![]()
Spark SQL Macros provide a capability to register custom functions into a Spark Session
that is similar to custom UDF Registration capability of Spark.
The difference being that the SQL Macros registration mechanism attempts to translate the function
body to an equivalent Spark catalyst Expression with holes(MarcroArg catalyst expressions).
A FunctionBuilder that encapsulates this expression is registered in Spark's FunctionRegistry.
Then any function invocation is replaced by the equivalent catalyst Expression
with the holes replaced by the calling site arguments.
There are 2 potential performance benefits for replacing function calls with native catalyst expressions:
- evaluation performance. Since we avoid the SerDe cost at the function boundary.
- More importantly, since the plan has native catalyst expressions more optimizations are possible.
- For example in the taxRate example below discount calculation can be eliminated.
- Pushdown of operations to Datsources has a huge impact. For example see below for the Oracle SQL generated and pushed when a macro is defined instead of a UDF.
To use this functionality:
- build the jar by issuing
sbt sql/assemblyor download from releases page. - the jar can be added into any Spark env.
- We have developed with
spark-3.1dependency.
We explain further with another example, contrasting current function registration and invocation with macro registration and invocation.
A custom function is registered, in the following way. Consider a very simple function that adds 2 its
argument.
spark.udf.register("intUDF", (i: Int) => {
val j = 2
i + j
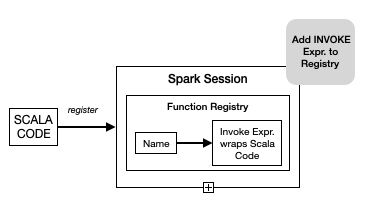
})Under the covers a Invoke Catalyst Expression is associated with the function name in
Spark's Function Registry. At runtime an Invoke Catalyst Expression runs the associated
function body.
Then the following spark-sql query(assuming unit_test has a column c_int : Int):
select intUDF(c_int)
from unit_test
where intUDF(c_int) > 1generates the following plan:
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|plan |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|== Physical Plan ==
*(1) Project [if (isnull(c_int#9)) null else intUDF(knownnotnull(c_int#9)) AS intUDF(c_int)#10]
+- *(1) Filter (if (isnull(c_int#9)) null else intUDF(knownnotnull(c_int#9)) > 1)
+- *(1) ColumnarToRow
+- FileScan parquet default.unit_test[c_int#9] Batched: true, DataFilters: [(if (isnull(c_int#9)) null else intUDF(knownnotnull(c_int#9)) > 1)], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/qy/qtpc2h2n3sn74gfxpjr6nqdc0000gn/T/warehouse-8b1e79b..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<c_int:int>
|
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
- The
intUDFis invoked in theFilter operatorfor evaluating theintUDF(c_int) < 0predicate; - The
intUDFis invoked in theProject operatorto evaluate the projectionintUDF(c_int)
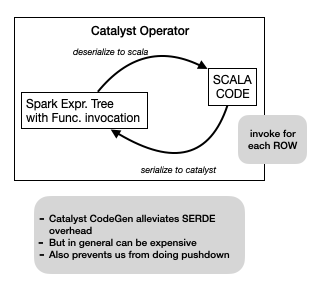
Logically the evaluation of these function calls involves moving values
between Catalyst and Scala and making a function call on the JVM.
Catalyst CodeGen(and Java JIT) does a good job of optimizing away the Serde and
function calls for simple functions; but in general this cannot be avoided.
Besides since the function code is a blackbox no further optimization, like
expression pushdown to a DataSource is possible.
The intUDF is a trivial function that just adds 2 to its argument.
It would be nice if we convert the function body into a + 2 expressions.
With Spark SQL Macros you can register the function as a macro like this:
import org.apache.spark.sql.defineMacros._
spark.registerMacro("intUDM", spark.udm((i: Int) => {
val j = 2
i + j
}))This is almost identical to the registeration process for custom functions in Spark. But under the covers, we leverage the Macro mechanics of the Scala Compiler to analyze the Scala AST of the function body and try to generate an equivalent Catalyst Expression for the function body.
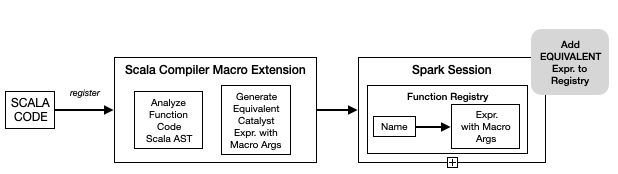
If we succeed then what is registered in the Function Registry is a plain old Catalyst Expression with holes that get replaced with argument expressions at any call-site of the function.
