Try the public beta: https://testflight.apple.com/join/neaw91ke


- Introduction
- App architecture
- "Point Light Casters" Demo
- "Infinite Space" Demo
- "Apple Metal" Demo
- "Skeleton animations and cascaded shadows" Demo
This is my first iOS app and a playground for me to explore Swift and the Apple Metal rendering API.
This project has no external libraries: all animations, physics and graphics are written from scratch. I worked on it in my spare time for almost 2 months, learning a ton about Swift, Metal and different rendering techniques in the process. For studying I used these resources (in the following order):
Coming from web development with Javascript and WebGL / WebGPU, this project was really fun to do as my first iOS app.
The app is made up by two layers:
- Very thin SwiftUI UI layer, compromising mostly of buttons and text
- A Metal view responsible for drawing the graphics and animation and also capturing and reacting to user inputs such as clicks and dragging.
These two layers communicate with each other by using published properties via Combine's ObservableObject which acts as a central dispatcher and automatically announces when changes to its properties have occured.
Let's assume that this object definition looks like this:
class Options: ObservableObject {
@Published var activeProjectName: String = WelcomeScreen.SCREEN_NAME
}A good example would be:
- The user clicks on the homescreen menu drawn by the Metal layer, bounding box detection is performed on the polygons formed by the vertices and the correct demo to be opened is determined.
- The Metal layer opens the demo with an animation and dispatches the name of the clicked demo as a string to
activeProjectNameproperty insideOptions. - The SwiftUI layer observes the change of
activeProjectNameinside theObservableObjectand displays the demo name, "Back" and "Demo Info" buttons on top with a subtle animation. - When the user clicks on the "Back" button inside the SwiftUI layer, the
activeProjectNameis set tonilinside theObservableObject. This change is observed by the Metal layer which closes down the active demo with an animation.
And here are these steps visualised:


The visuals of this demo are borrowed from this Threejs example. I really like the interplay of shadows and lights so was curious to implement it via the Metal API.
It renders a cube with front face culling enabled and two shadow casters represented by cut off spheres.
Metal has no preprocessor directives, rather it uses function constants to permutate a graphics or a compute function. Since Metal shaders are precompiled, different permutations do not result in different binaries, rather things are lazily turned on or off conditionally upon shader pipeline creation.

The sphere above is made of three drawcalls, using three different pipelines backed by the same vertex and fragment shaders. Each pipeline permutation has different inputs / outputs and codepaths toggled by function constants:
- Front part of the sphere - has a gradient as color and is cut-off along the Y axis
- Back side of the sphere - has a solid white as color and is cut-off along the Y axis
- Center part - another sphere with a solid white as color and no cut-off
The function constants look like this:
constant bool is_sphere_back_side [[function_constant(0)]];
constant bool is_shaded_and_shadowed [[function_constant(1)]];
constant bool is_cut_off_alpha [[function_constant(2)]];Later on in the shader code these values can be used to achieve the different spheres look. For example, to cutoff a sphere the code might look like this:
fragment float4 fragment_main() {
// ...
if (is_cut_off_alpha) {
float a = computeOpacity(in.uv);
if (a < 0.5) {
discard_fragment();
}
}
}Point shadow casting is straightforward and hardly a new technique: we place a camera where the light should be, orient it to face left, right, top, bottom, forward and backwards, in the process rendering each of these views into the sides of a cube depth texture. We then use this cube texture in our main fragment shader to determine which pixels are in shadow and which ones are not. Nothin' that fancy.

The Metal API however makes things interesting by allowing us to render all 6 sides of the cube texture in a single draw call. It does so by utilising layer selection. It allows us to render to multiple layers (slices) of a textture array, 3d texture or a cube texture. We can choose a destination slice for each primitive in the vertex shader. So each sphere is rendered 6 times with a single draw call, each render done with a different camera orientation and its result stored in the appropriate cube texture side.

