The Official Pytorch Implementation for Switch Gated Multi-Layer Perceptron(SG-MLP).
SG-MLP, a novel and attentionless architecture for Natural Language Understanding(NLU), achieves decent results in the GLUE benchmark without any help of the Attention Mechanism in both Pre-Training and FineTuning steps. The following repositiory contains demos, pretrained models, and supplementaries necessary for reproducing the results.
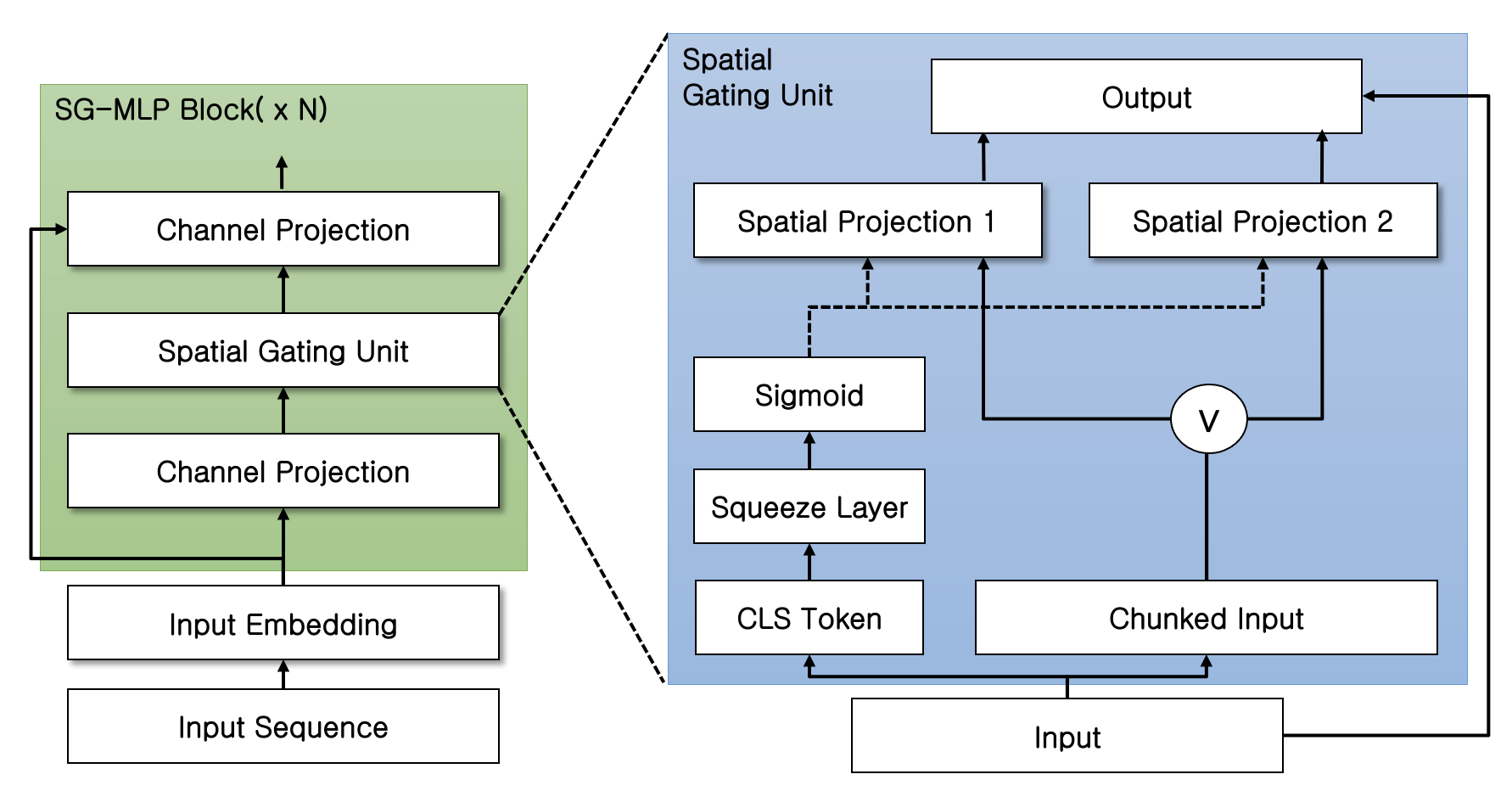
We trained a total of three models SG-MLP Small, SG-MLP Base and SG-MLP Large.
The following are the configuration for each models. Pretrained weights for all models are available here.
| SG-MLP | Parameter | Tokenizer | Corpus | Train Steps |
|---|---|---|---|---|
SG-MLP Small |
67 M |
bert-base-cased |
Book Corpus + Wiki |
110,000 |
SG-MLP Base |
125 M |
roberta-base |
C4 |
200,000 |
SG-MLP Large |
170 M |
roberta-base |
C4 |
200,000 |
- Load SG-MLP Base
from SGMLP.models.model import build_base_model
from SGMLP.utils import apply_weight
PATH = '/weights/SGMLP_Base.pth'
base_model = build_base_model()
base_model = apply_weight(base_model,PATH)- Load SG-MLP Large
from SGMLP.models.model import build_large_model
from SGMLP.utils import apply_weight
PATH = '/weights/SGMLP_Large.pth'
large_model = build_large_model()
large_model = apply_weight(large_model,PATH)SG-MLP trained on the C4 corpus, learns to predict proper grammer and commonsense knowledge. Refer to the codes below, or the Colab Notebook for a MLM demo ran by our model. (Make sure you have our pretrained model downloaded for the demo)
from SGMLP.models.model import build_large_model
from SGMLP.utils import SGMLP_inference, apply_weight
PATH = '/weights/SGMLP_Large.pth'
large_model = build_large_model(output_logits = True)
large_model = apply_weight(large_model,PATH)
SGMLP_inference('A bird has <mask> legs.',large_model)- 김승원 - Seungone Kim
- 손규진 - GUIJIN SON
- 주세준 - SE JUNE JOO
- 조우진 - WOOJIN CHO
- 채형주 - Hyungjoo Chae
@InProceedings{Zhu_2015_ICCV,
title = {Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books},
author = {Zhu, Yukun and Kiros, Ryan and Zemel, Rich and Salakhutdinov, Ruslan and Urtasun, Raquel and Torralba, Antonio and Fidler, Sanja},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {December},
year = {2015}
}@InProceedings{wikitext,
author={Stephen, Merity and Caiming ,Xiong and James, Bradbury and Richard Socher}
year=2016
}@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}@InProceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
}