http://cpp-lang.sevendays-study.com/day0.html
1972年にC言語が開発されると、瞬く間に各方面で利用されるデファクトスタンダードの言語となりました。しかし、それにつれ、この言語の問題と限界が露呈するようになりました。
そのひとつは、C言語は、大規模な開発には、必ずしも向かないということです。時代の変化とともにコンピュータの性能が向上すると、多数のプログラマが参加する大規模開発が主流になってきました。しかし、C言語はそういったプログラミングを行ううえでは、必ずしも効率的な言語とはいえませんでした。そこで、C言語にオブジェクト指向的な拡張を施したC++(シー・プラス・プラス)言語が開発され、利用されるようになったのです。
C++言語について詳しく説明する前に、オブジェクト指向とは何かということについて詳しく説明していきましょう。
オブジェクト指向の「オブジェクト」とは、英語で「もの」とか「物体」などを表す言葉で、データを現実世界のものに置き換える考え方です。
たとえば、オブジェクト指向プログラミング言語で、テレビを操作するプログラムを作成したと仮定します。そのとき、オブジェクト指向では、テレビを象徴する「テレビ」というオブジェクトを用意します。また、「テレビ」には、「スイッチを入れる」、「チャンネルを変える」などといった動作が伴います。これら動作のことを「メソッド」と言います。
オブジェクト指向では、これら「オブジェクト」とその動作である「メソッド」の組み合わせと、その相互作用でプログラムを記述します。
このような考え方が、現在のプログラミング言語の考え方の主流なのです。現在、主なオブジェクト指向言語には、以下のようなものがあります。
ここでは、C++言語の特徴について説明します。一般に。C++言語には、以下の長所・短所があるといわれています。簡単にまとめると、以下のようになります。
C++言語の長所 C言語と互換性があり、ソースコードを再利用できる。 他のオブジェクト指向言語と違い独自のフレームワーク必要とせず、ネイティブコードを得られる。 C言語よりもセキュリティの面が優れている。 これに対し、デメリットとしては以下のようなものがあげられます。
C++言語の短所 他の言語に比べ、言語使用が複雑。 標準で利用できるライブラリが少ない。 メモリ管理機能(GC機能)が存在しない。 といった点が挙げられます。
実行結果からもわかるとおり、このプログラムを実行すると、"HelloWorld."という文字列が表示されます。見てみると、namespace,coutなど見慣れない記述が多いことがわかります。
すでに述べたとおり、C++言語は、あくまでもC言語を拡張したものであることから、printf()関数などを用いてコンソールに文字列を表示することが出来ます。しかし、ここではあえて、C++言語特有の方法で行ってみることにします。
では、一体、このプログラムはどのような仕組みになっているのでしょうか?ここでは、C言語との違いを中心に見てみましょう。
1行目に出てくる、#includeは、C言語同様、ヘッダファイルと呼ばれるファイルを読み込むときに用いる宣言です。ここで読み込むファイルは、iostreamというファイルです。これは、ヘッダファイルですが、C++の場合のものであり、C言語の時のように".h"は、必要ありません。そのため、C言語のヘッダファイルと一線を画すため、単にヘッダと呼ばれます。
C言語では、ヘッダファイルを呼び込むことにより、様々な関数を利用できるようになりましたが、C++の場合は、ヘッダを読み込むことにより、クラスを利用できるようになるといった違いがあります。(詳細は後述)
3行目のusing namespace std;の部分ですが、using namespaceは、指定された名前の名前空間を使うことを意味しています。詳細は後述しますが、名前空間とは、C言語には存在せず、C++言語から用いられるようになった重要な概念です。
次に出てくる、coutは、ここで定義されているものです。したがって、利用するためには、「標準名前空間を利用する」という宣言としてこの一文が必要になるわけです。