- THREE.PointLight ShadowMap Demo
- Rendering Reflections with Fewer Render Passes
- Learn OpenGL - Point Shadows

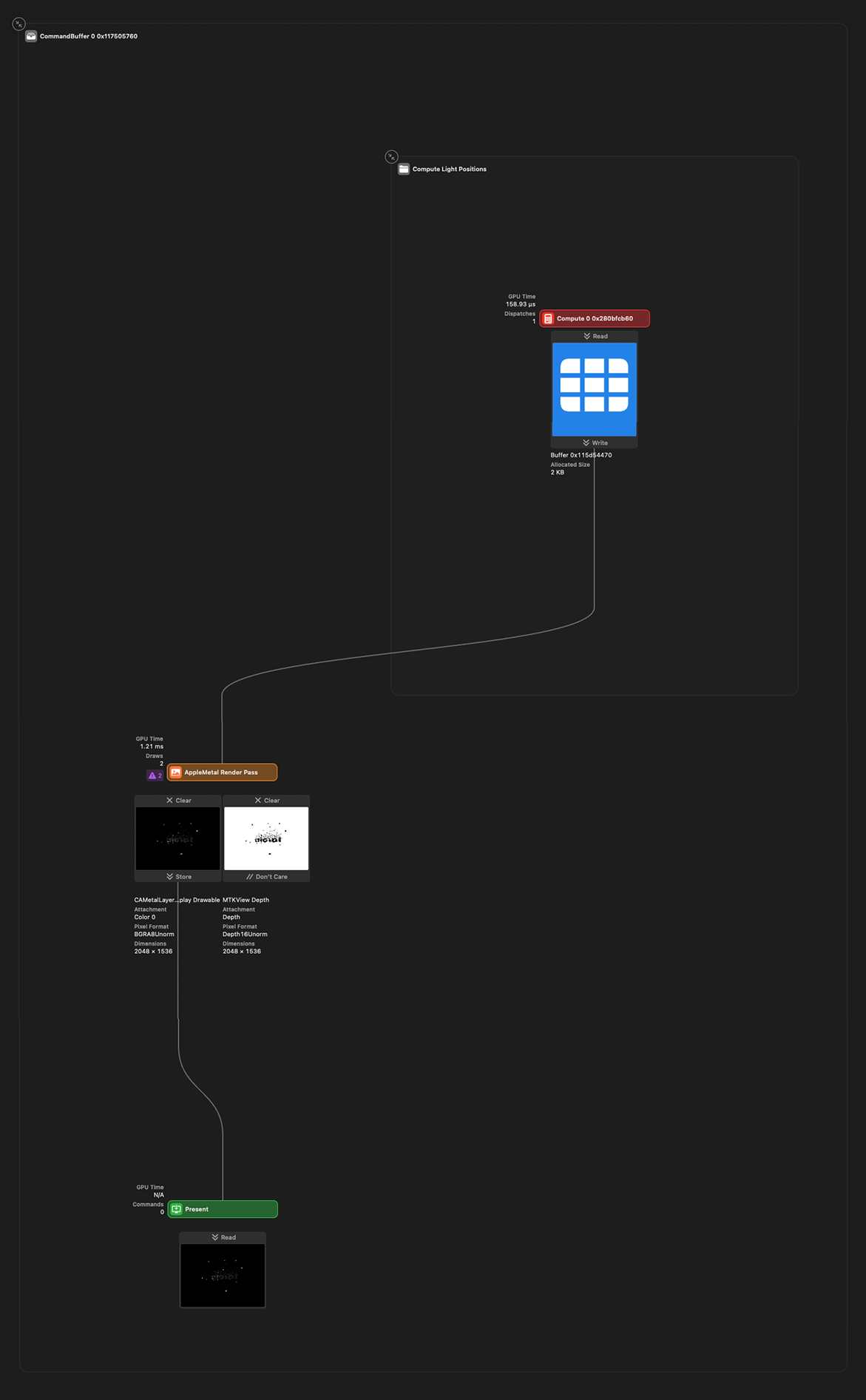
This demo renders 3000 boxes lighted by 300 point lights. It uses compute shaders to animate the boxes / lights positions on the GPU and deferred rendering to decouple scene geometry complexity from shading. It takes advantage of modern tile-based architecture on Apple hardware. Each point light is represented as a solid colored sphere, rendered to the framebuffer with additive blending enabled.
In traditional deferred rendering we render our intermediate G-Buffer textures to video memory and fetch them at the final light accumulation pass.
However tile-based deferred rendering (TBDR) capable GPUs introduce the concept of tile memory:
Tile memory is fast, temporary storage that resides on the GPU itself. After the GPU finishes rendering each tile into tile memory, it writes the final result to device memory.
Here is how it looks in Xcode debugger:

The three textures on the right are transient and stored in "tile memory" only. They are marked as "Don't care", so they are discarded after the render pass is completed. The right one is the final render submitted to device memory (marked as "Store"). The textures on the right are written to and sampled from by the texture on the left all in the same pass!
From left to right we have the following G-Buffer textures:
-
G-Buffer output texture. Storage mode is
Store, as we want this texture stored in video memory in order to show it on the device screen. It usesBGRA8Unormpixel color format as this is the pixel format of the backing metal view (MTKView.colorPixelFormat). -
Normal + Shininess + Base Color with
RGBA16Floatpixel format. Storage mode is.memorylesswhich marks it as transient and to be stored in tile memory only2.1. The normal is tightly packed into the first 2
rgchannels and unpacked back into 3 channels in the final step2.2. Shininess is packed into the
bchannel2.3. And finally, the base color is encoded into the last
achannel. You may ask yourself how can an RGB color be encoded into a single float and it is really not. Rather all of the boxes use the same float value for their RGB channels. Perhaps Color is not the best word here? -
Position + Specular with
RGBA16Floatpixel format. Storage mode is.memorylesswhich marks it as transient and to be stored in tile memory only3.1. The XYZ position is encoded into the
rgbcomponents3.2. Specular into the remaining
acomponent -
Depth texture with
DepthUNormpixel format. Storage mode is.memorylesswhich marks it as transient and to be stored in tile memory only
Here is how they are created in Swift code:
outputTexture = Self.createOutputTexture(
size: size,
label: "InfiniteSpace output texture"
)
normalShininessBaseColorTexture = TextureController.makeTexture(
size: size,
pixelFormat: .rgba16Float,
label: "G-Buffer Normal + Shininess + Color Base Texture",
storageMode: .memoryless
)
positionSpecularColorTexture = TextureController.makeTexture(
size: size,
pixelFormat: .rgba16Float,
label: "G-Buffer Position + Specular Color Base Texture",
storageMode: .memoryless
)
depthTexture = TextureController.makeTexture(
size: size,
pixelFormat: .depth16Unorm,
label: "G-Buffer Depth Texture",
storageMode: .memoryless
)
- Metal Docs - Tile-Based Deferred Rendering
- The Arm Manga Guide to the Mali GPU
- Compact Normal Storage for small G-Buffers

While this is arguably the easiest demo technically, I had the most fun creating it. It features particles with simple verlet physics and transitions between the words "APPLE" and "METAL". The particle and lights movement is animated on the GPU via compute shaders. The particles are colored by the lights via Phong shading.
The words particles positions were created by rendering text via the HTML5 <canvas /> API and scanning it's positions on a 2D grid and storing them in a Javascript arrays. The resulting 2D grid positions were exported from JS to Swift arrays.

This demo features directional lighting and a PBR surface model, albeit mostly copy-pasted from LearnOpenGL and ported to the Metal Shading Language. The models are loaded and parsed from USDZ files and the appropriate textures are used in each step of the lighting equations.
The skeleton animations for each model are loaded and can be mixed, played at different speeds etc.
CSM is an upgrade to traditional shadow mapping and addresses its few shortcommings, mainly the fact that it is difficult for the rendering distance to be large (think open world games for example), due to the limited shadow texture resolution size. As the rendering distance gets larger, increase in the shadow texture size is required, otherwise shadows gets less precise and more blocky. A shadow texture resolution can realistically be increased only so much on modern day hardware, especially mobile, so a better solution is needed.
CSM is a direct answer to that. The core insight is that we do not need the same amount of shadow detail for things that are far away from us. We want crisp shadows for stuff that’s near to the near plane, and we are absolutely fine with blurriness for objects that are hundreds of units away: it’s not going to be noticeable at all.
To do that, we divide our camera frustum into N sub-frustums and for each sub-frustum render a shadow map as seen from the light point of view. Send the resulting shadow map textures to the fragment shader and sample from the correct shadow map texture using the fragment depth value.
The scene in this demo is separated into three sections:

The red section will get the best shadow quality as it's nearest to the viewer camera. Next is green and then blue: these two levels will get progressively less shadow detail as they are further away.
You may have noticed the 3 shadow textures displayed in the bottom left for debugging purposes. Here is a better view of them:

The whole scene is rendered into three separate shadow map textures. The trick here is the same as in the first demo - we are able to render the whole scene into the 3 different texture slices in a single draw call via Metal layer selection. We can select with CSM shadow cascade to render to in dynamically in the vertex shader.
Additional Percentage Close Filtering is applied to the shadows to reduce aliasing.