The query:
select intUDM(c_int)
from sparktest.unit_test
where intUDM(c_int) < 0generates the following physical plan:
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|plan |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|== Physical Plan ==
*(1) Project [(c_int#9 + 1) AS (c_int + 1)#27]
+- *(1) Filter (isnotnull(c_int#9) AND ((c_int#9 + 1) > 1))
+- *(1) ColumnarToRow
+- FileScan parquet default.unit_test[c_int#9] Batched: true, DataFilters: [isnotnull(c_int#9), ((c_int#9 + 1) > 1)], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/qy/qtpc2h2n3sn74gfxpjr6nqdc0000gn/T/warehouse-8b1e79b..., PartitionFilters: [], PushedFilters: [IsNotNull(c_int)], ReadSchema: struct<c_int:int>
|
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
- The predicate
intUDM(c_int) < 0becomes("C_INT" + 1) < 0 - the projection
intUDM(c_int)becomes"C_INT" + 2. - since Macro calls are just plain old catalyst expressions,
the Project and Filters are pushable to Datasources. When we run a
similar query against an Oracle Datasource that we have developed the plan looks
like the one below.
- in this case the Oracle sql pushed is the entire query(the pushed sql uses jdbc bind variables)
- because we are pushing the entire query only rows matching the filter condition are streamed out of the datasource.
|== Physical Plan ==
Project (2)
+- BatchScan (1)
(1) BatchScan
Output [1]: [(c_int + 2)#2316]
OraPlan: 00 OraSingleQueryBlock [(C_INT#2309 + 2) AS (c_int + 2)#2316], [oraalias((C_INT#2309 + 2) AS (c_int + 2)#2316)], orabinaryopexpression((((C_INT#2309 + 2) < 0) AND isnotnull(C_INT#2309)))
01 +- OraTableScan SPARKTEST.UNIT_TEST, [C_INT#2309]
ReadSchema: struct<(c_int + 2):int>
dsKey: DataSourceKey(jdbc:oracle:thin:@den02ads:1531/cdb1_pdb7.regress.rdbms.dev.us.oracle.com,tpcds)
oraPushdownBindValues: 2, 1
oraPushdownSQL: select ("C_INT" + 2) AS "(c_int + 2)"
from SPARKTEST.UNIT_TEST
where ((("C_INT" + ?) > ?) AND "C_INT" IS NOT NULL)
(2) Project [codegen id : 1]
Output [1]: [(c_int + 2)#2316]
Input [1]: [(c_int + 2)#2316]
We will provide translation support for the following scala constructs
- Primitive datatypes, Case Classes in Scala, Tuples, Arrays, Collections and Maps
- For Tuples and Case Classes we will translate field access
- Value Definitions
- Arbitrary References at the macro call-site that can be evaluated at macro definition time
- Arithmetic, Math, Datetime, String, and Decimal functions supported in Catalyst
- Recursive macro invocations
- Scala Case and If statements.
See Spark SQL Macro examples page.
In addition to supporting User-Defined macros, we also plan to provide a way such that argument functions provided to DataFrame map and flatMap high-order functions get converted to equivalent catalyst expressions.
Let's define a Product dataset:
case class Product(prod : String, prodCat : String, amt : Double)
val prods = for(i <- (0 until 1000000)) yield {
Product(s"p_$i", {val m = i % 3; if (m == 0) "alcohol" else if (i == 1) "grocery" else "rest"}, (i % 200).toDouble)
}
val prodDF = spark.createDataset(prods).coalesce(1).cache
prodDF.count
prodDF.createOrReplaceGlobalTempView("products")Now consider tax and discount calculation defined as:
- no tax on groceries, alcohol is
10.5%, everything else is9.5% - on Sundays give a discount of
5%on alcohol.
