The main benefit of a very deep network is that it can represent very complex functions. It can also learn features at many different levels of abstraction, from edges (at the lower layers) to very complex features (at the deeper layers). However, a huge barrier to training them is vanishing gradients.
ResNets has 2 advantages:
- A "shortcut" or a "skip connection" allows the gradient to be directly backpropagated to earlier layers reducing the vanishing gradient problem

- ResNet blocks with the shortcut makes it very easy for one of the blocks to learn an identity function
Training set: 1080 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (180 pictures per number)
Test set: 120 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (20 pictures per number)
Here are examples for each number, and corresponding labels converted to one-hot.

Architecture:
- Input is an image of size 64 x 64 x 3 (RGB), which is normalized by dividing 255
- Model:
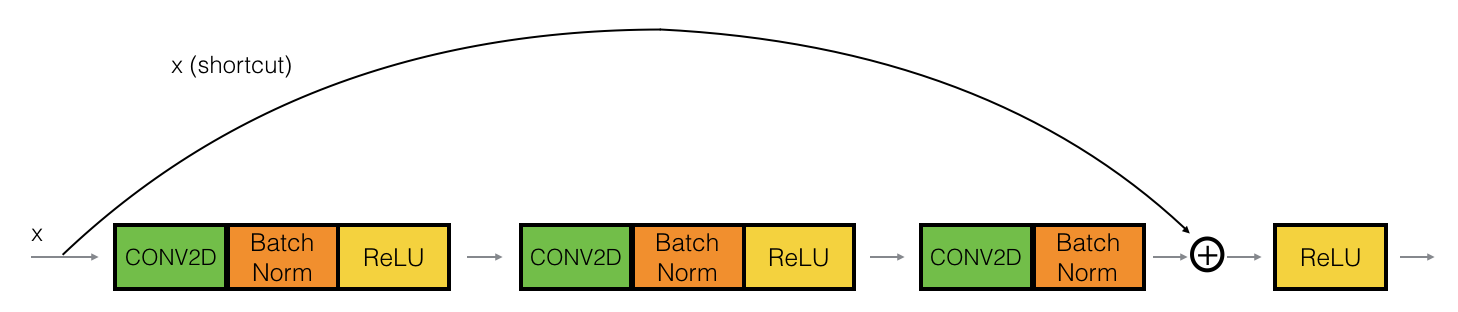
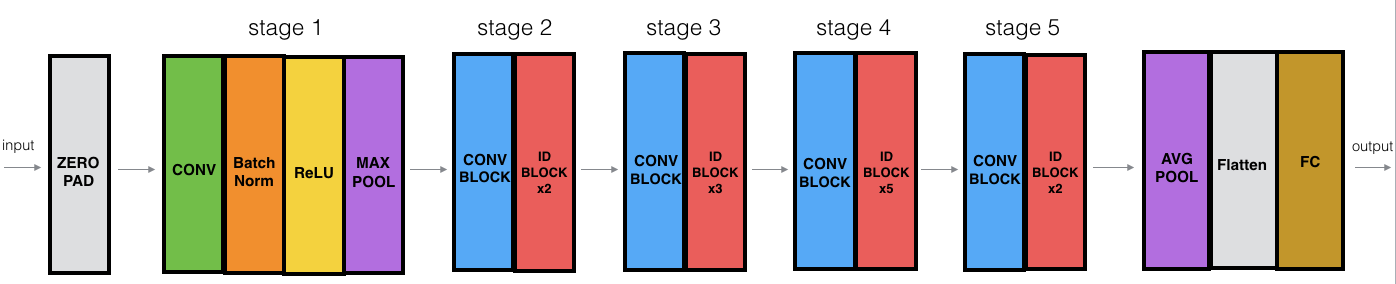 which comprises of identity block:
which comprises of identity block:
 and convolution block:
and convolution block:
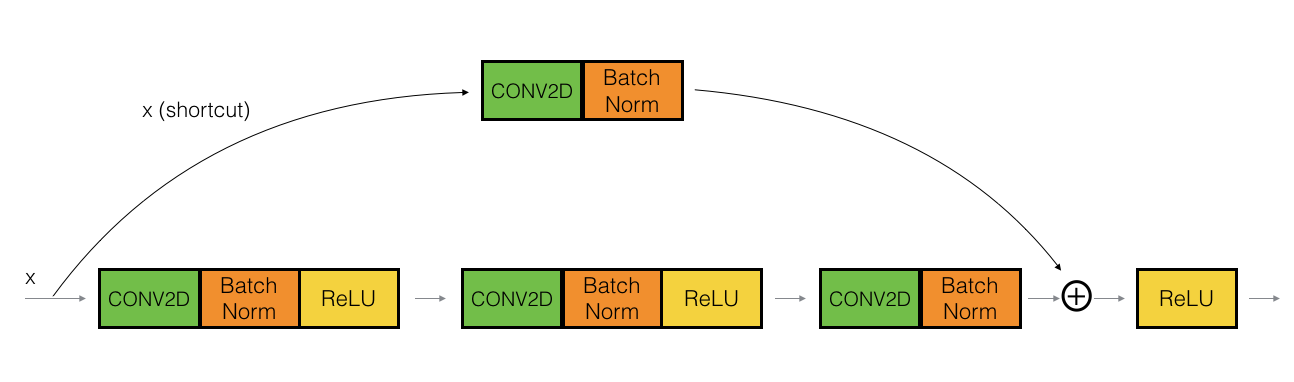
- The last fully connected layer gives a probability of the image belonging to one of the six classes.
