WELCOME TO THE WAV2VGM PROJECT !!!
This (messy) utility for Python 3 takes an input WAV file and outputs it as
an VGM file that uses OPL3 synthesis to recreate the original sound.
Examples are provided demonstrating famous speeches as well as a
conversion of a classic arcade tune from YM2151 (OPM) to YMF262M! (OPL3)
Directory Content:
doc - Currently just some screenshots
input - Some same wave files to use as input
output - Those waves, converted to OPL3, as VGM and MP3 file
training_sets - Large files for training AI models
models - AI Models created using the above data
src - Misc. source code, training set generator, and
trainer for the convolutional neural-network.
WAV2VGM.py - Main executable
The sound files from the input/ directory have been converted and are provided in the output/ directory as VGM files and MP3 files. These can be played using WINAMP, VGMPLAY, a REAL OPL3 CHIP, etc.:
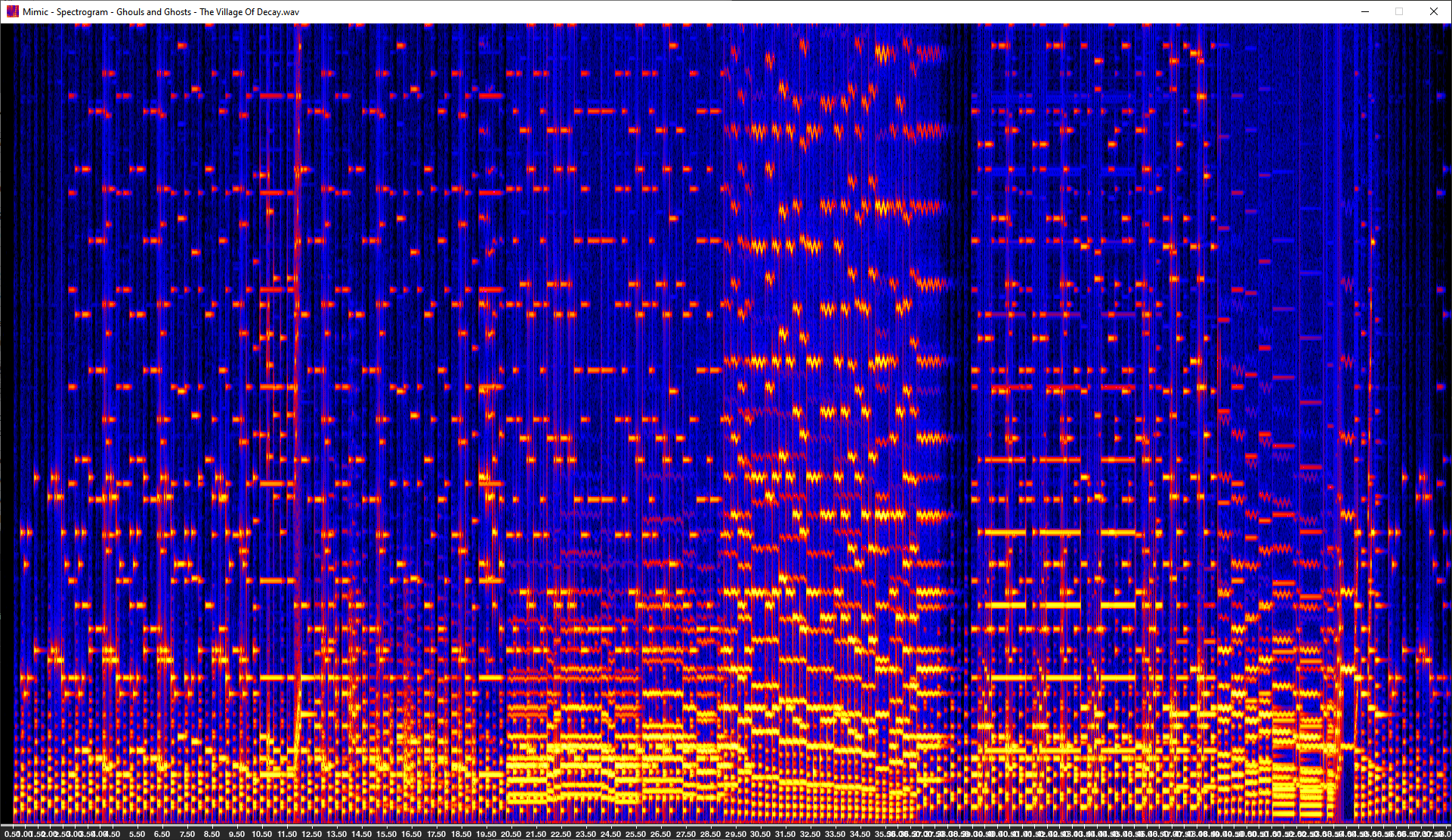
Ghouls and Ghosts - The Village of Decay