import org.apache.spark.sql.defineMacros._
import org.apache.spark.sql.sqlmacros.DateTimeUtils._
import java.time.ZoneId
spark.registerMacro("taxAndDiscount", spark.udm({(prodCat : String, amt : Double) =>
val taxRate = prodCat match {
case "grocery" => 0.0
case "alcohol" => 10.5
case _ => 9.5
}
val currDate = currentDate(ZoneId.systemDefault())
val discount = if (getDayOfWeek(currDate) == 1 && prodCat == "alcohol") 0.05 else 0.0
amt * ( 1.0 - discount) * (1.0 + taxRate)
}))The Plan for the following query
spark.sql(
"""
|explain extended
|select prod, taxAndDiscountM(prod, amt) as taxAndDiscount
|from global_temp.products""".stripMargin
).show(1000, false)is:
|== Parsed Logical Plan ==
'Project ['prod, 'taxAndDiscountM('prod, 'amt) AS taxAndDiscount#357]
+- 'UnresolvedRelation [global_temp, products], [], false
== Analyzed Logical Plan ==
prod: string, taxAndDiscount: double
Project [prod#3, ((amt#5 * (1.0 - if (((dayofweek(current_date(Some(America/Los_Angeles))) = 1) AND (prod#3 = alcohol))) 0.05 else 0.0)) * (1.0 + CASE WHEN (prod#3 = grocery) THEN 0.0 WHEN (prod#3 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#357]
+- SubqueryAlias global_temp.products
+- Repartition 1, false
+- LocalRelation [prod#3, prodCat#4, amt#5]
== Optimized Logical Plan ==
Project [prod#3, ((amt#5 * 1.0) * (1.0 + CASE WHEN (prod#3 = grocery) THEN 0.0 WHEN (prod#3 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#357]
+- InMemoryRelation [prod#3, prodCat#4, amt#5], StorageLevel(disk, memory, deserialized, 1 replicas)
+- Coalesce 1
+- LocalTableScan [prod#3, prodCat#4, amt#5]
== Physical Plan ==
*(1) Project [prod#3, ((amt#5 * 1.0) * (1.0 + CASE WHEN (prod#3 = grocery) THEN 0.0 WHEN (prod#3 = alcohol) THEN 10.5 ELSE 9.5 END)) AS taxAndDiscount#357]
+- InMemoryTableScan [amt#5, prod#3]
+- InMemoryRelation [prod#3, prodCat#4, amt#5], StorageLevel(disk, memory, deserialized, 1 replicas)
+- Coalesce 1
+- LocalTableScan [prod#3, prodCat#4, amt#5]
|
The analyzed expression for thetaxDiscount calculation is:
(
(amt#5 *
(1.0 - if (((dayofweek(current_date(Some(America/Los_Angeles))) = 1) AND (prod#3 = alcohol))) 0.05 else 0.0)) *
(1.0 + CASE WHEN (prod#3 = grocery) THEN 0.0 WHEN (prod#3 = alcohol) THEN 10.5 ELSE 9.5 END)
) AS taxAndDiscount#357In the optimized plan, the discount calculation is replaced by 1.0 because the day this explain
was run was a Friday
(
(amt#5 * 1.0) *
(1.0 + CASE WHEN (prod#3 = grocery) THEN 0.0 WHEN (prod#3 = alcohol) THEN 10.5 ELSE 9.5 END)
) AS taxAndDiscount#300There are many cases where Spark SQL Macros based plans will perform better than equivalent User-Defined functions.
Obviously as we demonstrated in the Macro behavior section Spark Macro plans enable lot more pushdown processing to the DataSource. In these cases by-and-large the Macro based plan will provide a lot of performance gain.
But even without the advantage of pushdown macro plans can perform better because the Serialization-Deserialization at function call boundaries is avoided; also the function call itself is avoided.
Consider the taxRate macro from the previous section:
We define the taxRate logic as a Spark UDF which is identical to the Spark SQL Macro above:
// function registration
import java.time.ZoneId
spark.udf.register("taxAndDiscountF", {(prodCat : String, amt : Double) =>
import org.apache.spark.sql.catalyst.util.DateTimeUtils._
import java.time.ZoneId
val taxRate = prodCat match {
case "grocery" => 0.0
case "alcohol" => 10.5
case _ => 9.5
}
val currDate = currentDate(ZoneId.systemDefault())
val discount = if (getDayOfWeek(currDate) == 1 && prodCat == "alcohol") 0.05 else 0.0
amt * ( 1.0 - discount) * (1.0 + taxRate)
})Now consider the 2 queries:
// queries
val macroBasedResDF = sql("select prod, taxAndDiscountM(prod, amt) from global_temp.products")
val funcBasedResDF = sql("select prod, taxAndDiscountF(prod, amt) from global_temp.products")
val funcBasedRes = funcBasedResDF.collect
val macroBasedRes = macroBasedResDF.collect
In our testing we found the task times for the macro based query to be around 2-3 faster than the function based query
We support translation of Date, Timestamp and Interval values and translation of functions
from org.apache.spark.sql.sqlmacros.DateTimeUtils module.
