm2-math-7b, internlm2-math-7b-chat, internlm2-math-20b, internlm2-math-20b-chat.
- Multi-Modal:
- Supported Datasets: [Detailed Info]
- NLP:
- General: 🔥ms-bench, 🔥alpaca-en(gpt4), 🔥alpaca-zh(gpt4), multi-alpaca-all, instinwild-en, instinwild-zh, cot-en, cot-zh, firefly-all-zh, instruct-en, gpt4all-en, sharegpt-en, sharegpt-zh, 🔥tulu-v2-sft-mixture, wikipedia-zh, open-orca, open-orca-gpt4, sharegpt-gpt4.
- Agent: 🔥ms-agent, damo-mini-agent-zh, damo-agent-zh, agent-instruct-all-en.
- RLHF: 🔥hh-rlhf, stack-exchange-paired.
- Coding: code-alpaca-en, 🔥leetcode-python-en, 🔥codefuse-python-en, 🔥codefuse-evol-instruction-zh.
- Medical: medical-en, medical-zh, medical-mini-zh.
- Law: 🔥lawyer-llama-zh, tigerbot-law-zh.
- Math: 🔥blossom-math-zh, school-math-zh, open-platypus-en.
- SQL: text2sql-en, 🔥sql-create-context-en.
- Text Generation: 🔥advertise-gen-zh, 🔥dureader-robust-zh.
- Classification: cmnli-zh, 🔥cmnli-mini-zh, 🔥jd-sentiment-zh, 🔥hc3-zh, 🔥hc3-en.
- RLHF: 🔥hh-rlhf, stack-exchange-paired.
- Other: finance-en, poetry-zh, webnovel-zh, generated-chat-zh, cls-fudan-news-zh, ner-jave-zh.
- Multi-Modal:
- Vision: coco-en, 🔥coco-mini-en, coco-mini-en-2, capcha-images.
- Audio: aishell1-zh, 🔥aishell1-mini-zh.
- Custom Dataset
- NLP:
- Supported Templates:
- Text Generation: default-generation, default-generation-bos, chatglm-generation.
- Chat: default, qwen, baichuan, chatglm2, chatglm3, llama, openbuddy, internlm, internlm2, yi, yuan, xverse, ziya, skywork, bluelm, zephyr, sus, deepseek, deepseek-coder, codefuse-codellama, codefuse, cogagent-chat, cogagent-instruct, yi-vl, internlm-xcomposer2, openbmb.
SCEdit is an efficient generative fine-tuning framework proposed by Alibaba TongYi Vision Intelligence Lab. This framework enhances the fine-tuning capabilities for text-to-image generation downstream tasks and enables quick adaptation to specific generative scenarios, saving 30%-50% of training memory costs compared to LoRA. Furthermore, it can be directly extended to controllable image generation tasks, requiring only 7.9% of the parameters that ControlNet needs for conditional generation and saving 30% of memory usage. It supports various conditional generation tasks including edge maps, depth maps, segmentation maps, poses, color maps, and image completion.
We using 3D style data from the style transfer dataset for training, and testing with the same Prompt: A boy in a camouflage jacket with a scarf. The qualitative and quantitative results are as follows:
| Method | bs | ep | Target Module | Param. (M) | Mem. (MiB) | 3D style |
|---|---|---|---|---|---|---|
| LoRA/r=64 | 1 | 50 | q/k/v/out/mlp | 23.94 (2.20%) | 8440MiB |  |
| SCEdit | 1 | 50 | up_blocks | 19.68 (1.81%) | 7556MiB |  |
| LoRA/r=64 | 10 | 100 | q/k/v/out/mlp | 23.94 (2.20%) | 26300MiB |  |
| SCEdit | 10 | 100 | up_blocks | 19.68 (1.81%) | 18634MiB |  |
| LoRA/r=64 | 30 | 200 | q/k/v/out/mlp | 23.94 (2.20%) | 69554MiB |  |
| SCEdit | 30 | 200 | up_blocks | 19.68 (1.81%) | 43350MiB |  |
The benchmark listed above can be reproduced by:
# Install swift by the next chapter
cd examples/pytorch/multi_modal/notebook
python text_to_image_synthesis.pySWIFT is running in Python environment. Please make sure your python version is higher than 3.8.
- Install SWIFT by the
pipcommand:
# full ability
pip install ms-swift[all] -U
# only use llm
pip install ms-swift[llm] -U
# only use aigc
pip install ms-swift[aigc] -U
# only use adapters
pip install ms-swift -U- Install SWIFT by source code(for running sft/infer examples), please run:
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]SWIFT requires torch>=1.13.
