Sentimental Analysis is the process of computationally identifying and categorizing statements made from a piece of text and determine whether the author’s feelings toward a particular product is positive, negative or neutral. It is very vital for Industrial leaders like Amazon with their giant E-Commerce business to understand consumer behaviour and their sentiment to reach out better to them. With recent developments in the field of machine learning and text analytics this could be effectively achieved. In this project we aim to predict the sentiment or polarity of a review given to a particular amazon baby product using supervised machine learning algorithms. Based on that we will compare the performance of each of the approaches used and comment on the best approach for such applications.
Dataset [http://jmcauley.ucsd.edu/data/amazon/]
The Dataset used is from the official amazon product data hosted in the link above and is provided by researchers from UCSD. This Review dataset contains the following features in JSON format:
- reviewerID - ID of the reviewer, e.g. A2SUAM1J3GNN3B
- asin - ID of the product, e.g. 0000013714
- reviewerName - name of the reviewer
- helpful - helpfulness rating of the review, e.g. 2/3
- reviewText - text of the review
- overall - rating of the product
- summary - summary of the review
- unixReviewTime - time of the review (unix time)
- reviewTime - time of the review (raw)
As part of the data pre-processing and preparing the training data for classifiers we would be first splitting the reviews based on the polarity to positive and negative classes. Also we will use the NLTK in python for the purpose of lemmitizer and removal of stop words to clean the data.
We will be applying the following approaches to perform sentimental analysis on the Amazon baby products review dataset. We will compare the approaches individually and analyze their performance metrics using parameters such as accuracy, precision, recall and F1- score.
- K-Nearest Neighbour
- Support Vector Machine
- LSTM with Word2Vec
- LSTM with Glove Model
- Multionomial Naive Bayes Classifier
- Logistic Regression
- Adaboosting
Accuracy of Classifiers on Original Data where Positive Reviews were Greater than Negative Reviews
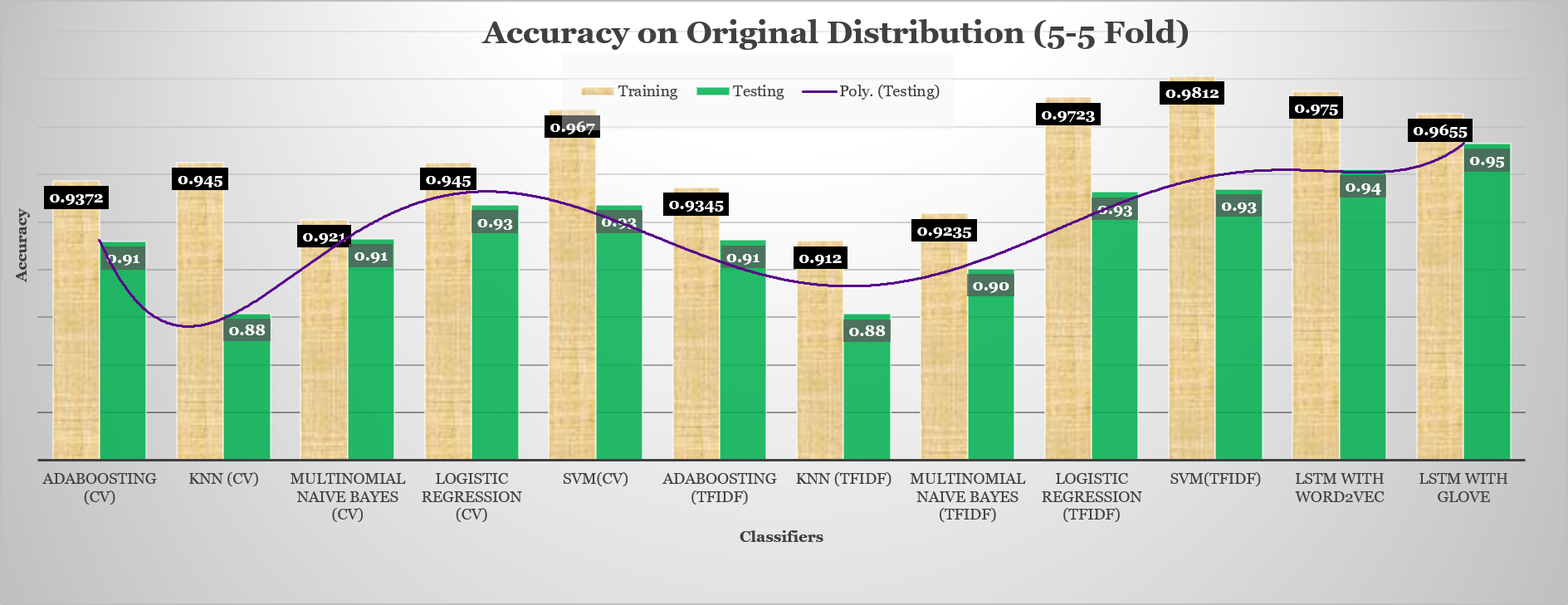{kind=link}
Accuracy of Classifiers on Balanaced Data where Positive Reviews are Equal to the Negative Reviews
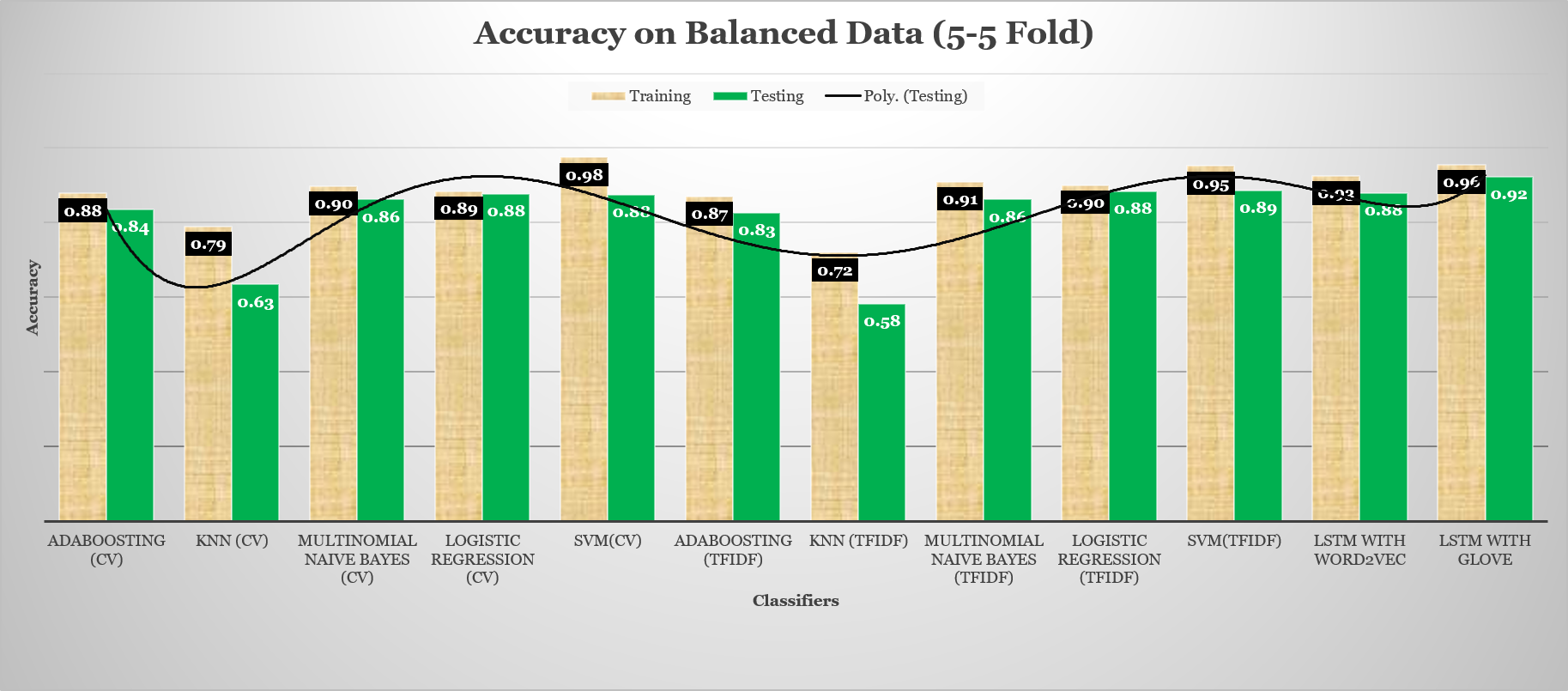{kind=link}