Spectrogram view of a song: "Ghouls and Ghosts - The Village of Decay"
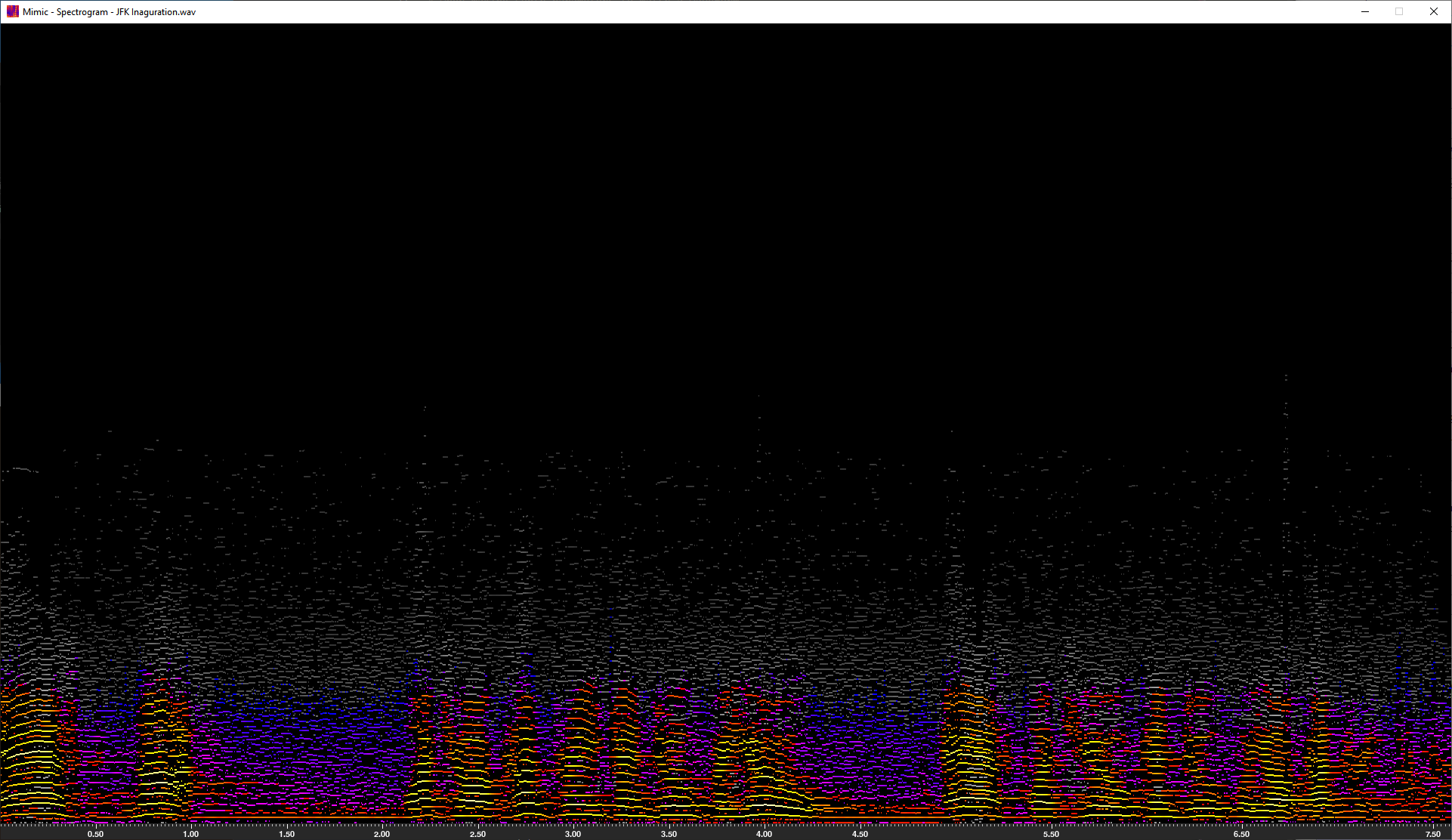
Peak Detection view of a speech sample
This utility requires Python 3.8+ to be installed, as well as the package manager, python3-pip. There are additional dependencies, listed in requirements.txt, which can be be installed from the command-line in Windows, Linux, or Mac by doing something similar to the following:
pip install numpy pygame scipy PyOPL torch
sudo pip install numpy pygame scipy PyOPL torch
If you want to experiment with training the AI stuff yourself, there are more appropriate versions of torch (pytorch) to install, for example, ones that leverage your system's GPU. Your steps will vary, but in my case, it was from a Windows admin command prompt:
pip install numpy pygame scipy matplotlib PyOPL torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
Input files must be 16-bit WAV files, MONO, with a 44.1 kHz samplerate.
