
🔥🔥 The VideoCrafter1 for high-quality video generation are now released! Please Join us and create your own film on Discord/Floor33.

🤗🤗🤗 VideoCrafter is an open-source video generation and editing toolbox for crafting video content.
It currently includes the Text2Video and Image2Video models:
Click the GIF to access the high-resolution video.
 |
 |
| "A girl is looking at the camera smiling. High Definition." | "an astronaut running away from a dust storm on the surface of the moon, the astronaut is running towards the camera, cinematic" |
 |
 |
| "A giant spaceship is landing on mars in the sunset. High Definition." | "A blue unicorn flying over a mystical land" |
 |
 |
 |
 |
 |
 |
 |
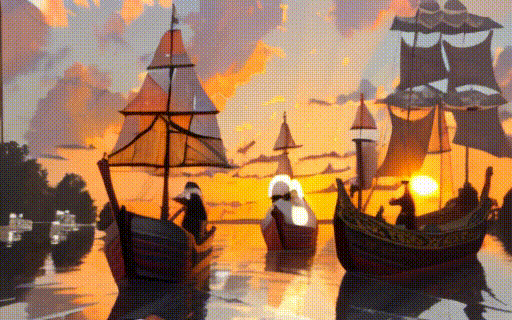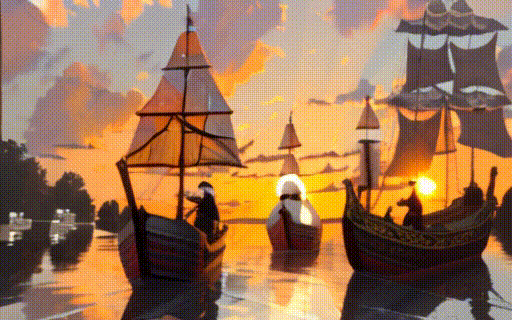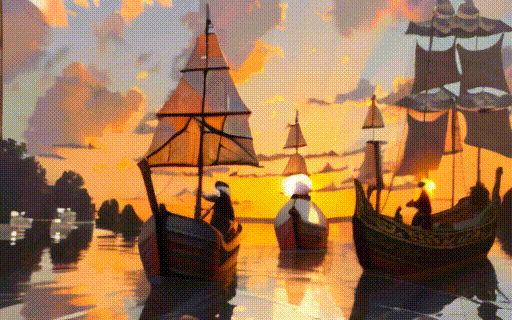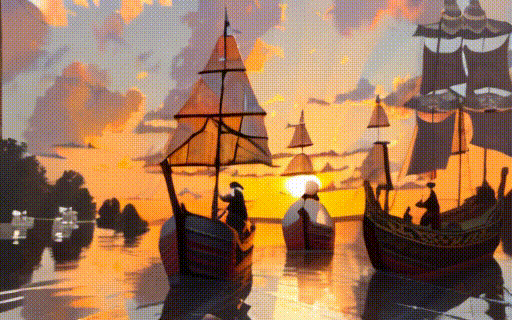 |
| "a black swan swims on the pond" | "a girl is riding a horse fast on grassland" | "a boy sits on a chair facing the sea" | "two galleons moving in the wind at sunset" |
-
[2023.10.13]: 🔥🔥 Release the VideoCrafter1, High Quality Video Generation!
-
[2023.08.14]: Release a new version of VideoCrafter on Discord/Floor33. Please join us to create your own film!
-
[2023.04.18]: Release a VideoControl model with most of the watermarks removed!
-
[2023.04.05]: Release pretrained Text-to-Video models, VideoLora models, and inference code.
| Models | Resolution | Checkpoints |
|---|---|---|
| Text2Video | 576x1024 | Hugging Face |
| Image2Video | 320x512 | Hugging Face |
conda create -n videocrafter python=3.8.5
conda activate videocrafter
pip install -r requirements.txt- Download pretrained T2V models via Hugging Face, and put the
model.ckptincheckpoints/base_1024_v1/model.ckpt. - Input the following commands in terminal.
sh scripts/run_text2video.sh- Download pretrained I2V models via Hugging Face, and put the
model.ckptincheckpoints/i2v_512_v1/model.ckpt. - Input the following commands in terminal.
sh scripts/run_image2video.sh⏳⏳⏳ Comming soon. We are still working on it.💪
The technical report is currently unavailable as it is still in preparation. You can cite the paper of our base model, on which we built our applications.
@article{he2022lvdm,
title={Latent Video Diffusion Models for High-Fidelity Long Video Generation},
author={Yingqing He and Tianyu Yang and Yong Zhang and Ying Shan and Qifeng Chen},
year={2022},
eprint={2211.13221},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Our codebase builds on Stable Diffusion. Thanks the authors for sharing their awesome codebases!
We develop this repository for RESEARCH purposes, so it can only be used for personal/research/non-commercial purposes.