Para este taller vamos a estar viendo el caso de aprendizaje supervisado para entrenar clasificadores de texto. En general un clasificador es un programa que te dice la probabilidad de que un input (texto, imagen, audio, archivo binario, ect...) sea de algún tipo específico.
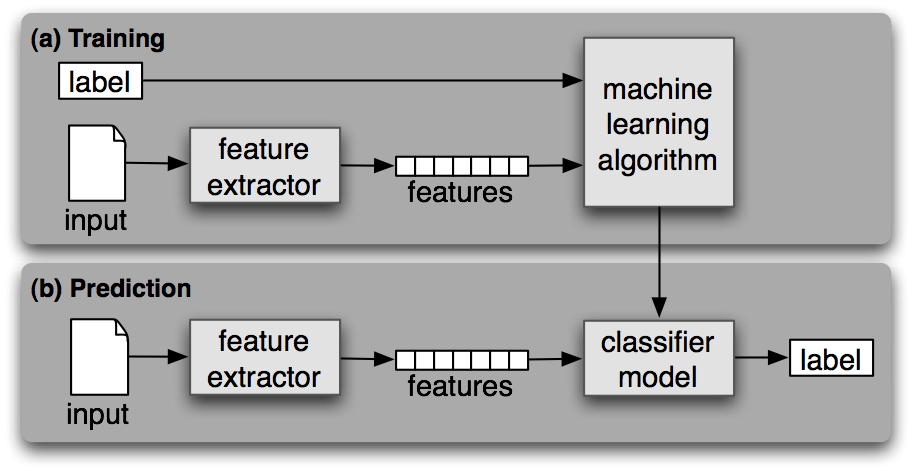
En este caso estamos viendo texto, específicamente documentos. Un documento es una colección de texto, puede ser un libro, un tweet, una noticia, una página de internet, una conversación de whatsapp o un correo. La clasificación la escogemos nosotros al momento de "entrenar" el clasificador, por eso se le dice aprendizaje supervisado. Nosotros tenemos que mostrarle al algoritmo lo que se conoce como un train set, documentos previamente clasificados, y además un test set, documentos clasificados que serán solo usados para medir la efectividad del clasificador luego de ser entrenado. Imagínate una tabla de dos columnas en donde en la primera columna está el documento (bloque de texto) y en la segunda columna está el "tipo" de documento. En base a esto el algoritmo "aprende". Por ejemplo, imaginate una tabla de excel en donde la primera columna contiene un tweet y la segunda columna te indica si es están hablando sobre algo relacionado a Donald Trump.
Para que la computadora pueda entender el documento se hace lo que se conoce como “feature extraction” o “extracción de características”. Esto es una función que transforma el documento en un vector (array) de características. La definición de características es sumamente importante ya esto es lo que el algoritmo utiliza para ajustar sus criterios. Para este taller utilizaremos un bag-of-words approach. Esto consiste en agarrar todas las palabras que existen entre todos los documentos que queremos poder clasificar y crear un array donde cada elemento corresponde a una posible palabra y se indica si el documento la tiene o no.
https://www.nltk.org/book/ch06.html#gender-identification
def gender_features(word):
return {'last_letter': word[-1]}
def gender_features2(name):
features = {}
features["first_letter"] = name[0].lower()
features["last_letter"] = name[-1].lower()
for letter in 'abcdefghijklmnopqrstuvwxyz':
features["count({})".format(letter)] = name.lower().count(letter)
features["has({})".format(letter)] = (letter in name.lower())
return features
https://www.nltk.org/book/ch06.html#gender-identification
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return featuresDeben completar el programa para poder crear el clasificador de text usando la data que esta en noticias.csv
http://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html
-
Tokenization: tf-idf
-
NGrams grupos de palabras
-
skLearn
-
gensim