続いて、プログラムの中身に移ります。C++言語では、printf()関数と同じような働きをするものとして、coutが用意されています。
coutは、C言語で用いた関数のようなものではありません。見た目は似ていますが、実はオブジェクトと呼ばれるもので、特に標準入出力の出力をつかさどるものなのです。
C++言語の入出力ストリームでは、>>および、<<を用いることにより、ストリームと呼ばれる対象に対するデータのやりとりを行います。ここでは、coutを通じて、巣津力ストリームに、文字列"HelloWorld."を送り出しているわけです。
最後のendlは改行を表します。C言語で用いた¥nも利用可能ですが、C++で、coutを用いる場合は、こちらが一般的です。
ではここで、名前空間とは何か、という概念について説明しましょう。C++言語とC言語の大きな違いのひとつは、C++言語が、あらかじめ大規模開発を意識して作られている言語だという点があります。
大規模開発とは、大勢の人間がひとつのソフト・アプリケーションを開発することで、その場合問題になってくるのが名前の重複です。その場合、ひとつの単語が変数名などとして用いられると、ほかの開発者はそれを利用できなくなり、大変不便です。
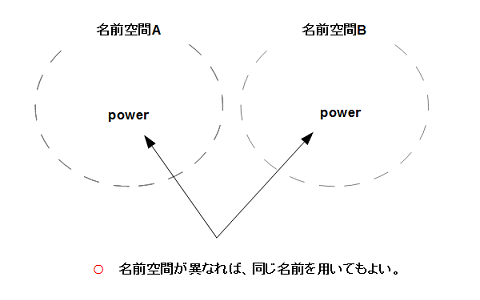
そこで、名前空間という概念を用意し、名前空間が違えば、同じ名前を用いてもよい、というルールを作ったわけです。たとえば、ゲームの開発現場で、二人のプログラマーがたまたまpower変数を使用していたとします。
このとき、プログラマーAが、この変数をプレイヤーの力として、プログラマーBがモンスターの力としてこの変数を用いていたならば、プレイヤー、モンスターのそれぞれの名前空間をあらかじめ別々に用意しておけば、こういった問題は発生しません。(図1-1)
続いて、コンソールから数値を入力し表示するという簡単なサンプルを紹介しましょう。まずは、以下のプログラムを実行してください。
#include <iostream>
using namespace std;
int main(){
int a;
cin >> a;
cout << "a=" << a << endl;
return 0;
}$ ./input
5
a=5実行結果からわかるとおり、キーボードから入力した数値をそのまま出力しています。ここで出てくる、cinも、標準名前空間に含まれるものの一つです。C言語であれば、scanf()関数に相当する処理です。
7行目で、キーボードから数値の入力を受け付けています。値は整数型変数aに代入され、8行目で表示されています。coutでは、連続していくつものものを表示する場合、間を<<ではさみます。そのため8行目では、"a="、変数aの値、改行(endl)の順で出力されるわけです。
このことからわかるとおり、C++においては、C言語のprintf()のように、%dや¥nといった記述はほとんど必要ありません。利用することは皆無ではありませんが、C言語に比べればはるかに少なくなっています。
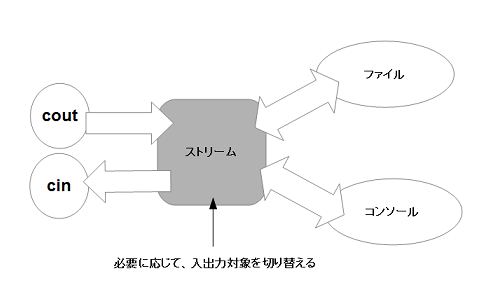
最後に、ストリームの概念について説明して終わることにしましょう。ここまで読むと、coutや、cinは、単純に、C言語のprintf()関数や、scanf()関数の代わりと思われるかも知れませんが、実は違います。
これらは、ストリームと呼ばれるものに対し、データ(数値や文字列など)を送り込んだり、逆に受け取ったりするものなのです。ストリームとは、英語で渓流などを表す言葉で、「流れ」という意味で用いられています。
つまり、cinや、coutは、その”流れ”からデータを受け取ったり、送り込んだりするわけです(図1-3)。不等号の向きは、その流れの向きを表すわけです。そして、そのストリームの行き着く先は、今回のサンプルのようなコンソールだったり、ファイルシステムだったりするわけです。これにより、ファイルへの読み書きと、コンソールからの入力・出力の処理がほとんど同じような記述で行うことが出来るのです。
