Official code and data repository of ADBench: Anomaly Detection Benchmark. Please star, watch, and fork ADBench for the active updates!
We are making revision to the paper, and there might be some mismatches between the repo and the paper. The next paper release will be around Mid Sep.
Our ADBench benchmark paper is now available on arxiv. If you find this work useful or use some our released datasets, we would appreciate citations to the following paper:
@article{han2022adbench,
title={ADBench: Anomaly Detection Benchmark},
author={Songqiao Han and Xiyang Hu and Hailiang Huang and Mingqi Jiang and Yue Zhao},
year={2022},
eprint={2206.09426},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
ADBench is a collaborative effort between researchers at Shanghai University of Finance and Economics (SUFE) and Carnegie Mellon University (CMU). The project is designed and conducted by Minqi Jiang (SUFE) and Yue Zhao (CMU), and Xiyang Hu (CMU) --the author(s) of important anomaly detection libraries, including anomaly detection for tabular (PyOD), time-series (TODS), and graph data (PyGOD).
ADBench is (to our best knowledge) the most comprehensive tabular anomaly detection benchmark, where we analyze the performance of 30 anomaly detection algorithms on 57 datasets (where we introduced 10 new datasets). By analyzing both research needs and deployment requirements in industry, ADBench conducts 98,436 experiments with three major angles:
- the effect of supervision (e.g., ground truth labels) by including 14 unsupervised, 7 semi-supervised, and 9 supervised methods;
- algorithm performance under different types of anomalies by simulating the environments with 4 types of anomalies; and
- algorithm robustness and stability under 3 settings of data corruptions.
Key Takeaways in 1 Minute:
‼️ surprisingly none of the benchmarked unsupervised algorithms is statistically better than others, emphasizing the importance of algorithm selection;‼️ with merely 1% labeled anomalies, most semi-supervised methods can outperform the best unsupervised method, justifying the importance of supervision;- in controlled environments, we observe that best unsupervised methods for specific types of anomalies are even better than semi- and fully-supervised methods, revealing the necessity of understanding data characteristics;
- semi-supervised methods show potential in achieving robustness in noisy and corrupted data, possibly due to their efficiency in using labels and feature selection;
⁉️ and many more can be found in our papers (Section 4)
The Figure below provides an overview of our proposed ADBench (see our paper for details).

We envision three primary usages of ADBench:
- Have better understanding of anomaly detection algorithms: please read our paper for details.
- Conduct future research on anomaly detection: we list 4 important future research questions in the paper--see Section 4 to see some thoughts!
- Access rich algorithm implementation and datasets: see details below for how to use them
- Benchmark your anomaly detection algorithms: see notebook for instruction.
The experiment code is written in Python 3 and built on a number of Python packages:
- scikit-learn==0.20.3
- pyod==1.0.0
- Keras==2.8.0
- tensorflow==2.8.0
- torch==1.9.0
- rtdl==0.0.13
- delu
- lightgbm
- xgboost
- catboost
- copulas
We present the following example for quickly implementing ADBench in three different Angles illustrated in the paper. Currently, 57 datasets can be used for evaluating 30 algorithms in ADBench, and we encourage to test your customized datasets/algorithms in our ADBench testbed.
Angle I: Availability of Ground Truth Labels (Supervision)
from data_generator import DataGenerator
from myutils import Utils
# one can use our already included datasets
data_generator = DataGenerator(dataset='6_cardio.npz')
# specify the ratio of labeled anomalies to generate X and y
# la could be any float number in [0.0, 1.0]
data = data_generator.generator(la=0.1)
# or specify the X and y of your customized data
# data_generator = DataGenerator(dataset=None)
# data = data_generator.generator(X=X, y=y, la=0.1)
# import AD algorithms (e.g., DevNet) and initialization
from baseline.DevNet.run import DevNet
model = DevNet(seed=42)
# fitting
model.fit(X_train=data['X_train'], y_train=data['y_train'])
# prediction
score = model.predict_score(data['X_test'])
# evaluation
utils = Utils()
result = utils.metric(y_true=data['y_test'], y_score=score)Angle II: Types of Anomalies
# For Angle II, different types of anomalies are generated as the following
data_generator = DataGenerator(dataset='6_cardio.npz')
# the type of anomalies could be 'local', 'global', 'dependency' or 'cluster'.
data = data_generator.generator(realistic_synthetic_mode='local')Angle III: Model Robustness with Noisy and Corrupted Data
# For Angle III, different data noises and corruptions are added as the following
data_generator = DataGenerator(dataset='6_cardio.npz')
# the type of anomalies could be 'duplicated_anomalies', 'irrelevant_features' or 'label_contamination'.
data = data_generator.generator(noise_type='duplicated_anomalies')- We also provide an example for quickly implementing ADBench, as shown in notebook.