Construction support:
new java.sql.Date(epochVal)is translated to Cast(MillisToTimestamp(spark_expr(epochVal)), DateType)`new java.sql.Timestamp(epochVal)is translated toMillisToTimestamp(spark_expr(epochVal))java.time.LocalDate.of(yr, month, dayOfMonth)is translated toMakeDate(spark_expr(yr), spark_expr(month), spark_expr(dayOfMonth))- we don't support translation of construction of
java.time.Instantbecause there is no spark expression to construct a Date value from long epochSecond, int nanos.
Certain Arguments must be macro compile time static values:
- there is no spark expression to construct a
CalendarInterval, so these must be static values. ZoneIdmust be a static value.
org.apache.spark.sql.sqlmacros.DateTimeUtils provides a marker interface for code inside Macros,
that is a replacement for functions in org.apache.spark.sql.catalyst.util.DateTimeUtils.
Use the functions with Date values instead of Int, Timestamp values instead of Long and Predef.String
values instead of org.apache.spark.unsafe.types.UTF8String values.
Other interface changes:
getNextDateForDayOfWeektakesStringvalues for thedayOfWeekparamtruncDate, truncTimestamptake String values for thelevelparam
We support translation for logical operators(AND, OR, NOT), for comparison operators
(>, >=, <, <=, ==, !=), string predicate functions(startsWith, endsWith, contains),
the if statement and the case statement.
Support for case statements is limited:
- case pattern must be
cq"$pat => $expr2", so no if in case - the pattern must be a literal for constructor pattern like
(a,b),Point(1,2)etc.
- You must import
import org.apache.spark.sql.sqlmacros.registered_macros- this implements scala language
Dynamictrait. - The Spark-SQL macro translator resolves method calls on this object against registered macros in the session.
- this implements scala language
We collapse org.apache.spark.sql.catalyst.expressions.GetMapValue,
org.apache.spark.sql.catalyst.expressions.GetStructField and
org.apache.spark.sql.catalyst.expressions.GetArrayItem expressions if
they are correspondingly on top of a CreateMap, CreateStruct or CreateArray
We also simplify Unwrap <- Wrap expression sub-trees.
We allow macro call-site static values to be used in the macro code.
These values need to be translated to catalyst expression trees.
Spark's [[org.apache.spark.sql.catalyst.ScalaReflection]] already
provides a mechanism for inferring and converting to catalyst expressions
(via [[org.apache.spark.sql.catalyst.encoders.ExpressionEncoder]]s)
values for supported types. We leverage
this mechanism. But in order to leverage it we need to stand-up
a runtime Universe inside the macro invocation. This is fine because
[[SQLMacro]] is invoked in an env. that has all the Spark classes in the
classpath. The only issue is that we cannot use the Thread Classloader
of the Macro invocation. For this reason [[MacrosScalaReflection]]
is a copy of [[org.apache.spark.sql.catalyst.ScalaReflection]] with its
mirror setup on org.apache.spark.util.Utils.getSparkClassLoader
Instead of developing a new builder capability to construct macro universe Trees for catalyst Expressions, we directly construct catalyst Expressions. To Lift these catalyst Expressions back to the runtime world we use the serialization mechanism of catalyst Expressions. So the [[SQLMacroExpressionBuilder]] is constructed with the serialized form of the catalyst Expression. In the runtime world this serialized form is deserialized and on macro invocation [[MacroArg]] positions are replaced with the Catalyst expressions at the invocation site.
The following macro definition(in a scala file) doesn't get translated.
val a = Array(5)
spark.registerMacro("intUDM", spark.udm((i: Int) => {
val j = a(0)
i + j
}))- Macro translation happens during the compilation of the above code snippet.
- at Macro translation time the value of
ais unknown
- at Macro translation time the value of
- For identifiers that are not macro params or are well-known symbols
(such as
java.lang.Math.abs) SQL Expression translation attempts to replace them with their value at macro compilation time by issuing a macro contexteval. This fails and so the overall macro translation falls back to registering a User-Defined-Function.
Note in spark-shell (in non :paste mode) the above will succeed because
val a = Array(5) is compiled before the spark.registerMacro(... code block.