C++言語では、文字列の操作を行うstringというクラスが存在します。クラスとは何かという説明は後ほど出てくるので、ここでは省略します。ただ、これをcinおよびcoutと合わせて使うと大変便利で、char型の配列を用いて文字列の操作を行っていたC言語に比べれば、大変楽なので、まずはそのことについて解説します。
#include <iostream>
#include <string>
using namespace std;
int main(){
string s,t;
t ="入力された文字は、";
cout << "文字列を入力:";
cin >> s;
cout << t+s << "です。" << endl;
return 0;
}文字列を入力:Hello ←キーボードから入力
入力された文字は、Helloです。実行すると「文字列を入力:」と出力され、入力待ち状態になります。ここで、任意の文字列を入力し、Enterを押すと、「入力された文字列は○○です。」と出ます。見てわかるとおり、C言語で同様のプログラムを作るときよりも、数段簡単ですし、cin、coutの記述方法は、intのときとまったく変わりません。これが、C++のストリームを利用する際の魅力のひとつです。
また、文字列を扱うには、まず2行目のように、ヘッダファイルstringをインクルードする必要があります。これは、C言語のヘッダファイルであるstring.hとは違うので、注意が必要です。値への代入は、9行目、10行目のように、=(イコール)演算子を用いて行うことができます。
また、13行目のように、+(プラス)演算子を用いて、文字列同士をつなげることが可能です。このように、C言語とは違い、文字列の操作が簡単にできることがC++言語の特徴です。stringでは、以下の表2-1のように演算子を用いて文字列を操作することが可能です。
| 演算子 | 意味 |
|---|---|
| + | 文字列同士の足し算 |
| += | 文字列同士の足し算(代入演算) |
| == | 比較演算(同等の内容) |
| != | 比較演算(内容が異なる) |
| > , < | 比較演算(大小) |
この章から先は、クラスと呼ばれるデータ構造を使用したプログラムを行います。すでに述べたとおり、オブジェクト指向プログラミングでは、クラスは必ず登場します。C++言語におけるクラスは、その構造だけを見ると、C言語の構造体とよく似ています。構造体は、複数の変数を1つにまとめ たものでした。配列と違い、それぞれの変数はデータ型が異なっても構いません。
それに対し、クラスは、構造体の中に、さらに関数まで加えたものだといえばわかり易いでしょう。つまり、メンバとして変数と関数の両方を含めることができるという構造です。変数の方をメンバ変数、関数の方をメンバ関数と呼びます。クラスと構造体の違いは、これだけではありませんが、その他の違いについては、今後少しずつ説明していきます。
では、実際にC++言語のクラス宣言を見てみましょう。
class CSample
{
public:
void function();
private:
int m_num;
};最初に付けるclassは、クラス宣言をすることを意味するものです。構造体のstructと同じような役割を果たしています。CSampleはクラスの名前です。
構造体の場合と同様、クラスの構成要素は、メンバと呼ばれます。これには、メンバ変数とメンバ関数とがありますが、普通の変数宣言や、関数プロトタイプの書き方と同じです。ここで宣言されるので、外側にプロトタイプ宣言を書く必要はありません。
このサンプルでは、メンバ変数として、m_numが、メンバ関数としてfunction()が定義されています。また、特にメンバ関数のことを、メソッドとも呼ばれます。
また、ここで出てくる、publicとprivateというキーワー ドは、アクセス修飾子(しゅうしょくし)と言います。詳細は後で説明します。今のところは、メンバ関数の宣言の前にpublic、メンバ 変数の宣言の前にprivateと書くと思っておいて下さい。もし、メンバ変数やメンバ関数が複数ある場合、次のようになります