- For complete results of ADBench, please refer to our paper.
- For reproduce experiment results of ADBench, please run the code.
ADBench includes 57 datasets, as shown in the following Table.
-
Among them, 47 widely-used real-world datasets are gathered for model evaluation, which cover many application domains, including healthcare (e.g., disease diagnosis), audio and language processing (e.g., speech recognition), image processing (e.g., object identification), finance (e.g., financial fraud detection), etc.
-
we introduce 10 more complex datasets from CV and NLP domains with more samples and richer features in ADBench. Pretrained models are applied to extract data embedding from NLP and CV datasets to access more complex representation. Please see the datasets folder and our paper for detailed information.
-
We organize the above 57 datasets into user-friendly format. All the datasets are named as "number_data.npz" in the datasets folder. For example, one can evaluate AD algorithms on the cardio dataset by the following codes. For multi-class dataset like CIFAR10, additional class numbers should be specified as "number_data_class.npz". Please see the folder for more details.
-
We provide the data processing code for NLP datasets and for CV datasets in Google Colab, where one can quickly reproduce our procedures via the free GPUs. We hope this could be helpful for the AD community.
We have unified all the datasets in .npz format, and you can read a dataset by the following script
import numpy as np
data = np.load('6_cardio.npz', allow_pickle=True)
X, y = data['X'], data['y']| Number | Data | # Samples | # Features | # Anomaly | % Anomaly | Category |
|---|---|---|---|---|---|---|
| 1 | ALOI | 49534 | 27 | 1508 | 3.04 | Image |
| 2 | annthyroid | 7200 | 6 | 534 | 7.42 | Healthcare |
| 3 | backdoor | 95329 | 196 | 2329 | 2.44 | Network |
| 4 | breastw | 683 | 9 | 239 | 34.99 | Healthcare |
| 5 | campaign | 41188 | 62 | 4640 | 11.27 | Finance |
| 6 | cardio | 1831 | 21 | 176 | 9.61 | Healthcare |
| 7 | Cardiotocography | 2114 | 21 | 466 | 22.04 | Healthcare |
| 8 | celeba | 202599 | 39 | 4547 | 2.24 | Image |
| 9 | census | 299285 | 500 | 18568 | 6.20 | Sociology |
| 10 | cover | 286048 | 10 | 2747 | 0.96 | Botany |
| 11 | donors | 619326 | 10 | 36710 | 5.93 | Sociology |
| 12 | fault | 1941 | 27 | 673 | 34.67 | Physical |
| 13 | fraud | 284807 | 29 | 492 | 0.17 | Finance |
| 14 | glass | 214 | 7 | 9 | 4.21 | Forensic |
| 15 | Hepatitis | 80 | 19 | 13 | 16.25 | Healthcare |
| 16 | http | 567498 | 3 | 2211 | 0.39 | Web |
| 17 | InternetAds | 1966 | 1555 | 368 | 18.72 | Image |
| 18 | Ionosphere | 351 | 32 | 126 | 35.90 | Oryctognosy |
