Index Skip Scan
Postgres currently has a simple implementation of traversing a btree. It starts at the root and traverses the tree from top to bottom. When it reaches the leaf it starts scanning horizontally. It will continue scanning until the end of the index or when it knows remaining tuples can never match the WHERE clause. Details about the current implementation are well described on this page.
The proposed patch aims to improve scans involving WHERE-clauses on non-leading index columns, as well as queries involving a DISTINCT-clause.
Suppose we have a multi-column index that looks (simplified) like the following picture. The index has two columns a and b.
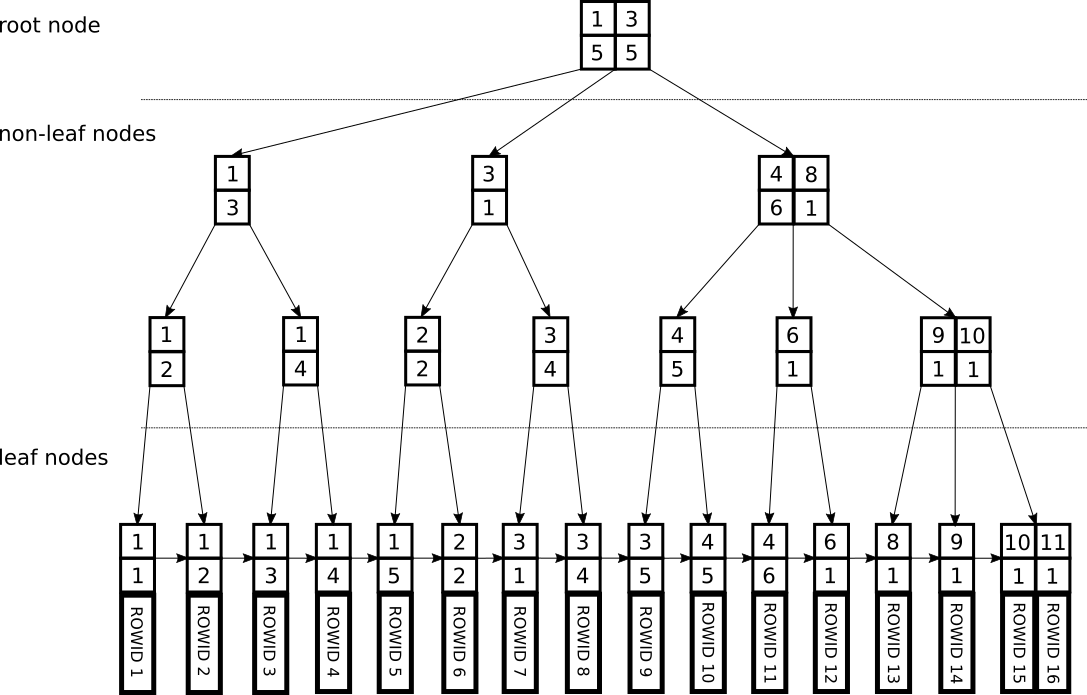
SELECT * FROM tbl WHERE b=3
When filtering on b=3, the current implementation would descend downwards to the left-most tuple, after which it would scan the full index.
The skip implementation would scan differently. First of all, it divides the index tuple in two parts. The prefix and postfix part. In this example, the prefix would be column a, and the postfix column b. Given a certain prefix, it can start a scan from the root, including extra conditions that become available. In this example:
- Scan from the root down to the first tuple
(1,1) - Knowing that the prefix is 1, we can now start a scan from root for
a=1 AND b=3. We end up at tuple(1,3) - Next tuple is
(1,4), which means it is now impossible to find any more matching tuples within the prefix ofa=1. We start again from the root to find the first tuplea>1. - We find the next prefix is 2, so our next scan from root will be
a=2 AND b=3. We end up at tuple(3,1). This is not equal to the prefix we were looking for! This means there must be no matching tuple witha=2. - We restart a scan from root for
a=3 AND b=3. We find(3,4). This does not match either and we can be sure there are no other matches within prefix 3, so we can start another scan from root fora>3. This continues until the end of the index.
SELECT * FROM tbl WHERE b BETWEEN 3 AND 5
- Scan from root to find first tuple
(1,1) - Scan from root with condition
a=1 AND b>=3 - Find
(1,3). Scan further right and find(1,4)and(1,5). - One more right finds you
(2,1), which is not equal to the prefixa=1anymore. The new prefix isa=2and we search from root fora=2 AND b>=3. - We find
(3,1). This is again a new prefix, so we search from root fora=3 AND b>=3. We find(3,4). This continues until the end of the index.
SELECT DISTINCT ON (a) * FROM tbl WHERE b BETWEEN 3 AND 5
This works very similarly to the case described above. The only difference is that once a tuple for a certain prefix has been found, we force a skip to the next prefix. For example, after finding (1,3), we don't continue searching, but skip over a>1 instead.
From the examples above, we can derive a few basic actions that we can take at any point in time when looking for a next tuple:
- Given the current tuple, we can move horizontally to the next tuple.
- Given the current tuple, we can restart from the root searching for the condition
prefix columns >= current tuple + possibly extra scan conditions. Effectively, we skip within the current prefix to the next suitable tuple. - Given the current tuple, we can restart from the root searching for the condition
prefix columns > current tuple. Effectively, we skip to the next prefix.
- In real life, the Postgres implementation is much more complex than the conceptual description above. One of the differences is that tuples are always clustered together on a page and we need to read the full page at once. This leads to more complexity. It also allows for some optimizations.
- There are many corner cases in determining the next basic action that needs to be taken after having read a page. It depends on the prefix that we're currently looking at, the tuples on the page and other scan conditions we have.
- There are also many corner cases in determining the next scan key to scan from root. It is a combination of the current tuple and the scan conditions.
- A special case of a scan is the
CURSORscan. This allows fetching tuples forwards and backwards. The behavior for this is different forDISTINCTthan for regular index scans that scan all tuples.