class CSample
{
public:
void function();
int function2();
private:
int m_num;
char* m_str;
};続いて、簡単なサンプルプログラムを通して、実際にクラスおよびオブジェクトをどのように活用するかについて説明しましょう。実際にこのクラスを利用するには、まずクラスの変数を宣言します。これは構造体変数を宣言するのと同じことです
CSample obj; // CSampleクラスの変数objを宣言通常、これらはインスタンスとかオブジェクトなどといいます。オブジェクト指向という言葉は、このオブジェクト から来ている訳ですが、オブジェクトという言葉は、場面によって様々に意味を持ち得るため分かりにくい場合があります。そのため本サイトでは、クラスから生成されたものを、インスタンスという言葉で記述することにします。
クラスのインスタンスを生成することをインスタンス化、もしくはインスタンスの生成などといいます。なお、「インスタンス」という言葉には「実体」という意味があり、 「インスタンス化」は「クラスを実体化する」という意味があるのです。
「クラス」はそのままでは単なる「型」に過ぎ ないので、使うには実体化する必要があるということです。メンバ変数やメンバ関数を使うとき(アクセスするとき)も、構造体と同じで、ドット演算子(.)を使います。また、インスタンスへのポインタを経由するときはアロー演算子(->)を使います。
では実際に、簡単なサンプルプログラムを通してみてみましょう。
#ifndef _SAMPLE_H_
#define _SAMPLE_H_
// クラス宣言
class CSample
{
public:
void set(int num); // m_numに値を設定する
int get(); // m_numの値を取得する
private:
int m_num;
};
#endif //_SAMPLE_H_#include "sample.h"
void CSample::set(int num)
{
m_num = num;
}
int CSample::get()
{
return m_num;
}#include <iostream>
#include "sample.h"
using namespace std;
int main()
{
CSample obj; // CSampleをインスタンス化
int num;
cout << "整数を入力して下さい:" << endl;
cin >> num;
obj.set( num ); // CSampleのメンバ変数をセット
cout << obj.get() << endl; // メンバ変数の値を出力
return 0;
}整数を入力して下さい:5 ← キーボードから数値を入力
5実行結果を見れば判る通り、キーボードから入力された数値がそのまま出力されています。
##### プログラムの概要
では、ここでプログラムの概要を見ていきましょう。まずは、ファイルの依存関係を見ていきましょう。通常、クラス宣言は、ヘッダファイルの中で行います。そのためここでは、sample.hの中で、クラスの定義がなされています。このヘッダファイルは、実装を行う、sample.cppおよび、このクラスを利用するmain.cppで参照されます。
ヘッダファイルの内容がクラスの定義になったということと、ソースファイルの拡張子が、.cppに変わった以外は、ほぼC言語の場合と同じです。
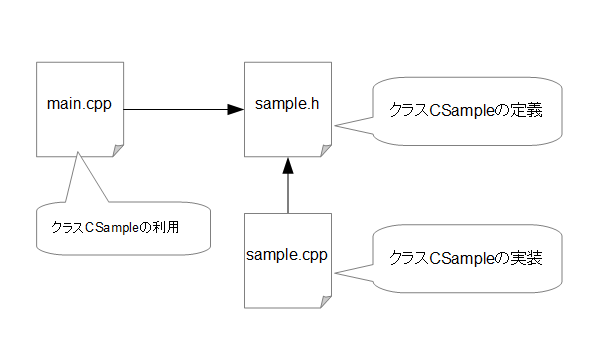
通常、ヘッダファイルのファイル名は、クラスの名前と対応した名前がつけられるのが一般的です。この例だと、ファイル名がsample.hであることから、クラス名は、CSampleとなっています。