| 19 | landsat | 6435 | 36 | 1333 | 20.71 | Astronautics |
| 20 | letter | 1600 | 32 | 100 | 6.25 | Image |
| 21 | Lymphography | 148 | 18 | 6 | 4.05 | Healthcare |
| 22 | magic.gamma | 19020 | 10 | 6688 | 35.16 | Physical |
| 23 | mammography | 11183 | 6 | 260 | 2.32 | Healthcare |
| 24 | mnist | 7603 | 100 | 700 | 9.21 | Image |
| 25 | musk | 3062 | 166 | 97 | 3.17 | Chemistry |
| 26 | optdigits | 5216 | 64 | 150 | 2.88 | Image |
| 27 | PageBlocks | 5393 | 10 | 510 | 9.46 | Document |
| 28 | pendigits | 6870 | 16 | 156 | 2.27 | Image |
| 29 | Pima | 768 | 8 | 268 | 34.90 | Healthcare |
| 30 | satellite | 6435 | 36 | 2036 | 31.64 | Astronautics |
| 31 | satimage-2 | 5803 | 36 | 71 | 1.22 | Astronautics |
| 32 | shuttle | 49097 | 9 | 3511 | 7.15 | Astronautics |
| 33 | skin | 245057 | 3 | 50859 | 20.75 | Image |
| 34 | smtp | 95156 | 3 | 30 | 0.03 | Web |
| 35 | SpamBase | 4207 | 57 | 1679 | 39.91 | Document |
| 36 | speech | 3686 | 400 | 61 | 1.65 | Linguistics |
| 37 | Stamps | 340 | 9 | 31 | 9.12 | Document |
| 38 | thyroid | 3772 | 6 | 93 | 2.47 | Healthcare |
| 39 | vertebral | 240 | 6 | 30 | 12.50 | Biology |
| 40 | vowels | 1456 | 12 | 50 | 3.43 | Linguistics |
| 41 | Waveform | 3443 | 21 | 100 | 2.90 | Physics |
| 42 | WBC | 223 | 9 | 10 | 4.48 | Healthcare |
| 43 | WDBC | 367 | 30 | 10 | 2.72 | Healthcare |
| 44 | Wilt | 4819 | 5 | 257 | 5.33 | Botany |
| 45 | wine | 129 | 13 | 10 | 7.75 | Chemistry |
| 46 | WPBC | 198 | 33 | 47 | 23.74 | Healthcare |
| 47 | yeast | 1484 | 8 | 507 | 34.16 | Biology |
| 48 | CIFAR10 | 5263 | 512 | 263 | 5.00 | Image |
| 49 | FashionMNIST | 6315 | 512 | 315 | 5.00 | Image |
| 50 | MNIST-C | 10000 | 512 | 500 | 5.00 | Image |
| 51 | MVTec-AD | See Table B2. | Image | |||
| 52 | SVHN | 5208 | 512 | 260 | 5.00 | Image |
| 53 | Agnews | 10000 | 768 | 500 | 5.00 | NLP |
| 54 | Amazon | 10000 | 768 | 500 | 5.00 | NLP |
| 55 | Imdb | 10000 | 768 | 500 | 5.00 | NLP |
| 56 | Yelp | 10000 | 768 | 500 | 5.00 | NLP |
| 57 | 20newsgroups | See Table B3. | NLP |
Compared to the previous benchmark studies, we have a larger algorithm collection with
- latest unsupervised AD algorithms like DeepSVDD and ECOD;
- SOTA semi-supervised algorithms, including DeepSAD and DevNet;
- latest network architectures like ResNet in computer vision (CV) and Transformer in natural language processing (NLP) domain ---we adapt ResNet and FTTransformer models for tabular AD in the proposed ADBench; and
- ensemble learning methods like LightGBM, XGBoost, and CatBoost.
The Figure below shows the algorithms (14 unsupervised, 7 semi-supervised, and 9 supervised algorithms) in ADBench.