Examples of starting the utility from the command-line:
cd WAV2VGM
python WAV2VGM.py "input\JFK Inaguration.wav"
cd WAV2VGM
./WAV2VGM.py "input/JFK Inaguration.wav"
If all is well, after some time, a window should appear which displays a spectrogram of the input sound. From here, a few different commands can be issued by pressing the following (lowercase) keys:
p - Play original sound (Currently, program is unresponsive during playback)
f - Analyzes the sound simply, and outputs a VGM file to the 'output/'
directory. Also, plays a rendition of the output. (The program will
be unresponsive during playback.)
(Output file can be played using WINAMP, VGMPLAY, or a real YMF262M!)
a - Analyze the spectrum and show frequency peaks.
Clicking on the displayed spectrogram sets some cursors, but these don't yet
do anything, and might even crash the app! (Still kinda fun to play with.)
Or, close the window to quit.
EXPERIMENTAL STUFF - (WORK-IN-PROGRESS)
n - Tries to make a VGM using the convolutional neural-network model at
'models/torch_model.pth' (Not working well at all)
g - Tries to make a VGM using the slow-as-heck genetic algorithm! The
initial population is completely randomized. Super slowwwww.
(Also not working well at all.)
b - Brute force. This uses the original basic additive synthesis method
to generate the initial spectra, but then the genetic algo gets a
crack at it and starts making several changes which improve the
fit. (Super slow, but I'm anxious to get through a whole conversion
and hear this, because the graphs look exciting!) UPDATE: Sounds
terrible! Just because the spectrum looks neat doesnt mean it's
gonna sound right!
m - Manual mode.. currently just applies the original method and lets
you view the per-frame results using left/right arrow keys,
or press P to make a VGM and play it. For some reason, this one
sounds WAY less bloopy than the one using the F key. It's nearly
perfect! ...except it's pretty quiet, and there's this weird
crackling sound??
CHANGELOG:
2024-11-25: Added 'manual mode' with what would be a greatly improved
sound, except for the weird crackle. What the heck?
I put some example VGM's in this subfolder:
'output/less_bloopy_but___' ...hopefully will find the
cause of the crackle sometime.
AI Notes: I'm going to give up on the AI for a while..
What's a good loss function for a bank of registers where
several parts (channels) are completely interchangable?
My head hurts. AI gurus, please help.
2024-11-16: Massive code cleanups and speedups.
2024-11-15: Some AI Improvement
2024-11-14: Greatly improved output sound quality.
- The spectrogram is made by slicing the input wave into 4096 byte samples, with 32-samples of overlap per slice. Each spectrum is 2048-bins spanning a frequency range of 0Hz to 22050 Hz, at about 10.8 Hz per bin. The frequency range shown on screen scaled up by three though, from 0Hz (bottom) to 7350 Hz (top).
There is much room for improvement in this project:
-
The code is quite disorganized and slow, and the user interface is sparse and unintuitive.
-
The input file format requirements are too strict. Utility should be able to load files of different types, with different sample rates and channel counts.
-
There should be some settings to tweak to affect the conversion.
-
The output files are larger than they really need to be. (Redundancy in the instructions sent to the OPL3, e.g. the same frequency being set repeatedly, even if unchanged)
-
It would be super easy to add OPL2 support, since it's nearly the same except with less channels. (Many of the synthesizers supported by the VGM file format would be a good fit with this project and should be added.)
-
The quality of the output could be HUGELY BETTER: The re-synthesis method currently only contains pure sine waves (1-operator, basically), rather than any of the more advanced features offered in OPL3 such as 2-op, 4-op, percussion modes, waveforms besides sine, volume envelopes, vibrato, tremolo, etc. See below.
-
Work is underway to try to leverage more advanced synthesizer capabilities:
-
The first attempt was a super-slow genetic algorithm that generates some interesting results.
-
We are also trying to build a neural network to do it! See the READMEs in 'model/' and 'training_sets/' for info about the NN stuff.
-