- RELU activation function. Categorical cross entropy loss. Adam optimizer
- Mini-batch gradient descent with minibatch_size of 32
The model is CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK x 2 -> CONVBLOCK -> IDBLOCK x 3 -> CONVBLOCK -> IDBLOCK x 5 -> CONVBLOCK -> IDBLOCK x 2 -> AVGPOOL -> FLATTEN -> FC
Outcome:
- Training cost graph-
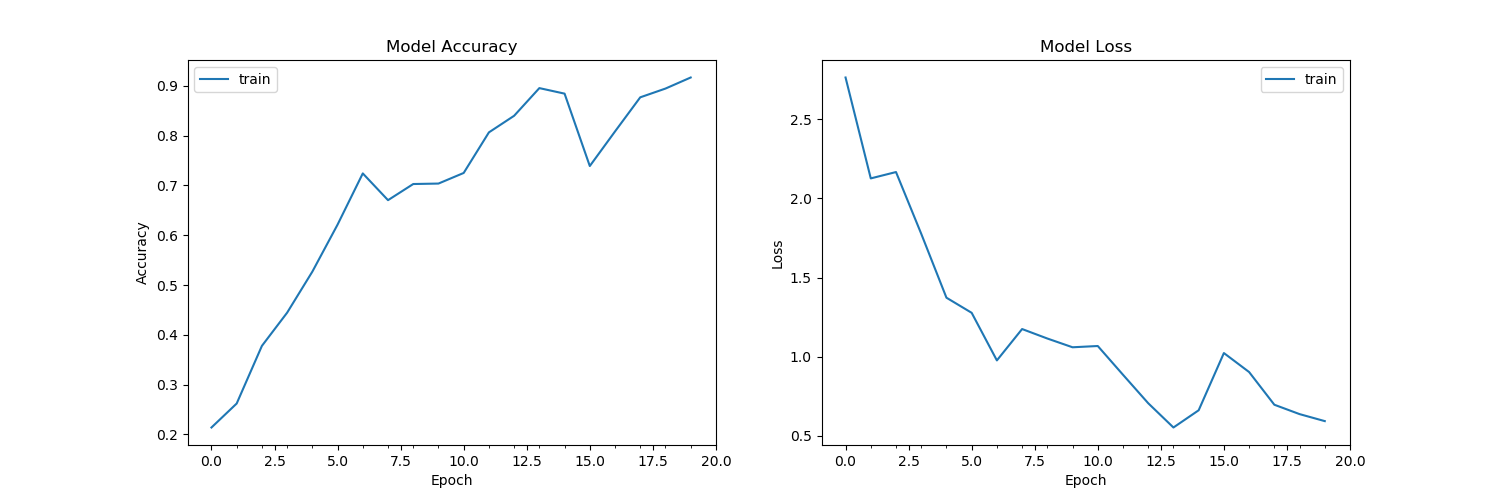
- Train accuracy - 0.917
Train loss - 0.59
Test accuracy - 0.875
Test loss - 0.77 - TODO- to overcome overfitting, add L2 or dropout regularization