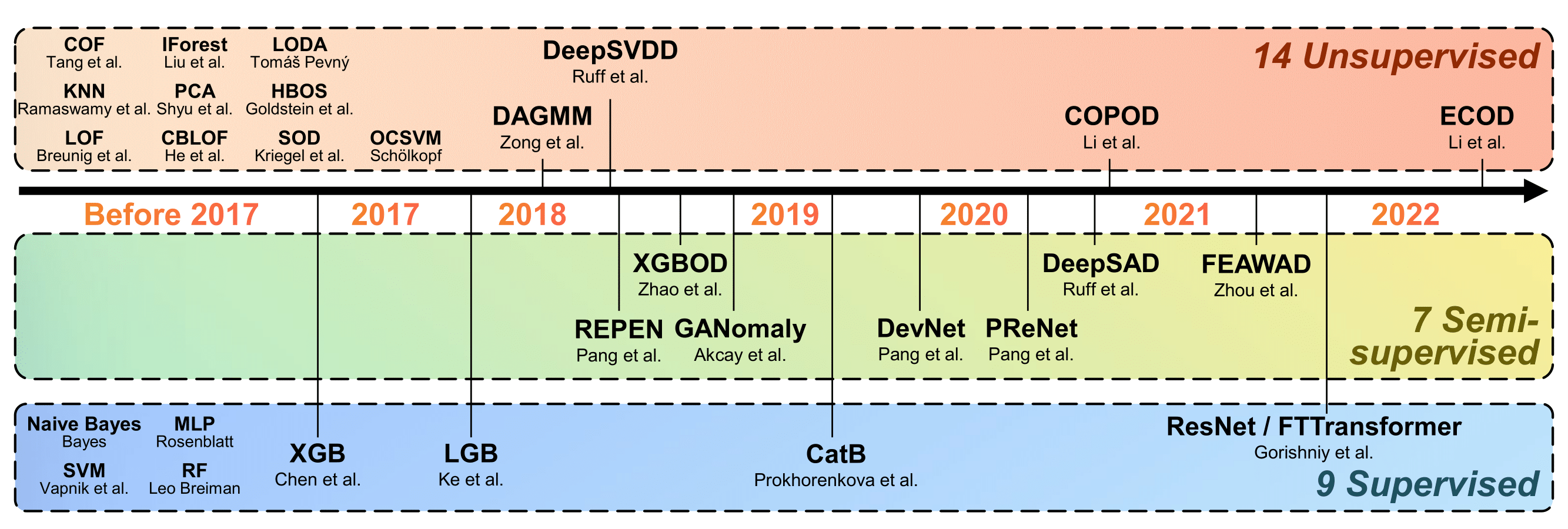

For each algorithm, we also introduce its specific implementation in the following Table. The only thing worth noting is that model name should be specified (especially for those models deployed by their corresponding package, e.g., PyOD). The following codes show the example to import AD models. Please see the Table for complete AD models included in ADBench and their import methods.
from baseline.PyOD import PYOD
model = PYOD(model_name='XGBOD') # initialization
model.fit(X_train, y_train) # fit
score = model.predict_score(X_test) # predict| Model | Year | Type | DL | Import | Source |
|---|---|---|---|---|---|
| PCA | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| OCSVM | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| LOF | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| CBLOF | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| COF | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| HBOS | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| KNN | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| SOD | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| COPOD | 2020 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| ECOD | 2022 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| IForest† | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| LODA† | Before 2017 | Unsup | ✗ | from baseline.PyOD import PYOD | Link |
| DeepSVDD | 2018 | Unsup | ✓ | from baseline.PyOD import PYOD | Link |
| DAGMM | 2018 | Unsup | ✓ | from baseline.DAGMM.run import DAGMM | Link |
| GANomaly | 2018 | Semi | ✓ | from baseline.GANomaly.run import GANomaly | Link |
| XGBOD† | 2018 | Semi | ✗ | from baseline.PyOD import PYOD | Link |
| DeepSAD | 2019 | Semi | ✓ | from baseline.DeepSAD.src.run import DeepSAD | Link |
| REPEN | 2018 | Semi | ✓ | from baseline.REPEN.run import REPEN | Link |
| DevNet | 2019 | Semi | ✓ | from baseline.DevNet.run import DevNet | Link |
| PReNet | 2020 | Semi | ✓ | from baseline.PReNet.run import PReNet | / |
| FEAWAD | 2021 | Semi | ✓ | from baseline.FEAWAD.run import FEAWAD | Link |
| NB | Before 2017 | Sup | ✗ | from baseline.Supervised import supervised | Link |
| SVM | Before 2017 | Sup | ✗ | from baseline.Supervised import supervised | Link |
| MLP | Before 2017 | Sup | ✓ | from baseline.Supervised import supervised | Link |
| RF† | Before 2017 | Sup | ✗ | from baseline.Supervised import supervised | Link |
| LGB† | 2017 | Supervised | ✗ | from baseline.Supervised import supervised | Link |
| XGB† | Before 2017 | Sup | ✗ | from baseline.Supervised import supervised | Link |
| CatB† | 2019 | Sup | ✗ | from baseline.Supervised import supervised | Link |
| ResNet | 2019 | Sup | ✓ | from baseline.FTTransformer.run import FTTransformer | Link |
| FTTransformer | 2019 | Sup | ✓ | from baseline.FTTransformer.run import FTTransformer | Link |
- '†' marks ensembling. This symbol is not included in the model name.
- Un-, semi-, and fully-supervised methods are denoted as unsup, semi and sup, respectively.