Repoducibility of the following paper:
I'm rewriting it(basically loss function) but tensorflow has many restricts (like tensor can not be assigned and so on), so it might take days until you can download this code and run it. Previous code didn't get the accuracy as the PyTorch version that's why I decided to rewrite it :)
If you're also interested in this paper and want to implement it on TensorFlow, this repo could be a help. I will leave the problems and newest prograss in the final part. If anyone meet the same issues or have some suggestion please feel free to leave me a message or send me an email: [email protected], we can discuss a bit deeper.
This is a repo to implement this paper in TensorFlow: Real-Time.Seamless.Single.Shot.6D.Object.Pose.Prediction. The author is Bugra Tekin, Sudipta N, etc.
"We propose a single-shot approach for simultaneously detecting an object in an RGB image and predicting its 6D pose without requiring multiple stages or having to examine multiple hypotheses. The key component of our method is a new CNN architecture inspired by the YOLO network design that directly predicts the 2D image locations of the projected vertices of the object's 3D bounding box. The object's 6D pose is then estimated using a PnP algorithm."
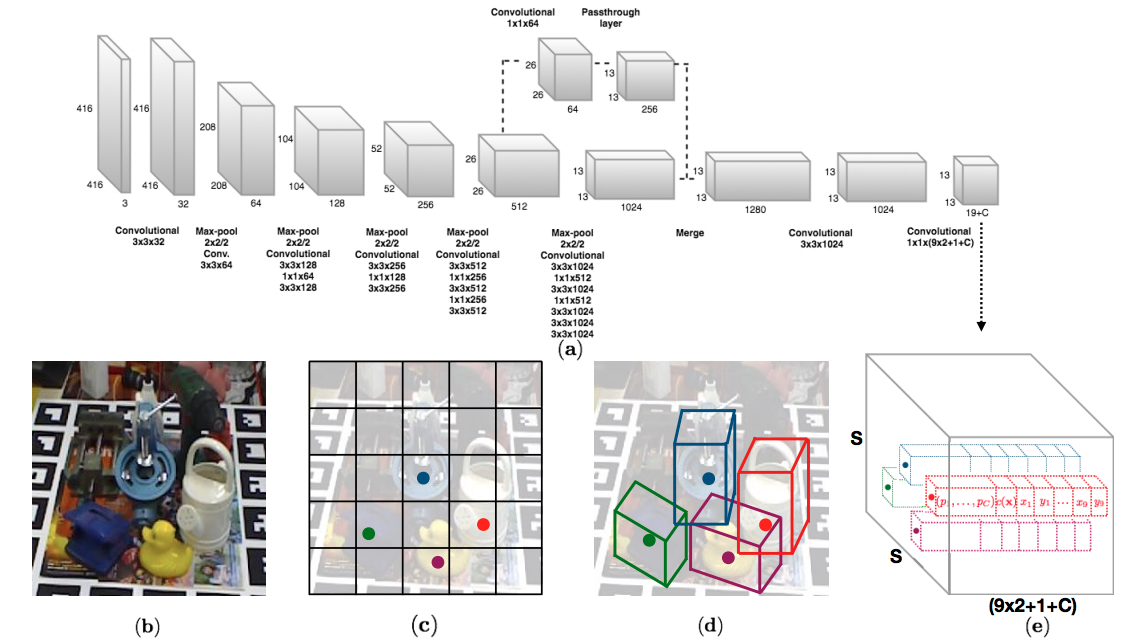
This code is test on Linux (ubuntu 16.04) with CUDA 9.0 and cudNN v7. This implementation is write on TensorFlow 1.8.0 using Python 3.5.3. To run this you need to install following dependencies with PIP or CONDA: Python 3.5.4, TensorFlow 1.8.0, Numpy 1.15.4, OpenCV 3.4.0.
This code use LINEMOD dataset. In training you also will be using VOC dataset for some reason, when you clone this repo and go inside the main directory, you can download datasets by typing:
wget -O LINEMOD.tar --no-check-certificate "https://onedrive.live.com/download?cid=05750EBEE1537631&resid=5750EBEE1537631%21135&authkey=AJRHFmZbcjXxTmI"
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
tar xf LINEMOD.tar
tar xf VOCtrainval_11-May-2012.tar
Because of the PyTorch .weights files cannot be used in TensorFlow, you can down load the COCO pre-trained .ckpt files here (For the IP issues i can't share the checkpoint files now, you can go to any tensorflow yolov2 repo and download the ckpt files, in general you just need to remove last layer and ckpt files can be used).
These weights had been trained on COCO dataset for classification. In paper, author use ImageNet pre-trained weights, I didn't test the difference. Hope someone can try it and give us some advices.
Because of in early iterations pose estimations are inaccuracy, the confidence value would be vary widely, so author suggested pre-train the model by changing the CONF_OBJ_SCALE = 0 and CONF_NOOBJ_SCALE = 0, to achieve this, run:
python train.py --datacfg cfg/ape.data --pre True --gpu 2
the first argv datacfg represents the catogories of dataset, second argv pre represents if it is pre training.
When finish pre-train and set the right .ckpt files(make sure the name, path correct), run below to train the model
python train.py --datacfg cfg/ape.data --gpu 2
After training, run
python valid.py --datacfg cfg/ape.data
to see the result and accuracy.
I finish the pre-train step (it gets good accuracy on classification), but in training, I didn't get such a good result, the coordinates loss has been down to 0.0x level, but predict coordinates are even can't perfectly match the ground truth, I think loss function may be on blame, I am rewriting it by duplicating PyTorch version (directly duplicate can't be running so I changed a lot). If you find any incorrect of code, please send me an email [email protected], I will be very appreciate that. The valid.py file is not finished yet, it now just to check whether pictures is predicted correctly. Also, I just test the model using single object, the occlusion part will be later uploaded to this repo
Thanks for reading Fan