また、このファイルはヘッダファイルであることから、C言語の場合と同様に、#ifndef、#define、#endifマクロで二重インクルードの防止処理が施されています。この規則に関しては、C言語の場合とまったく同様のルールが適用されます。
C言語のプロトタイプ宣言にあたる部分は、C言語のメンバ関数の宣言の中に記述されています。ただ、実装は、対応する.cppファイルの中でなされています。ここでは、sample.cppの中で記述されています。
メンバ関数の定義の仕方は、通常の関数とそれほど変わりません。ただ、関数名だけでは、何というクラスのメンバ関数 なのかが分からないので、関数名の頭にクラス名を付け::を挟みます。CSample::setなら、CSampleクラスのsetメンバ関数 ということになります。その他のメンバ関数についても、同様です。(表2-1参照)
表2-1:CSampleクラスのメンバ関数の宣言と、実装の組み合わせ
| 宣言 | 実装 |
|---|---|
| void set(int num) | CSample::set(int num) |
| int get() | int CSample::get() |
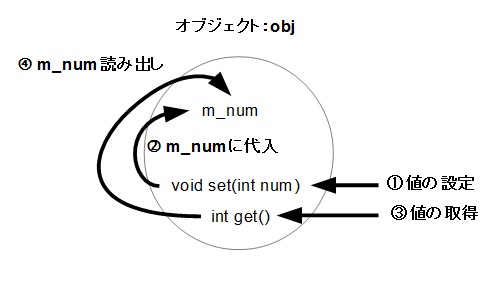
このプログラムは、キーボードから入力された整数を、一旦メンバ変数に記憶してから、それを出力するという 非常に単純な例です。入力された値は、ローカル変数numに格納してから、setメンバ関数を使って、メンバ変数に記憶しています。この一連の処理の流れを、図にすると、以下のようになります。(図2-2.)
list2-1だけを見る限りでは、「C言語と違い、随分と面倒くさいことをするものだな」と思うかもしれません。C言語であれば、変数と関数を定義し、呼び出すことによって、このような処理は簡単に処理できますし、コードももっと短くなるでしょう。
しかし、このようなプログラムのメリットは、実はすでに述べた通り、インスタンスを複数作ることができることにあるのです。まずは、以下のlist2-2を入力し、実行してみてください。なお、これを使用するにあたり、sample.hおよび、sample.cppは、list2-1のものをコピーしてそのまま利用して下さい。
#include <iostream>
#include "sample.h"
using namespace std;
int main(){
CSample obj1,obj2; // CSampleのインスタンスを複数生成
obj1.set( 1 ); // obj1のsetメソッド呼び出し
obj2.set( 2 ); // obj1のsetメソッド呼び出し
cout << obj1.get() << endl; // obj1のメンバ変数の値を出力
cout << obj2.get() << endl; // obj2のメンバ変数の値を出力
return 0;
}このプログラムでは、obj1およびobj2という二つのインスタンスを作っています。実行結果からわかる通り、同じメソッドにアクセスし、同じメンバ変数に値を入れていますが、それぞれの実行結果は異なります。
これは、同じ名前のメンバ変数、メンバ関数であっても、インスタンスが異なれば別物であることを意味します。たとえば、obj1.set(1)とすれば、obj1のm_numが1になりますが、obj2のm_numにはなんら変化は起こりません。
同様に、obj1.get()を実行しても、値がとられるのはあくまでも、obj1.m_numであり、obj2とは、なんら関係ありません。このように、同じ名前がついたインスタンス変数やインスタンス関数であっても、インスタンスが異なれば別物であるというのが、オブジェクト指向最大の特徴です。(図2-3.参照)
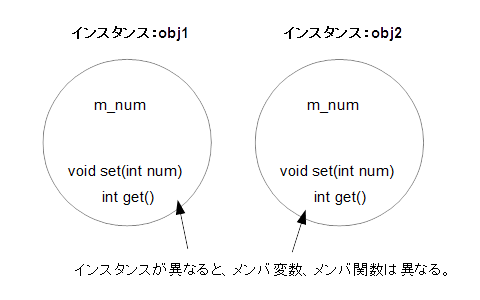
この例でいくのなら、obj1のm_numに値を代入しても、obj2のm_numの値は変わりませんし、その逆も同じです。つまり、インスタンスが違うと、同じ名前のメンバ変数でもまったく違うものだということです。