- Use SWIFT in our docker image:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.1SWIFT supports multiple tuners, as well as tuners provided by PEFT. To use these tuners, simply call:
from swift import Swift, LoRAConfig
config = LoRAConfig(...)
model = Swift.prepare_model(model, config, extra_state_keys=['...'])The code snippet above initialized the tuner randomly. The input model is an instance of torch.nn.Module, the config is a subclass instance of SwiftConfig or PeftConfig. extra_state_keys is
the extra module weights(like the linear head) to be trained and stored in the output dir.
You may combine multiple tuners by:
from swift import Swift, LoRAConfig, PromptConfig
model = Swift.prepare_model(model, {'lora': LoRAConfig(...), 'prompt': PromptConfig(...)})Call save_pretrained and push_to_hub after finetuning:
from swift import push_to_hub
model.save_pretrained('some-output-folder')
push_to_hub('my-group/some-repo-id-modelscope', 'some-output-folder', token='some-ms-token')Assume my-group/some-repo-id-modelscope is the model-id in the hub, and some-ms-token is the token for uploading.
Using the model-id to do later inference:
from swift import Swift
model = Swift.from_pretrained(model, 'my-group/some-repo-id-modelscope')Here shows a runnable example:
import os
import tempfile
# Please install modelscope by `pip install modelscope`
from modelscope import Model
from swift import LoRAConfig, SwiftModel, Swift, push_to_hub
tmp_dir = tempfile.TemporaryDirectory().name
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
model = Model.from_pretrained('modelscope/Llama-2-7b-ms', device_map='auto')
lora_config = LoRAConfig(target_modules=['q_proj', 'k_proj', 'v_proj'])
model: SwiftModel = Swift.prepare_model(model, lora_config)
# Do some finetuning here
model.save_pretrained(tmp_dir)
push_to_hub('my-group/swift_llama2', output_dir=tmp_dir)
model = Model.from_pretrained('modelscope/Llama-2-7b-ms', device_map='auto')
model = SwiftModel.from_pretrained(model, 'my-group/swift_llama2', device_map='auto')This is a example that uses transformers for model creation uses SWIFT for efficient tuning.
from swift import Swift, LoRAConfig, AdapterConfig, PromptConfig
from transformers import AutoModelForImageClassification
# init vit model
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
# init lora tuner config
lora_config = LoRAConfig(
r=10, # the rank of the LoRA module
target_modules=['query', 'key', 'value'], # the modules to be replaced with the end of the module name
merge_weights=False # whether to merge weights
)
# init adapter tuner config
adapter_config = AdapterConfig(
dim=768, # the dimension of the hidden states
hidden_pos=0, # the position of the hidden state to passed into the adapter
target_modules=r'.*attention.output.dense$', # the modules to be replaced with regular expression
adapter_length=10 # the length of the adapter length
)
# init prompt tuner config
prompt_config = PromptConfig(
dim=768, # the dimension of the hidden states
target_modules=r'.*layer\.\d+$', # the modules to be replaced with regular expression
embedding_pos=0, # the position of the embedding tensor
prompt_length=10, # the length of the prompt tokens
attach_front=False # Whether prompt is attached in front of the embedding
)
# create model with swift. In practice, you can use any of these tuners or a combination of them.
model = Swift.prepare_model(model, {"lora_tuner": lora_config, "adapter_tuner": adapter_config, "prompt_tuner": prompt_config})
# get the trainable parameters of model
model.get_trainable_parameters()
# 'trainable params: 838,776 || all params: 87,406,432 || trainable%: 0.9596273189597764'You can use the features offered by Peft in SWIFT:
from swift import LoraConfig, Swift
from peft import TaskType
lora_config = LoraConfig(target_modules=['query', 'key', 'value'], task_type=TaskType.CAUSAL_LM)
model_wrapped = Swift.prepare_model(model, lora_config)
# or call from_pretrained to load weights in the modelhub
model_wrapped = Swift.from_pretrained(model, 'some-id-in-the-modelscope-modelhub')The saving strategy between Swift tuners and Peft tuners are slightly different. You can name a tuner by:
model = Swift.prepare_model(model, {'default': LoRAConfig(...)})
model.save_pretrained('./output')In the output dir, you will have a dir structure like this:
output
|-- default
|-- adapter_config.json
|-- adapter_model.bin
|-- adapter_config.json
|-- adapter_model.bin
The config/weights stored in the output dir is the config of extra_state_keys and the weights of it. This is different from PEFT, which stores the weights and config of the default tuner.
-
ModelScope Library is the model library of ModelScope project, which contains a large number of popular models.
This project is licensed under the Apache License (Version 2.0).
You can contact and communicate with us by joining our WeChat Group:
